








近年来,Transformer 架构在自然语言处理领域取得了巨大成功,从机器翻译到文本生成,其强大的建模能力为语言理解与生成带来了前所未有的突破。
然而,随着模型规模的不断扩大和应用场景的日益复杂,传统 Transformer 架构逐渐暴露出缺陷,尤其是在处理长文本、关键信息检索以及对抗幻觉等任务时,Transformer 常常因过度关注无关上下文而陷入困境,导致模型表现受限。
为攻克这一难题,来自微软和清华的研究团队提出了 DIFF Transformer,一种基于差分注意力机制的创新基础模型架构。

论文标题:
Differential Transformer
论文链接:
https://openreview.net/pdf?id=OvoCm1gGhN
代码链接:
https://aka.ms/Diff-Transformer
其核心思想是通过计算两组 Softmax 注意力图的差值来放大对关键上下文的关注,同时消除注意力噪声干扰。DIFF Transformer 具备以下显著优势:
在语言建模任务中,DIFF Transformer 在模型大小、训练 token 数量等方面展现出了卓越的可扩展性,仅需约 65% 的模型规模或训练 token 数量即可达到与传统 Transformer 相当的性能,大幅提升了语言模型通用表现。
在长文本建模、关键信息检索、数学推理、对抗幻觉、上下文学习、模型激活值量化等一系列任务中,DIFF Transformer 展现了独特优势,相比传统 Transformer 有显著提升。
DIFF Transformer 的特性使其在自然语言处理领域具有广阔的应用前景,有望成为推动语言模型发展的新动力。此外,已有跟进研究初步验证方法在视觉、多模态等领域中的有效性,显示出其跨模态通用的潜力。该研究已被 ICLR 2025 接收,并获选为 Oral 论文(入选比例 1.8%)。

