








事件抽取是 NLP 信息抽取中的一个重要子课题,被广泛研究。从语音中直接抽取事件是一个应用场景众多的任务,如会议纪要、讲座、采访、新闻报道等。来自哈工深的团队最近提出了一项全新的任务 SpeechEE,从语音中直接进行事件抽取。
针对这个任务,作者通过人工录制和系统合成方式构建了一个多场景、多领域、多语言、多风格、多背景的大规模语音事件抽取基准数据集;同时还构建了一个端到端语音事件抽取模型。

论文链接:
https://arxiv.org/abs/2408.09462
项目链接:
https://SpeechEE.github.io/
收录会议:
ACM MM 2024

动机介绍
事件抽取(Event Extraction,EE)是信息抽取领域内关键任务之一,旨在从自然语言中提取出结构化的事件信息,包括事件的触发词和事件论元。起初对 EE 任务的研究集中于文本领域,但随着多媒体技术的发展,文本事件抽取可以被扩展到更多信息源,例如音频。
直接从语音中提取相关事件信息具有广阔的前景,因为在许多应用场景下文稿是无法获得的,例如会议纪要、讲座、采访、新闻报道等场景,如图 1 所示。因此,作者开创性地提出了语音事件抽取(Speech Event Extraction, SpeechEE)任务,旨在自动从音频中提取出结构化的事件记录,具体包括触发词识别、事件分类、论元识别和论元角色分类。
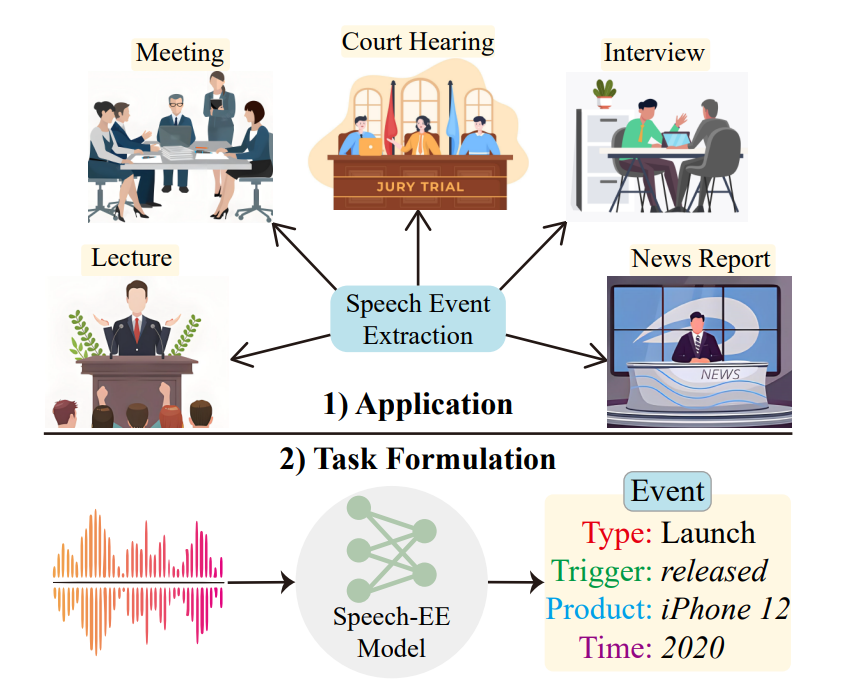
▲ 图1 语音事件抽取任务及其应用场景
一种最直接的方式是采用流水线方法,即首先通过语音识别技术(Automatic Speech Recognition,ASR)将音频转换为文稿,然后使用现有的文本事件抽取技术进行事件抽取。
