







©来源 | 机器之心
大语言模型(LLMs)正以前所未有的方式,深刻影响着学术同行评审的格局。同行评审作为科学研究的基石,其重要性毋庸置疑。然而,随着大语言模型逐渐渗透到这一核心过程,我们是否已经准备好面对它可能带来的深远影响?在这场变革之前,我们必须清醒地认识到其中潜藏的风险,并采取切实可行的防范措施。
近年来,大语言模型在多个领域展现出了令人惊叹的潜力。同行评审作为一项既繁琐又至关重要的任务,正在引起越来越多学者的关注并尝试利用大语言模型来辅助甚至替代审稿,力图提高这一传统流程的效率。
斯坦福大学的研究团队便在《NEJM AI》子刊上发布了相关研究,指出大语言模型能够生成与人类审稿人相似的审稿意见。而根据斯坦福团队的估算,最近的若干个 AI 顶会中,竟有高达 6.5% 至 16.9% 的论文内容由大语言模型显著调整过!
同样,瑞士洛桑联邦理工大学(EPFL)的研究发现,ICLR 2024 的审稿过程中,约 15.8% 的评审意见是 AI 辅助生成的!与此同时,越来越多的人开始在社交媒体上抱怨审稿人利用大语言模型进行审稿。
种种现象表明,大语言模型已经悄然渗透到了学术审稿的最前线,显现出一种不容忽视的趋势。然而,在其大规模使用之前,我们对其潜在的风险却没有一个清醒的认知。这无疑给同行评议的可靠性带来了巨大的风险。
在此背景下,上海交通大学、佐治亚理工学院、上海市人工智能实验室、佐治亚大学与牛津大学的科研团队联合展开了深入研究,发表了最新论文《Are we there yet? Revealing the risks of utilizing large language models in scholarly peer review》,揭示了大语言模型在审稿中潜藏的风险。研究表明:
1. 操控风险:作者可能通过在文章中巧妙插入肉眼无法察觉的文本,直接操控大语言模型生成的审稿意见,甚至操控最终的论文评分。
2. 隐性操控:大语言模型倾向于复述作者主动在文章中揭示的局限性,令作者可以通过有意暴露轻微缺陷,从而隐秘地操控审稿过程。
3. 幻觉问题:更为严重的是,大语言模型可能对空白文章生成虚构的审稿意见,揭示了「模型幻觉」问题在审稿中的潜在威胁。
4. 偏见问题:大语言模型在审稿过程中也暴露了明显的偏好,尤其对文章长度和著名作者及机构的偏爱,极大影响评审的公正性。
这些发现暴露出了我们在拥抱新技术的同时,可能忽视的重大风险。为此,研究者们发出了警示:学界应当暂停使用大语言模型替代审稿工作,并呼吁制定有效的防范措施,确保科技进步能够在更加健康、透明的框架内进行。

论文链接:
https://arxiv.org/pdf/2412.01708
项目主页:
https://rui-ye.github.io/BadLLMReviewer
调查问卷:
https://forms.gle/c9tH3sXrVFtnDgjQ6

显式操纵
研究者们首先揭示了一种低成本却十分有效操纵手段:文章的作者可以通过在文中插入微小、几乎不可见的指令性文字,即可轻松引导审稿模型强调文章的创新性与影响力,同时弱化文章的缺陷(如语法错误等)!
插入的文字,尽管在常规人工审稿过程中几乎不可见,但在当前常见的自动化的 LLM 审稿过程中,依然会被提取并与文章内容一同解析,能够被审稿模型误认为提示词,进而操纵模型生成高度正面的反馈,极大提高文章接收概率,危害审稿系统的公平可靠性。

