






 文章介绍了如何使用LabelStudio进行命名实体抽取(NER)和关系抽取(RE)的文本数据库标注,包括环境配置、工具使用、标注设置、快捷键操作以及数据导出和JSON格式处理。重点探讨了关系抽取的标注方法及其数据导出的挑战。
文章介绍了如何使用LabelStudio进行命名实体抽取(NER)和关系抽取(RE)的文本数据库标注,包括环境配置、工具使用、标注设置、快捷键操作以及数据导出和JSON格式处理。重点探讨了关系抽取的标注方法及其数据导出的挑战。
前言
最近在做一些命名实体抽取(NER)和关系抽取(RE)的文本数据库标注工作
网上搜集资料后发现有一个标注工具叫label studio非常实用。
相关工作参考了文章命名实体识别(NER)标注神器——Label Studio 简单使用
环境配置
安装代码(命令行)
pip install -U label-studio运行代码(命令行)
label-studio工具使用
运行代码后会自动跳转到一个本地网页界面,我这里的地址是localhost:8080,如果本地端口被其他程序占用,会顺延到localhost:8081等等
点开注册账户之后会跳转到如下界面:

以上是我这里的几个项目,标注进度也很清晰地展示了出来
文件导入
点开其中一个项目,首先选择右上角的import选项导入文件,跳出以下界面
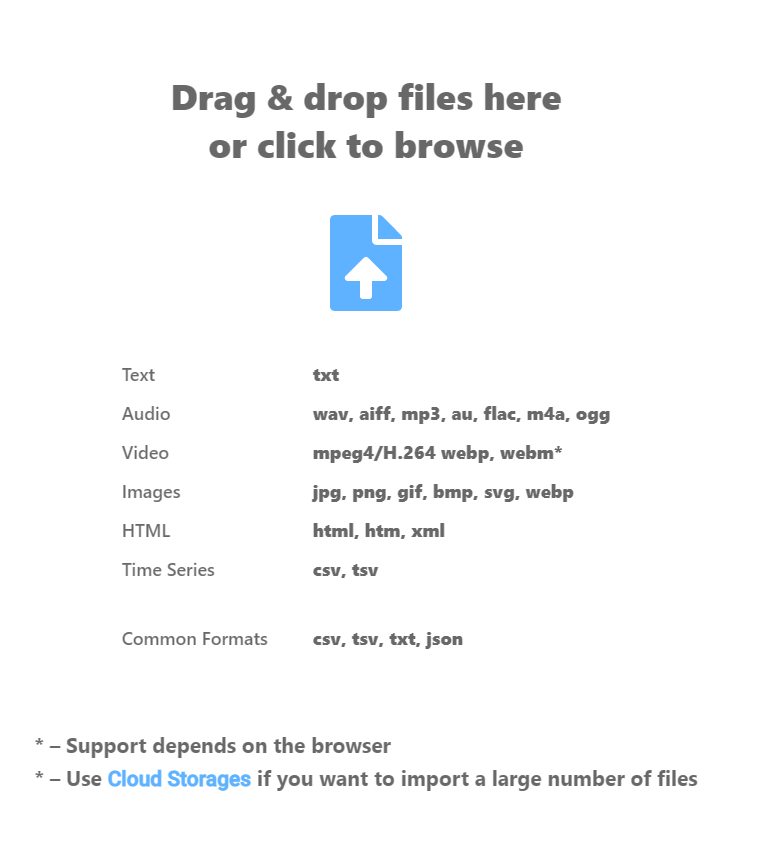
这里我选择的是txt文本文件,每一行文本在导入后就是一条记录
标注设置
点击右上角的setting选项,进入标注设置界面后选择labeling interface
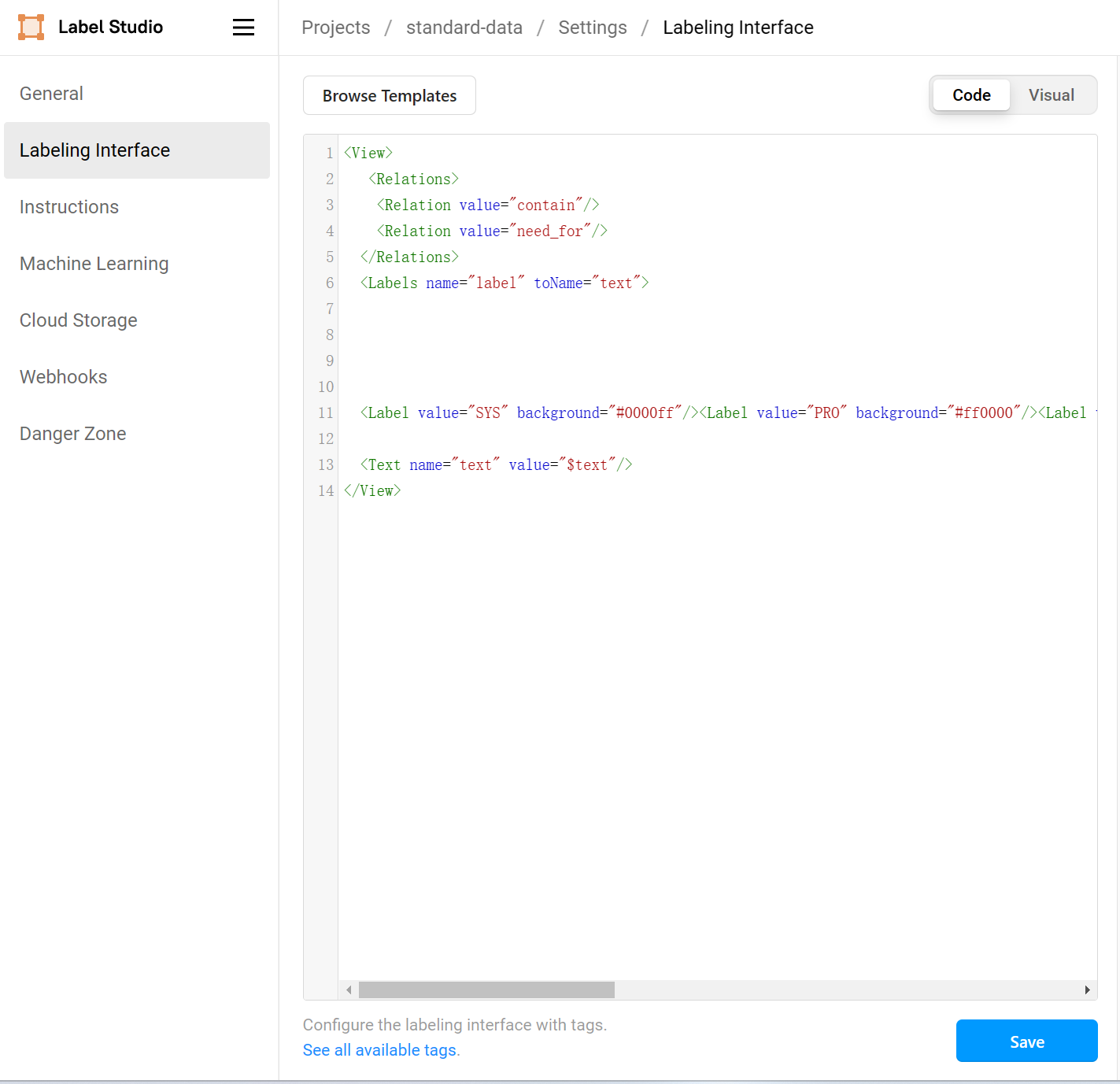
可以点击browse templates获取模板,也可以自己编写规则,编写规则见官方网站
命名实体抽取在已有的文章中都说得很清楚了,我主要是探索了一下关系抽取的标注方法
首先是标注设置的代码