但是这种流水线方法存在两大问题:首先此方法不可避免地存在误差传播问题,最终结果严重依赖于中间文稿的准确性;此外 SpeechEE 和 ASR 的存在本质区别:ASR 需要识别出音频中包含的全部文本信息,旨在降低词错误率,而 SpeechEE 任务只需关注音频中事件有关信息,如触发词和事件论元,旨在正确抽取相关的事件记录,因此模型的优化目标也不尽相同。
除此之外,现有的文本事件抽取方法不能解决 SpeechEE 任务所带来的新的挑战。首先与文本不同,语音没有清晰边界,准确地识别包含触发词和事件论元的语音片段存在困难。其次,在实际场景中语音可能包含噪声,直接影响语音事件抽取的性能。
此外,语音信号比文本信号更长,增大了对 SpeechEE 建模的困难性。最后,语音存在模糊性,如同音和近音现象容易导致实体识别错误,而事件论元中往往存在不常见的人名、地名等,也增大了语音事件抽取任务的难度。
因此,作者提出了一种端到端的语音事件抽取模型(E2E SpeechEE),采用生成式的编码器-解码器 Transformer 架构,从而避免了对语音边界精确划分的问题;在编码器端结合对比学习技术,更好进行事件表征学习,提升模型从语音表征中识别出事件语义的能力;在解码器端引入检索增强模块,利用外部知识实现更加灵活的解码策略;在编码器和解码器之间引入长度缩减单元缓解语音和文本模态之间的长度不匹配问题。
为了评估所提出模型的性能表现,作者构建了一个多场景、多语言、多领域、多风格的大规模语音事件抽取基准数据集,既包括人工录制语音,也包含系统合成语音。并通过大量实验证明了 E2E SpeechEE 模型的优越性。

数据集构建
作者为 SpeechEE 任务提出了一个全新的大规模基准数据集,数据来源自 8 个有着严格标准和广泛使用的经典文本事件抽取数据集。通过人工录制和系统合成两种方法构建了一个多场景、多领域、多语言、多风格、多背景的大规模高质量基准数据集,如图 2 所示。
