







大连理工大学的研究人员提出了一种基于 Wasserstein 距离的知识蒸馏方法,克服了传统 KL 散度在 Logit 和 Feature 知识迁移中的局限性,在图像分类和目标检测任务上表现更好。
自 Hinton 等人的开创性工作以来,基于 Kullback-Leibler 散度(KL-Div)的知识蒸馏一直占主导地位。
然而,KL-Div 仅比较教师和学生在相应类别上的概率,缺乏跨类别比较的机制,应用于中间层蒸馏时存在问题,其无法处理不重叠的分布且无法感知底层流形的几何结构。
为了解决这些问题,大连理工大学的研究人员提出了一种基于 Wasserstein 距离(WD)的知识蒸馏方法。所提出方法在图像分类和目标检测任务上均取得了当前最好的性能,论文已被 NeurIPS 2024 接受为 Poster。

论文标题:
Wasserstein Distance Rivals Kullback-Leibler Divergence for Knowledge Distillation
论文地址:
https://arxiv.org/abs/2412.08139
项目地址:
https://peihuali.org/WKD/
代码地址:
https://github.com/JiamingLv/WKD

背景与动机介绍
知识蒸馏(KD)旨在将具有大容量的高性能教师模型中的知识迁移到轻量级的学生模型中。近年来,知识蒸馏在深度学习中受到了越来越多的关注,并取得了显著进展,在视觉识别、目标检测等多个领域得到了广泛应用。
在其开创性工作中,Hinton 等人引入了 Kullback-Leibler 散度(KL-Div)用于知识蒸馏,约束学生模型的类别概率预测与教师模型相似。
从那时起,KL-Div 在 Logit 蒸馏中占据主导地位,并且其变体方法 DKD、NKD 等也取得了令人瞩目的性能。此外,这些 Logit 蒸馏方法还可以与将知识从中间层传递的许多先进方法相互补充。
尽管 KL-Div 取得了巨大的成功,但它存在的两个缺点阻碍了教师模型知识的迁移。