方法
本文提出了一种名为 Differential Transformer(DIFF Transformer) 的基础模型架构,旨在解决传统 Transformer 在长文本建模中对无关上下文过度分配注意力的问题。该方法通过差分注意力机制(Differential Attention)放大对关键上下文的关注,同时消除注意力噪声,从而显著提升模型在多种任务中的性能。
差分注意力机制
传统 Transformer 的注意力机制通过 Softmax 函数对输入序列中的不同 token 进行加权,但 Softmax 的性质导致模型难以完全消除无关上下文的影响。为了克服这一问题,DIFF Transformer 引入了差分注意力机制。
具体而言,该机制将查询向量(Query)和键向量(Key)在注意力头(Head)维度分为两组,分别计算两组的 Softmax 注意力图,然后计算两者的差值作为最终的注意力分数。这一设计类似于电子工程中的差分放大器,以及降噪耳机,通过两组信号相减以消除共有噪声。
差分注意力的数学表达如下:
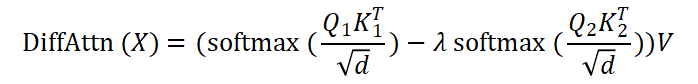
其中,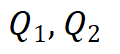 和
和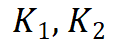 分别是两组查询和键向量,
分别是两组查询和键向量,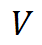 是值向量,
是值向量,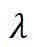 是一个可学习的标量参数,用于调节两组注意力图的权重。计算过程如图 1 所示。
