







文章目录
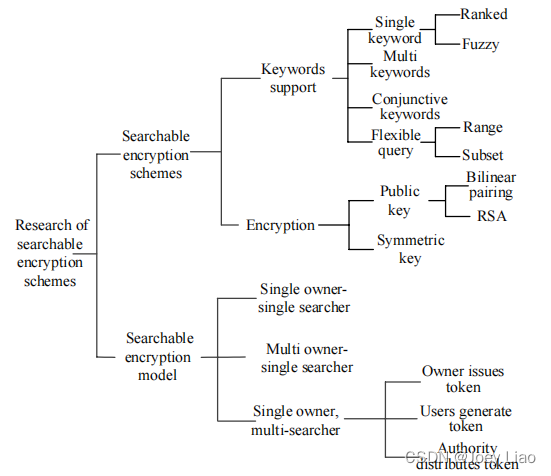
- 1 SE的研究方向
- 2 SE 机制的构造算法
- 3 SE 机制搜索效果分析
1 SE的研究方向
- 灵活、高效的搜索语句的设计:从研究初期的支持单词搜索,到后来逐渐发展为支持连接关键字搜索,再到支持
区间搜索和子集搜索等复杂的逻辑语句。其研究难点在于:如何达到支持复杂的搜索请求的效果以及如何寻找
到适合的困难假设来证明其安全性 - 模糊搜索和基于相似度排序的模糊搜索
- 在不同现实场景中对 SE 机制的应用
2 SE 机制的构造算法
根据构造算法不同分为基于对称密码学算法(symmetric key cryptography based)的 SE 机制以及基于公钥密码学算法(public key cryptography based)的 SE 机制
2.1 SE机制的主要算法
- Setup:该算法主要由权威机构或者数据所有者进行并生成密钥.在基于公钥密码学的 SE 机制中,该
算法会根据输入的安全参数(security parameter)来产生公钥和私钥;在基于对称密码学的 SE 机制中,
运行该算法后会产生一些私钥,例如伪随机函数的密钥等; - BuildIndex:该算法由数据所有者执行.在这种算法中,数据所有者将根据文件内容,选出相应的关键
字集合,并使用可搜索加密机制建立索引表.在基于公钥密码学的 SE 机制中,数据所有者会使用公钥
对每个文件的关键字集进行加密;在基于对称密码学的 SE 机制中,数据所有者会使用对称密钥或者
使用基于密钥的哈希算法对关键字集进行加密.而文件内容主体将会使用对称加密算法进行加密; - GenToken:该算法以根据用户需要搜索的关键字为输入,产生相应的搜索凭证.算法的执行者主要由
应用场景决定,可以由数据所有者、用户或者权威机构来执行(具体场景部分将在第 4节中进行讨论); - Query:该算法是由服务器端进行.服务器将以接收到的搜索凭证和每个文件中的索引表为输入,进行
协议所预设的计算,最后通过输出结果是否与协议预设的结果相同来判断该文件是否满足搜索请
求.服务器最后将搜索结果返回.
