






 文章介绍了在Point-NN基础上提出的Seg-NN和其参数化变体Seg-PN,它们在小样本3D场景分割中表现出色,Seg-PN尤其在S3DIS和ScanNet数据集上达到SOTA性能,显著减少训练时间。Seg-NN通过非参数化编码器和低频特征提取降低资源消耗,Seg-PN通过QUEST模块缓解原型偏置问题。
文章介绍了在Point-NN基础上提出的Seg-NN和其参数化变体Seg-PN,它们在小样本3D场景分割中表现出色,Seg-PN尤其在S3DIS和ScanNet数据集上达到SOTA性能,显著减少训练时间。Seg-NN通过非参数化编码器和低频特征提取降低资源消耗,Seg-PN通过QUEST模块缓解原型偏置问题。

本文在非参数化网络 Point-NN 的基础上,提出了用于小样本 3D 场景分割的模型 Seg-NN,而进一步提出的一种参数化的变体 Seg-PN 在 S3DIS 和 ScanNet 数据集上的小样本分割任务取得了 SOTA 性能,分别超过第二名 4.19% 和 7.71%,同时将训练时间减少了 90%。

论文地址:
https://arxiv.org/pdf/2404.04050.pdf
代码地址:
https://github.com/yangyangyang127/Seg-NN

背景和介绍
为了解决数据标注成本的问题,当前 3D 场景的小样本分割任务逐渐引起了关注。现有的 3D 小样本分割方法基本上遵循元学习的策略,训练一个 3D 编码器和类别原型(class prototype)生成模块。如图 1(a)所示,这些算法通常需要以下三步:
(1)预训练:通过监督学习在“可见”类别上预训练。考虑到 3D 领域中缺乏预训练模型,这一步骤通过训练学习了一个 3D 编码器,例如 DGCNN。
(2)Episodic 训练:在“可见”类别上进行元学习形式的训练,主要微调了上一步的 3D 编码器和训练了一个分割头。
(3)测试:模型在“未见过”的类别上测试小样本分割的性能。
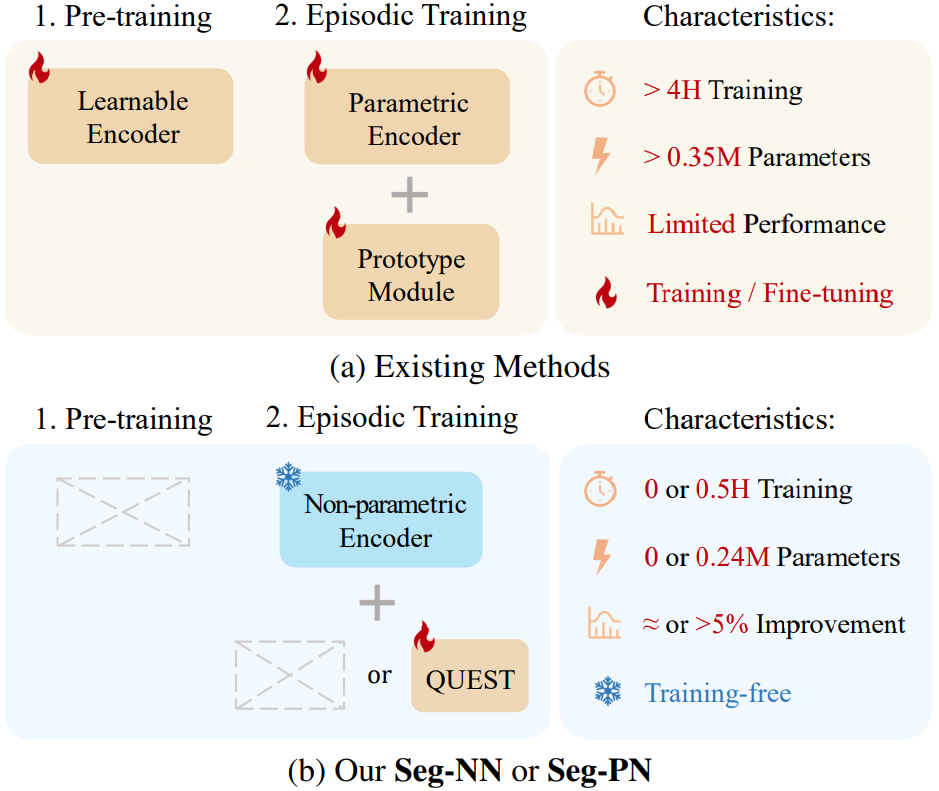
然而,该流程包含两个比较大的问题:
1)在“可见”类别上预训练和微调的 3D 编码器,在“未见过”的类别上测试必然会性能不佳,因为可见类别和未见类别存在 domain gap;
2)复杂的预训练和 Episodic 训练,会带来大量时间和资源开销。
为了解决这些问题,本论文在非参数化网络 Point-NN 的基础上,提出了用于小样本 3D 场景分割的模型 Seg-NN,Seg-NN 是一个不需要训练的 3D 编码器。如图 1(b)所示,Seg-NN 不需要训练,但性能与一些基于训练的方法相当。这种无需训练的特性简化了小样本训练流程,资源消耗最小,并缓解了由于训练集和测试集类别不同引起的 domain gap。
此外,论文基于 Seg-NN 进一步提出了一种参数化的变体 Seg-PN。Seg-PN 只需要训练一个额外的 QUEST 模块,以缓解由于数据集过小引起的原型偏置(prototype bias)问题,如图 1(b)所示。Seg-PN 在 S3DIS 和 ScanNet 数据集上的小样本分割任务取得了 SOTA 性能,分别超过第二名 4.19% 和 7.71%,同时将训练时间减少了 90%。

Seg-NN
