







最近,旷视打造了一支多模态大模型的“点读笔”-Fox,轻松实现对 8 页文档(中英混合,单栏多栏格式混合的极端场景)的交互式感知理解。
对于信息密集的 PDF 文档,Fox 支持高可控性的细粒度理解,比如在用户感兴趣区域内进行文字识别、段落翻译以及页面内部的图片内容描述等。
“一图胜千言”—— one image token >> one text token。本文中,我们进一步突破了对于文档的视觉感知理解的上限,高密度的信息被真正压缩,LVLM 真正地“看”懂图,才能真正做好、做出能用的文档多模大模型。更多细节请看我们的 paper。

论文题目:
Focus Anywhere for Fine-grained Multi-page Document Understanding
论文地址:
https://arxiv.org/abs/2405.14295
代码地址:
https://github.com/ucaslcl/Fox
项目主页:
https://ucaslcl.github.io/foxhome/

Fox的效果展示
(1)中英混合、单栏多栏混合的 8 页 PDF 文档,任意区域的 OCR:

(2)下图左侧展示了 8 页文档内跨页的 VQA。右侧展示了双栏中文页面的前景 OCR。

(3)双栏密集英文页面的前景 OCR:

(4)页面内图片描述:Fox 能给出文档内内容关联的回答(young Dual Language Learners)。当然 Fox 还支持 line-level OCR,以及对 RoI 区域的翻译、总结等。

(5)Fox 可以结合页面内文字,认识到这是一张关于 global seismic hazards 的图。此外,Fox 还支持 RoI 内的 latex 格式转换,例如下面的 table 转 latex。Fox 还支持更加灵活的颜色引导的 RoI 区域 OCR。