3 SE 机制搜索效果分析
分为单词字搜索、连接关键字搜索和复杂逻辑结构语句
3.1 支持单词搜索的SE机制
3.1.1 最早版本的SSE
支持单词搜索指的是用户一次只能对一个关键字进行搜索.2000 年提出了一种基于对称密码学算法的实用 SE 方案
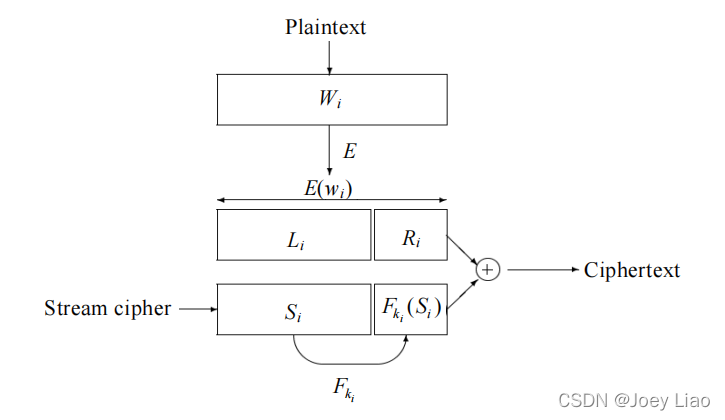
加密过程:
- 一次加密:使用固定的分组加密算法 E 加密文档中的每个关键字得到密文 Xi=E(wi)。并将密文 Xi分成<Li, Ri > 两部分,假设词语 wi的比特流有 n 位, Li 和 Ri 分别为 n-m 和 m 位。
- 伪随机生成器生成一串伪随机序列( S1 ,S2… Sk)且i∈(1,k ) ,Si 有 n-m位;根据散列函数 f 生成密钥ki=f(Li),使用Ki生成校验序列Fki(Si)长度为m位。所以由伪随机序列和校验序列组成流密码Ti=<Si,Fki (Si)>。
- 使用流密码Ti对密文Xi进行二次加密,通过异或运算Ci=Xi^Ti得到二次加密密文。
检索过程:
- 在用户提交检索后需要加密查询关键字w’i得到X’i=E(w’i),X’i分成<L’i,R’i>两部分。
- 使用散列函数得到k’i=f(Li)将<X’i,k’i>发送给服务器。
- 与存储在服务器端的密文集合(C1,C2,…,Cl)进行异或运算,得到T’i =Xi^Ci,进行异或操作得到T’i,如果存在Si对应的Ti使得T’i=Ti,成立,那么该文档中包含关键字wi,反之不包含。
缺点:云端服务器需要对每个文件的内容进行扫描,看密文内容是否存在给定的关键字的密文形式相匹配的内容,造成的计算开销将与文件大小呈线性关系,在海量数据环境下,该方法效率不佳.同时,服务器端可以通过统计攻击的方法获得一些额外的用户隐私信息,例 如,通过得到的搜索凭证来判断用户前后搜索的关键字是否相同等.
3.1.2 建立在Bloom Filter上的SE
它的主要思想是:将文档中的关键字通过多个哈希函{h1,…,hr}处理,将映射到的布隆过滤器位置设为 1。用户在查询时使用同样的哈希函数,若果该位置上的值均为 1,那么该关键字在文档中存在
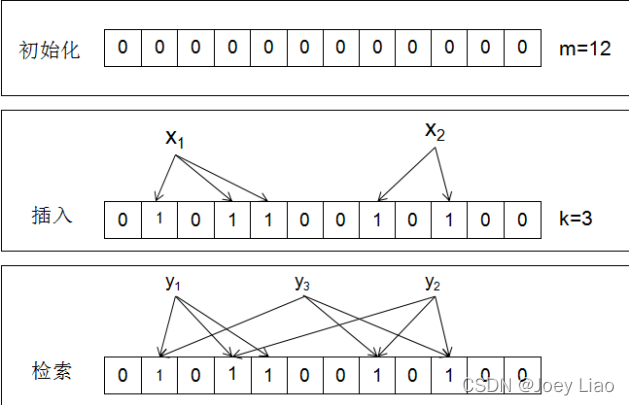
缺点:在映射的过程中可能会出现碰撞问题。例如在图中的y3并没有在该文件中,但因为该文件有x1和x2,于是y3发生碰撞,导致了错误
为了解决这个问题。在此方案的基础上提出一种基于公钥加密关键字搜索的方案,主要思想是:将关键字字符串通过 k 个哈希函数映射到布隆过滤中,原本置为“1”的位置现在插入的是关键字的地址。在查询关键字 yi 时,将其映射到得所有位置的值取与运算,如果值为 1 那么该关键字在文档中存在,反之。
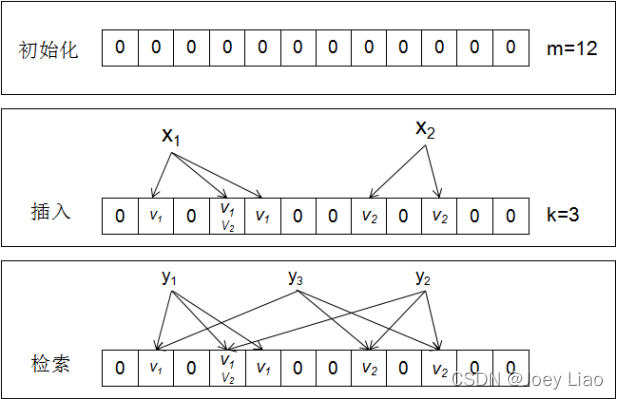 在检索 y1、y2、y3 是否存在时:y1 和 y2 映射位置上所有的值都相同可以认为两个关键字均存在,y3映射的位置上与运算后的结果为 0 因此 y3 不存在。
在检索 y1、y2、y3 是否存在时:y1 和 y2 映射位置上所有的值都相同可以认为两个关键字均存在,y3映射的位置上与运算后的结果为 0 因此 y3 不存在。
