







©作者 | 汤轶文
单位 | 上海科技大学、上海AI Lab
研究方向 | 3D视觉,大模型高效迁移
许多近期的研究致力于开发大型多模态模型(LMMs),使 LLMs 能够解读多模态信息,如 2D 图像(LLaVA)和 3D 点云(Point-LLM, PointLLM, ShapeLLM)。主流的 LMM 通常是依赖于强大但计算量大的多模态编码器(例如,2D 的 CLIP 和 3D 的 I2P-MAE)。
虽然这些预训练编码器提供了强大的多模态嵌入,富含预先存在的知识,但它们也带来了挑战,包括无法适应不同的点云分辨率,以及编码器提取的点云特征无法满足大语言模型的语义需求。
因此,作者首次全面研究了无编码器架构在 3D 大型多模态模型中应用的潜力,将 3D 编码器的功能直接整合到 LLM 本身。最终,他们展示了首个无编码器架构的 3D LMM—ENEL,其 7B 模型与当前最先进的 ShapeLLM-13B 相媲美,表明无编码器架构的巨大潜力。

论文标题:
Exploring the Potential of Encoder-free Architectures in 3D LMMs
作者单位:
上海人工智能实验室,西北工业大学,香港中文大学,清华大学
代码链接:
https://github.com/Ivan-Tang-3D/ENEL
论文链接:
https://arxiv.org/pdf/2502.09620v1

背景和动机
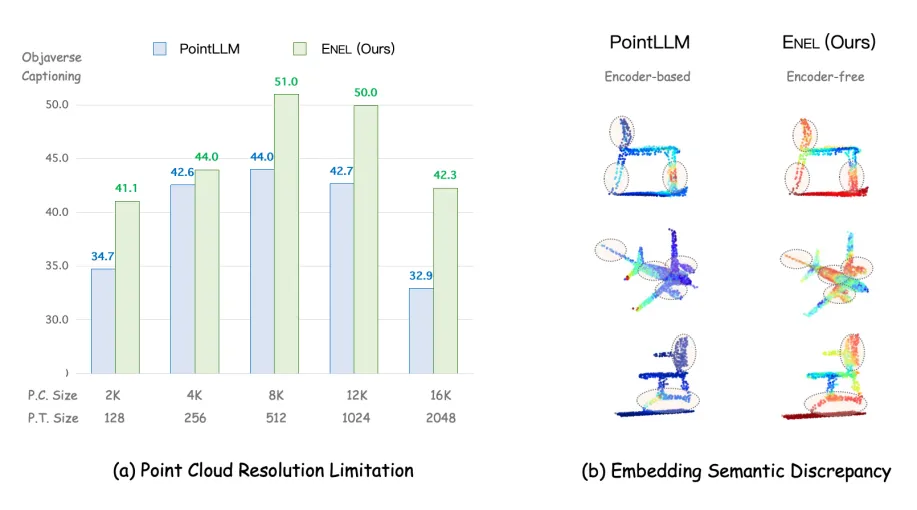
对于 3D LMMs,基于编码器的架构有以下潜在缺点:
1. 点云分辨率限制:3D 编码器通常在固定分辨率的点云数据上进行预训练,例如 PointLLM 的编码器 Point-BERT 使用 1,024 个点。然而,在推理过程中,输入点云的分辨率可能会有所不同(例如,8,192 个点或 512 个点)。
训练和推理分辨率之间的差异可能导致在提取 3D 嵌入时丢失空间信息,从而使 LLMs 理解变得困难。如(a)所示,PointLLM 在不同的点云分辨率输入下性能差异过大,而我们提出的 ENEL 显示出了一定的鲁棒性。
2. 嵌入语义差异:3D 编码器通常采用自监督方法(如掩码学习和对比学习)进行预训练,但 3D 编码器和大语言模型的训练分离导致训练目标可能与 LLMs 的特定语义需求不一致,无法捕捉到 LLMs 理解 3D 物体所需的最相关语义。
即使使用投影层将 3D 编码器与 LLMs 连接,简单的 MLP 也往往不足以进行完全的语义转换。如图(b)所示,ENEL 架构中 text token 更能关注到点云物体的关键部位,如椅脚和机翼。

