







©作者 | 机器之心编辑部
来源 | 机器之心
任意长度的上下文都能 hold 住?这里有一个名为 ∞-former 的新模型。
在过去的几年里,Transformer 几乎统治了整个 NLP 领域,还跨界到计算机视觉等其他领域。但它也有弱点,比如不擅长处理较长上下文,因为计算复杂度会随着上下文长度的增长而增长,这使其难以有效建模长期记忆。为了缓解这一问题,人们提出了多种 Transformer 变体,但它们的记忆容量都是有限的,不得不抛弃较早的信息。
在一篇论文中,来自 DeepMind 等机构的研究者提出了一种名为 ∞-former 的模型,它是一种具备无限长期记忆(LTM)的 Transformer 模型,可以处理任意长度的上下文。

论文链接:
https://arxiv.org/pdf/2109.00301.pdf
通过利用连续空间注意力机制来处理长期记忆,∞-former 的注意力复杂度可以独立于上下文长度。因此,它能够借助一个固定的算力开销建模任意长度的上下文并保持「粘性记忆(sticky memories)」。
在一个综合排序任务上进行的实验证明了∞-former 能够保留来自长序列的信息。此外,研究者还进行了语言建模的实验,包括从头开始训练一个模型以及对一个预训练的语言模型进行微调,这些实验显示了无限长期记忆的优势。
不过,和其他很多 Transformer 变体的论文一样,这篇论文的标题也引发了一些吐槽:
∞-former:一种拥有无限记忆的 Transformer
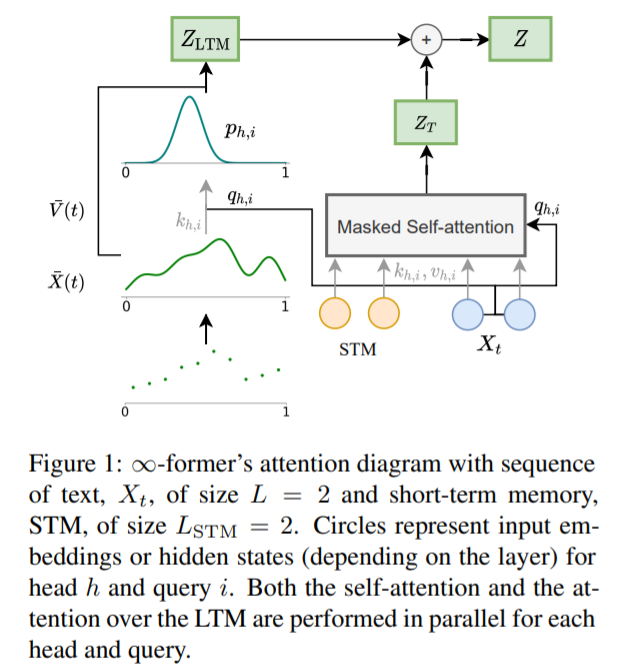
为了使模型能够处理长程上下文,研究者提出用一个连续 LTM 来扩展原始 transformer,这个 LTM 存储前面步骤的输入嵌入和隐藏状态。他们还考虑了有两种记忆的可能性:LTM 和 STM(短期记忆),类似于 transformer-XL 的记忆。∞-former 的整体架构如下图 1 所示。
为了让新模型的 LTM 达到无限的程度,研究者使用了一个连续空间注意力框架(参见《 Sparse and Continuous Attention Mechanisms 》),它在适用于记忆的信息单元数量(基函数)和这些单元的表示粒度之间进行了权衡。在这一框架中,输入序列被表征为一个连续信号,表示为径向基函数的一个线性组合。这种表征有两个显著的优势:1)上下文可以用 N 个基函数来表示,N 小于上下文中 token 的数量,降低了注意力复杂度;2)N 可以是固定的,这使得在记忆中表征无限长度的上下文成为可能(如图 2 所示),代价是损失 resolution,但不增加其注意力复杂度,O(L^2 + L × N),其中的 L 对应 transformer 序列长度。