是一个可学习的标量参数,用于调节两组注意力图的权重。计算过程如图 1 所示。
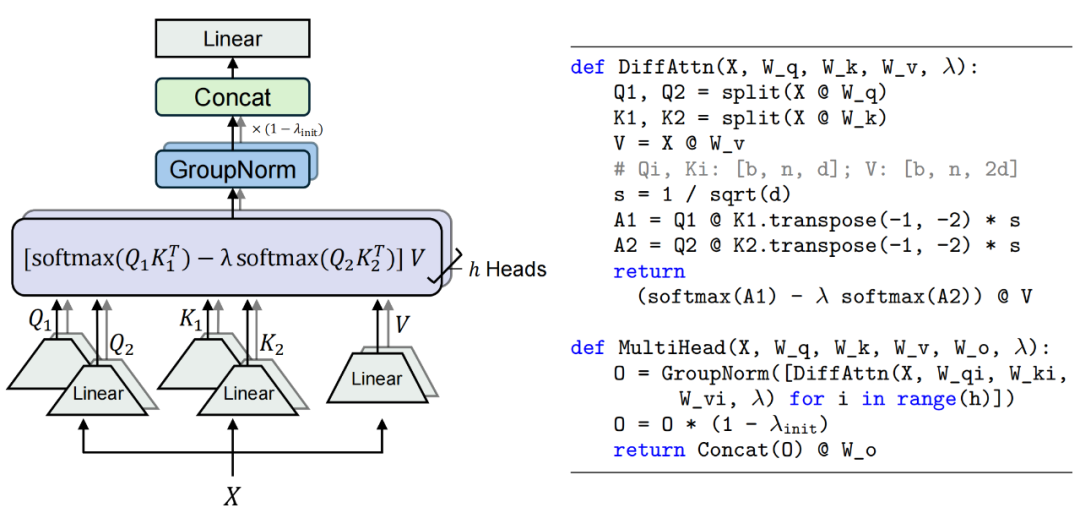
▲ 图1. 差分注意力机制图示与伪代码
为了同步学习速率,将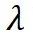 重参数化为:
重参数化为:
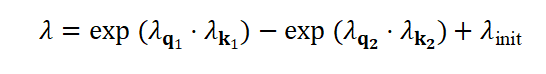
其中,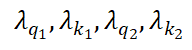 是可学习的向量,而
是可学习的向量,而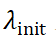 是用于初始化的常数。
是用于初始化的常数。
多头差分注意力
为了进一步提升模型的表达能力,DIFF Transformer 采用了多头机制。每个注意力头独立计算差分注意力,并将多头输出拼接为最终结果。具体实现如下:
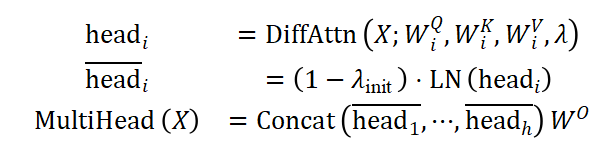
其中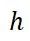 是注意力头的数量,
是注意力头的数量,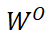 是输出投影矩阵。为了保持与 Transformer 梯度一致,DIFF Transformer 在每个头的输出后应用了独立的归一化层,采用 RMSNorm 实现。
是输出投影矩阵。为了保持与 Transformer 梯度一致,DIFF Transformer 在每个头的输出后应用了独立的归一化层,采用 RMSNorm 实现。
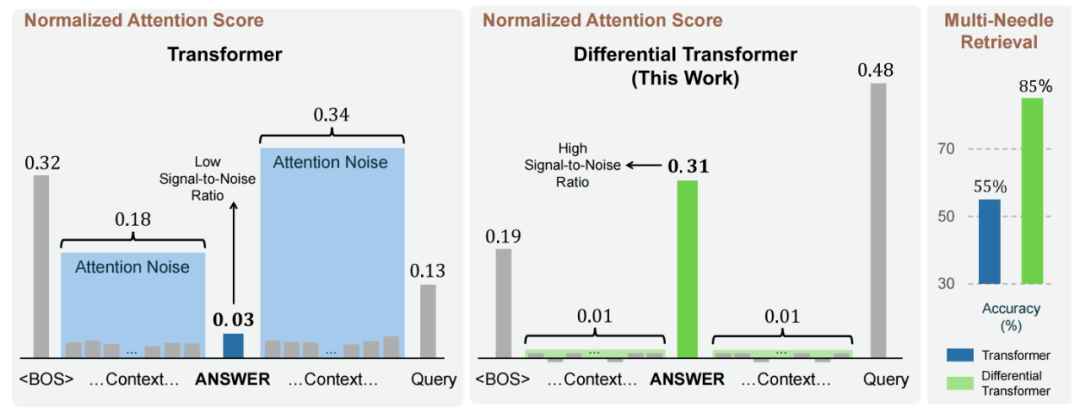