具体方案
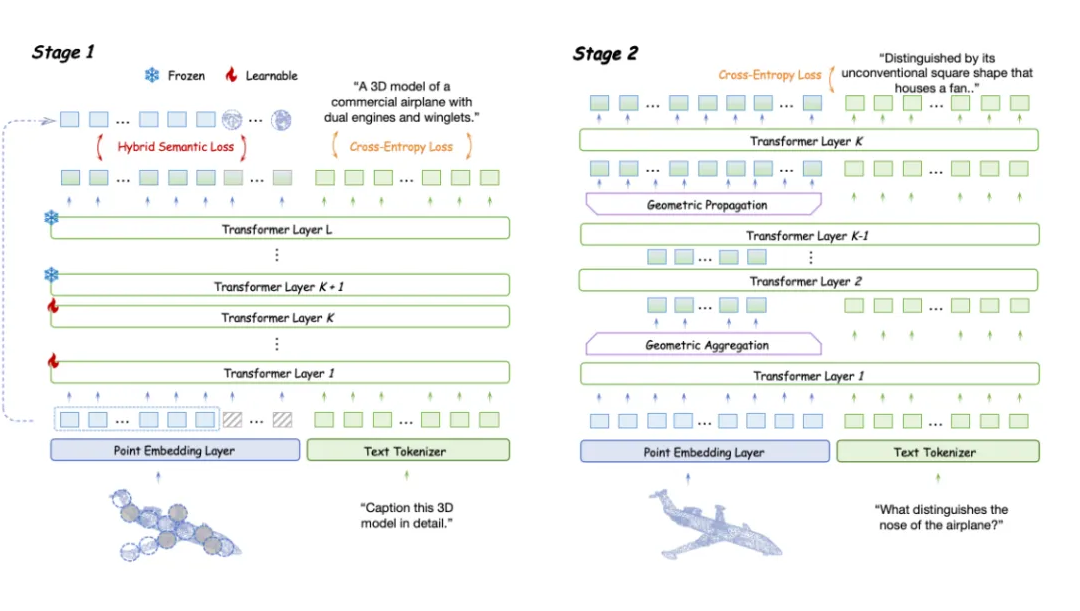
作者选择 PointLLM 作为基准模型进行探索,并使用 GPT-4 评分标准在 Objaverse 数据集上评估不同策略的表现。在无编码器结构的探索中他们提出以下两个问题:
1. 如何弥补 3D 编码器最初提取的高层次 3D 语义?在 3D LMMs 中,完全跳过编码器会导致难以捕捉 3D 点云的复杂空间结构。
2. 如何将归纳偏置整合到 LLM 中,以便更好地感知 3D 几何结构?传统的 3D 编码器通常将显式的归纳偏置嵌入到其架构中,以逐步捕捉多层次的 3D 几何。例如,像 Point-M2AE 这样的模型使用局部到全局的层次结构,这一概念在 2D 图像处理的卷积层中也很常见。
LLM 嵌入的语义编码
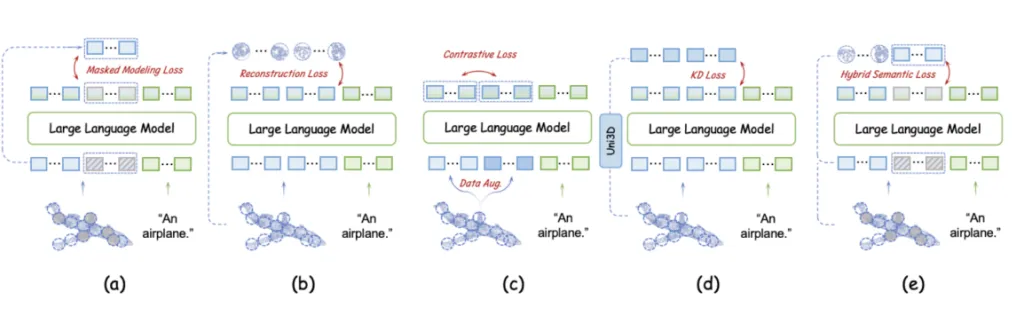
因为缺乏 3D 编码器导致点云语义信息的编码不足,极大地阻碍了 LLM 理解点云的结构细节。现有的大多数 3D 编码器使用自监督损失将点云的高层语义嵌入到 Transformer 中,主要分为四种类型:掩蔽建模损失(a)、重建损失(b)、对比损失(c)和知识蒸馏损失(d)。
基于 token embedding 模块和 LLM 可学习层,作者在预训练阶段实现并评估了这些损失对无编码器 3D LMM 的影响,并提出混合语义损失。
点云自监督学习损失通常有助于无编码器 3D LMM。自监督学习损失通过特定的任务设计对复杂的点云进行变换,促使 LLM 学习潜在的几何关系和高层次的语义信息。
在这些自监督学习损失中,掩蔽建模损失展示了最强的性能提升。掩蔽比率与训练优化难度直接相关,从 30% 增加到 60% 会导致性能下降。此外,显式重建点云 patch 不如掩蔽建模有效,但有助于 LLM 学习点云中的复杂模式。相比前两种损失,知识蒸馏损失的效果较差。最后,对比损失未能提取详细的语义信息,表现最差。
基于上述实验结果,作者提出混合语义损失(Hybrid Semantic Loss),他们对于掩蔽部分采用掩蔽建模,而对于可见部分,他们使用重建策略。这种方法不仅将高层次的语义嵌入 LLM 中,而且确保在整个点云学习过程中保持几何一致性。
层次几何聚合策略
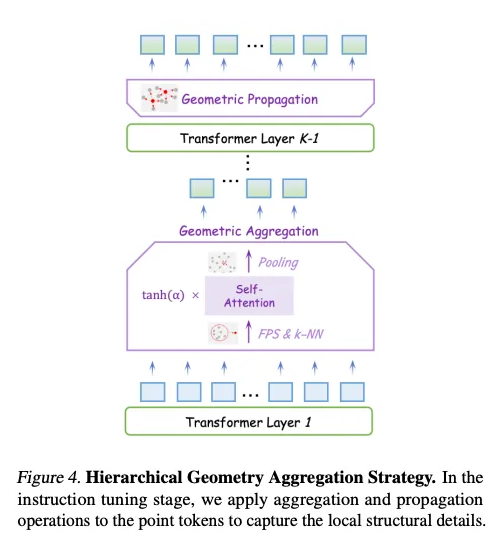
在无编码器架构中,LLM 本身并没有明确的局部建模模块。自注意力机制主要用于建模全局交互。因此,基于提出的混合语义损失,作者在指令调优阶段探索如何使 LLM 主动感知 3D 局部细节,并补充学到的全局语义。为此,他们提出了层次几何聚合策略。
从 LLM 的第二层开始,输入的点云 token 基于它们对应的坐标使用最远点采样进行下采样,将 token 数量从 M 减少到 𝑀/2, 作为局部中心。然后,使用 k-NN 算法获得邻近点。针对邻近点他们采用门控自注意力机制进行组内交互,捕捉局部几何结构。最后,他们应用池化操作融合每个邻居的特征,结果特征长度为 M/2。总共进行 l-1 次几何聚合。
为了确保 LLM 充分提取局部信息,作者选择在聚合操作后经过多层 LLM 层进行进一步的语义建模,避免丢失细粒度的几何细节。
随后,他们进行 l 次几何传播。按照 PointNet++ 的方法,他们将聚合后的特征从局部中心点传播到它们周围的 k 个邻近点,经过 l 次后重新得到长度为 M 的点云特征。