多场景:包含了句子级事件抽取、文档级事件抽取和对话级事件抽取,囊括了三种不同的任务场景。
多领域:数据内容涉及新闻、医药、网络安全、生物科学、电影等多个领域。
多语言:涉及 2 种语言,包括六个英文子集和两个中文子集。
多风格:包含不同年龄、不同性别、不同音色和不同语调的多种说话人风格。
多背景:语音设置不仅包含安静场景,还包括十种不同的噪音背景以更好地拟合实际应用中的语音事件抽取场景。
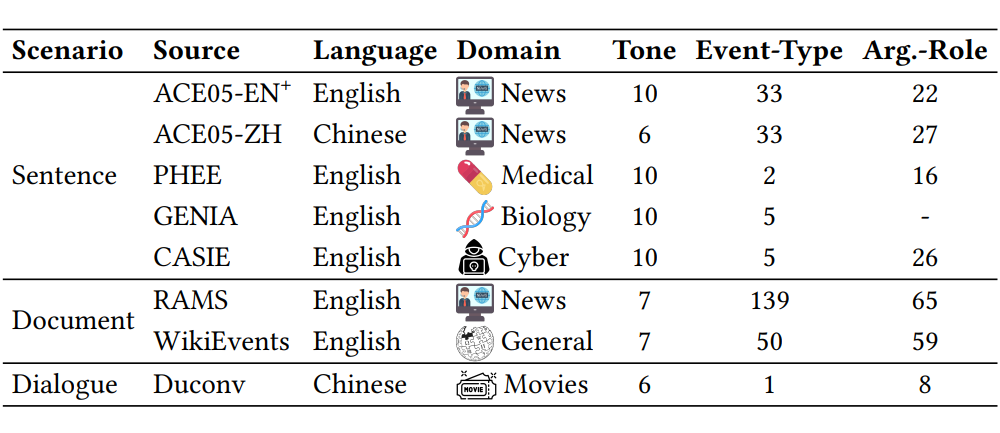
▲ 图2 SpeechEE 基准数据集概览
由于人工录制语音数据需要严苛的环境限制和高额的成本,除了人工录制语音数据集,作者还利用现有的高质量开源语音合成框架(Text-to-Speech,TTS)如 Bark,edge-tts 对训练集进行数据增强,即基于文本事件抽取数据来合成语音数据。
最后,对于人工录制语音和系统合成语音进行了后处理筛选和交叉检验以进行严格的质量控制,最终得到了大规模的 SpeechEE 基准数据集,如图 3 所示,该基准数据集为 SpeechEE 模型性能评估提供了有力支持。

▲ 图3 SpeechEE 基准数据集规模统计

模型框架
3.1 流水线方法
作者为 SpeechEE 任务提出了两种模型框架:流水线方法(pipeline SpeechEE)和端到端方法(E2E SpeechEE)。Pipeline 方法将语音事件抽取任务划分为两个子任务:ASR 和文本事件抽取。
作者提出一种直接可行的实现方式:使用高性能的 Whisper 模型作为 ASR 模型将音频转换为对应文稿,然后使用从序列到结构的 Text2Event 方法作为文本事件抽取模型,将这两个表现良好的现有模型级联形成两阶段的流水线模型,如图 4(a)所示。
