







©作者 | 金川杨、舒天民
单位 | Johns Hopkins University
心智能力(Theory of Mind,ToM),即理解人们思维的能力,是开发具有类人社会智能的 AI 模型的重要基础。
近日,来自 JHU, NYU, MIT, Harvard 等机构的研究团队开创了第一个多模态的 ToM 测试基准,发现现有的多模态模型和 LLM 都表现存在系统性缺陷,同时他们提出了一种有效的新方法。在刚结束的 ACL 2024 会议中,这篇论文获得杰出论文奖。

论文标题:
MMToM-QA: Multimodal Theory of Mind Question Answering
论文链接:
https://arxiv.org/abs/2401.08743
代码链接:
https://github.com/chuanyangjin/MMToM-QA
网站链接
https://chuanyangjin.com/mmtom-qa

MMToM-QA:第一个多模态的ToM benchmark
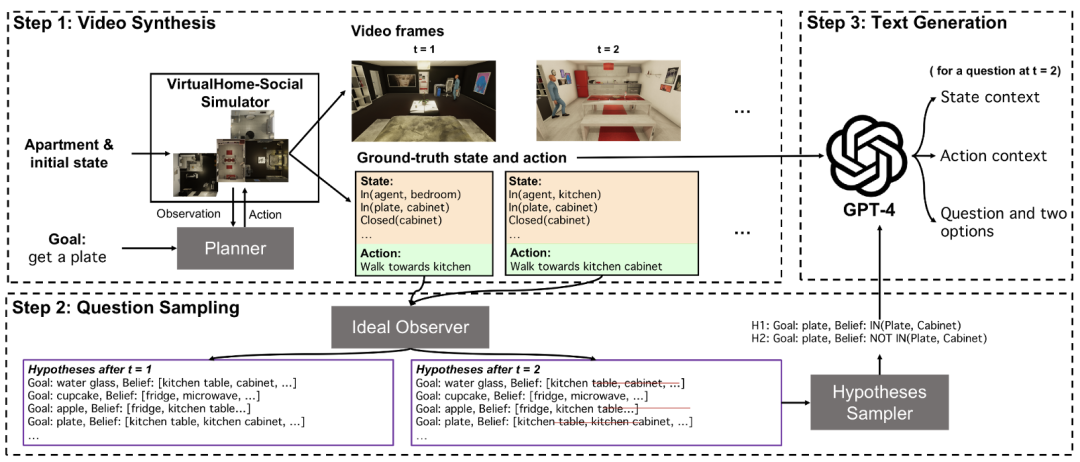
先前所有心智能力的测试基准都是单一模态的。MMToM-QA 是第一个多模态的心智能力测试基准。其中每个问题包含三部分:一个人的活动视频,环境和人类动作的文字描述与一个 ToM 问题。
此前,大部分的心智能力测试基准都使用较简单的模版,文字或视频的长度很短。MMToM-QA 要求在更长的上下文下,更复杂多样的环境下系统性衡量模型的心智能力。既考察 belief(人们所认为的),也考察 goal(人们的目标)。

为了生成这些视频,该团队使用 VirtualHome-Social 模拟器来中生成一系列人物动作,并渲染合成视频。接下来,使用一个模型来跟踪记录在视频的每个时刻中 agent 所有可能的目标和想法,据此生成问题,并使用 GPT-4 生成改进问题的描述。
Meta、MIT、CMU、JHU 的众多团队已使用 MMToM-QA 来研发与人合作的大模型、机器人等。

大模型集体翻车:GPT-4V存在致命缺陷
在 MMToM-QA 上的实验结果显示,当人们可以使用不同模态的信息时,他们理解他人的能力会有所提升。在这种多模态条件下,在每个问题上大多数参与者都达成了一致意见,这验证了基准设计的有效性。
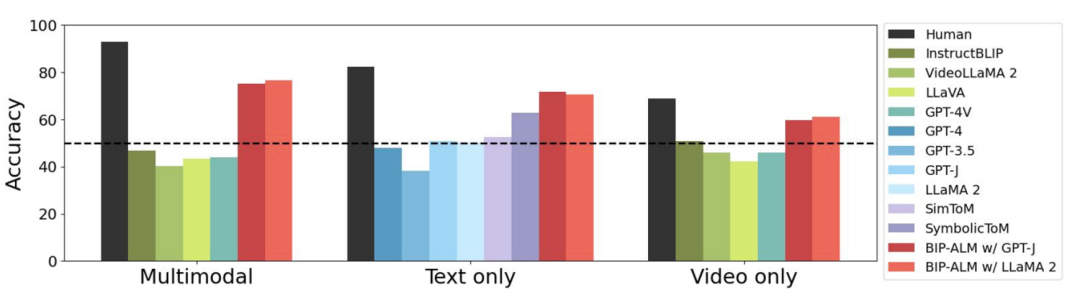
相比之下,多模态模型和 LLM 的表现远不如人类。它们在所有问题类型上表现得像随机猜测一样。唯一的例外是 GPT-4V,当人们的信念与现实一致时它表现良好,但当涉及到人们持有错误信念或更新信念时,GPT-4V 会系统性犯错,并且在判断目标时表现较差。
以下是 GPT-4V 的一个失败案例。从视频和文本中可以看出,柜子里没有蛋糕,但女人却朝柜子走去,准备打开它。因此,正确答案应该是 「女人认为柜子里有一个蛋糕。」然而,GPT-4V 错误地使用了真实世界的状态来推断女人的想法,这表明 GPT-4V 无法区分信念和真实世界状态。