新的弊端:如果数据库的规模比较大那么需要的存储空间也更多
3.2 加上了倒排索引技术的SSE
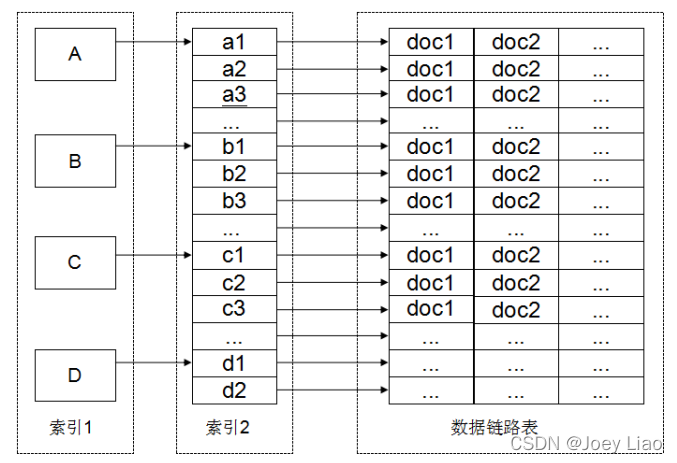
即属性当作索引,指向包含该属性的文件。流程图如下
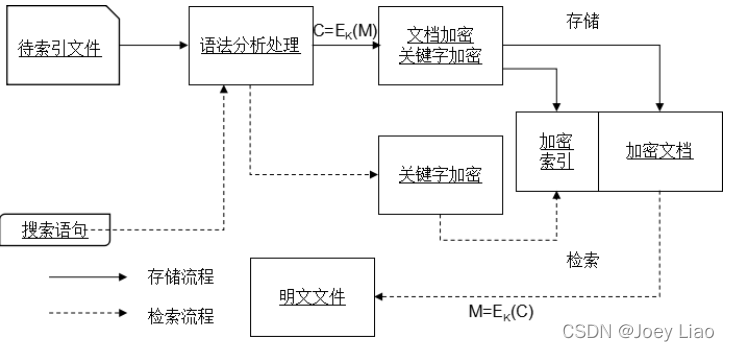
4 模糊搜索的SSE
该方案的突破点是基于编辑距离构建模糊关键字集合,使得用户在一些微小失误情况下,得到与输入方式正确一样的检索结果。编辑距离:把字符串 wi 转换成 wj 的最少操作次数称为编辑距离,即 ed(wi, wj)。它可以用来衡量两个字符串的相似性,在转换的过程中可以进行替换、插入、删除的操作。例如 w1=“student”进行替换操作,集合 W={atudent, studlnt, stodent,„}中的字符串均符合 ed(w1,wi)=1。
与传统的SSE的区别在于建立索引时为每个关键词wi建立编辑距离为d的集合Swi-d,当搜索关键词w‘时,便依据Sw-d中的关键词集合,依次匹配,,若有匹配则加入SK计算出查询陷门,再到索引中查询。
牺牲存储容量来提高少量精确度,大大降低了系统的可用性
5 支持连接(多)关键字搜索的可搜索加密机制
对于多关键词搜索,拍脑袋的想法是应用单词搜索后求交集,或者对每个多关键词进行存储
- 前者允许服务器除了连接查询的结果之外,还学习大量额外的信息,使服务器能够观察到哪些文档匹配了多关键词搜索的每个单独的关键字,随着时间的推移,服务器可能会将这些信息与统计上可能的搜索知识相结合,以推断有关用户文档的信息。
- 后者却需要指数级的存储空间
5.1 Secure conjunctive keyword search over encrypted data 2004
贡献:
- 形式化的定义了安全的多关键词搜索方案(通俗的讲:如果服务器没有从一组加密的文档和功能中学习到其他信息)
- 提出了2个满足上述安全的多关键词搜索方案,但是他们要求多关键字字段时固定的
几个假设:
- 关键词字段:如果文档是电子邮件,我们可以定义以下4个关键字字段:“From”、“To”、“Date”和“Subject”。
- 同一个关键字永远不会出现在两个不同的关键字字段中(满足这一需求的最简单方法是在关键字前添加它们所属字段的名称)
- 每个文档都有相同的关键字字段(NULL作为填充)
- Di = (Wi,1,… ,Wi,m)
- 当讨论使服务器能够验证文档在字段j中包含特定关键字的功能时,我们用Wj表示该关键字
一个多关键词搜索算法由以下5个算法组成,前4个算法是随机的

A Conjunctive Search Scheme with Constant Online Communication Cost
在这个方案中多关键词查询的Capability的大小,相对于在服务器上存储的文档总数是线性的,并且用户和服务器之间的大部分通信成本可以离线完成。由两个部分组成:
- A “proto-capability” part:它包含一个以n为线性的数据量,n是存储在服务器上的加密文档的总数。该数据独立于该功能允许的连接查询,因此可以离线传输