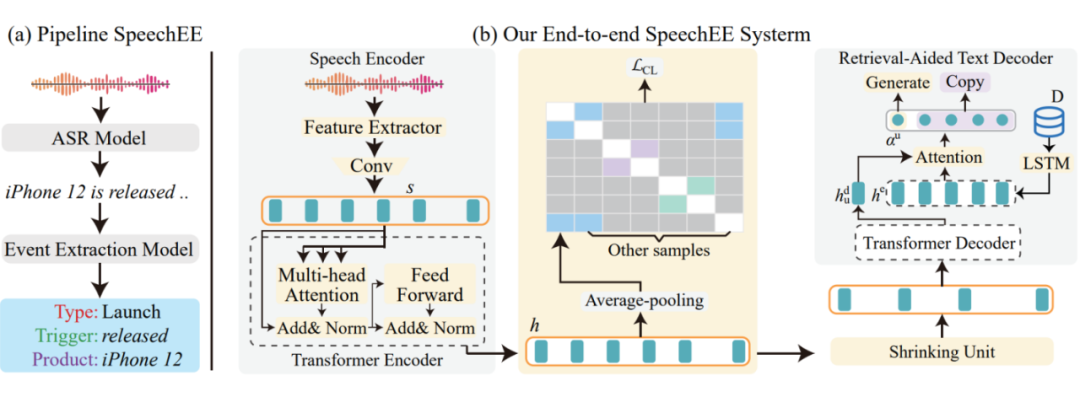
▲ 图4 Pipeline 方法和 E2E 方法模型架构图
3.2 端到端方法
如前文所述,流水线方法不可避免存在误差传播等问题,因此作者创新性地提出了 E2E SpeechEE 模型,如图 4(b) 所示,整体上 E2E SpeechEE 采用编码器-解码器架构,由三个主要组件构成:音频编码器、长度缩减单元和检索增强的文本解码器。
音频编码器:音频编码器采用类似 Whisper 的架构,由声学特征提取器和 Transformer 编码器构成。输入音频经过特征提取得到对数梅尔频谱,卷积处理后通过 Transformer 编码器获得音频表征向量。
然而音频编码器虽然通过 ASR 预训练具备有捕获音频特征的能力,但是不能对 SpeechEE 任务中的事件相关特征进行直接建模,因此作者设计了对比学习策略,根据事件类型划分正负样本,使具有相同事件类型的语音表征相似化,不同事件类型的语音表征差异化,从而更好地进行表征学习,捕获事件相关语义特征。
长度缩减单元:通常情况下,语音序列比对应转译后的文本序列更长,在事件抽取任务中,语音信息冗余的现象则更为明显。因此作者在编码器和解码器之间设计了一个长度缩减单元,通过投影和下采样策略有效缓解了不同模态之间序列长度不匹配的问题。
检索增强的文本解码器:经过长度缩减处理后,采用预训练的文本解码器对结构化事件记录进行逐词解码。但是,由于语音存在模糊性,如同音、近音现象,精确地解码出实体元素,尤其是一些模型在训练阶段罕见生僻的人名、地名存在较大困难。因此作者提出在解码器端使用检索机制,引入外部知识而构建实体字典,通过注意力机制计算检索概率,辅助解码器灵活地决定直接生成结果或是从实体字典中输出检索结果。

实验分析
4.1 主实验结果分析