<View>
<Relations>
<Relation value="contain"/>
<Relation value="need_for"/>
</Relations>
<Labels name="label" toName="text">
<Label value="SYS" background="#0000ff"/>
<Label value="PRO" background="#ff0000"/>
<Label value="CON" background="#FFC069"/>
<Label value="PAT" background="#00ff00"/>
<Label value="MAI" background="#ffff00"/>
<Label value="PER" background="#00ffff"/>
</Labels>
<Text name="text" value="$text"/>
</View>我这里是设置了6种实体类型和2种关系类型,如果要添加或者修改设置,直接更改这段代码即可
标注操作
文本标注操作,比较简单也很容易理解,但是关系抽取的标注实在是令人难以捉摸
我探索了好久,终于发现label-studio竟然还有快捷键选项
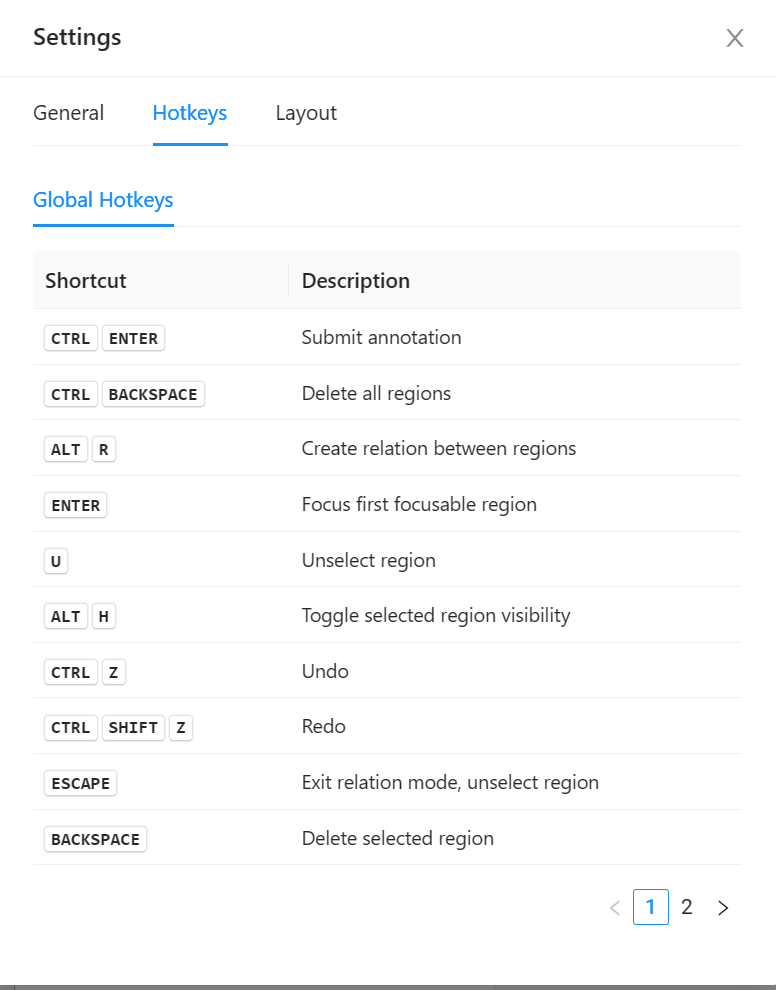
这里默认的关系标注快捷键为Alt+R,不得不说这个键位设置真的隐蔽
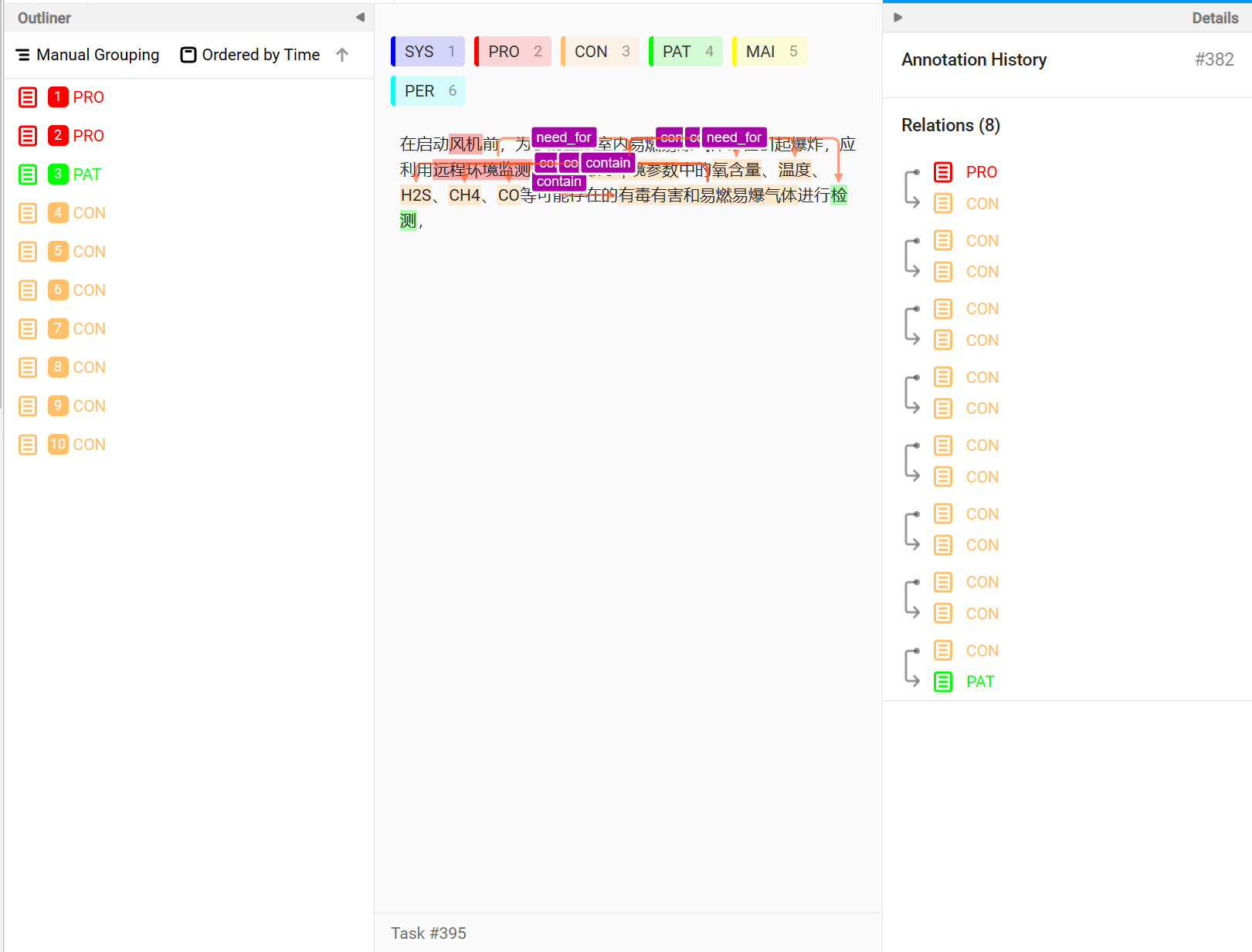
然后就可以开始愉快的标注工作了。
数据导出
label-studio的数据导出比较清楚,基本涉及各种格式,如果只需要导出BIO标注的,可以选择CSV导出,代码参考命名实体识别(NER)标注神器——Label Studio 简单使用
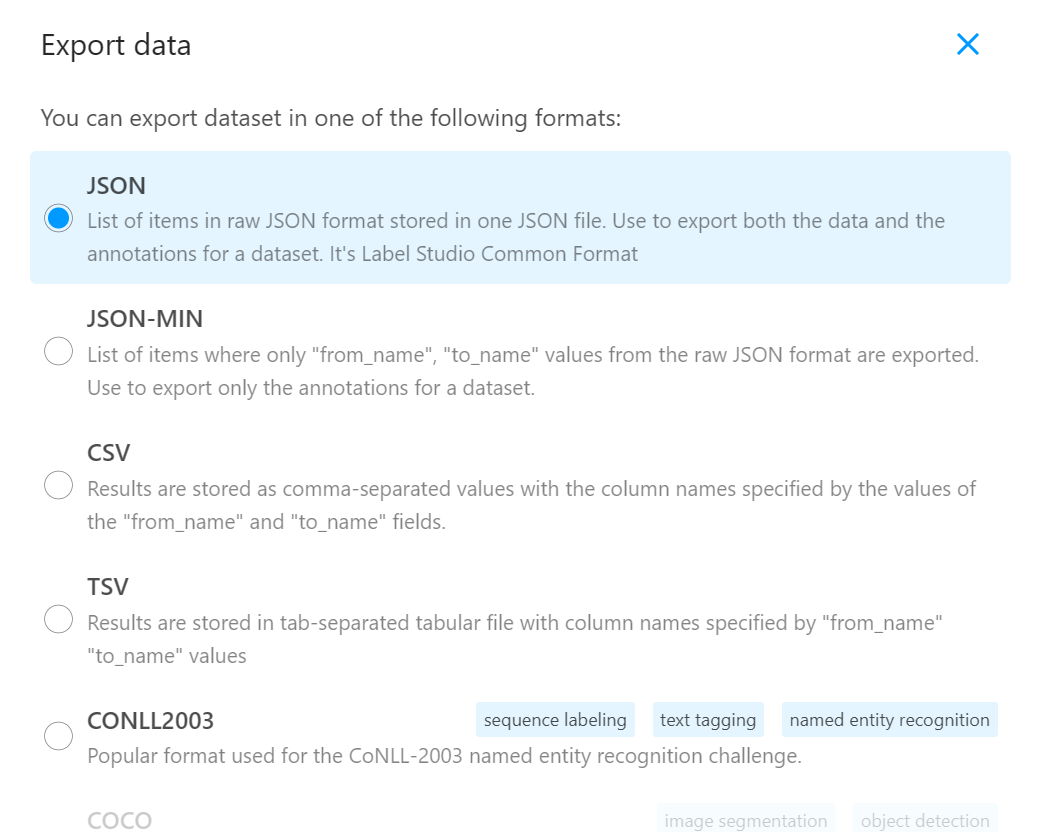
问题是关系抽取的数据导出非常不受重视,我全部试了一下,只有第一个JSON格式是可以导出关系的
