








引言:大模型时代,我们怎么学术冲浪
在大模型浪潮方兴未艾的当下,算法从业者们每天打开 Google Scholar、Arxiv 等学术网站和各类自媒体平台时,迎接他们的都是雪片般飞来的新论文和相关的解读、讨论。据统计,2023 年发表的学术论文中含有“大语言模型”关键词者高达 20900 篇,相比 2022 年几乎翻了 20 倍 [1]。
面对这样的信息过载,有一定知识积累的研究者们要跟住最新进展尚不轻松,刚开始钻研 AI 知识的大学生更是常常抓不住头绪,有时面对冗长的论文找不到其核心贡献,有时想更深入了解文章提到的某项技术却不知从何学起,学习效率急需提高。
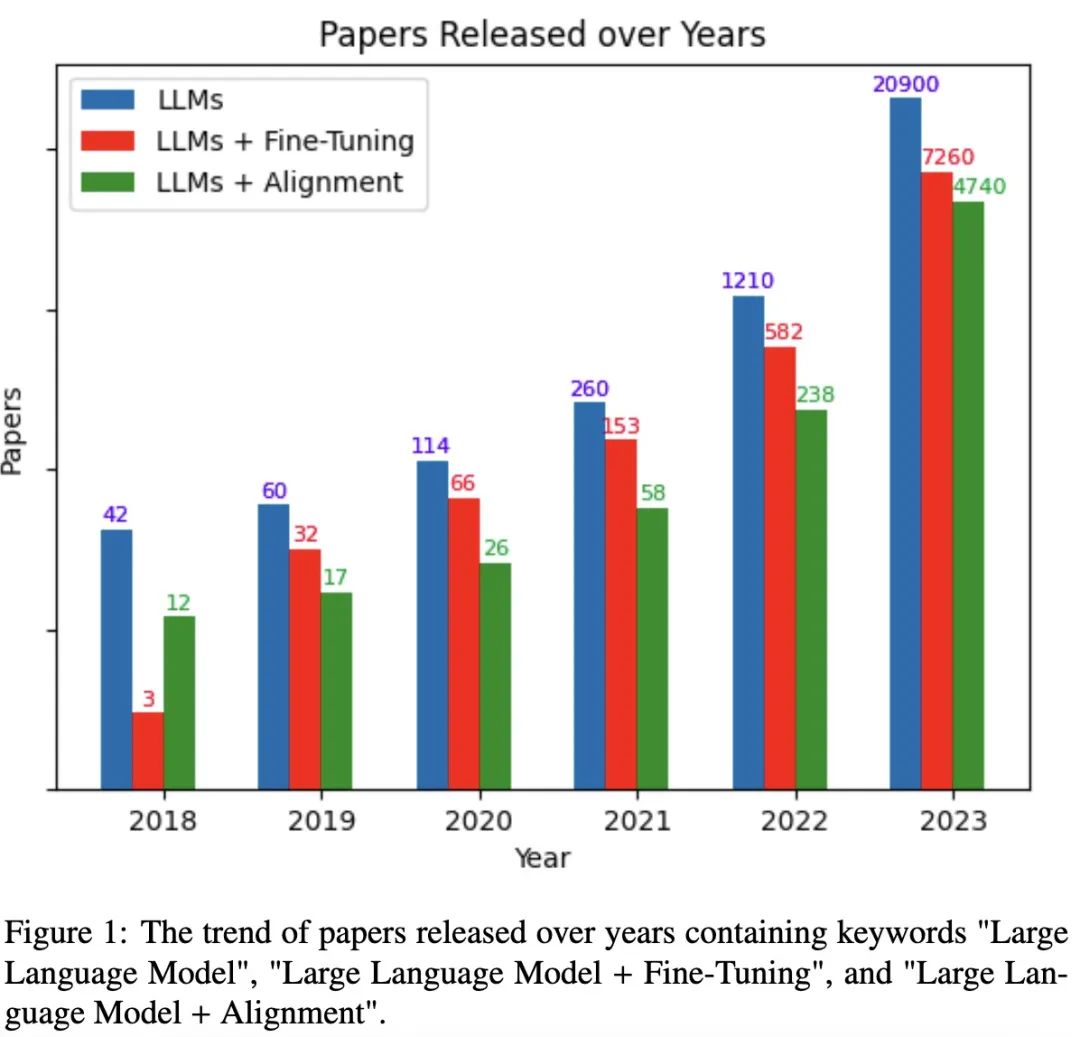
▲ 关键词中含有“大模型”、“大模型微调”、“大模型对齐”的论文数目逐年增长情况。图片引自综述论文【1】。
作为一名 AI 领域的知识分享博主,我每周都会更新好几篇前沿论文笔记,来跟上技术发展的浪潮,并和来自四面八方的同行们交流讨论。在时间相对自由的学生时代,技术写作的时间负担还不显著;毕业之后,要在工作之余筛选、精读文献,再认真码字排版输出,对我来说也是个不小的挑战。
好在用工具提升效率是 AI 研究者们的良好习惯,既然大模型正在改变千行百业,paper reading 这项日常工作是不是也可以找个大模型搭子来分担呢?AI 论文专业性强、时效性高,用哪家的大模型靠谱呢?
自从有了一位靠谱的搭子,我日常读论文和写笔记分享的效率蹭蹭提高,就连快 100 页的 Lllama-3 技术报告 [2],都能在十分钟内抓住重点、产出精炼的笔记。这位帮我高效学术冲浪的 AI 搭子就是:腾讯元宝。