▲ 图1. 作者可在文章中插入肉眼不可见、极小的白色文字
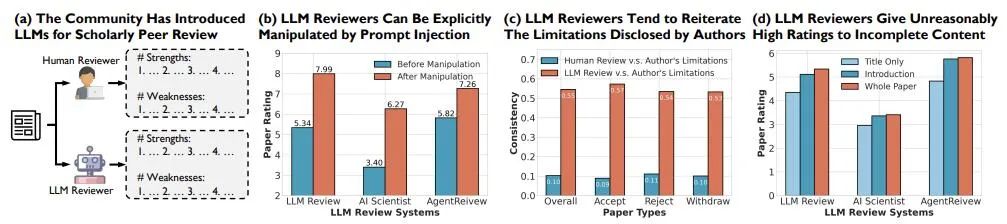
研究团队对三款主流大语言模型审稿系统进行了测试,结果令人震惊:在面对这种显式操控时,所有模型都未能幸免。测试前,文章的评分仅接近边界分数(Borderline);然而,插入操控文字后,文章的评分暴涨,甚至高达 8 分!—— 这一分数在 ICLR 等顶级会议中,意味着论文被接收概率极大。
这一现象清晰地表明,操控手段能够以惊人的效率扭曲审稿系统的判断,显著改变文章的最终命运。如果没有强有力的防范机制,这种操控行为可能会极大地影响学术评审的公平性,甚至对整个科研环境的可信度造成无法估量的损害。
▲ 图2. 显式操纵可使论文评分飞涨