- A “query” part:依赖于连接查询功能允许的的常量数据。此数据必须在进行查询时在线发送。我们称这个数据量为常数,因为它并不依赖于存储在服务器上的文档的数量,而只取决于每个文档的关键字字段的数量m。m为创建索引时的常量

A Conjunctive Search Scheme with Constant Communication Cost
该协议向服务器发送能力的总通信成本在文档数量上是不变的(但在关键字字段数量上是线性的)。

5.2 Privacy-Preserving Multi-Keyword Ranked


不考虑隐藏访问模式和搜索模式,要求有关键词字典
使用了安全kNN(最邻近的k个点)算法,中内积相似度的概念来定义作者自己的前k个相关的文档
安全kNN:数据记录pi和查询向量q之间的欧氏距离用于选择k个最近的数据库记录。密钥由S(d+1维向量)和{M1,M2}((d+1)*(d+1)),其中d是每个记录pi的域的数量。首先将pi和q扩展为d+1维向量,第d+1维的值是 -0.5||p2i||和1,然后q被一个随机数r缩放为(rq,r),然后pi和q分别分裂为{p’i,p’‘i}和{q’,q’’},这里S作为分裂指示器(若S的第j位为0,{p’i[j],p’‘i[j]}和pi[j]一致,q’[j]和q’’[j]为两个随机数,但加起来和为q[j],当S的第j位为1时,qi和q的操作互换),然后{p’i,p’‘i}加密为{MT1p’i,MT2p’‘i},{q’,q’’}加密为{M-11q’和M-12q’’}。然后在查询阶段pi和q的内积为
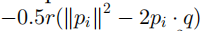
作为指标来选择k个最近的邻居数据
将安全kNN用在MRSE中:
- 将扩展去掉,就用原来的n维向量,那么最后的內积为rpi * q
- 由于S在已知的密文模型中是未知的,所以{p’i,p’‘i}和{q’,q’’}可当做d维随机串
- 那么若要求解加密的数据向量,来看下产生的线性方程的数量,{p’i,p’‘i}中,m个数据有2dm 未知数,并且{M1,M2}有 2d2个未知数,因为我们只有2dm个方程式所以解不出来,{q’,q’’}中类似也解不出来
- 因此,在没有密钥知识的情况下,数据向量和查询向量在经过这样一系列分裂和乘法等过程之后,都不能通过分析相应的密文来恢复。
MRSE_I: Privacy-Preserving Scheme in Known Ciphertext Model
我们保留这个维数扩展操作,但在每个查询向量中的扩展维数分配一个新的随机数t

 但是有缺陷,比如说document frequency,可以观察到某些统计信息,作者总结了是因为n+1位随机数被固定了的原因
但是有缺陷,比如说document frequency,可以观察到某些统计信息,作者总结了是因为n+1位随机数被固定了的原因
于是提出了将扩展1位随机数改进到扩展U位随机数
MRSE_II: Privacy-Preserving Scheme in Known Background Model

5.3 Efficient and Secure Ranked Multi-Keyword Search on Encrypted Cloud Data