作者在句子级、文档级、对话级三种不同场景下,对流水线方法和端到端方法分别进行了实验,相应的实验结果如图 5,图 6,图 7 所示。根据实验结果可知:
1)E2E 方法在三种不同场景下的性能均超过流水线方法,证明了 E2E SpeechEE 模型的优越性;
2)不同的预训练语言模型对 SpeechEE 的性能存在影响,在多数情况下 T5 的表现优于 BART 模型;
3)对比事件抽取的四个评价指标,可以发现事件论元的识别和分类相比触发词的识别与分类存在更大挑战。
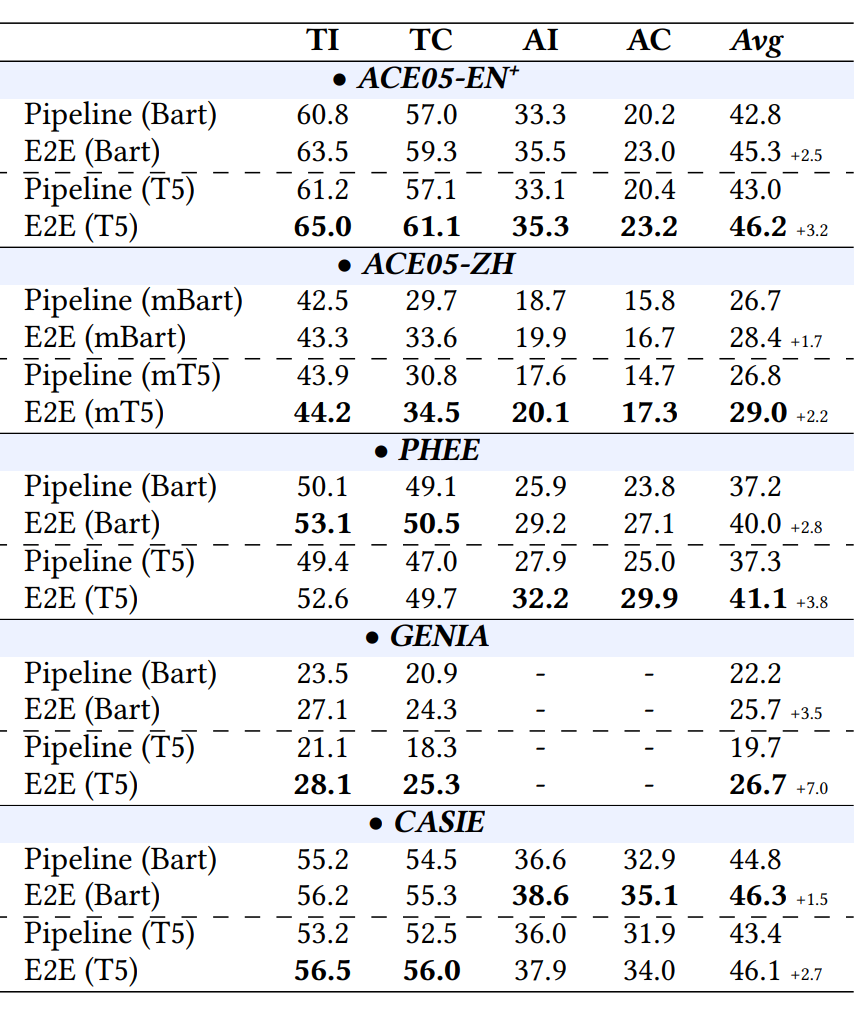
▲ 图5 句子级 SpeechEE 实验结果
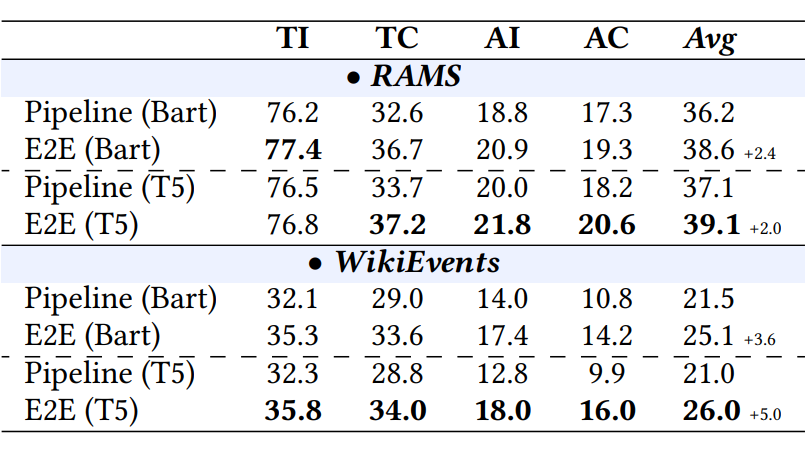
▲ 图6 文档级 SpeechEE 实验结果
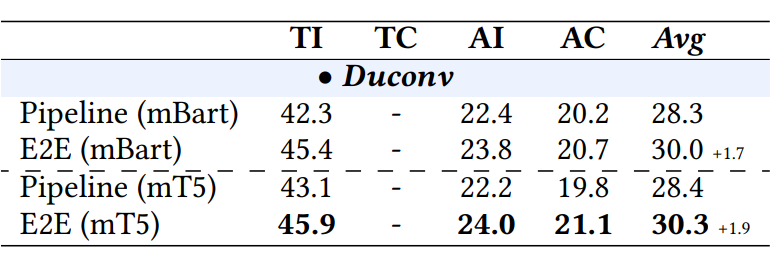
▲ 图7 对话级 SpeechEE 实验结果
4.2 消融实验结果分析
为了探究对比学习策略(CL),长度缩减单元(SU)和实体字典检索增强(ED)三个不同模块为 E2E SpeechEE 模型带来的影响,作者在 PHEE 子数据集上进行了消融实验,实验结果如图 8 所示,可以发现去除三者中任意一个模块均造成了整体模型性能的下降,证明了这三个策略的不可或缺性。

▲ 图8 E2E SpeechEE 模型消融实验结果
4.3 语音事件抽取vs文本音事件抽取
此外,作者还通过定量实验探究了文本事件抽取和语音事件抽取的性能差距。在保证相同预训练语言模型,同样采用生成式端到端方法的基准下(编码器存在输入信号差异),图 9 展示了在各个数据集上语音事件抽取和文本事件抽取的性能差异。SpeechEE 的性能显著低于 TextEE 性能,强调了 SpeechEE 的研究意义及其所面临的巨大挑战。