▲ 图2. Transformer与DIFF Transformer注意力分数分布可视化
图 2 展示了 DIFF Transformer 和传统 Transformer 在注意力分数分配上的显著差异。作者将一段关键信息插入大段不相关文本的中间位置,并对模型抽取关键信息时的注意力分数分配进行可视化。
传统 Transformer 的注意力分数被广泛分配到整个上下文中,只有极少分数分配至关键信息;而 DIFF Transformer 能够将更高的分数集中在目标答案上,并且几乎不向无关上下文分配注意力。
注意力分数分配的稀疏性与精准性也使得 DIFF Transformer 在处理长文本关键信息检索任务时显著优于 Transformer。

实验
作者通过一系列实验验证了 DIFF Transformer 在多个方面的卓越性能,证明了其在大语言模型中应用的独特潜力与优势。
语言建模
作者研究了 DIFF Transformer 在扩展模型规模和训练数据量时的性能,如图 3 所示。实验表明,DIFF Transformer 仅需约 65% 的参数规模或训练数据量即可达到与 Transformer 相当的语言建模性能。例如,6.8B 参数规模的 DIFF Transformer 在语言建模损失上与 11B 参数规模的 Transformer 相当。
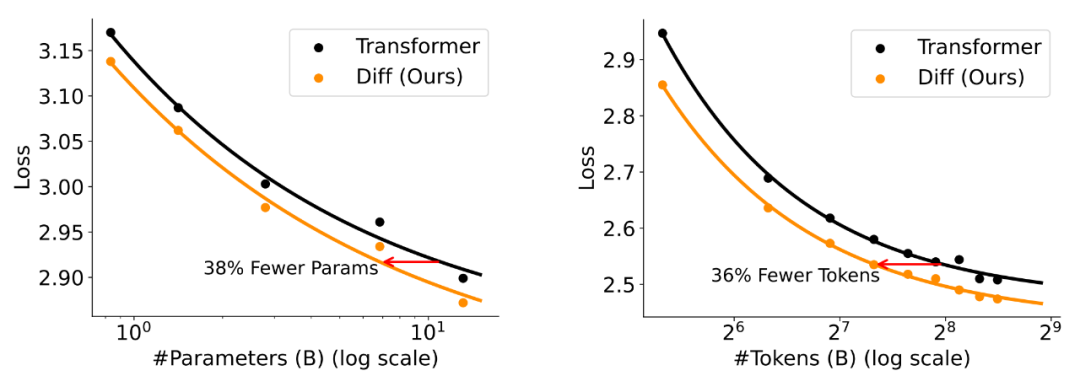
▲ 图3. 语言建模上的模型参数、训练数据量可扩展性实验
长文本建模
作者将模型扩展到 64K 上下文长度,并在长文本书籍数据上进行了评估。结果显示,考虑累积平均负对数似然(NLL)指标, DIFF Transformer 在不同序列位置上均优于 Transformer,能够更有效地利用长上下文信息。