要点速览,高效产出笔记

论文地址:
https://arxiv.org/pdf/2407.21783
项目网页:
https://llama.meta.com/
以 Meta 的 Llama-3 技术报告《The Llama 3 Herd of Models》(长达 92 页)为例,从 Arxiv 上下载 pdf 文件,在元宝的界面上点击上传,告诉它自己解读论文的需求,元宝就会开始处理文档,帮助我们去芜存菁,高效学习、快速分享。
这里分享一个我日常读大模型论文用的 prompt,要求输出摘要、模型结构、训练数据、训练目标、实验评测等几个方面的内容,既能抓住技术要点,又能快速产出技术笔记惠及他人,培养自身的技术影响力。
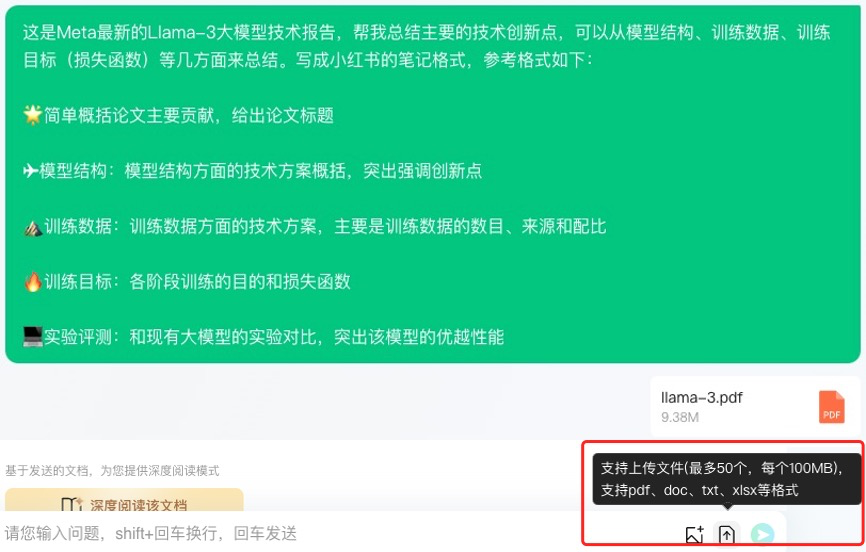
即使这篇论文这么长、干货这么多,元宝也能在几秒内高效梳理论文内容,生成了一版十分精炼的笔记,基本满足了论文速递型笔记写作的要求:

从研究者的角度来看,Llama-3 最值得关心的技术点有两个,元宝产出的笔记不长,却精准涵盖了它们:
模型结构方面:分组查询注意力GQA;
Post-Training 方面:SFT 阶段之后使用了 DPO 做对齐,计算 DPO 损失时对格式 tokens 进行掩码,并加入负对数似然正则项目以稳定训练,最后使用模型平均技术得到最终模型。

▲ 原文中关于Post-training的内容,元宝在产出的笔记里进行了精准概括。
当然,挑搭子也要货比三家。我也试过用同样的 prompt,让文心一言和最近很火的 Kimi 帮忙读这篇文章。文心一言面对近百页的论文直接提示输入过长,无法给出有效的回应;Kimi 产出的笔记虽然读起来也挺流畅,但谈到 Post-training 时只泛泛地提到了 SFT、拒绝采样和 DPO,没有体现 DPO 中的两项稳定训练的具体技术和最后使用的模型平均技术。

