






Python中实现文字识别的常用方法是使用pytesseract库,它是Google的Tesseract-OCR引擎的Python封装。
一、Tesseract-OCR下载安装
Tesseract-OCR下载地址Index of /tesseract,网页最下方选择最新版下载。
安装过程中勾选chi_sim下载中文训练数据,其他训练数据根据需要选择。
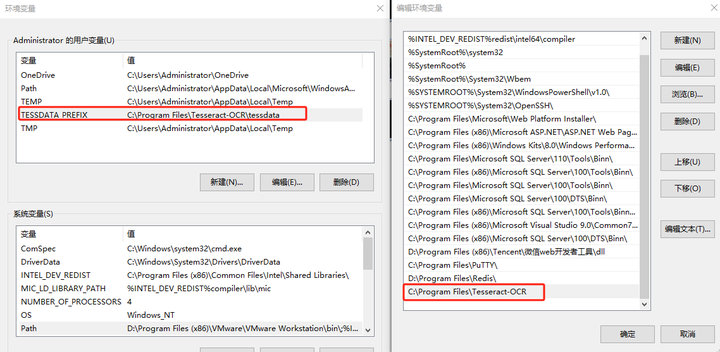
安装好后,添加环境变量:
用户变量:TESSDATA_PREFIX:C:\Program Files\Tesseract-OCR\tessdata
系统变量:Path:C:\Program Files\Tesseract-OCR
具体路径根据实际安装路径。
在命令行测试是否安装成功。
tesseract -v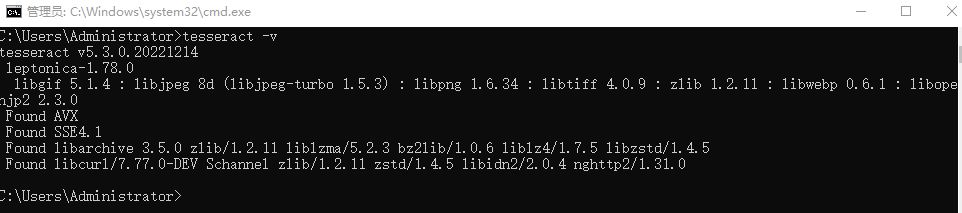
如图表明成功安装
二、安装pytesseract库
我的python版本是3.12,并不一定必须该版本。命令行执行:
pip install pytesseract -i https://pypi.tuna.tsinghua.edu.cn/simple-i参数指定从清华服务器下载,可以加速下载,减少错误。
三、python代码识别
import pytesseract
from PIL import Image
# 指定tesseract安装路径。如果配置好环境变量,该行应注释。
# pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files\\Tesseract-OCR' # 根据实际路径修改
# 打开图片,确保正确的图片路径
image = Image.open('D:\\chx\\temp.png')
# 使用Tesseract进行文字识别。如果要识别中文,需参数lang='chi_sim'
text = pytesseract.image_to_string(image,lang='chi_sim')
print(text)有疑问欢迎评论交流。















 5552
5552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