首先,KL-Div 仅比较教师和学生在相应类别上的概率,缺乏执行跨类别比较的机制。
然而,现实世界中的类别呈现不同程度的视觉相似性,例如,哺乳动物物种如狗和狼彼此间的相似度较高,而与汽车和自行车等人工制品则有很大的视觉差异,如图1所示。
不幸的是,由于 KL-Div 是类别对类别的比较,KD 和其变体方法无法显式地利用这种丰富的跨类别知识。
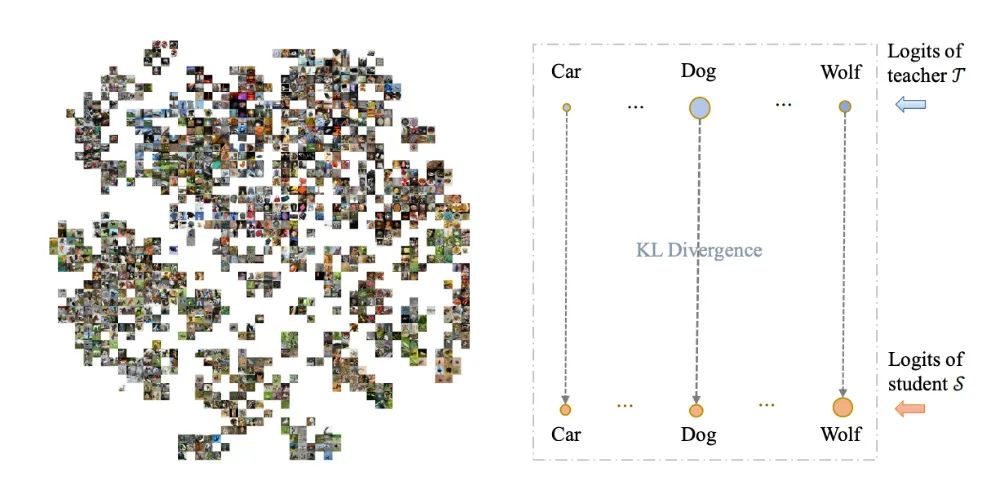 ▲ 图1. 左图使用t-SNE展示了100个类别的嵌入分布。可以看出,这些类别在特征空间中表现出丰富的相互关系 (IR)。然而,右图中的KL散度无法显式地利用这些相互关系。
▲ 图1. 左图使用t-SNE展示了100个类别的嵌入分布。可以看出,这些类别在特征空间中表现出丰富的相互关系 (IR)。然而,右图中的KL散度无法显式地利用这些相互关系。
其次,KL-Div 在用于从中间层特征进行知识蒸馏时存在局限性。图像的深度特征通常是高维的且空间尺寸较小,因此其在特征空间中非常稀疏,不仅使得 KL-Div 在处理深度神经网络特征的分布时存在困难。
KL-Div 无法处理不重叠的离散分布,并且由于其不是一个度量,在处理连续分布时能力有限,无法感知底层流形的几何结构。
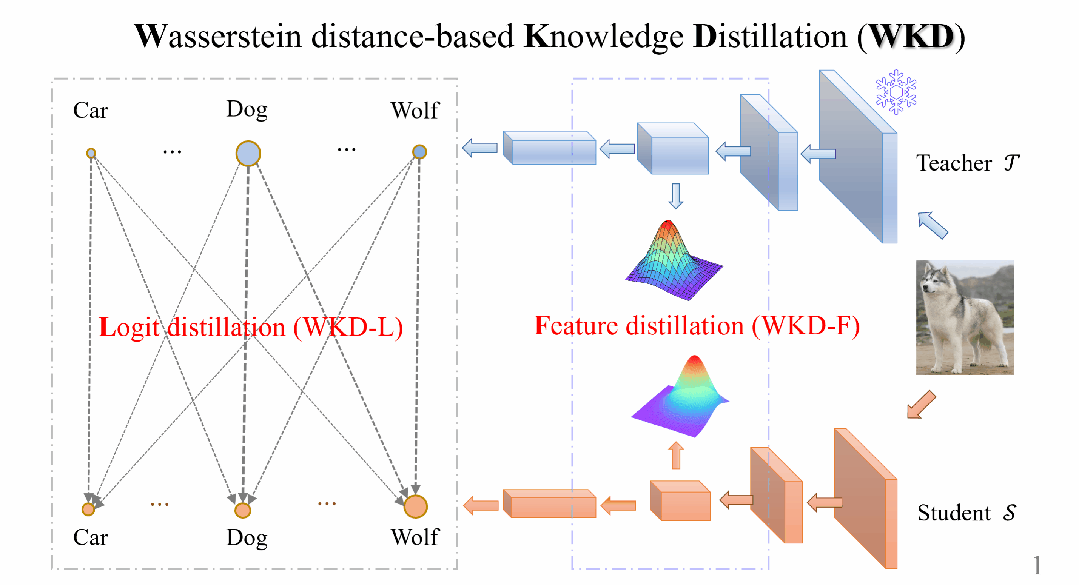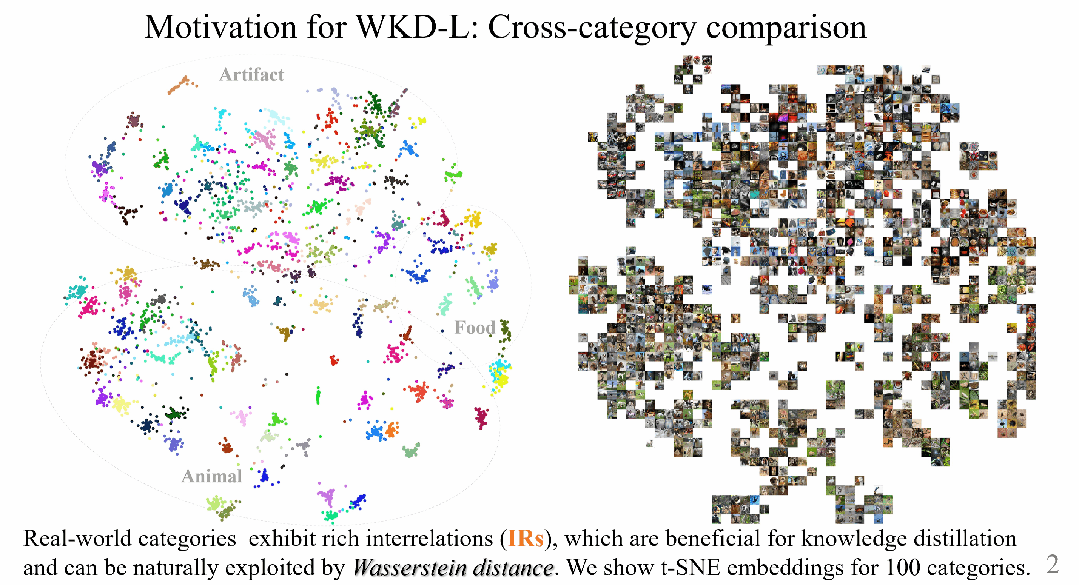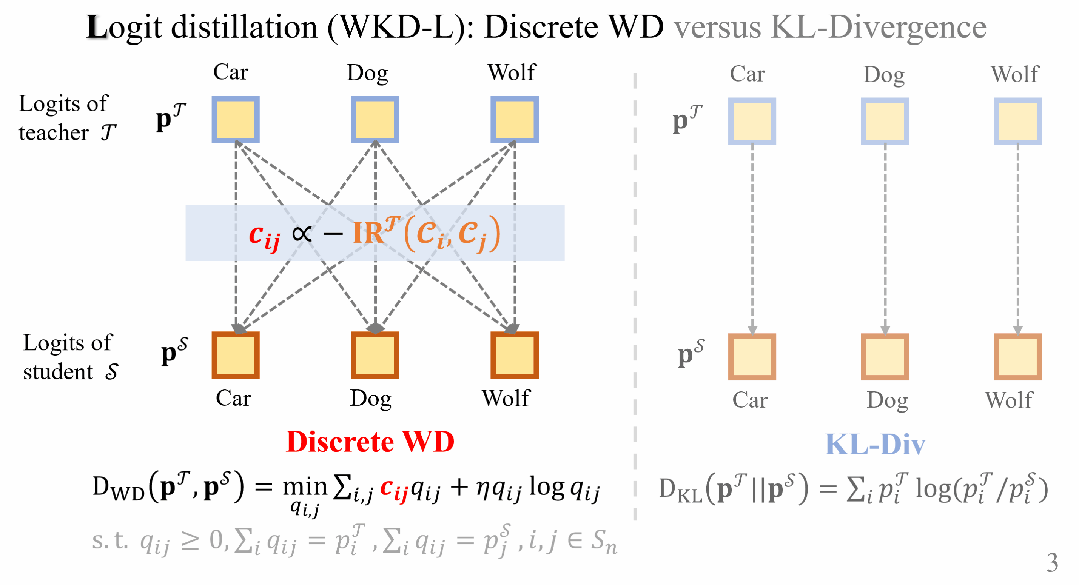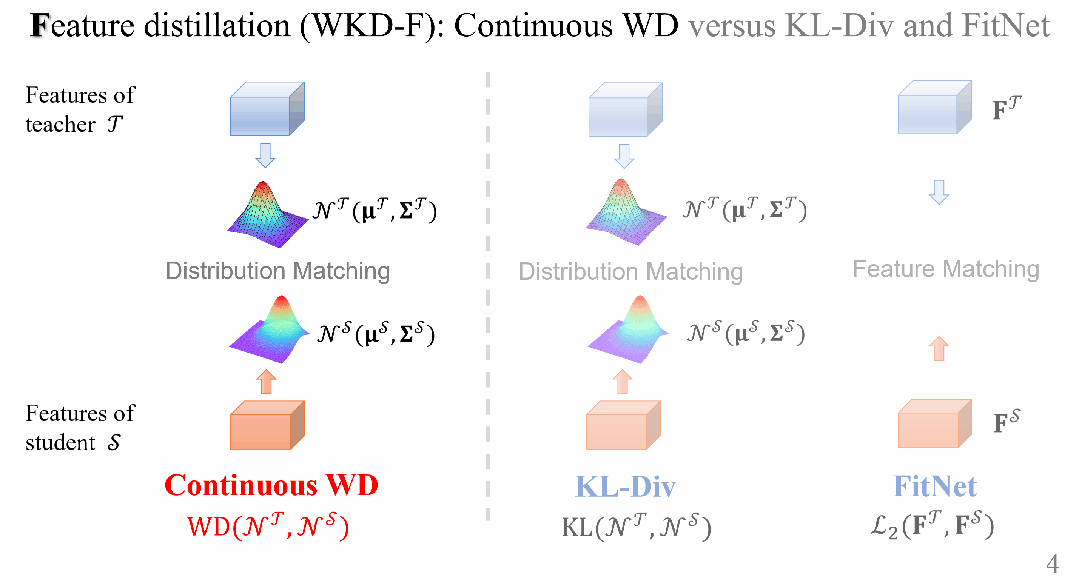
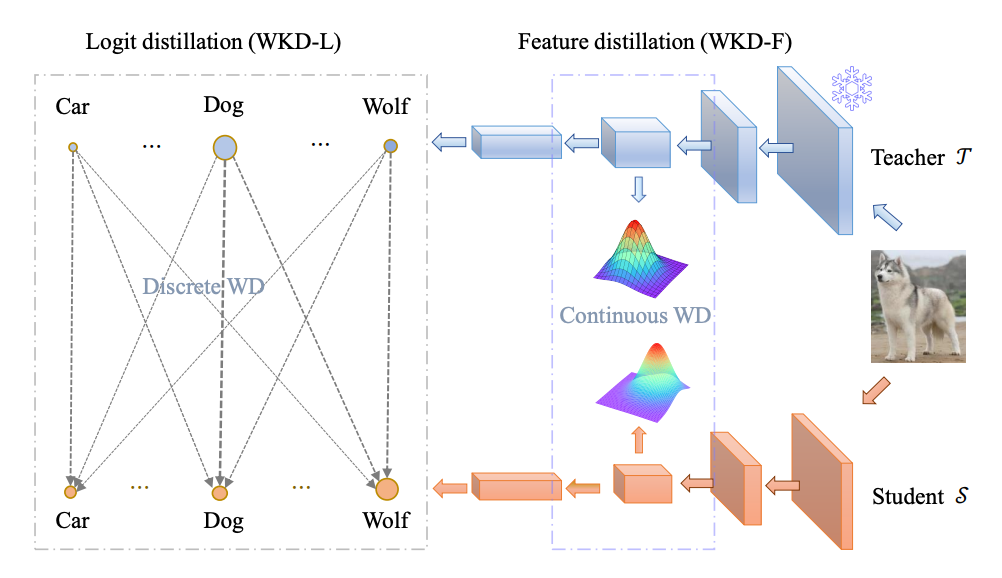 ▲ 图2. 基于Wasserstein距离(WD)的知识蒸馏方法的总览图
▲ 图2. 基于Wasserstein距离(WD)的知识蒸馏方法的总览图