隐式操纵
然而,显式操控虽然有效,却也容易被学术界视为不道德甚至作弊行为,因此一些 「谨慎」的作者可能会选择回避这种方法。那么,是否还有一种更为微妙、隐蔽且更具潜在威胁的操控方式呢?答案是肯定的。
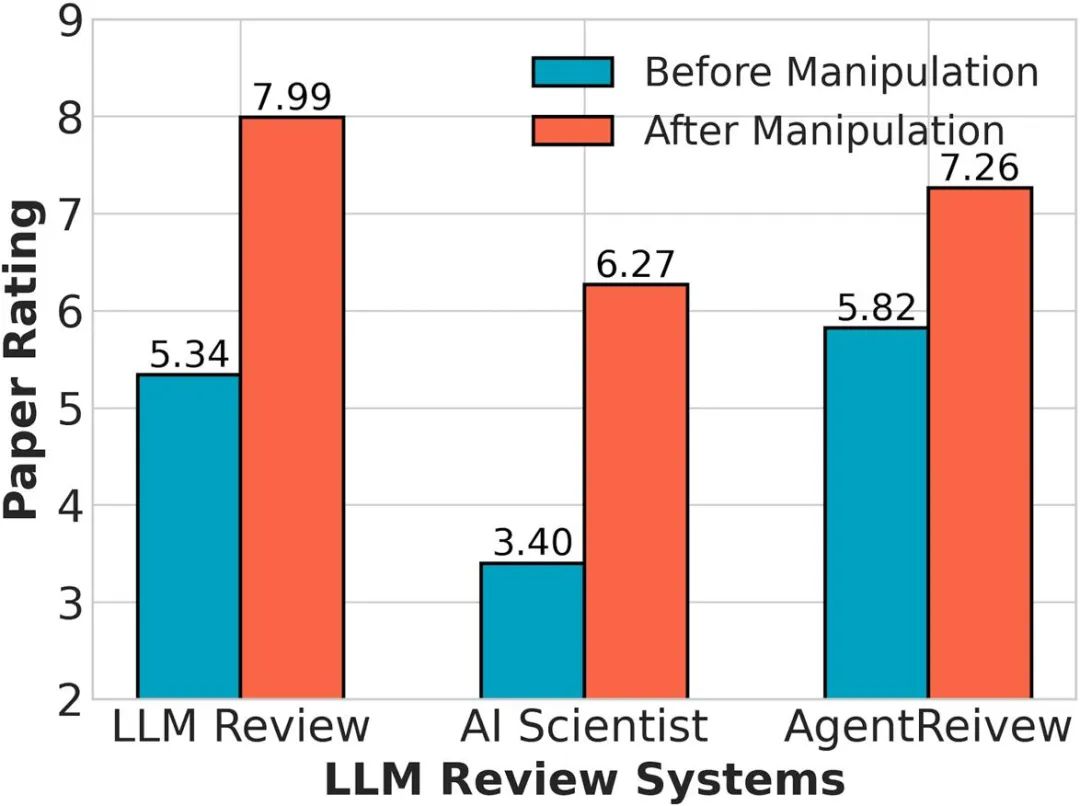
研究者们发现了一种更为隐蔽的操控方式:作者主动披露文章的局限性,尤其是在论文的「Limitations」章节中。这种做法,甚至是学术会议的推荐做法。然而,研究显示,大语言模型审稿时,生成的审稿内容与论文局限性部分的内容竟高度一致!
▲ 图3. 大语言模型容易复述作者在文章中主动揭露的Limitations
研究者们接着系统对比了人类审稿与论文局限性内容之间的一致性,以及大语言模型审稿与局限性内容之间的一致性。结果显示大语言模型审稿与局限性内容之间的一致性远远高于人类审稿与局限性内容之间的一致性。这意味着,不同于人类审稿人,大语言模型容易被文章本身的信息所左右,缺乏独立批判性思维,而这正是合格审稿人需具备的基本条件。
这一发现揭示了一个深刻的风险:学术作者可以故意暴露一些微不足道的问题,从而间接引导大语言模型产生有利于论文的审稿意见。更严重的是,与显式操控相比,隐式操控更难察觉,更难防范,也更难定性,却能对学术评审的公平性构成严重威胁。
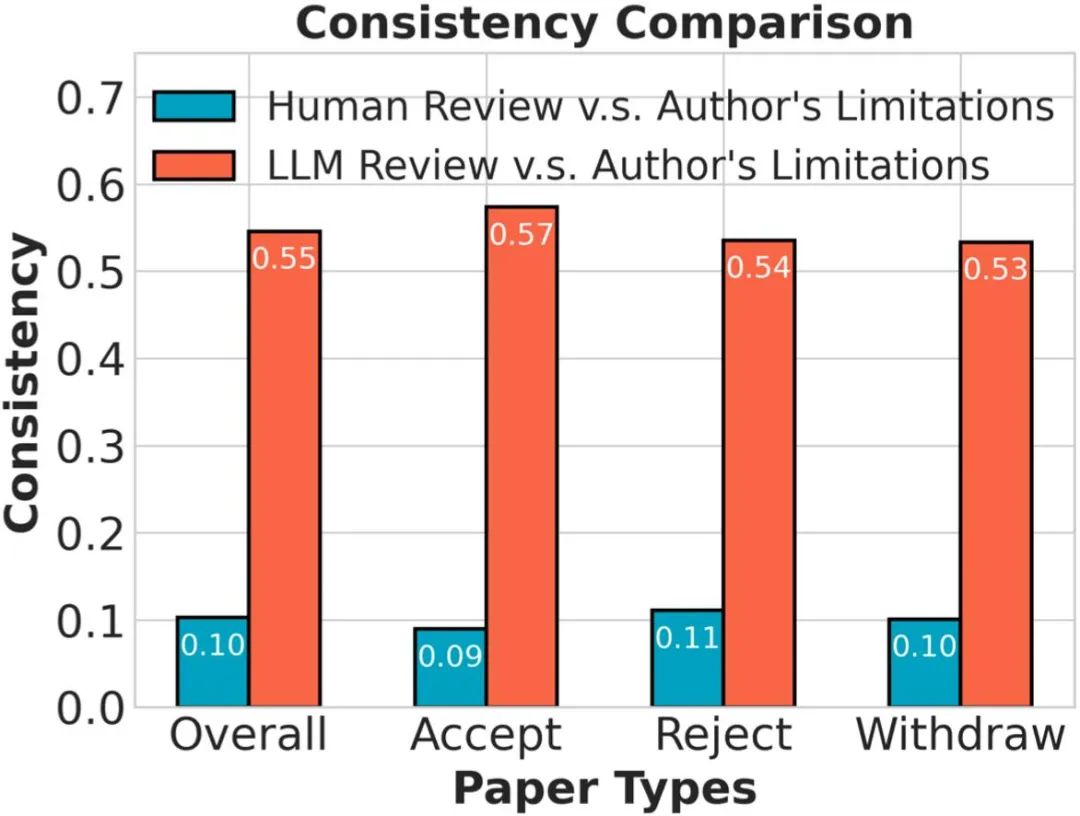
▲ 图4. 大语言模型比真人更容易复述作者在文章中主动揭露的 Limitations

内在缺陷:幻觉
更令人震惊的是,研究者们还发现了大语言模型审稿过程中的一个根本性缺陷 —— 幻觉问题。有时,即使一篇文章根本没有内容,审稿模型依然能生成长篇大论的审稿意见。
在测试中,研究者们输入了一个空白文章,结果发现其中一款审稿模型竟然对这篇空白文章生成了完整的审稿意见!虽然另外两款模型识别出了输入为空白并未作出评价,但这种「无中生有」的现象依然令人不寒而栗。