JSON数据处理
首先是数据读取,这里文件命名为project.json
import json
path = 'project.json'
with open(path,'r',encoding = 'utf-8') as fp:
data = json.load(fp)
fp.close()然后是数据的处理,基本注释已经写在里面了。
def json_to_BR_annotations(data):
dictlist = []
for j in range(0,len(data)):
#数据获取
datalist = data[j]['annotations'][0]['result']
#数据格式初始化
datadict = {}
datadict['text'] = data[j]['data']['text']#读取数据
datadict['BIO_anno'] = ['O' for i in datadict['text']]#初始化BIO(全部设置为O)
datadict['relation_anno'] = [[['N',i]] for i in range(0,len(datadict['text']))]#初始化关系标注(全部设置为O)
for d in datalist:
if d['type'] == 'labels':#BIO提取
sid = d['value']['start']
eid = d['value']['end']
label = d['value']['labels']
datadict['BIO_anno'][sid] = 'B-'+label[0]#单字符词
if sid+1<eid:#多字符词
for id in range(sid+1,eid):
datadict['BIO_anno'][id] = 'I-'+label[0]
if d['type'] == 'relation':#关系标注
fid = d['from_id']#头实体
tid = d['to_id']#尾实体
for sd in datalist:
if sd['type'] == 'labels':
if sd['id'] == fid:#找到头节点
head = sd
if sd['id'] == tid:#找到尾节点
tail = sd
#关系确定
if d['labels'] != []:#关系不为空
relation = d['labels'][0]
#最终标注
headid = head['value']['end'] - 1#头节点尾字id
tailid = tail['value']['end'] - 1#尾节点尾字id
if datadict['relation_anno'][headid][0][0] == 'N':#不存在任何关系
datadict['relation_anno'][headid][0] = [relation,tailid]
else: #已经存在过关系
datadict['relation_anno'][headid].append([relation,tailid])#加在已有关系的后面
#数据保存
dictlist.append(datadict)
return dictlist
最后是一些数据展示
这段话
在启动风机前,为了防止舱室内易燃易爆气体存在引起爆炸,应利用远程环境监测系统对廊内环境参数中的氧含量、温度、H2S、CH4、CO等可能存在的有毒有害和易燃易爆气体进行检测,
输出结果
BIO_anno
['O', 'O', 'O', 'B-PRO', 'I-PRO', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-PRO', 'I-PRO', 'I-PRO', 'I-PRO', 'I-PRO', 'I-PRO', 'I-PRO', 'I-PRO', 'O', 