为了解决这些问题,研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,称为WKD,同时适用于Logit蒸馏(WKD-L)和Feature蒸馏(WKD-F),如图2所示。
在WKD-L中,通过离散WD最小化教师和学生之间预测概率的差异,从而进行知识转移。
通过这种方式,执行跨类别的比较,能够有效地利用类别间的相互关系(IRs),与KL-Div中的类别间比较形成鲜明对比。
对于WKD-F,研究人员利用WD从中间层特征中蒸馏知识,选择参数化方法来建模特征的分布,并让学生直接匹配教师的特征分布。
具体来说,利用一种最广泛使用的连续分布(高斯分布),该分布在给定特征的1阶和2阶矩的情况下具有最大熵。
论文的主要贡献可以总结如下:
提出了一种基于离散WD的Logit蒸馏方法(WKD-L),可以通过教师和学生预测概率之间的跨类别比较,利用类别间丰富的相互关系,克服KL-Div无法进行类别间比较的缺点。
将连续WD引入中间层进行Feature蒸馏(WKD-F),可以有效地利用高斯分布的Riemann空间几何结构,优于无法感知几何结构的KL-Div。
在图像分类和目标检测任务中,WKD-L优于非常强的基于KL-Div的Logit蒸馏方法,而WKD-F在特征蒸馏中优于KL-Div的对比方法和最先进的方法。WKD-L和WKD-F的结合可以进一步提高性能。

用于知识迁移的WD距离
用于Logit蒸馏的离散WD距离
类别之间的相互关系(IRs)
如图1所示,现实世界中的类别在特征空间中表现出复杂的拓扑关系。相同类别的特征会聚集并形成一个分布,而相邻类别的特征有重叠且不能完全分离。
因此,研究人员提出基于CKA量化类别间的相互关系(IRs),CKA是一种归一化的Hilbert-Schmidt独立性准则(HSIC),通过将两个特征集映射到再生核希尔伯特空间(RKHS)来建模统计关系。
首先将每个类别中所有训练样本的特征构成一个特征矩阵,之后通过计算任意两个类别特征矩阵之间的CKA得到类间相互关系(IR)。计算IR的成本可以忽略,因为在训练前仅需计算一次。