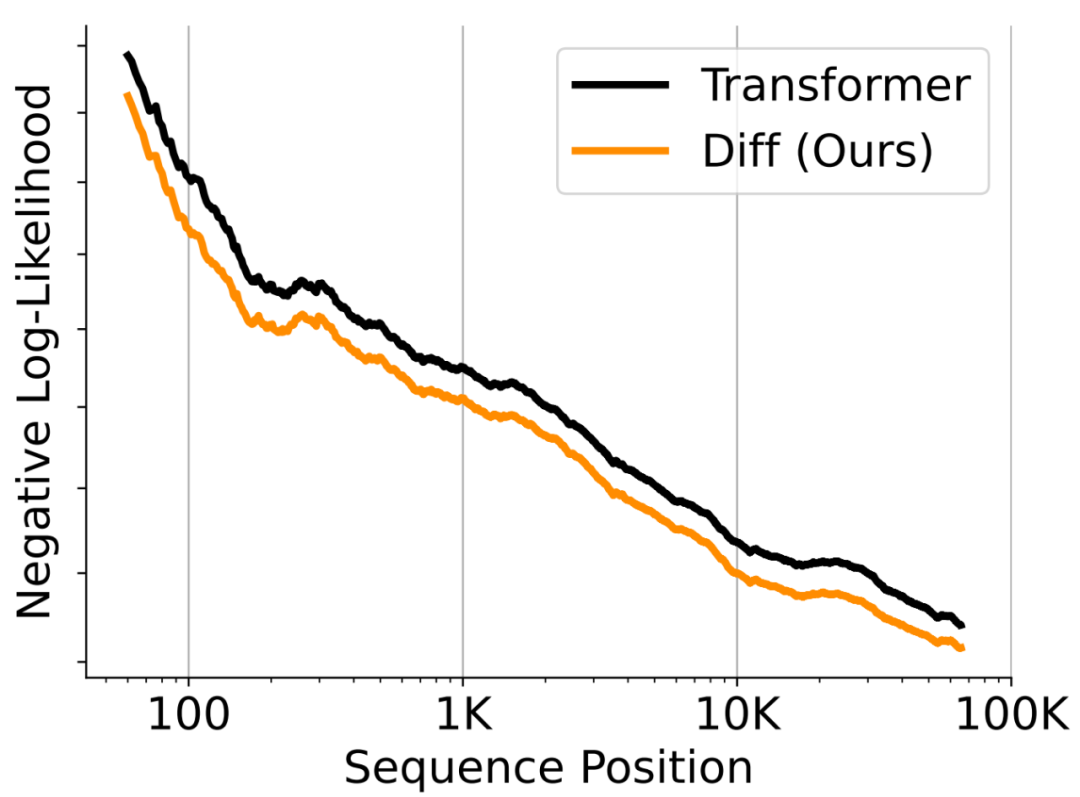
▲ 图4. 长文本书籍数据模型性能评估
关键信息检索
作者通过「多针检索」(Multi-Needle Retrieval)实验评估了模型从大量上下文中提取关键信息的能力,如图 5 所示。
实验表明,DIFF Transformer 在不同上下文长度和答案深度下均表现出更高的准确率,尤其是在文本较长以及答案位于文本更靠前位置时,优势更为明显。例如,在 64K 上下文中,DIFF Transformer 在答案位于 25% 深度时的准确率比 Transformer 高出 76%。
此外,统计信息显示,DIFF Transformer 在注意力分数分配上也表现出更高的聚焦能力,能够准确定位关键信息,并展现了更高的信噪比。
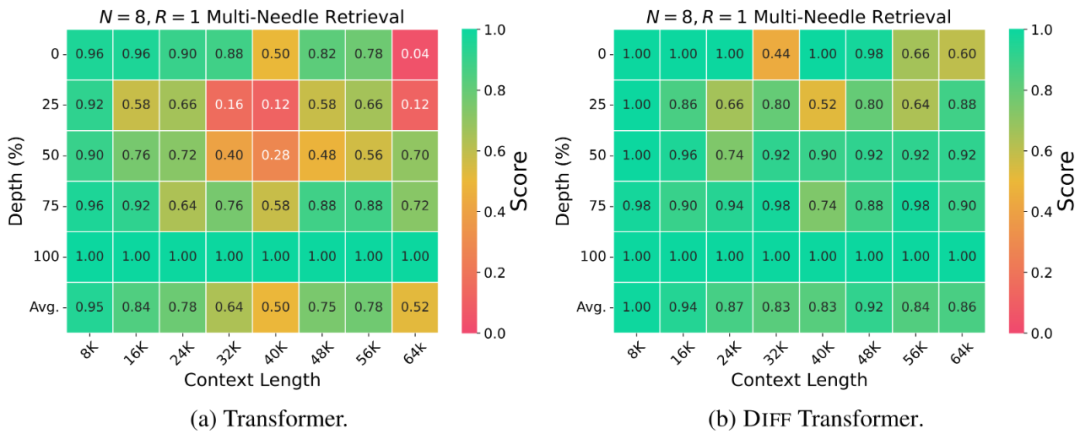
▲ 图5. 多针检索评估
上下文学习
作者从两个角度评估了 DIFF Transformer 的上下文学习能力:多样本上下文学习和样本顺序鲁棒性测试。 如图 6 所示,在多样本上下文学习任务中,作者使用了 4 个不同的数据集(TREC、TREC-fine、Banking-77 和 Clinic-150),并逐步增加示例数量,直到总长度达到 64K tokens。
结果显示,DIFF Transformer 在不同数据集上均优于 Transformer,平均准确率提升显著。
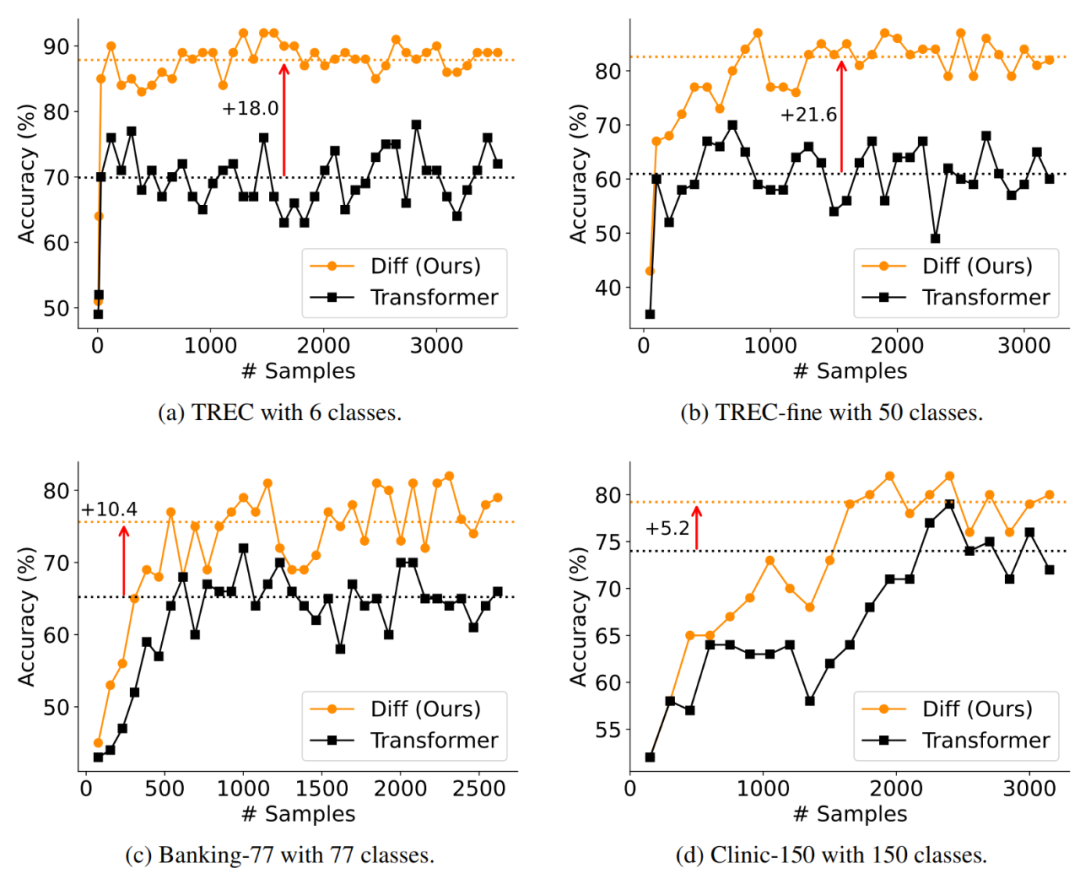
▲ 图6. 多样本上下文学习
在鲁棒性测试中,作者通过打乱示例顺序的方式评估了模型的性能稳定性。如图 7 所示,DIFF Transformer 在不同示例排列下的性能方差显著低于 Transformer,表明其对输入顺序的敏感性更低,具有更强的鲁棒性。