为了缓解损失较早记忆 resolution 的问题。研究者引入了「粘性记忆」的概念,将 LTM 新信号中的较大空间归于之前记忆信号的相关区域。这是一种强制重要信息在 LTM 中持续存在的过程,使得模型可以在不损失相关信息的情况下更好地捕捉长上下文,类似于大脑中的长时程增强和突触可塑性。
实验结果
为了检验∞-former 能否建模长上下文,研究者首先针对一个综合任务进行了实验,包括把 token 按其在一个长序列中的频率进行排序,结果如下:
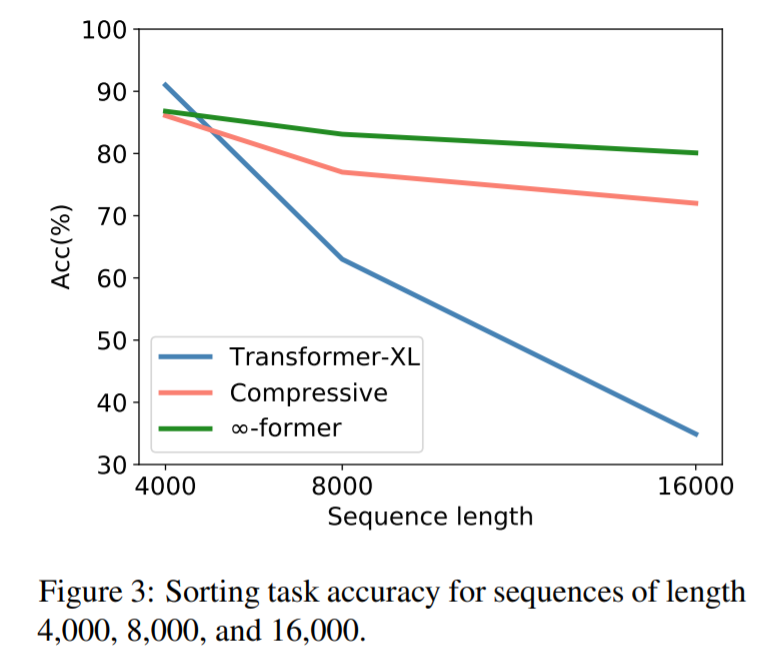
从图中可以看出,在序列长度为 4000 的时候,transformerXL 的准确率要略高于 compressive transformer 和 ∞-former。这是因为 transformerXL 几乎可以在记忆中保存整个完整序列。但随着序列长度的增加,transformerXL 的准确率迅速下降,compressive transformer 和 ∞-former 变化较小。这表明∞-former 更擅长建模长序列。
接下来,他们又进行了语言建模实验,包括:1)从头训练一个模型;2)微调一个预训练语言模型。
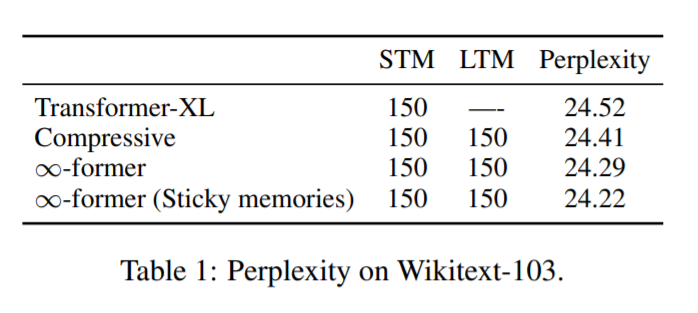
第一个语言建模实验的结果如下表 1 所示。从中可以看出,利用长期记忆扩展模型确实会带来更好的困惑度结果,而且使用粘性记忆也可以在一定程度上降低困惑度。
第二个语言建模实验的结果如下表 2 所示。该结果表明,通过简单地将长期记忆添加至 GPT-2 并进行微调,模型在 Wikitext-103 和 PG19 上的困惑度都会降低。这表明∞-former 具有多种用途:既可以从头开始训练模型,也可以用于改进预训练模型。

特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