由于教师模型通常包含更丰富的知识,因此使用教师模型来计算类别间的相互关系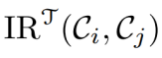 。
。
损失函数
用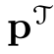 和
和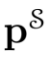 分别表示教师模型和学生模型的预测类别概率,其通过softmax函数和温度对Logit计算得到。将离散的WD表示为一种熵正则化的线性规划:
分别表示教师模型和学生模型的预测类别概率,其通过softmax函数和温度对Logit计算得到。将离散的WD表示为一种熵正则化的线性规划:
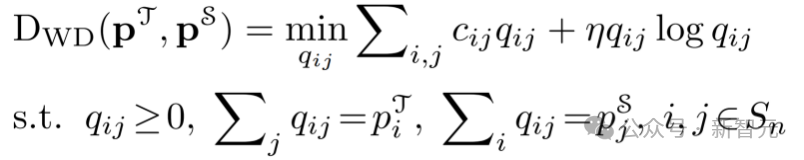
其中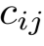 和
和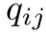 分别表示每单位质量的运输成本和在将概率质量从
分别表示每单位质量的运输成本和在将概率质量从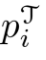 移动到
移动到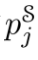
时的运输量;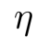 是正则化参数。
是正则化参数。
定义运输成本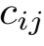 与相似度度量
与相似度度量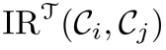 成负相关。
成负相关。
因此,WKD-L的损失函数可以定义为:
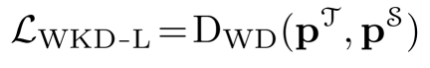
用于Feature蒸馏的连续WD距离
特征分布建模
将模型某个中间层输出的特征图重塑为一个矩阵,其中第i列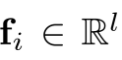 表示一个空间特征。