'B-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'O', 'O', 'B-CON', 'I-CON', 'I-CON', 'O', 'B-CON', 'I-CON', 'O', 'B-CON', 'I-CON', 'I-CON', 'O', 'B-CON', 'I-CON', 'I-CON', 'O', 'B-CON', 'I-CON', 'O', 'O', 'O', 'O', 'O', 'O', 'B-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'I-CON', 'O', 'O', 'B-PAT', 'I-PAT', 'O']relation_anno
[[['N', 0]], [['N', 1]], [['N', 2]], [['N', 3]], [['N', 4]], [['N', 5]], [['N', 6]], [['N', 7]], [['N', 8]], [['N', 9]], [['N', 10]], [['N', 11]], [['N', 12]], [['N', 13]], [['N', 14]], [['N', 15]], [['N', 16]], [['N', 17]], [['N', 18]], [['N', 19]], [['N', 20]], [['N', 21]], [['N', 22]], [['N', 23]], [['N', 24]], [['N', 25]], [['N', 26]], [['N', 27]], [['N', 28]], [['N', 29]], [['N', 30]], [['N', 31]], [['N', 32]], [['N', 33]], [['N', 34]], [['N', 35]], [['N', 36]], [['need_for', 44]], [['N', 38]], [['N', 39]], [['N', 40]], [['N', 41]], [['N', 42]], [['N', 43]], [['contain', 49], ['contain', 52], ['contain', 80], ['need_for', 84]], [['N', 45]], [['N', 46]], [['N', 47]], [['N', 48]], [['N', 49]], [['N', 50]], [['N', 51]], [['N', 52]], [['N', 53]], [['N', 54]], [['N', 55]], [['N', 56]], [['N', 57]], [['N', 58]], [['N', 59]], [['N', 60]], [['N', 61]], [['N', 62]], [['N', 63]], [['N', 64]], [['N', 65]], [['N', 66]], [['N', 67]], [['N', 68]], [['N', 69]], [['N', 70]], [['N', 71]], [['N', 72]], [['N', 73]], [['N', 74]], [['N', 75]], [['N', 76]], [['N', 77]], [['N', 78]], [['N', 79]], [['contain', 56], ['contain', 60], ['contain', 63]], [['N', 81]], [['N', 82]], [['N', 83]], [['N', 84]], [['N', 85]]]标注格式主要参考了论文Joint entity recognition and relation extraction as a multi-head selection problem的网络结构的标注方法

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









