







©PaperWeekly 原创 · 作者 | 李川皓
单位 | 上海人工智能实验室、北京理工大学
研究方向 | 多模态大语言模型、互联网检索增强

背景
随着人工智能的快速发展,大模型已逐步融入人们的日常工作和生活中。众所周知,大模型的训练和微调会消耗大量计算资源和时间,这意味着频繁更新大模型的参数是不切实际的。
然而,现实世界中的信息是实时产生的且不断变化的。这使得大模型在完成训练后,对于后续新产生的信息感到陌生,所以无法提供准确可靠的反馈。举例来说,一个在 5 月份完成训练的大模型,无法对黑神话悟空(8 月份发布)游戏内容相关的提问给出准确的回答。

为此,我们提出即插即用的 SearchLVLMs 框架,可以无缝整合任意的多模态大模型。该框架在推理阶段对大模型进行互联网检索增强,使得大模型无需微调即可对实时信息进行准确的反馈。

论文标题:
SearchLVLMs: A Plug-and-Play Framework for Augmenting Large Vision-Language Models by Searching Up-to-Date Internet Knowledge
文章链接:
https://arxiv.org/abs/2405.14554
项目主页:
https://nevermorelch.github.io/SearchLVLMs.github.io/
1. SearchLVLMs:我们提出首个辅助多模态大模型对实时信息进行反馈的开源检索增强框架。该框架主要包括查询生成、搜索引擎调用、分层过滤三个部分。以视觉问答为例,该框架会基于问题和图片生成查询关键词,并调用搜索引擎查找相关信息,再由粗到细地对检索结果进行过滤,得到对回答该问题有帮助的信息。这些信息会以 prompt 的形式在推理阶段提供给模型,以辅助回答。
2. UDK-VQA:我们提出一个数据生成框架,可以自动生成依赖实时信息进行回答的视觉问答数据。基于此框架,数据集可以完成动态更新,以保证测试数据的时效性。目前已有两个版本的数据集:UDK-VQA-240401-30、UDK-VQA-240816-20。涉及到的时间跨度分别是 24 年 4 月 1 日 - 24 年 4 月 31 日和 24 年 8 月 16 日 - 24 年 9 月 5 日。
3. 广泛的实验评估:我们在超过 15 个开源、闭源模型上进行了实验,包括 GPT-4o、Gemini 1.5 Pro、InternVL-1.5、LLaVA-1.6 等。在 UDK-VQA 数据集上的回答准确率,配备了 SearchLVLMs 的 SOTA LVLMs 超过了自带互联网检索增强的 GPT-4o 模型 35%。
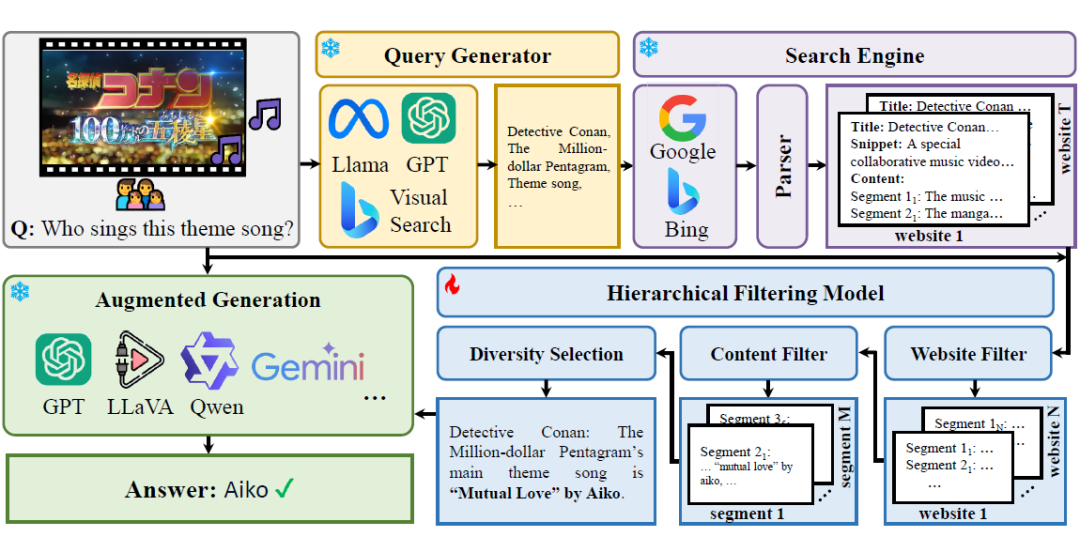