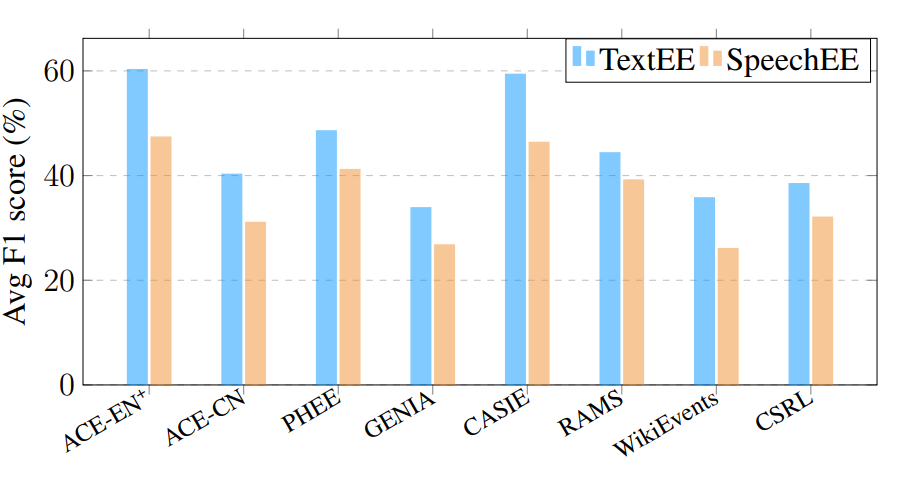
▲ 图9 语音事件抽取和文本音事件抽取性能差异
4.4 合成语音数据的影响
为了探究使用系统合成语音进行数据增强方法的影响,作者使用 E2E SpeechEE 模型在三种不同的数据集上进行了模型训练:1)只包含人工录制语音,2)只包含系统合成语音,3)二者混合语音,得到了如图 10 所示的实验结果。
在 ACE05-EN+,ACE05-ZH 和 PHEE 数据集上,人工录制语音数据的效果明显优于系统合成语音数据;而对于其他数据集,合成语音却取得了更优的性能。原因在于后几个数据集的人工录制语音规模相比合成语音显著更少,数据稀缺问题导致模型不能从训练数据中有效学习 SpeechEE 任务的特征模式。
除此之外,对比设置1)与设置 3)可以发现:混合语音训练数据表现出更高的性能,证明了采用合成语音进行数据增强在数据稀缺情况下的有效性。
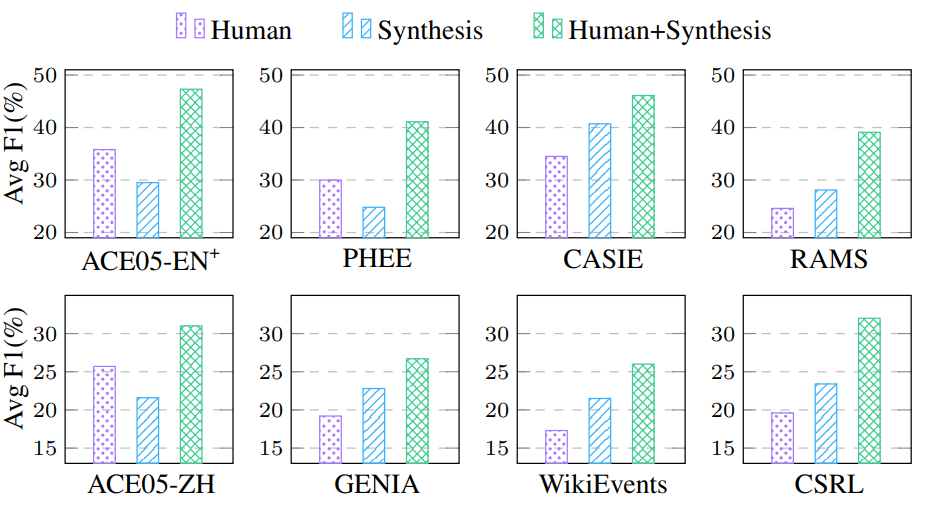
▲ 图10 合成语音数据的影响
4.5 案例分析
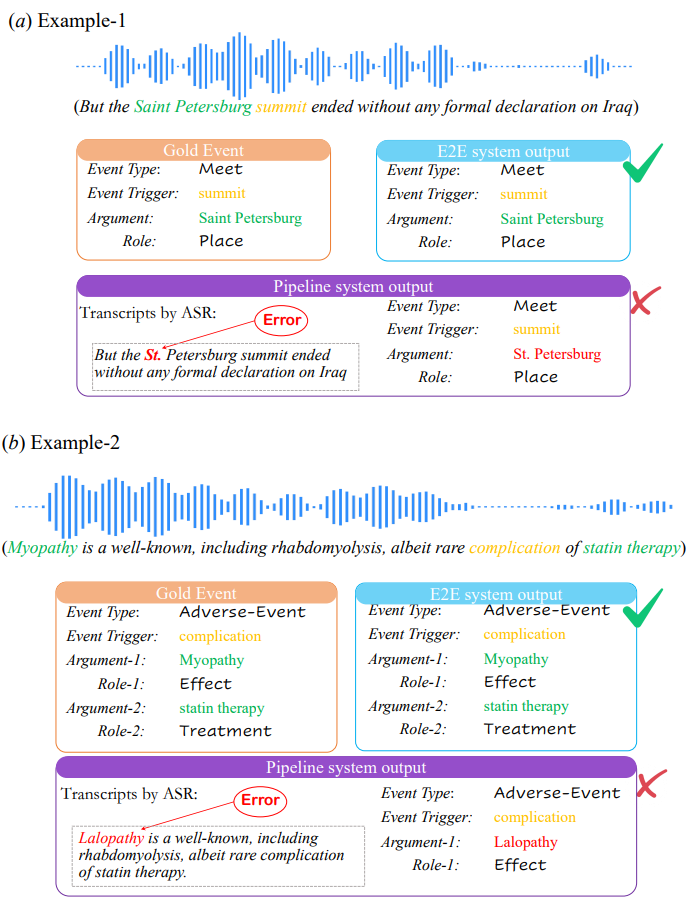
为了直观地比较 pipeline 方法和 E2E 方法在 SpeechEE 上的表现,作者进行了案例分析,如图 11 所示,在两个案例中,E2E 方法均产生了和金标相同的抽取结果,而 Pipeline 方法由于误差传播问题和近音词问题出现了和金标不一致的结果。
在示例 1 中 pipeline 方法在 ASR 阶段将音频中的 “Saint Petersburg” 识别为了 “St. Petersburg”,由于中间误差传播导致后续事件抽取阶段产生了不一致的结果。而在示例 2 中,由于发音相近,pipeline 方法在 ASR 阶段错误地将单词 “Myopathy” 识别为了单词 “Lalopathy”,导致事件论元抽取错误,并且没能抽取出全部的事件论元信息。