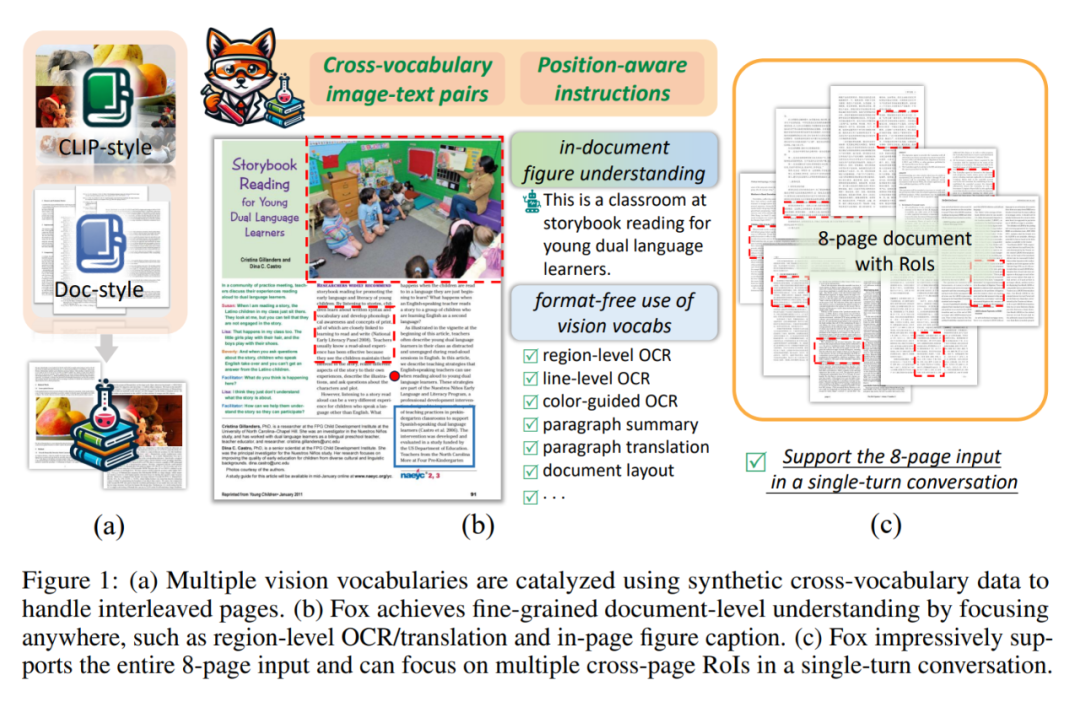
(6)对于卡通绘本,也可以哪里不会点哪里:
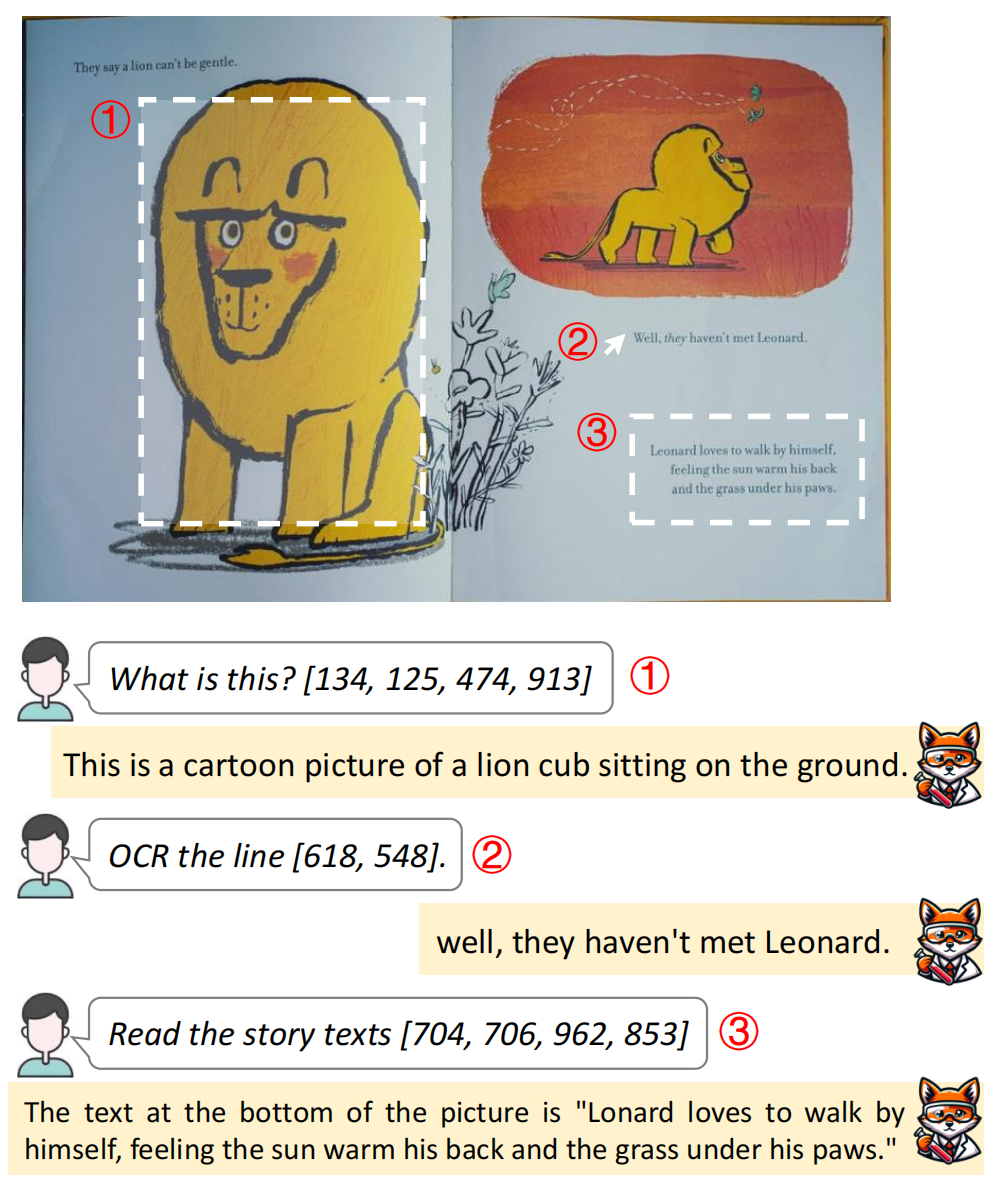
(7)电影海报和自然场景的对话问答,Fox 给出了非常有趣的答案(根据电影海报下面的文字给出了角色来源):