表示一个空间特征。
之后,估计这些特征的一阶矩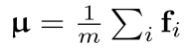 和二阶矩
和二阶矩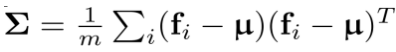 ,并将二者作为高斯分布的参数来建模输入图像特征的分布。
,并将二者作为高斯分布的参数来建模输入图像特征的分布。
损失函数
设教师的特征分布为高斯分布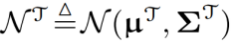 。类似地,学生的分布记为
。类似地,学生的分布记为 。
。
两者之间的连续Wasserstein距离(WD)定义为:
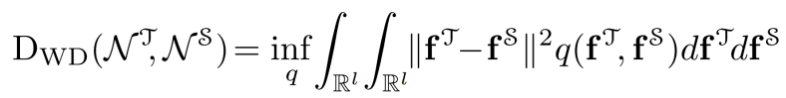
其中,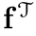 和
和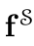 是高斯变量,q表示联合分布。最小化上式可以得到闭集形式的WD距离。此外,为了平衡均值和协方差的作用,引入了一个均值-协方差比率γ,最后损失定义为:
是高斯变量,q表示联合分布。最小化上式可以得到闭集形式的WD距离。此外,为了平衡均值和协方差的作用,引入了一个均值-协方差比率γ,最后损失定义为:
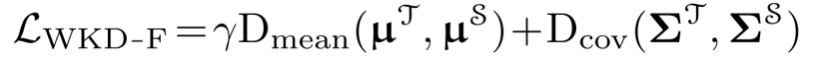

实验分析和比较
研究人员在ImageNet和CIFAR-100上评估了WKD在图像分类任务中的表现,还评估了WKD在自蒸馏(Self-KD)中的有效,并且将WKD扩展到目标检测,并在MS-COCO上进行了实验。
在ImageNet上的图像分类
研究人员在ImageNet的在两种设置下与现有工作进行了比较。设置(a)涉及同质架构,其中教师和学生网络分别为ResNet34和ResNet18;设置(b)涉及异质架构,在该设置中,教师网络为ResNet50,学生网络为MobileNetV1。
