







内存占用与训练表现的取舍,一直是大模型高效训练的难题。
为了突破内存瓶颈,许多低秩训练方法应运而生,如 LoRA(分解参数矩阵)和 GaLore(分解梯度矩阵)。
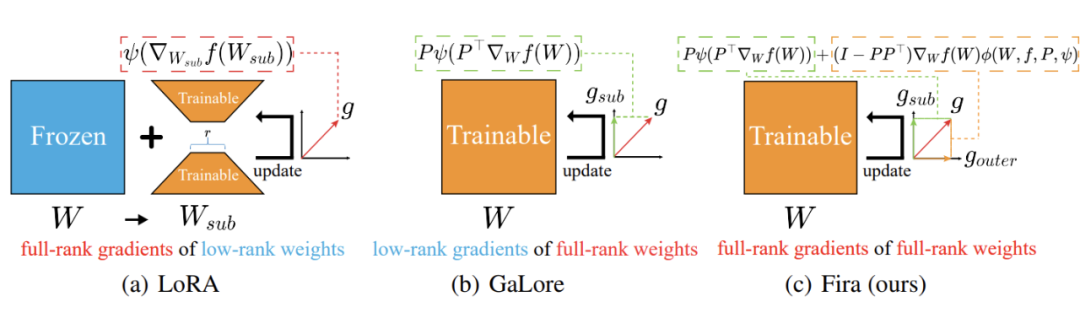
▲ 图1:从宏观层面分析三种内存高效低秩训练方法
然而,如上图所示,LoRA 将训练局限于参数的低秩子空间,降低了模型的表征能力,难以实现预训练;GaLore 将训练局限于梯度的低秩子空间,造成了子空间外梯度的信息损失。
相较于全秩训练,这两种方法由于施加了低秩约束,会导致训练表现有所下降;然而,若提高秩值,则会相应地增加内存占用。因此,在实际应用中,它们需要在确保训练表现与降低内存消耗之间找到一个恰当的平衡点。
这引发了一个核心问题:我们能否在维持低秩约束以确保内存高效的同时,实现全秩参数、全秩梯度的训练以提升表现呢?
针对这一难题,来自北理、北大和港中文 MMLab 的研究团队首次提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。

论文链接:
https://arxiv.org/abs/2410.01623
代码仓库:
https://github.com/xichen-fy/Fira
Fira 的三大亮点:
1. 即插即用:Fira 简单易用,其核心实现仅涉及两行关键公式,现已封装进 Python 库,可直接融入现有的大模型训练流程中,替换原有优化器。代码示例如下:
from fira import FiraAdamW, divide_params
param_groups = divide_params(model, target_modules_list = ['Linear'], rank=8)