方法简介
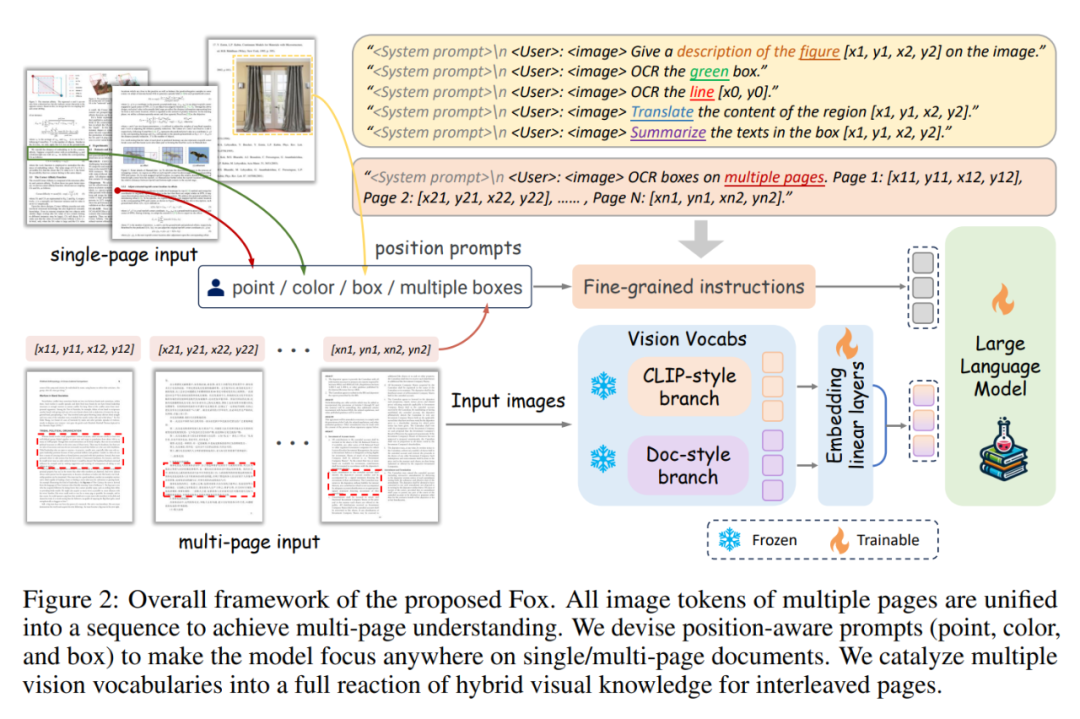
Fox 的模型结构如上图所示。Fox 支持单页/多页文档图像输入,所有图像的 image token 被统一到一个 sequence中进行多页文档理解。我们设计了基于 point、color、box 的 prompt,来实现在文档页面上聚焦任意位置。我们合成了图文交织的文档数据,来充分催化两个视觉词表,以更好地适用于实际文档应用场景。
此外,为了促进对文档细粒度理解的研究,作者还打造了一个中英双语的 benchmark,已经开源了数据和评测代码,共包含以下 9 种任务:
(1)Page-level OCR
(2)Region-level OCR
(3)Line-level OCR
(4)Color-guided OCR
(5)Region-level translation
(6)Region-level summary
(7)In-document figure caption
(8)Multi-page multi-region OCR
(9)Cross-page VQA

总结
我们呼吁更多的研究人员能关注到细粒度的单页/多页文档理解,单页的稀疏的问答任务远远不够。
真正做好多模态大模型,视觉编码器的信息压缩率(token 转化率)是非常重要的,Fox 仅探究了文档这一类应用方向。希望对大家的研究有所帮助!
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