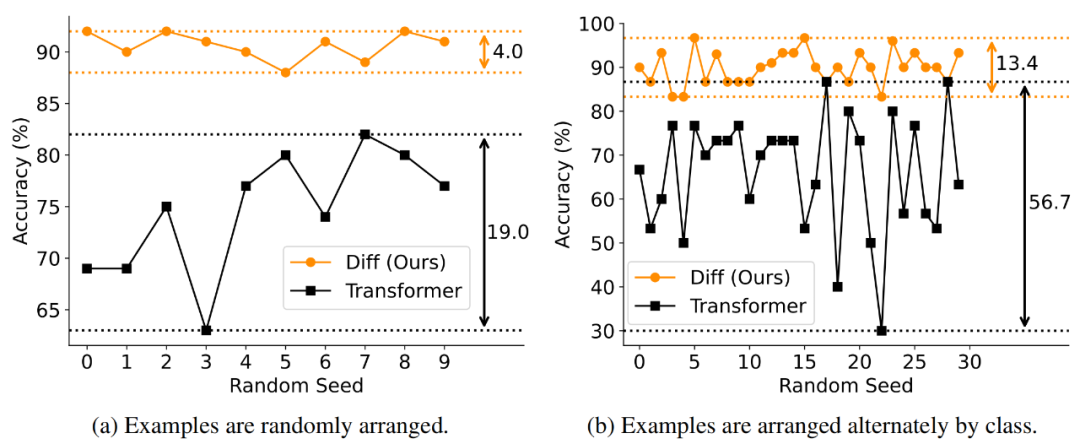
▲ 图7. 样本顺序鲁棒性测试
幻觉评测
作者利用文本摘要和问答任务作为两个典型的幻觉评测场景,评估了 DIFF Transformer 在降低大模型幻觉(hallucination)方面的表现。
结果如图 8 所示,DIFF Transformer 在生成摘要和回答问题时显著提升了准确率,减少了幻觉现象。这是因为差分注意力机制能够准确定位重要文段,避免无关上下文对模型预测的干扰。

▲ 图8. 利用文本摘要、问答任务进行幻觉评测
异常激活值分析
作者还发现 DIFF Transformer 能够显著减少模型激活中的异常值,这为模型激活值的量化提供了新的可能性。实验表明,DIFF Transformer 在注意力激活值(attention logits)和隐藏状态(hidden states)中的最大激活值显著低于 Transformer。
例如,在注意力激活值的 Top-1 激活值上,DIFF Transformer 比 Transformer 低了近 8 倍。利用这一性质,DIFF Transformer 在注意力激活值的低比特量化下的性能也优于 Transformer,如图 9 所示。
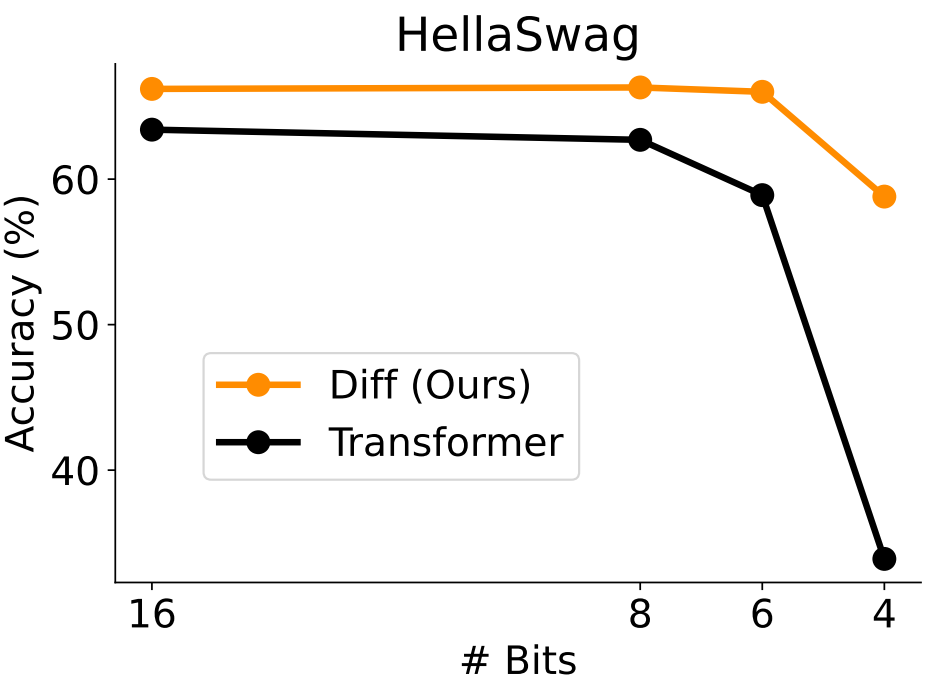
▲ 图9. 注意力激活值的低比特量化
数学推理能力
作者在数学推理任务上进一步验证了 DIFF Transformer 的性能。作者采用两阶段训练,在 3B 预训练模型的基础上进行有监督微调,并在 MATH 等 8 个数学数据集上评测模型性能。