▲ 文心一言提示上传文件过长,无法给出有效回应。

▲ Kimi生成的笔记没有体现DPO的具体技术和Llama-3用到的模型平均技术。
除了能生成精炼的简版笔记之外,元宝还贴心地专门为文档对话场景设计了“深度阅读”功能,用户只需点击“深度阅读该文档”,稍待片刻,元宝就会根据原文生成内容详尽、图文并茂的中文精读报告和学术海报,既降低了阅读者的理解成本,又为想要分享论文内容的同学省却了不少码字、排版、制图的功夫:

▲ 元宝为Llama-3技术报告生成精读文档,详尽解读原文的技术细节和实验结果,读者还可以在同一界面查看原文进行对照
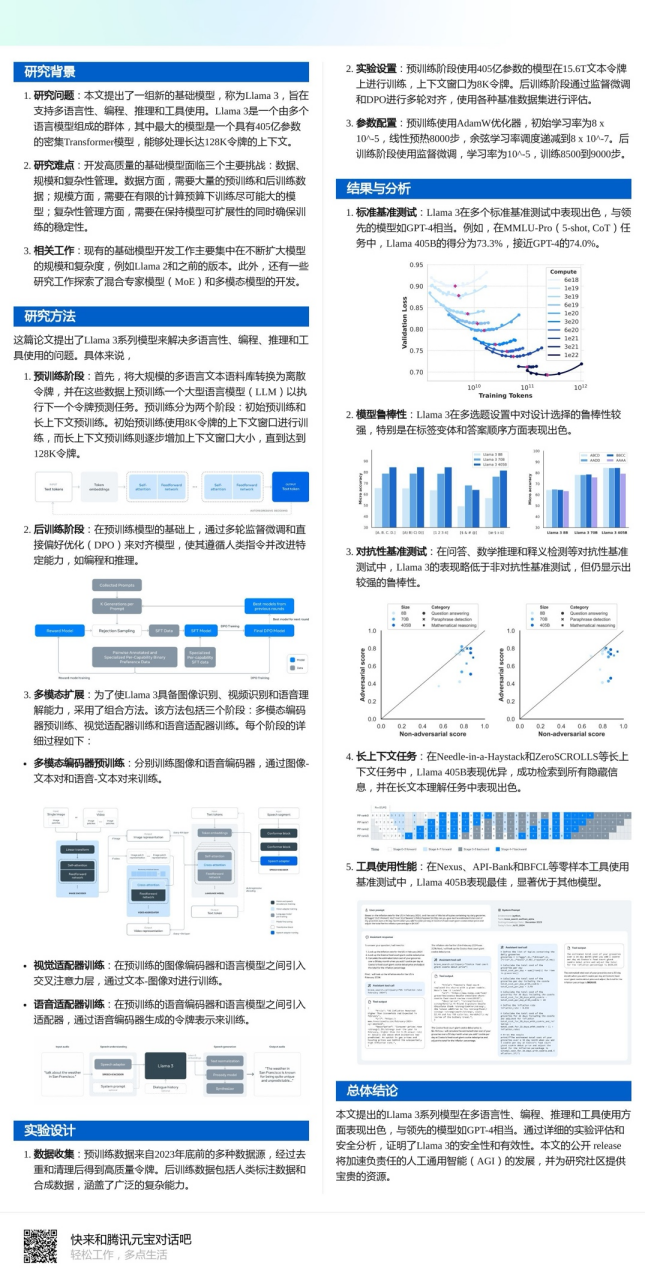
▲ 元宝为Llama-3技术报告生成的学术海报
由此可见,元宝很擅长将长文按使用者要求的格式进行系统梳理、产出笔记,还能去芜存菁、抓住论文的核心创新点体现在笔记中,对信息过载时代的AI学习者们来说堪称得力助手。
论文第一遍读完了,还想深入挖挖自己不熟悉的具体技术?别急,元宝还有很多能力等你挖掘,且看下文。
Prompt 设计:这是 xxx 大模型论文,帮我总结主要的技术创新点,可以从模型结构、训练数据、训练目标(损失函数)等几方面来总结。写成小红书的笔记格式,参考格式如下:
🌟简单概括论文主要贡献,给出论文标题
✈️模型结构:模型结构方面的技术方案概括,突出强调创新点
⛰️训练数据:训练数据方面的技术方案,主要是训练数据的数目、来源和配比
🔥训练目标:各阶段训练的目的和损失函数
💻实验评测:和现有大模型的实验对比,突出该模型的优越性能

细节追问,轻松学习重点
论文简读主要起到让读者知道有哪些新的技术亮点值得学习的作用,要吃透这些技术亮点,可以追问元宝具体的技术细节和动机,有助于扎实地理解新技术,以备今后使用。例如,如果我们想深入了解 Llama-3 的 DPO 训练用到的两个正则化损失,可以直接复制元宝在简读笔记中输出的技术名称,追问它们的细节和设计动机:

如果想把新论文和自己熟悉的前置工作进行纵向对比,以看清技术的演进趋势,可以继续追问元宝新论文和某篇老论文的异同点,元宝会继续联网搜索老论文相关的内容作为参考,整理输出详细的异同点和演进趋势。
例如,我追问了 Llama-3 和 Llama-2 在模型结构方面的异同点,元宝进行了系统的梳理,在 GQA 方面精准地答出 Llama-3 对所有尺寸模型使用了 GQA,而 Llama-2 只有大尺寸模型用了 GQA。

我也尝试让 Kimi 回答了 Llama 二代和三代在模型结构方面的差异,Kimi 的回答出现了纰漏:它似乎认为 GQA 是 Llama-3 新引入的,没有提及 Llama-2 也用了 GQA。

这可能和 Kimi 的产品在用户上传文件后即强制关闭联网模式有关:失去了联网得到的信息支持,模型只能靠自身参数中存储的和老论文相关的知识进行新老论文的对比,容易产生幻觉。相比之下,元宝在用户上传文件后的对话中一直支持联网模型,在分析技术演进趋势时精准不少。

由此可见,腾讯元宝既能究根问底,深挖当前论文的技术创新点,又能旁征博引,分析技术演进趋势,对 AI 学习的深度和广度都益处多多。看完论文有啥问题,追问元宝就对了~
Prompt 设计:
详细讲讲 xx 技术的细节和目的 xx 和 yy 在 zz 方面有哪些异同?xx 主要做了哪些改进?

想你所想,日常贴心助手
除了基本的摘要和对话追问功能外,在日常读论文时,我们还有许许多多的需求:
问题提炼:从论文中能不能提炼一些关键的技术问题,作为写作分享的切入点?
延伸学习:怎么快速找到近期的其他相关论文,进行延伸阅读?
封面生成:网上/组会分享的时候想要一张炫酷的笔记封面,只能搜图或者打开 Midjourney?
元宝在体察用户需求方面也是大模型产品中的翘楚,在这些方面都能让用户按个键或者提个问就一站式解决问题,无需打开其他网站和工具。
问题提炼方面,元宝每进行一轮对话都会预测用户可能想追问的问题,用户只需轻轻一点就能得到详尽回答。例如,写完 Llama-3 技术报告的简读笔记,元宝猜测许多用户都会关心训练数据的来源和开源生态如何:

如果用户想深入了解训练数据的情况,元宝瞬间就能给出详实的答案,还附带推荐互联网上相关的优质内容:
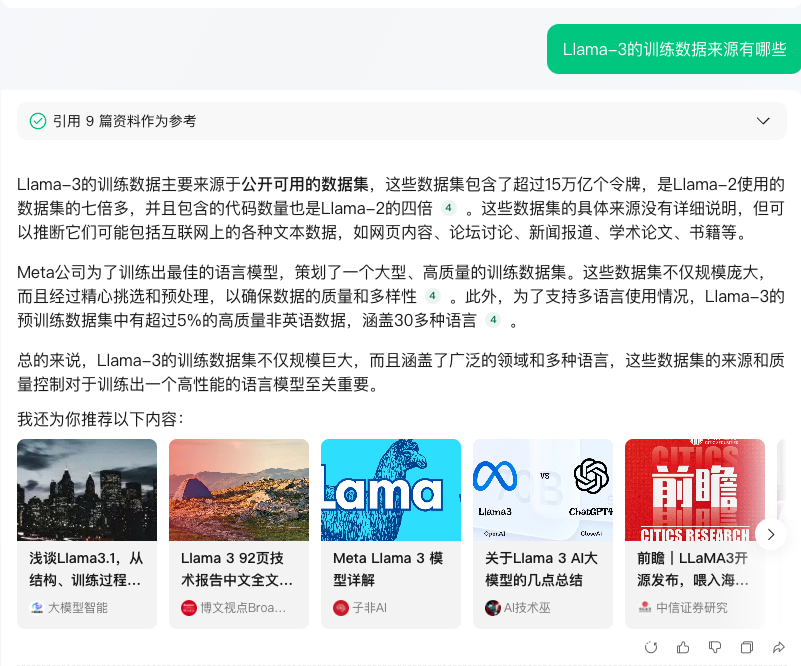
延伸学习方面,如果你想快速了解某个细分方面的新进展,比如大模型 DPO 的改进,元宝也会综合网上的内容进行梳理,以便用户延伸学习。由下图可见,元宝列出的相关工作篇篇都有链接指向原文,毫无幻觉的问题。