BIP-ALM:小模型 + 逆向规划超过GPT-4V
那么,我们该如何缩小 AI 模型和人类表现之间的差距?
该团队提出了一种新方法:BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models)。该方法首先从视频和文字中提取出相同的符号表示,接着对这些表示进行对齐和融合,再使用逆向结合语言模型来推断各种心理状态的概率。
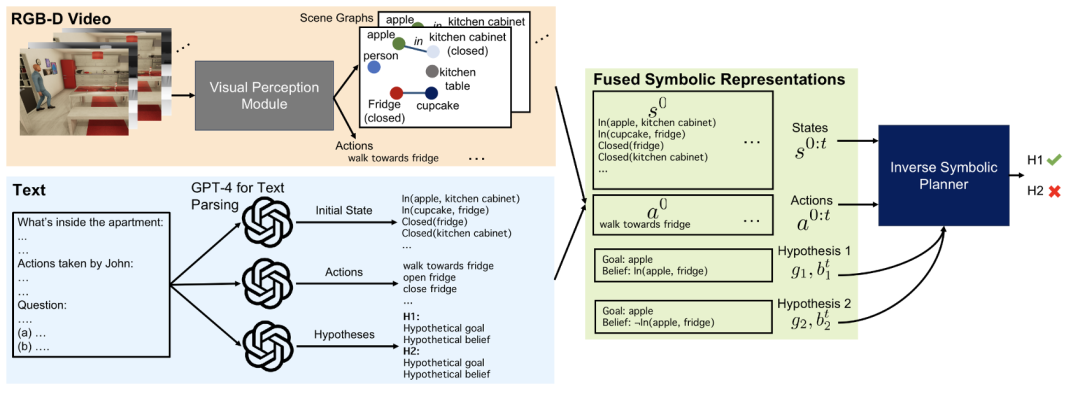
以下是融合符号表示的方法。模型将从视频中提取特定时刻的场景关系图,识别人物与物体之间的关系,例如他们正在经过哪些物体或他们正朝哪些物品前进。由于摄像头视角的限制和遮挡,文本提供了这些可能无法直接从视频中观察的这些信息。
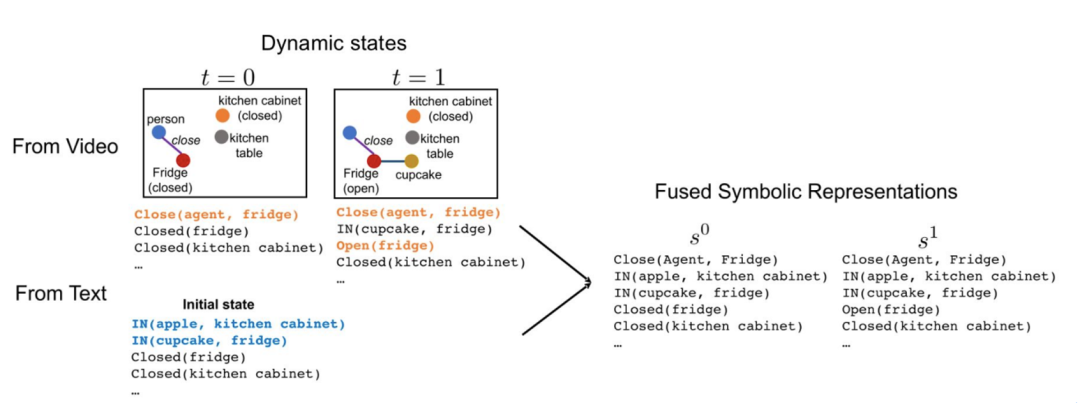
贝叶斯逆向规划(Bayesian inverse planning)可以根据观察到的 agent 的行为来推断其心理状态与潜在的信念和目标。先前的研究表明,贝叶斯逆向规划可以在简单情景下成功。然而,当状态空间变得很大时,计算每个可能信念和目标的概率变得非常复杂,导致计算瓶颈。下图中蓝色标出的部分就是一个计算瓶颈。为了加速这一过程,该团队使用了语言模型来估计每个时刻的心理状态的概率。

先前的大模型和各种方法无论是在文本、视频、还是多模态版本的 MMToM-QA 上都表现较差,而 BIP-ALM 则展现了较好的结果。论文作者认为 BIP-ALM 得益于:(1) 使用适用于不同模态信息的符号表示,(2) 模仿人类心智推理的逆向规划方法具有很强的鲁棒性和可解释性,(3) 语言模型具有很好的灵活性和可扩展性。

后续工作走向多智能体的多模态心智模型
该团队提出了后续研究 MuMA-ToM: Multi-modal Multi-Agent Theory of Mind,将 MMToM-QA 的测试基准和方法拓展到了多个智能体的领域。

论文标题:
MuMA-ToM: Multi-modal Multi-Agent Theory of Mind
论文链接:
https://arxiv.org/abs/2408.12574
代码链接:
https://github.com/SCAI-JHU/MuMA-ToM
网站链接
https://scai.cs.jhu.edu/projects/MuMA-ToM
MuMA-ToM 关注多智能体的互动,考察它们的信念、社会目标、和对他人目标的信念,发现大型多模态模型 GPT-4o、Gemini-1.5 Pro 等依然表现糟糕。针对这些发现,研究团队进一步提出了改进的方法 LIMP (Language model-based Inverse Multi-agent Planning)。
相比之前的方法,LIMP 使用自然语言而不是符号表示来提高通用性,并且能够利用任何预训练的大型语言模型,而 BIP-ALM 则要求开放权重的大型语言模型。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