基于PIR的多关键词搜索技术
文章贡献
- 为加密云数据上的关键字搜索的安全和隐私要求提供了正式的定义
- 提出了一种有效的排序多关键词搜索方案,并根据所定义的要求正式证明了该方案的安全性。
- 提出了一种排序方法,证明了能够被有效的实现,并且能返回与提交的搜索词高度相关的文档
- 实现了该系统
Index Generation
使用HMAC代替Hash函数,防止暴力破解(数据所有者使用每个文档的不同密钥,然后将密钥使用数据拥有者的私钥加密后,放在服务器)
对于每个关键词,进行HMAC函数( (HMAC: {0, 1}∗ → {0, 1}l ) ),xi是关键词wi进行HMAC函数的结果,Ii表示wi的索引,Iij ∈ GF(2),Ii = (Iir−1, . . . , Iij, . . . , Ii1, Ii0),xi是以d为基底,r位的数,即xji有dbit
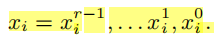
r位xi转换为rbit输出
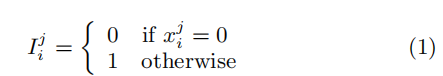
那么文档R的索引为它所包含的关键词的索引的位积运算(与运算)
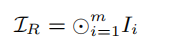
Trapdoor & Query Generation
引入了一种在用户请求数据拥有者时隐藏用户所查询的关键词的方法getBin()。
getBin():
- 将keyWord做hash,然后根据特定的几个bit分装进不同的桶(bin)里
- 桶的数量为δ,小于关键词数量,以至于每个桶中有多个关键词,可以用于模糊,δ的选择根据安全和效率需求
- 输出为{0,。。。,δ-1}
当用户需要查询n个关键词时
- 先通过getBin()获取到需要的桶id
- 发送桶id给数据拥有者,数据拥有者返回该桶中所需要的所有密钥,
- user通过所得的密钥计算出陷门(Ij1, . . . , Ijn )
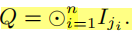
- 将Q发送给服务器
Oblivious Search on the Database
其实就是位运算
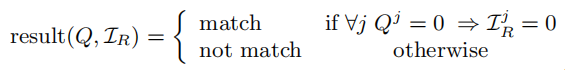
Document Retrieval
数据所有者使用不同密钥加密每个文档,然后将密钥使用数据拥有者的公钥加密后,放在服务器
用户要得到加密后的文件后,为了不向数据拥有者暴露自己取的是哪个文件,于是使用RSA盲化处理,其中y = RSAe(sk),sk是对应文件的密钥,e是数据拥有者的公钥,y是我们取回来的结果
- 用户计算 z = cey mod N,然后i发送给data owner
- z’ = zd mod N ,然后发送给用户
- sk = z’c−1 mod N得到对应的对称密钥
5.4 面向多关键字的模糊密文搜索方法
思想:使用布隆过滤器,将生成的索引与查询陷门一一做内积,取内积最大的几个文件返回。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