▲ 图11 案例分析

总结与未来展望
本文提出了 SpeechEE 新任务,将传统的事件抽取从文本扩展到语音模态,并开创性地构建了一个大规模的语音事件抽取基准数据集,为评估 SpeechEE 模型提供了有力支持。
此外,为了解决 SpeechEE 任务,本文介绍了一种端到端语音事件抽取模型,并通过大量实验证明了该模型对比简单流水线模型的优越性。最后,本文为将来的语音事件抽取研究提供了以下研究方向:
消除噪音影响:真实场景下的语音不可避免包含背景噪音和各种类型的干扰,如何对噪声进行处理从而提高 SpeechEE 的性能是一个重要的研究问题。
识别语音中的隐式元素:通常事件信息在语音中存在明显的对应片段,而有些事件元素作为背景线索暗含在音频之中,因此识别隐式事件元素是 SpeechEE 任务的一大挑战。
跨语言识别:本文所构建的数据集包含多种语言,却不是平行语料,如何进行跨语言事件抽取,以及如何更好地利用语音中的语言无关特征是更有趣的研究方向。
弱监督/无监督 SpeechEE:随着多模态大模型的发展,许多模型展示出强大的 zero-shot 能力,在数据稀缺情况下弱监督/无监督 SpeechEE 具有更加广阔的研究潜力。
新的评价指标:目前的 SpeechEE 任务采用和文本事件抽取相同的严格匹配评价策略,但是由于 SpeechEE 没有明确的文稿信息,严格匹配往往低估了 SpeechEE 模型的性能。因此我们期待一种更加公平的语义匹配评价策略来更好地契合 SpeechEE 任务。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