optimizer = FiraAdamW(param_groups, lr=learning_rate)2. 双赢解决方案:在维持低秩约束的前提下,Fira 首次实现大模型的全秩训练,打破了内存占用与训练表现的取舍难题。与此同时,区别于系统方法(如梯度检查点),Fira 不以时间换内存。
3. 实验验证:Fira 在多种规模的模型(60M 至 7B 参数)以及预训练和微调任务中均展现出卓越性能,优于现有的 LoRA 和 GaLore,甚至能达到或超越全秩训练的效果。与 GaLore 相比,Fira 的表现几乎不受秩值减少的影响,更加内存高效。

方法
Fira 训练框架由两部分组成:1)基于梯度模长的缩放策略:利用了我们首次在大模型低秩和全秩训练中发现的共通点——自适应优化器对原始梯度的修正效应,实现了低秩约束下的全秩训练。2)梯度模长限制器,通过限制梯度模长的相对增长比例,解决了大模型训练中常出现的损失尖峰问题。
1.1 背景动机
大模型训练常常面临显著的内存瓶颈,尤其是其中的优化器状态。举例来说,使用 Adam 优化器从头预训练一个 LLaMA 7B 模型(batchsize 为 1,精度为 BF16)可能需要至少 58GB 内存。
其中 14GB 用于加载参数,14GB 用于储存梯度,28GB 用于储存优化器状态,剩下 2GB 用于储存激活值。在这之中,优化器状态所占内存甚至要大于参数本身。因此,使用低秩方法来减少这一部分内存,实现大模型的内存高效训练十分重要。
而在现有的低秩方法中,LoRA 通过分解参数矩阵,使用低秩适配器来减少内存占用;Galore 通过分解梯度矩阵,在自适应优化器中储存低秩梯度来减少内存占用。鉴于使用 LoRA 低秩适配器方法来实现全参数训练的困难性,我们选择拓展 Galore 的梯度投影方法来实现全秩训练。