SearchLVLMs框架
如上图所示,SearchLVLMs 框架主要由三部分组成:查询生成、搜索引擎调用、分层过滤。
1. 在查询生成阶段,需要对问题和图像进行充分地理解,以转化为适用于搜索引擎的文本查询。对于问题而言,直接使用手工设计的 prompt 调用 LLM 得到问题查询词。对于图像而言,调用必应视觉搜索得到包含该图像或与该图像相关的网页,提取这些网页的题目/快照的最长公共子串作为图像查询词。
2. 在搜索引擎调用阶段,用户可以根据问题类型自主选择调用的搜索引擎类别。比如:对于实时性较强的新闻相关问题,可以选择调用必应新闻搜索;对于常识性问题,可以选择调用必应通用搜索。调用搜索引擎后会得到多个网页的题目、摘要和链接。
3. 在分层过滤阶段,首先调用网页过滤器对得到的网页进行初筛,基于网页的题目和摘要对这些网页进行重排。对于排序靠前的网页,使用爬虫获取网页的文本内容,每三句切分成一个片段,使用内容过滤器对这些片段进行重排。
对于排序靠前的片段,基于 CLIP 特征对它们进行聚类,选择离每个聚类中心的最近的片段,以避免内容重复片段对大模型预测带来的误导。被选择的片段被直接拼接在一起,用于提示大模型。
其中,网页过滤器和内容过滤器是两个独立训练的 LLaVA-1.5 模型,作用是为网页/片段进行打分——网页/片段对于回答该问题的帮助程度。为了训练这两个过滤器,也为了测试大模型对实时信息的反馈能力,我们进一步提出了一个数据生成框架——UDK-VQA,如下图所示。
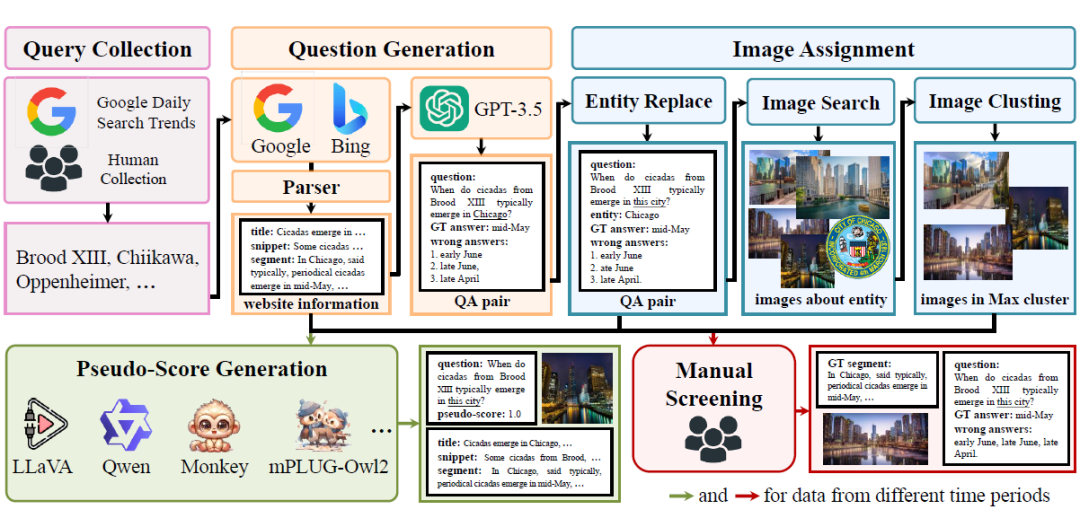