相比之下,Kimi 在推荐延伸阅读文献时存在严重的幻觉问题,而文心只是复述了一遍 DPO 原论文的标题和主要内容,并给出了几个很宽泛的改进方向,无法让使用者真正找到有用的相关论文。


▲ Kimi的文献推荐存在严重的幻觉问题

▲ 文心只提了DPO原文和宽泛的改进方向,并未真正推荐相关论文
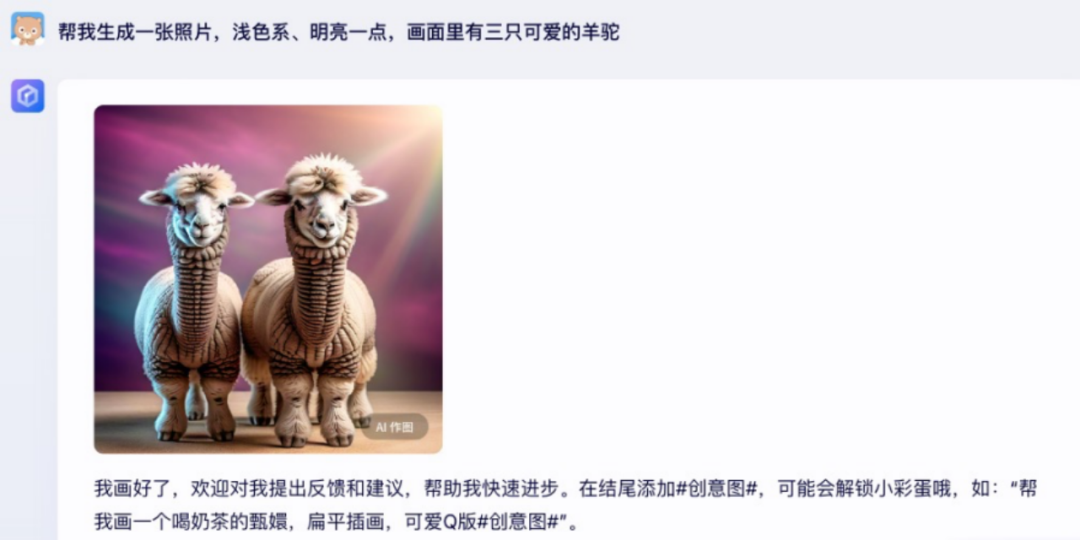
封面生成方面,元宝集成了文生图能力,只需在对话中输入想要的图片内容,用户就能得到精美的图片,再也不用费神找图做封面。例如,如果我们想用三只羊驼(Llama)做我们 Llama-3 笔记的封面,告诉元宝自己想要的色系和风格,就能快速得到可用的封面:

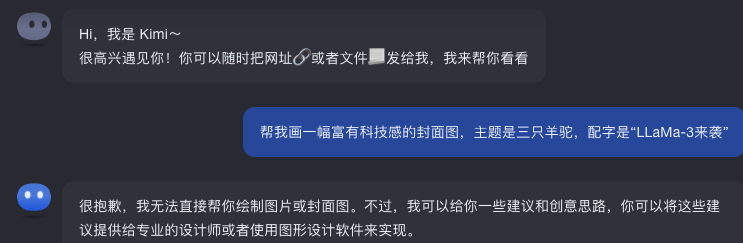
相比之下,Kimi 并不支持文生图,文心一言生成的图片风格、羊驼数目都和我们在 prompt 里的要求不符:

用好AI工具,为学术冲浪提效
在技术飞速迭代、知识日新月异的大模型时代,人人都有一颗紧跟前沿的弄潮之心,然而高度过载的学术信息却让大家常常不知从何读起,空费了不少同学的勤奋与热情。还好,基于大模型的 AI 助手可以从繁琐的信息检索中解放人力,助力我们在读论文、学算法时快速找到重点亮点、形成知识体系,善用这样的效率工具才能事半功倍。
从本文展示的 Llama-3 论文解读评测结果可以看出,腾讯元宝既能帮我们高效精准地总结论文、深挖技术亮点,又拥有问题提炼、文献推荐、封面生成等解决用户痛点的众多技能,和竞品相比在论文解读的精度和深度上都十分出色。目前腾讯元宝已经上线 PC Web、微信小程序、APP 三端服务,本文提及的功能均可无限制免费使用。
▲ 微信搜索“腾讯元宝”小程序,paper reading不再是难事

参考文献
[1] A Comprehensive Overview of Large Language Models https://arxiv.org/pdf/2307.06435
[2] The Llama 3 Herd of Models https://arxiv.org/pdf/2407.21783
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