在 Galore 中,全秩梯度 ,会被投影矩阵 ,分解成两项低秩梯度 和 ,其中 。为减少像 Adam 这样的自适应优化器在内存中对应的状态占用,Galore 仅在优化器核心 中保留低秩梯度 ,而非全秩梯度 。
而另一项梯度 ,则会因为缺少对应的优化器状态,被 Galore 直接丢弃,从而造成严重的信息损失。这也解释了,为什么 Galore 的性能会在 rank 值减小时,显著衰减。
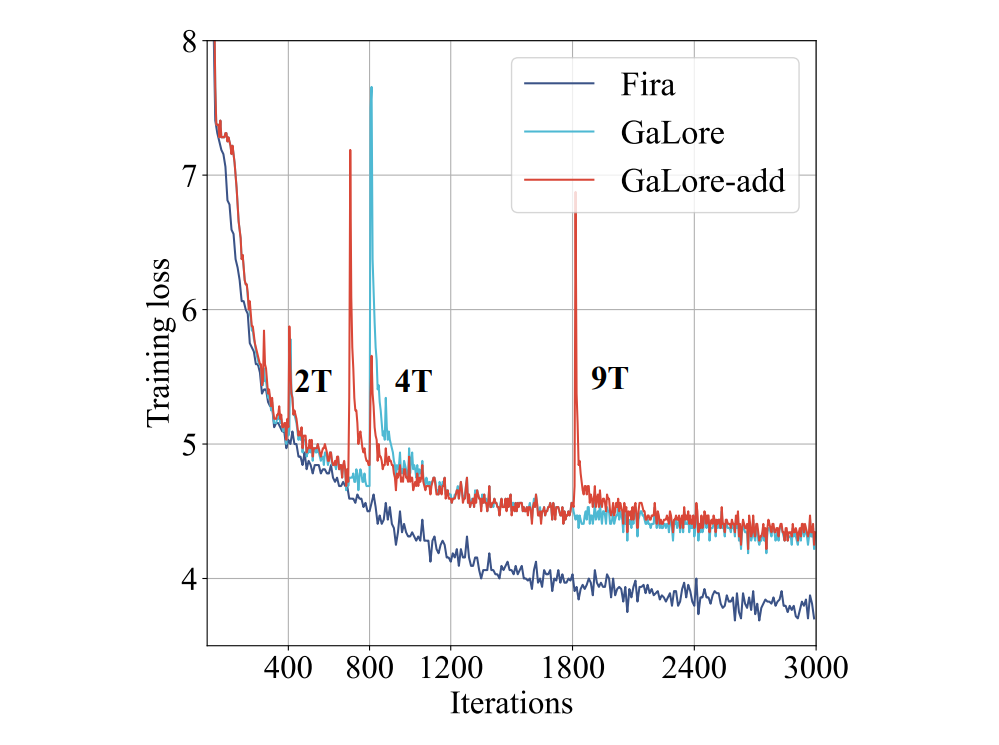
▲ 图2:Fira 与 Galore 及其变体的训练损失对比
为了弥补上述信息损失,最直观的方法是直接加上这一部分梯度 :
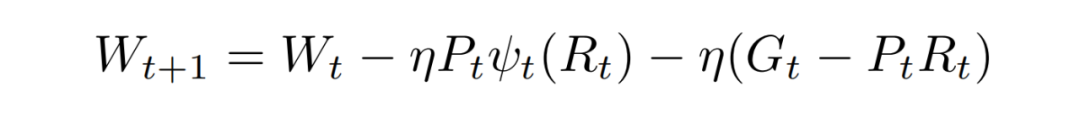
其中, 是参数矩阵, 是学习率。然而,如图 2 所示,使用这种方法(Galore-add)不仅未能带来性能提升,反而可能导致训练过程更加不稳定,且结果更差。分析原因可归结于这一部分的梯度缺乏优化器状态,直接使用会退化为单纯的 SGD 算法,并且可能与前面使用的 Adam 优化器的梯度不匹配,导致效果不佳。
1.2 基于梯度模长的缩放策略
为了解决上述挑战,我们提出了 scaling factor 概念,来描述 Adam 这样的自适应优化器对原始梯度的修正效应,并首次揭示了它在大模型的低秩训练和全秩训练之间的相似性。
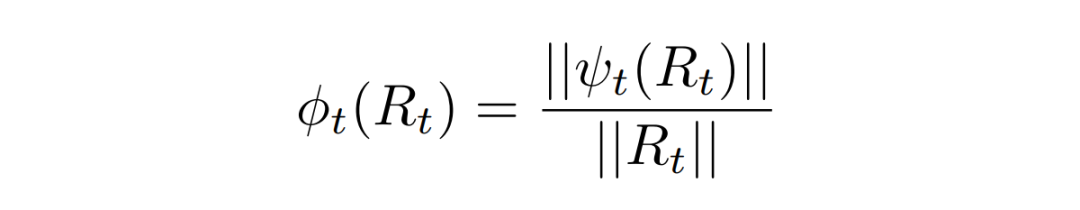
其中, 就是 scaling factor,代表经过优化器修正过的梯度与原始梯度的模长比例。如图 3,如果我们根据 scaling factor 的平均值对参数矩阵进行排序,可以发现低秩和全秩之间的排序非常相似。
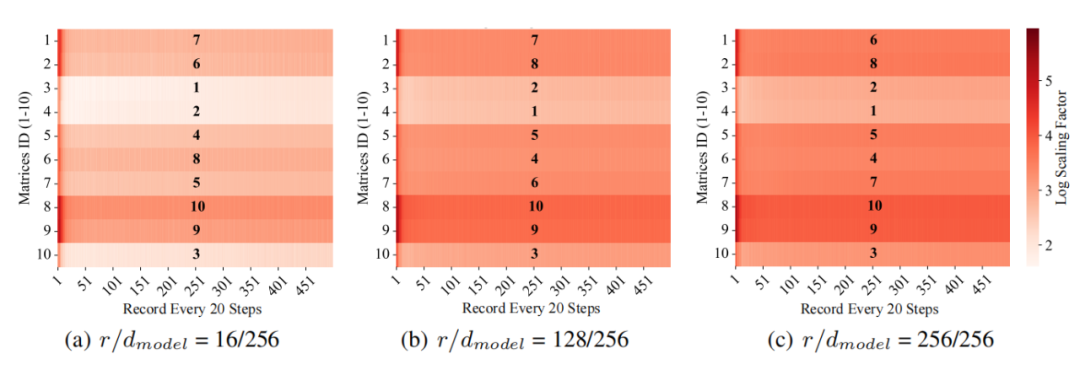