在第一阶段,采用 20B token 合成数学数据对模型进行微调,使模型获得基础数学能力,评测结果如图 10 所示。从 15B token 开始,DIFF Transformer 展现出了显著优于 Transformer 的数学能力,至 20B token 结束的时候,准确率的差距达到了 11% 左右。
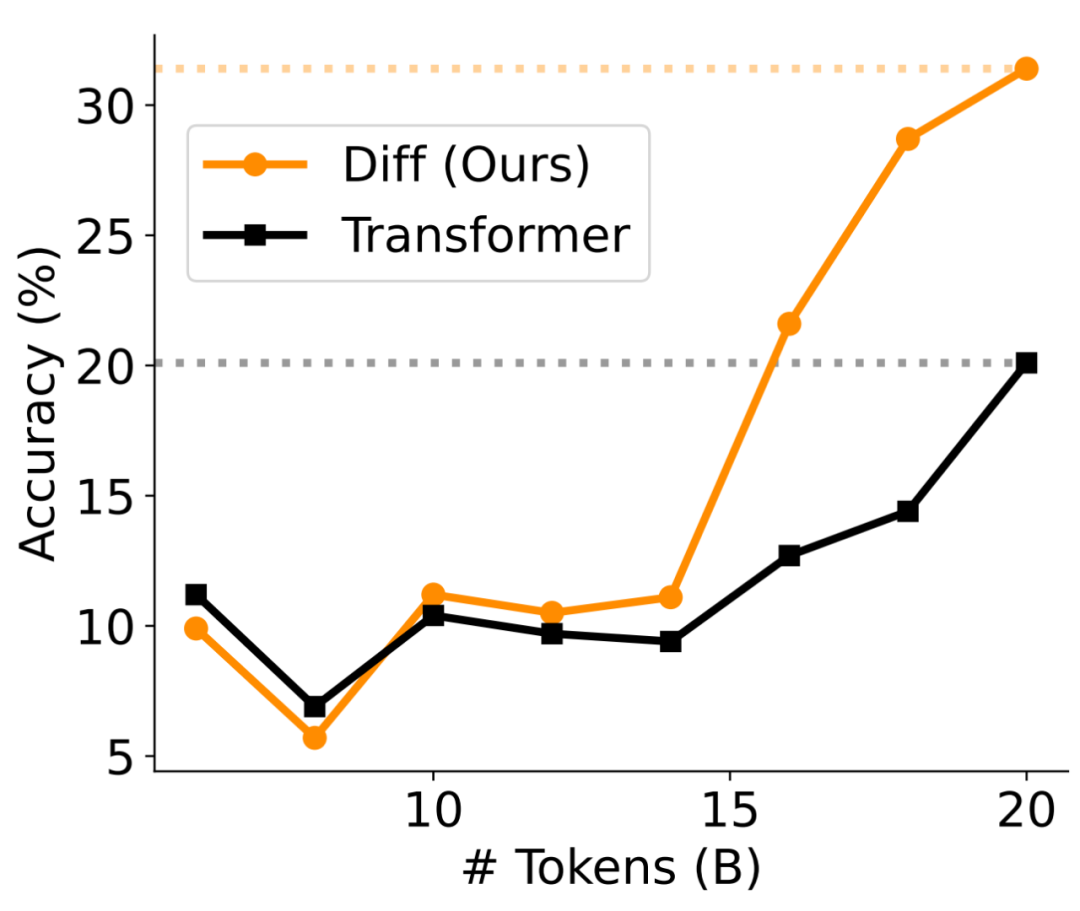
▲ 图10. 第一阶段数学合成数据微调
在第二阶段,作者利用 Deepseek-R1 输出所构造的数据集 OpenThoughts-114K-Math 对模型进行蒸馏,使模型更强大的深度推理能力。
如图 11 所示,在 8 个数据集上,DIFF Transformer 相较 Transformer 均有不同程度的提升,平均准确率提升了 7.5%,这表明差分注意力机制更强大的上下文建模能力在推理任务中也至关重要。
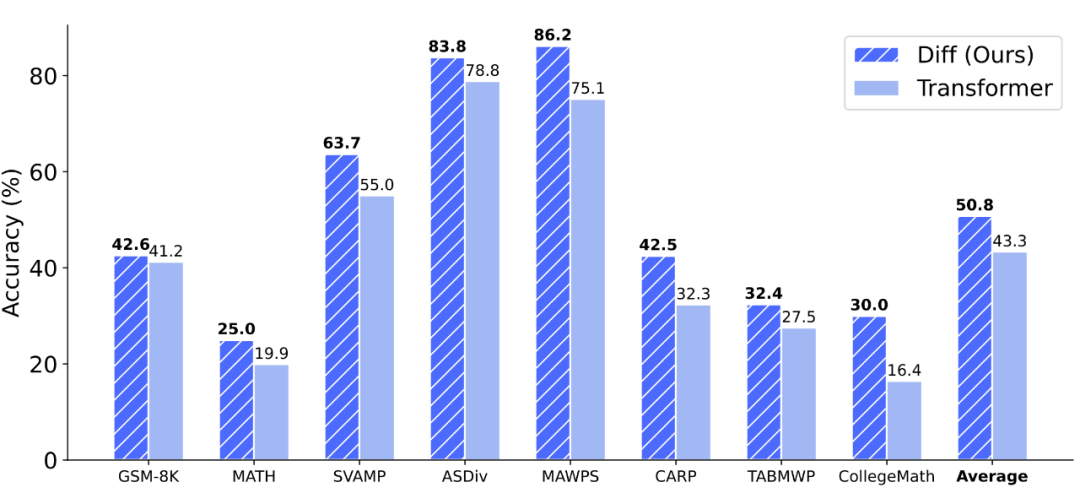
▲ 图11. 第二阶段深度推理能力评测
讨论与未来工作
DIFF Transformer 自发布以来获得了较大关注与讨论。作者在 Hugging Face 论文讨论平台、alphaXiv 平台上与社区开展了深入的探讨。
在 X 平台(原 Twitter)上,Google DeepMind 高级研究科学家(Senior Staff Research Scientist)Petar Veličković 与作者就文章中的理论分析展开讨论,ViT 核心作者 Lucas Beyer 也在阅读文章后撰写了一篇深入的论文总结,相关发帖已获得数十万浏览。
目前 DIFF Transformer 也已集成至 Hugging Face 的 transformers 库中。
Hugging Face:
https://huggingface.co/papers/2410.05258
alphaXiv:
https://www.alphaxiv.org/abs/2410.05258
Petar Veličković:
https://x.com/PetarV_93/status/1874820028975267866
Lucas Beyer:
https://x.com/giffmana/status/1873869654252544079
transformers库:https://github.com/huggingface/transformers/tree/main/src/transformers/models/diffllama
未来工作方面,作者认为可以利用 DIFF Transformer 的性质设计低比特注意力算子,以及利用差分注意力的稀疏特性进行键值缓存(key-value cache)的剪枝。
此外,将 DIFF Transformer 应用在除语言以外的其他模态上也值得探索。近期工作 DiffCLIP 将差分注意力扩展至视觉、多模态领域,揭示了 DIFF Transformer 在不同模态任务中的更多结构特性与应用潜力。
DiffCLIP:
https://arxiv.org/abs/2503.06626

总结
本文的贡献主要在两个方面:
1. DIFF Transformer 通过创新的差分注意力机制,有效解决了传统 Transformer 在处理文本时受到噪声干扰、注意力分配不准确的问题;
2. 凭借对关键信息的关注和对噪声的抵御能力,DIFF Transformer 在语言建模、长文本建模、关键信息检索、数学推理、对抗幻觉、上下文学习、模型激活值量化等任务中表现出色,有望在自然语言处理、多模态等领域作为基础模型架构。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