UDK-VQA数据生成
UDK-VQA 数据生成主要遵循五个步骤:查询搜集、问题生成、图像分配、伪标注生成、人为验证。
1. 查询搜集。查询搜集主要包括两方面,一方面是从谷歌每日搜索趋势上爬取热门搜索词,另一方面是人为搜集一些热门搜索词来对前者进行补充。
2. 问题生成。我们首先根据搜集到的搜索词调用搜索引擎得到相关的新闻,将新闻内容进行切分,得到多个内容片段。然后,我们要求 GPT 根据内容片段自问自答,得到<问题,答案>的集合。
3. 图像分配。在图像分配阶段,我们会提取出问题中的实体,使用图片搜索引擎得到实体的图片,并将问题中的实体单词替换为其上分位词,与图片一起组成视觉问答样本。
4. 伪标注生成。为了训练网页过滤器和内容过滤器,我们需要对网页/片段进行打分。对于一个视觉问答样本和一个网页/片段,我们基于两个原则进行打分:
如果该样本是基于该网页/片段生成的,分数为 1.0;
如果该样本不是基于该网页/片段生成的,我们使用 5 个开源模型在该网页/片段下尝试回答该样本,根据模型回答的正确率进行打分。
基于这样的伪标注方法,我们构造了 ~80w 样本用于训练。
5. 人为验证。构造测试集时,我们对第 3 步得到的视觉问答样本进行了人为筛选,确保测试样本的正确性。为了避免训练数据和测试数据需要参考相似的实时信息,在构造训练集和测试集时,我们使用不同时间区间的谷歌每日搜索趋势来爬取热门搜索词。
下图中(a)、(b)、(c)分别展示了训练样本、测试样本和测试样本的分布。
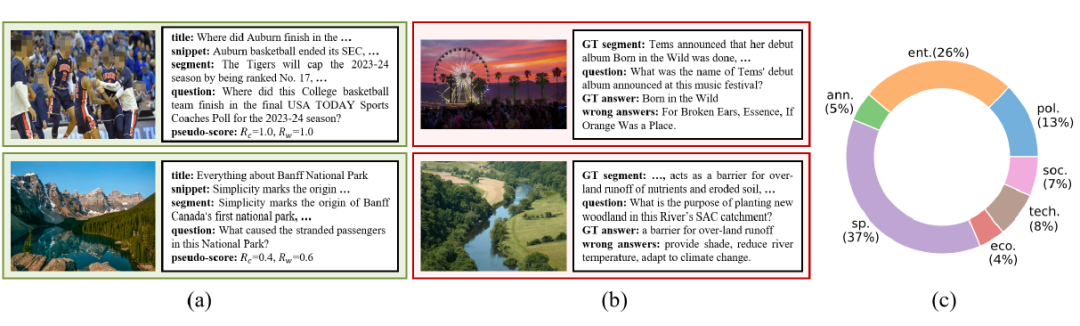
基于我们提出的数据生成框架,很容易可以构造出需要实时信息进行回答的视觉问答样本。我们会不断更新测试集,保证测试样本的时效性。目前,我们已经构造了两个版本的测试集,分别涉及到 2024 年 5 月份和 2024 年 9 月份的信息。

实验结果与结论
我们在 UDK-VQA 上测试了 15 个现有的 LVLMs,主要实验结果如下表所示。
其中,Raw 表示模型的原始版本(没有检索增强功能)、Long-Context(LC)表示将搜索引擎返回的网页爬取内容后,直接拼接起来提示模型,IAG 表示使用了模型内嵌的互联网检索增强能力。Gen.、Cham. 和 CLIP→FID(C→F)分别表示 [1]、[2] 和 [3] 中的方法。

从实验结果中可以发现:
1. 接收长上下文输入可以一定程度上避免对搜索引擎的返回内容进行二次筛选。Gemini Pro 1.5(LC)的性能高于内嵌互联网检索增强的 GPT-4V 和 GPT-4o,但是长上下文会引入额外的计算消耗,并引入一些不必要的信息对模型造成误导。经过 SearchLVLMs 的分层过滤模型进行二次筛选还有,可以进一步提升模型性能。
2. 具备检索增强能力的闭源商用模型在性能上显著高于不具备检索增强能力的开源模型。GPT-4V 和 GPT-4o 由于内嵌互联网检索增强模块,在准确率上大幅领先开源模型,如 LLaVA-1.6 和 InternVL-1.5,差距约为 20%~30%。
3. 我们的 SearchLVLMs 框架可以整合任意的多模态大模型,并大幅度提高它们对于依赖实时信息的问题的回答能力。无论是在闭源商用模型 Gemini 1.5 Pro、GPT-4o、GPT-4V,还是开源 SOTA 模型 LLaVA-1.6 和 InternVL-1.5上,SearchLVLMs 均能带来超过 50% 的性能提升。
4. SearchLVLMs 带来的性能提升,远高于已有方法。我们对比了检索增强方法 Gen.、C→F 和调用搜索引擎来辅助回答的框架 Cham.,SearchLVLMs 在应对实时信息检索任务时,表现出明显的优越性。
5. 使用 SearchLVLMs 整合开源模型,性能可以大幅超过内嵌互联网检索增强能力的闭源商用模型。InternVL-1.5 + SearchLVLMs 的准确率为 92.9%,远高于GPT-4o(IAG)的57.8%。这一发现表明,开源模型具有巨大的潜力,SearchLVLMs 在性能、可定制性和透明度上具有显著的优势。

参考文献
[1] Yu et al. Generate rather than retrieve: Large language models are strong context generators. arXiv 2023.
[2] Lu et al. Chameleon: Plug-and-play compositional reasoning with large language models. NeurIPS 2023.
[3] Chen et al. Can pre-trained vision and language models answer visual information-seeking questions? EMNLP 2023.
更多阅读



#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