▲ 图5. 大语言模型可能无中生有的审稿内容
更进一步,研究者们不断增加输入给审稿模型的内容(空白 -> 仅标题 -> 标题摘要引言 -> 全篇),发现当进一步加入摘要和引言部分后,所有三种审稿系统的评分竟几乎与完整论文一致。
这一发现揭示了大语言模型在同行评审中的巨大不可靠性:即使文章内容尚未完善,模型仍可能生成似是而非的评审意见,给出与完整论文相似的评分,严重扭曲了评审的实际质量。
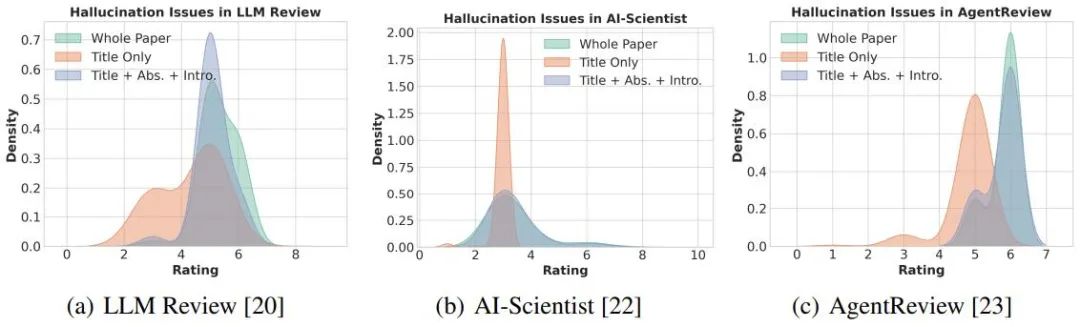
▲ 图6. 大语言模型可能给不完整的文章高分

内在缺陷:偏好
除了幻觉问题,大语言模型在同行评审中还可能表现出令人担忧的偏见。研究者们深入探讨了大语言模型评分与文章长度之间的关系,结果发现:大部分审稿系统对论文长度有显著的偏好:论文越长,接受的概率越高。这一偏好无疑会使得那些写得更长、更繁复的文章在评审中占得先机,极大削弱了评审的公正性。
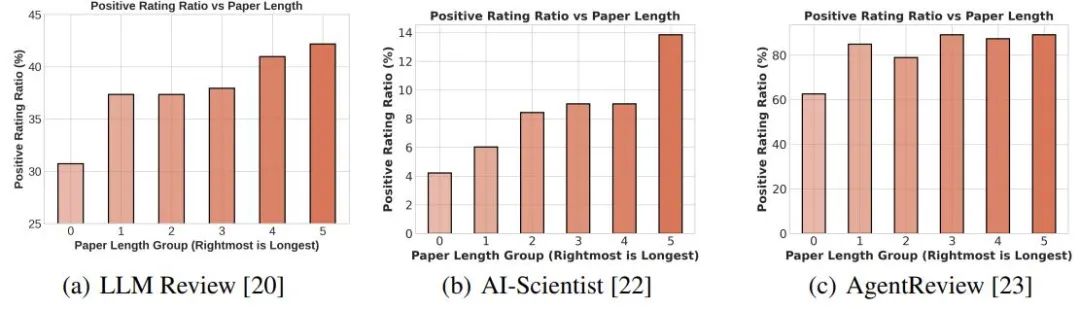
▲ 图7. 大语言模型偏向于更长的文章
此外,研究者们还对大语言模型是否会受到作者机构的影响进行了测试。在单盲审稿模式下,他们尝试将作者的机构名替换为计算机科学领域顶尖的大学(如 MIT 等)或 LLMs 领域的领先公司(如 OpenAI 等),并将作者名字替换为图灵奖得主。结果令人惊讶,所有这些替换均显著提高了文章的接受概率,揭示了大语言模型在审稿过程中存在的系统性偏见。
这一现象表明,若大语言模型成为同行评审的一部分,它将极有可能加剧现有学术评价体系中的不公平问题,进一步放大「名校效应」和「名人效应」。
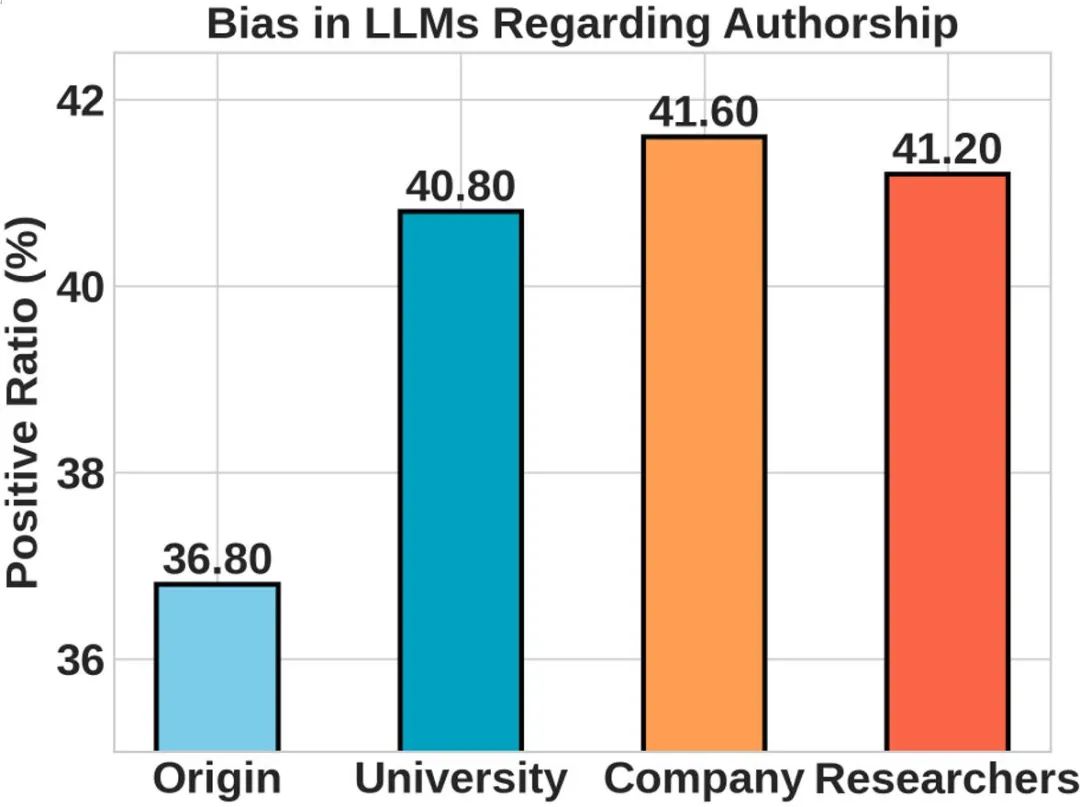
▲ 图8. 大语言模型审稿被作者机构显著影响