定量分析
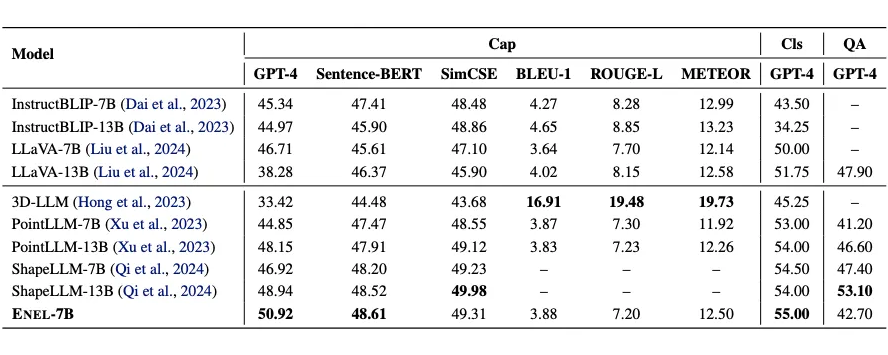
在 Objaverse 基准测试中,ENEL-7B 在 3D 物体描述任务中取得了 50.92% 的 GPT-4 得分,创下了新的 SOTA 性能。
在传统指标中,SentenceBERT 和 SimCSE 分别达到了 48.61% 和 49.31% 的得分,表现与 ShapeLLM-13B 相当。对于 3D 物体分类任务,ENEL-7B 超越了先前基于编码器的 3D LMMs,取得了 55% 的 GPT 得分。
此外,在 3D MM-Vet 数据集的 3D-VQA 任务上,尽管训练集中缺乏空间和具身交互相关的数据,ENEL 仍取得了 42.7% 的 GPT 得分,超过了 PointLLM-7B 1.5%。
考虑到与 PointLLM 相同的训练数据集,这些结果验证了作者提出的 LLM 嵌入式语义编码和层次几何聚合策略在无编码器架构中的有效性。

实现、训练和推理细节
作者使用 7B Vicuna v1.1 的检查点。在嵌入层中,点云首先通过一个线性层处理,将其维度从 6 扩展到 288。输入点云初始包含 8192 个点,随后经过三次最远点采样(FPS),分别将点云数量减少到 512、256 和 128。
每次 FPS 操作后,使用 k 近邻进行聚类,聚类大小为 81,并通过三角编码提取几何特征,随后通过线性层逐步将维度增加到 576、1152 和 2304。最后,投影层将特征映射到 LLM 的 4096 维度。
在两阶段训练过程中,每个阶段使用的数据集和预处理方法与 PointLLM 一致。所有训练均在 4 张 80G 的 A100 GPU 上以 BF16 精度进行,使用了 FlashAttention、AdamW 优化器以及余弦学习率调度策略。
在预训练阶段,模型训练了 3 个 epoch,批量大小为 128,学习率为 4e-4。在指令微调阶段,训练进行了 3 个 epoch,批量大小为 32,学习率为 2e-5。
用于分类和描述任务评估的 GPT-4 模型为「gpt-4-0613」版本,与 PointLLM 一致;而用于问答性能评估的 GPT-4 模型为「gpt-4-0125」版本,与 ShapeLLM 对齐。
关于作者
本文一作汤轶文本科毕业于上海科技大学,导师是李学龙教授,在上海人工智能实验室实习。他的研究兴趣是 3D 视觉,大模型高效迁移,多模态大模型和具身智能等。主要工作有 Any2Point, Point-PEFT, ViewRefer 等。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