Seg-NN 继承并改进了 Point-NN 的非参数化编码器来对 3D 场景进行编码,但做了以下修改:1)将位置和颜色信息投影到共享的表征空间并聚合;2)为了减少自然 3D 场景中的噪声和扰动,Seg-NN 只采样鲁棒的低频信号,并滤除高频噪声。提取每个点的表征后,通过相似性匹配来预测的分割 mask。
初始编码:把每个点的位置和颜色信息通过三角函数形式的位置编码映射到高维表征空间,然后将两者相加,这样可以为每个点得到一个综合的表征,记为初始编码。
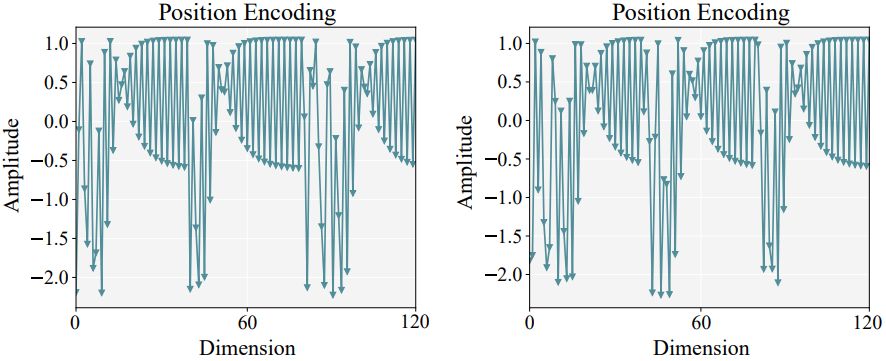
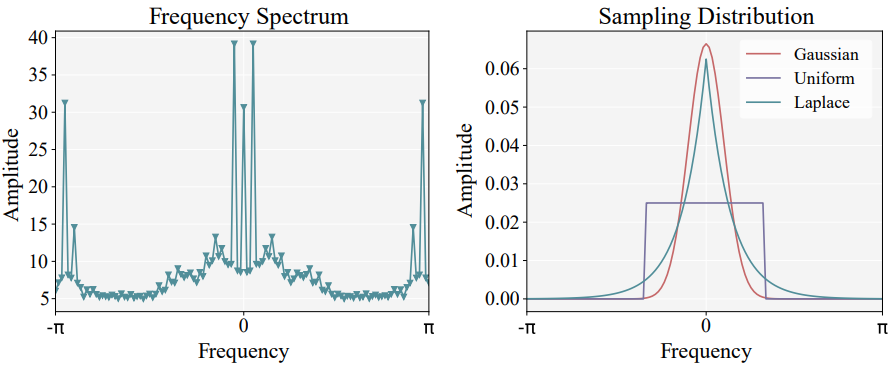
表征操纵:图 2 是两个初始编码的示例,其中假设表征的维度是 120。从中可以很容易地观察到,每个点的初始编码是带限信号。因此我们可以可视化一下每个点的频谱,得到了图 3 左边所示的频谱。从图 3 左边可以看到,点的表征的频率主要分布在低频和高频范围内。考虑到本文的目标是对自然 3D 场景进行编码,这些点通常包含噪声和扰动,而高频范围中可能存在的幅度较大的尖锐噪声可能导致表征的严重扰动。
此外,此前的很多工作已经证明神经网络倾向于优先学习低频信息,这表明低频特征是鲁棒且有分辨力的。因此,Seg-NN 依靠低频带来提取特征,并滤除高频以防止尖锐噪声产生干扰。那么如何提取低频特征呢?Seg-NN 仿照 PointNet++ 等模型设计了一个全连接层,只不过这个全连接层的权重矩阵不是通过学习得到的,而是通过随机采样一系列余弦波来作为权重矩阵。
这一系列的余弦波的频率可以从高斯分布,均匀分布,或者拉普拉斯分布中采样,如图 3 右边所示。结合图 3 的左右两幅图,可以把点的表征的低频成分提取出来。