▲ 图3:scaling factor在大模型低秩和全秩训练间的相似性
基于这个观察,我们就尝试在矩阵层面用低秩梯度 的 scaling factor,作为全秩梯度 的 scaling factor 的替代,从而近似地修正 ,弥补其缺少的优化器状态:
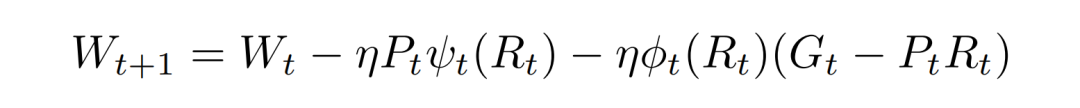
这样我们就在低秩约束下成功实现了全秩训练。进一步来说,刚才我们是从矩阵层面来考虑 scaling factor。顺理成章地,我们可以从更细粒度的角度——列的层面,来考虑 scaling factor,实现更加精细地修正。
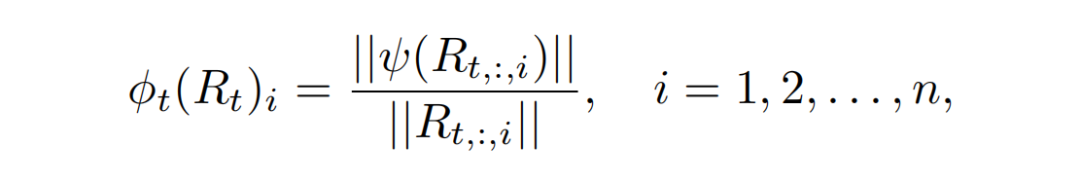
其中 是低秩梯度 的第 i 列, 是 scaling factor 的第 i 项。
1.3 梯度模长限制器
在训练过程中,梯度常常会突然增大,导致损失函数出现尖峰,从而影响训练的表现(如图 4 中的 Fira-w.o.-limiter)。经过分析,可能的原因是 Galore 在切换投影矩阵时存在不稳定性,以及维持 这种原始梯度的方向的方式,无法像 Adam 这样的自适应算法,有效应对大模型训练中存在的陡峭损失景观。
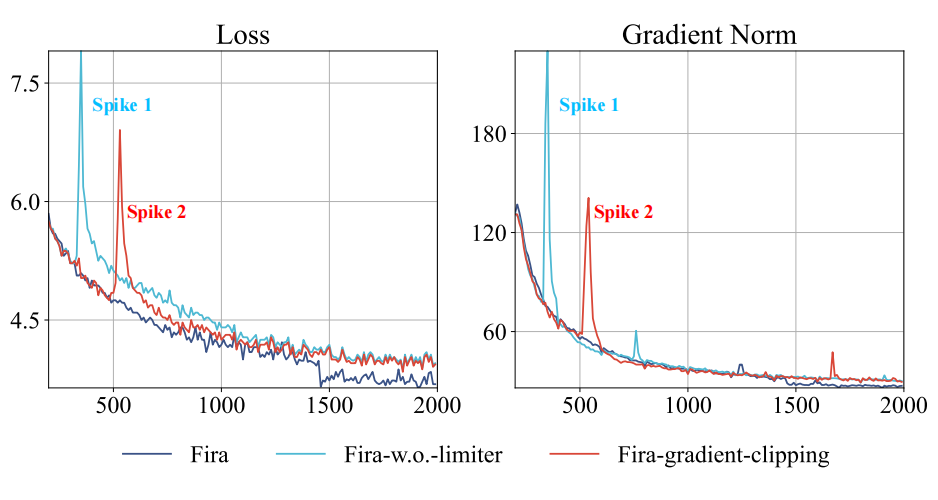
▲ 图4:3 种 Fira 变体的训练损失与梯度模长
然而,常见的梯度裁剪方法(如图 4 中的 Fira-gradient-clipping)由于采用绝对裁剪,难以适应不同参数矩阵间梯度的较大差异,从而可能导致次优的训练结果。
为此,我们提出了一种新的梯度模长限制器,它通过限制梯度模长的相对增长比例,来更好地适应不同梯度的变化:
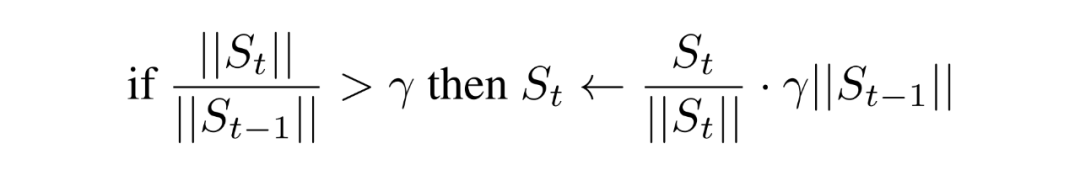