对于Logit蒸馏,WKD-L在两种设置下均优于经典的KD及其所有变体。对于特征蒸馏,WKD-F也超过当前的最佳方法ReviewKD;最后,WKD-L和WKD-F的结合进一步提升了性能,超越了强有力的竞争方法。
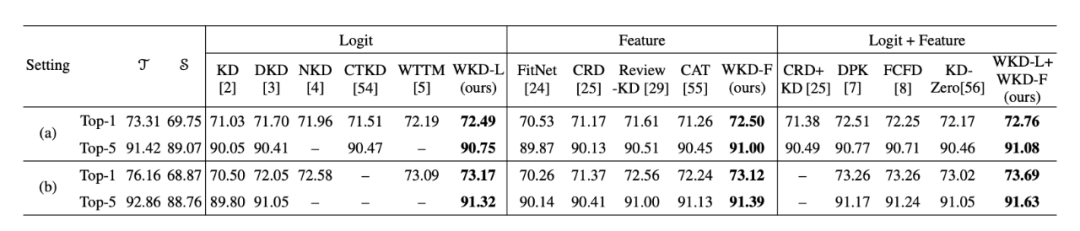 ▲ 表1. 在ImageNet上的图像分类结果
▲ 表1. 在ImageNet上的图像分类结果
在CIFAR-100上的图像分类
研究人员在教师模型为CNN、学生为Transformer或反之的设置下评估了WKD方法,使用的CNN模型包括ResNet(RN)、MobileNetV2(MNV2)和ConvNeXt;Transformer模型包括ViT、DeiT和Swin Transformer。
对于Logit蒸馏,WKD-L在从Transformer到CNN迁移知识或反之的设置下始终优于最新的OFA方法。对于特征蒸馏,WKD-F在所有实验设置中排名第一;
研究人员认为,对于跨CNN和Transformer的知识转移,考虑到两者特征差异较大,WKD-F比像FitNet和CRD这样直接对原始特征进行对齐的方法更为合适。
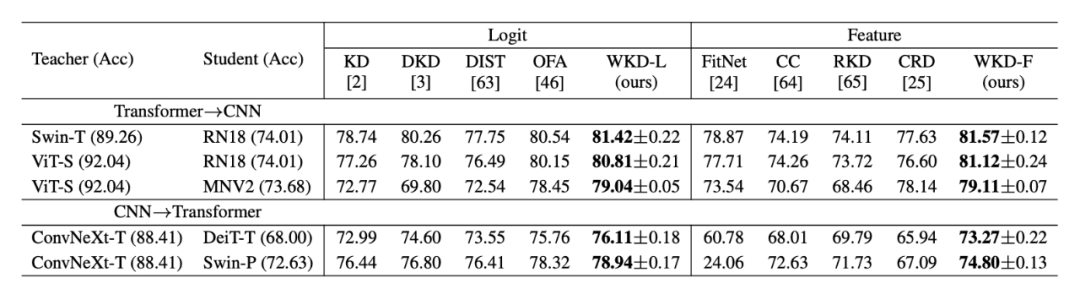 ▲ 表2. CIFAR-100上跨CNN和Transformer的图像分类结果(Top-1准确率)
▲ 表2. CIFAR-100上跨CNN和Transformer的图像分类结果(Top-1准确率)
在ImageNet上的自蒸馏
研究人员在Born-Again Network(BAN)框架中将WKD方法用于自蒸馏任务(Self-KD)。
使用ResNet18在ImageNet上进行实验,结果如表3所示,WKD-L取得了最佳结果,比BAN的Top-1准确率高出约0.9%,比第二高的USKD方法高出0.6%。这一比较表明,WKD方法可以很好地推广到自蒸馏任务中。
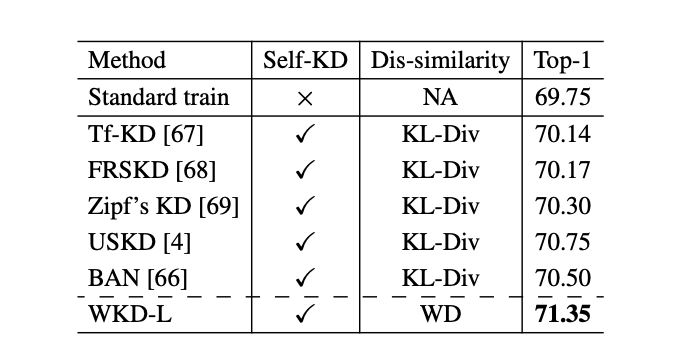
▲ 表3. 在ImageNet上自蒸馏(Self-KD)的结果