基于相似度的分割:通过堆叠表征操纵层,我们可以最终得到每个点的表征。此后我们提取不同类别的原型表征,通过相似度匹配的方式实现测试样本的分割。
综合来看,Seg-NN 不需要任何的训练,因为它是通过手工设计的特征提取层来提取特征和编码点云的。

Seg-PN
为了进一步提高性能,文章又继续提出了一个参数化的版本 Seg-PN。Seg-PN 继承了 Seg-NN 的非参数化 3D 编码器来对点云进行编码,并且只需要学习一个轻量级的分割头 QUEST。
为什么引入 QUEST 呢?因为在小样本学习中一个明显的问题是,小规模的支撑集(support set)可能无法准确表示真实分布,这导致类别原型存在偏差。为了缓解这个问题并将类别原型从支撑集的 domain 转移到查询集的 domain,本文提出了查询-支持转移模块(QUEry-Support Transfering module)QUEST。QUEST 通过支撑集和查询集的互相关(cross-correlation)和自相关(self-correlation)减小原型偏置,详细结构如图 4 所示。
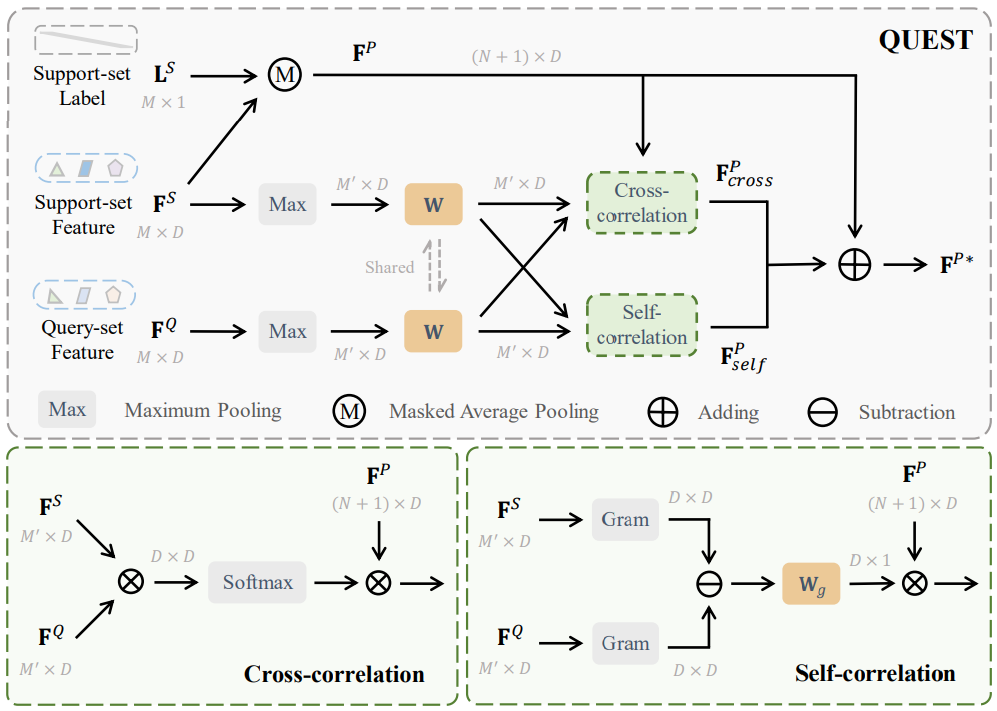
互相关: 假设 和 分别代表支撑集,查询集和类别原型的表征,那么 和 的互相关为
然后 QUEST 通过互相关来调整类别原型,
。
自相关:Seg-NN 使用了手工设计的滤波器来提取点的表征, 一个很明显的事实是不同的特征通道之间不是独立的,而是存在某些相关性,且这种相关性在支撑集和查询集的 domain 之间存在差异。因此, QUEST 探究了 和 之间的自相关的差异, 这种差异衡量了支撑集和查询集之间的 domain gap。一般来说, 特征向量的 Gram 矩阵可以表示自相关性。记支持集和查询集特征的 Gram 矩阵记为 和 ,可以分别计算如下:
此后我们通过一个可学习的权重 来提取 domain gap 并修正 ,
最后, QUEST 聚合了 和 来得到最终修正后的类别原型, 即

实验与结果
小样本分割:在 S3DIS 和 ScanNet 两个数据集上,Seg-NN 在不经过任何训练的情况下可以达到一些基于训练的方法的性能,而 Seg-PN 的性能达到了 SOTA。
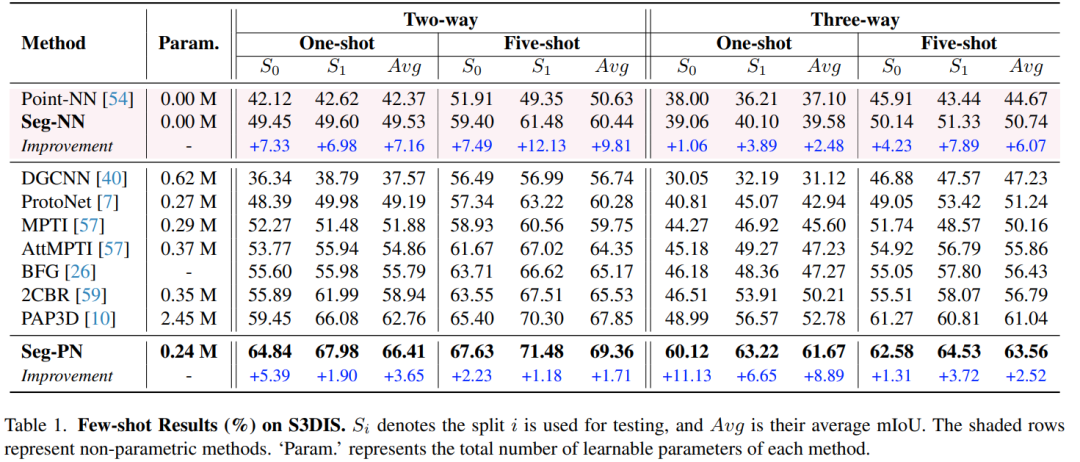
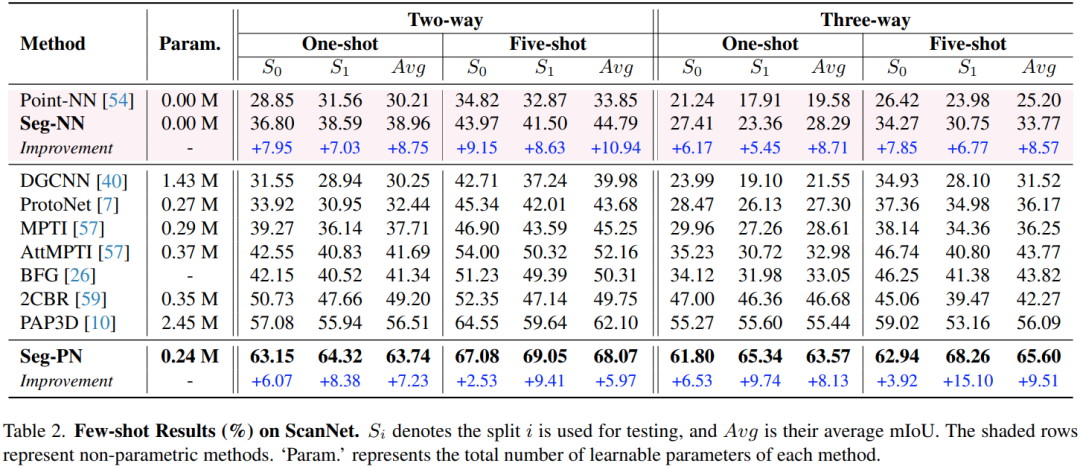
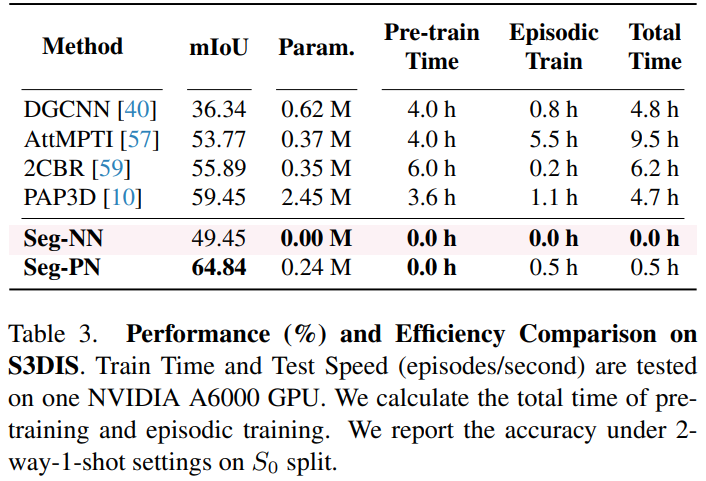
从训练时间角度来看,Seg-NN 不需要训练,而 Seg-PN 可以减少 90% 的训练时间。
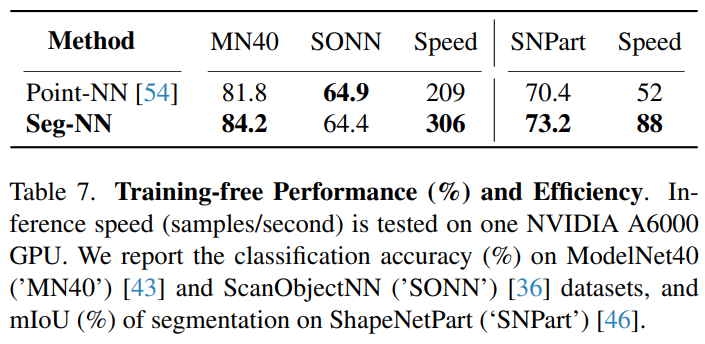
全监督分类和分割:在 ModelNet40 上,Seg-NN 的分类性能和速度超过了 Point-NN;在 ShapeNet-Part 数据集上,Seg-NN 的分割性能和速度也超过了 Point-NN。
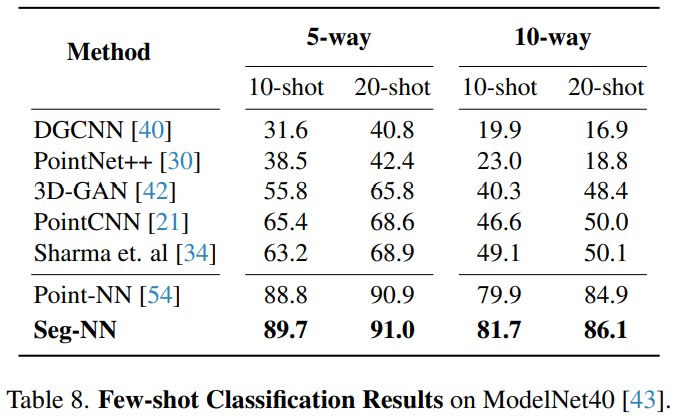
小样本分类:在 ModelNet40 上,Seg-NN 的小样本分类性能超过了当前所有的工作达到了 SOTA。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