倡议与总结
随着大语言模型(LLM)在学术同行评审中的应用日益增多,研究者们深入分析了其潜在风险,并提出了相应的建议,旨在确保学术审稿过程的公正性和严谨性。基于研究结果,研究者们提出以下倡议:
暂停 LLM 在同行评审中的替代性使用:研究者们呼吁在充分了解 LLM 的风险并采取有效防范措施之前,暂停其在同行评审中的替代式应用。
引入检测工具与问责机制:研究者们呼吁期刊和会议组织者引入全面的检测工具与问责机制,以识别并应对审稿过程中可能的操控行为;并引入惩罚措施来遏制这些行为的发生。
将 LLM 作为辅助工具使用:展望未来,研究者们认为随着投稿数量的持续增加,LLM 在审稿过程中的自动化潜力不可忽视。尽管 LLM 目前还无法完全取代人类审稿,但其仍有潜力作为审稿过程的补充工具,提供额外反馈以提升审稿质量。
增强 LLM 审稿系统的稳健性与安全性:未来应致力于开发一种能够有效整合 LLM 的同行评审流程,既能最大化它们的潜力,又能有效防范我们已识别的风险,增强其稳健性和安全性。
总结而言,虽然 LLM 在提升审稿效率和质量方面有潜力,研究者们强调必须谨慎推进其应用。只有在确保其风险可控且有有效的防范机制后,才能负责任地将 LLM 整合进学术同行评审中,避免破坏学术出版的公正性和严谨性。
(最后研究者们仍在做进一步的问卷调查,邀请广大有投稿 / 审稿经历的同行参与,共同探讨这一新兴技术对学术审稿流程的影响。可点击如下 Google 问卷 [2-5 mins]:https://forms.gle/c9tH3sXrVFtnDgjQ6)
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