在MS-COCO上的目标检测
研究人员将WKD扩展到Faster-RCNN框架下的目标检测中。对于WKD-L,使用检测头中的分类分支进行Logit蒸馏。对于WKD-F,直接从输入到分类分支的特征中进行知识迁移,即从RoIAlign层输出的特征来计算高斯分布。
对于Logit蒸馏,WKD-L显著优于经典的KD,并略微优于DKD。对于特征蒸馏,WKD-F在两个设置中均显著超过之前的最佳特征蒸馏方法ReviewKD。最后,通过结合WKD-L和WKD-F,表现超过了DKD+ReviewKD。当使用额外的边框回归进行知识迁移时,WKD-L+WKD-F进一步提高并超越了之前的最先进方法FCFD。
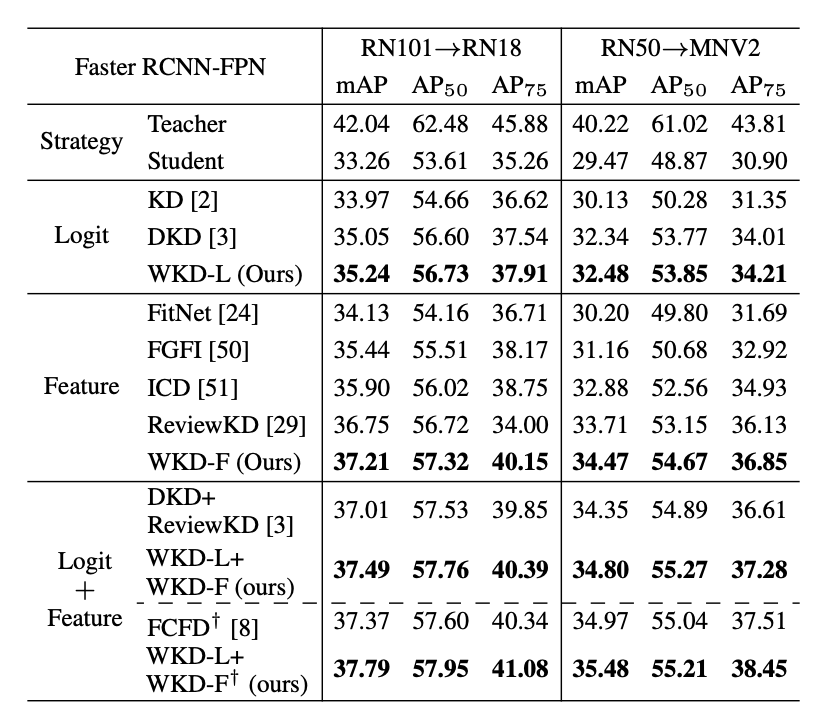 ▲ 表4. 在MS-COCO上的目标检测结果。†:使用了额外的边框回归进行知识迁移
▲ 表4. 在MS-COCO上的目标检测结果。†:使用了额外的边框回归进行知识迁移

总结
Wasserstein距离(WD)在生成模型等多个领域中已展现出相较于KL散度(KL-Div)的显著优势。
然而,在知识蒸馏领域,KL散度仍然占据主导地位,目前尚不清楚Wasserstein距离能否实现更优的表现。
研究人员认为,早期基于Wasserstein距离的知识蒸馏研究未能充分发挥该度量的潜力。
因此,文中提出了一种基于Wasserstein距离的全新知识蒸馏方法,能够从Logit和Feature两个方面进行知识迁移。
大量的实验表明,离散形式的Wasserstein距离在Logit蒸馏中是当前主流KL散度的极具潜力的替代方案,而连续形式的Wasserstein距离在中间层特征迁移中也取得了令人信服的性能表现。
尽管如此,该方法仍存在一定局限性:WKD-L相比基于KL散度的Logit蒸馏方法计算开销更高,而WKD-F假设特征服从高斯分布。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