其中 是比例增长的上限, 是原始梯度 修正后的结果。通过我们提出的控制梯度相对增长比例的方法,能够将梯度的骤然增大转化为平缓的上升,从而有效稳定训练过程。如图 2 和图 3 所示,我们的限制器成功避免了损失函数的尖峰情况,并显著提升了训练表现。

实验结果
如下表 1 所示,在预训练任务中,Fira 在保持内存高效的前提下,验证集困惑度()显著超过各类基线方法,甚至超越全秩方法。具体来说,在预训练 LLaMA 1B 模型时,Fira 节约了 61.1% 优化器状态所占内存,并且取得了比全秩训练更加好的结果。
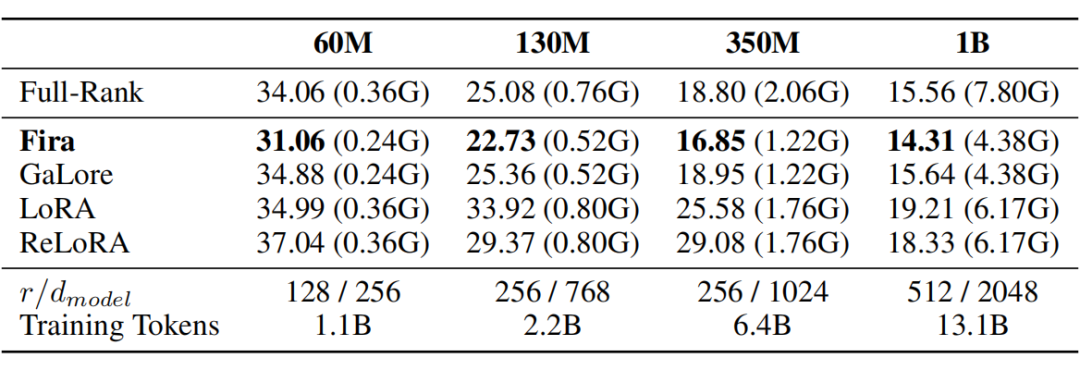
▲ 表1:使用 C4 数据集预训练不同大小的 LLaMA 模型验证集困惑度()对比
如下图 5 所示,在预训练 LLaMA 7B 模型时,Fira 在使用了比 Galore 小 8 倍的秩 rank 的情况下,训练表现远超 Galore。这展现了 Fira 在大规模大模型上的有效性,以及相较 Galore 更高的内存减少能力。
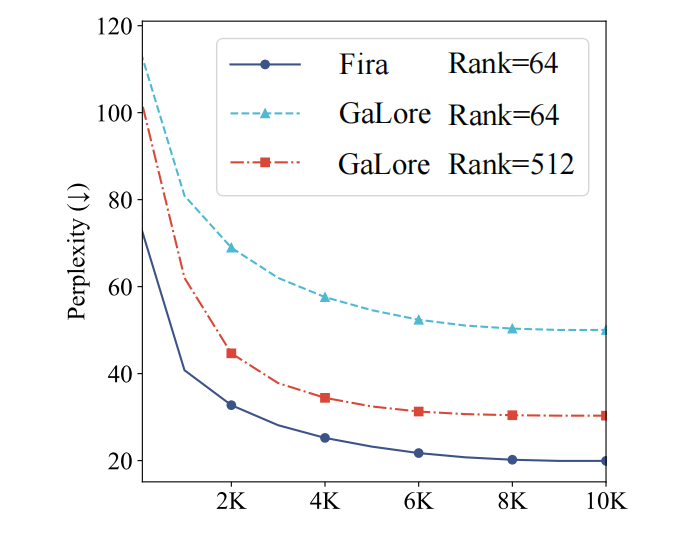
▲ 图5:使用 C4 数据集预训练 LLaMA 7B 的验证集困惑度()对比
如下表 2 所示,在八个常识推理数据集微调 LLaMA 7B 的任务中,相较其他基线方法,Fira 在一半的数据集下表现最好,平均准确率最高的同时实现了内存高效。
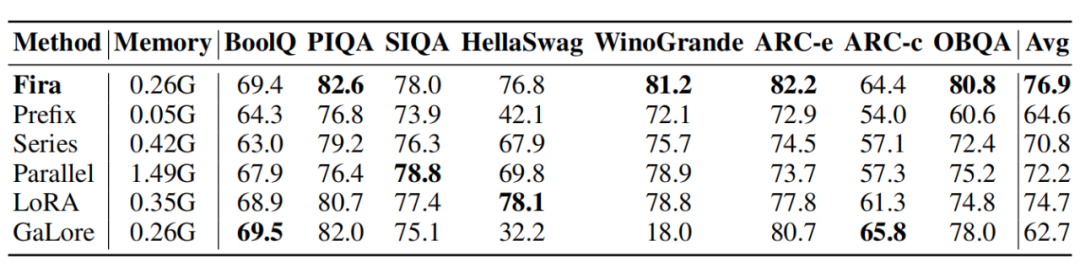
▲ 表2:在八个常识推理数据集微调 LLaMA 7B 准确率对比
如下表 3 所示,Fira-w.o.-scaling 说明了 Fira 使用基于梯度模长的缩放策略的有效性;Fira-matrix 说明了从更细粒度的列级别,而不是矩阵级别,考虑 scaling factor 的有效性;Fira-w.o.-limiter 说明了 Fira 中梯度模长限制器的有效性;Fira-gradient-clipping 说明了梯度裁剪可能无法完全解决损失尖峰问题,导致结果次优。
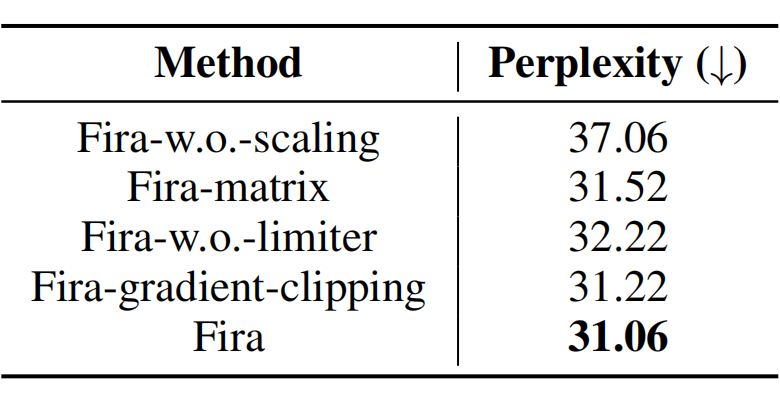
▲ 表3:消融实验
如下图 6 所示,与 GaLore 相比,Fira 的表现几乎不受秩 rank 值减少的影响。在低秩的情况下(rank=16, rank=4),Fira 仍然能与全秩训练相当,相较 Galore 更加内存高效。
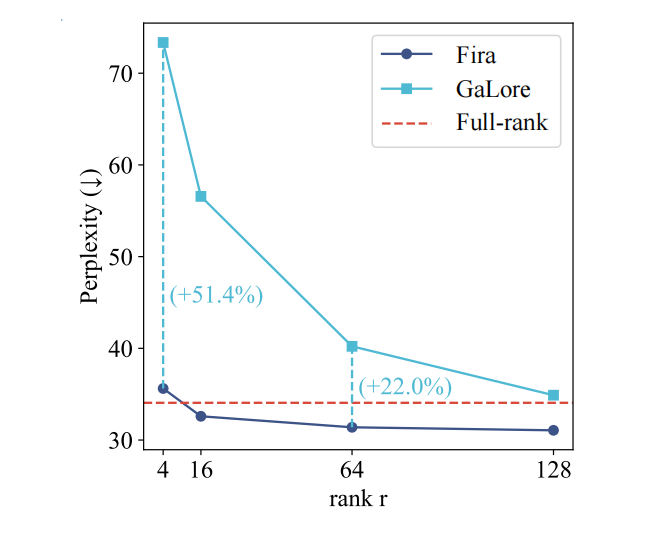
▲ 图6:不同 rank 下的预训练验证集困惑度()
如下表 4 所示,我们在不同模型大小,以及低秩和全秩条件下,训练 10,000 步,并对得到的矩阵和列级别上 Scaling factor 做平均。
接着,我们使用了斯皮尔曼(Spearman)和肯德尔(Kendall)相关系数分析了 Scaling factor 在矩阵和列级别上大小顺序的相关性。其中,Coefficient 中 1 代表完全正相关,-1 代表完全负相关,而 P-value 越小越好(通常小于 0.05 为显著)。
在所有规模的 LLaMA 模型中,Scaling factor 在矩阵和列的级别上都表现出很强的正相关关系,并且所有的 P-value 小于 0.05,非常显著,为 Fira 中基于梯度模长的缩放策略提供了坚实的实验基础。
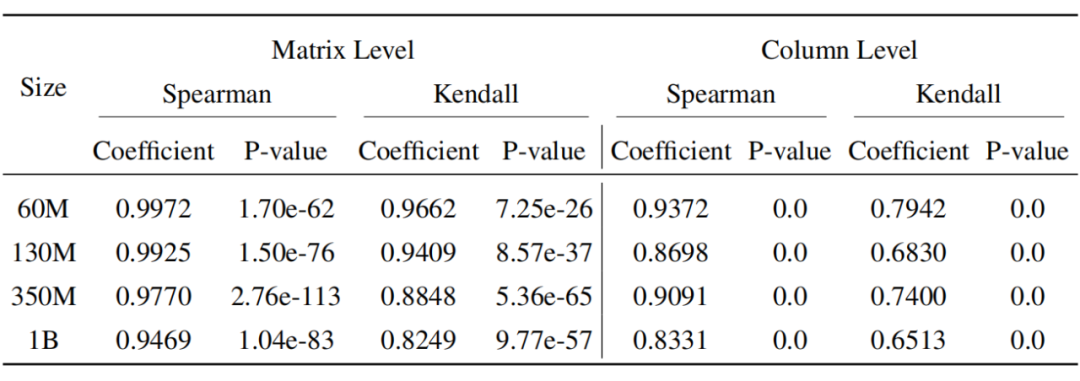
▲ 表4:矩阵和列级别上的 Scaling factor 低秩与全秩相似性分析。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









