






1 简介
视频编解码是指将视频数据压缩和解压缩的过程,以便更高效地存储和传输视频内容。
具体来说,编码器负责将原始视频数据压缩成更小的体积,便于存储或传输;而解码器则负责将压缩后的数据还原成原始的视频格式,以便播放或处理。
视频编解码的基本原理:
- 压缩原理:视频编解码技术通过去除冗余信息、利用图像间的相似性以及采用压缩算法来实现数据的压缩。冗余信息包括空间性冗余(如相邻像素的相似性)和时间性冗余(如连续图像帧间的相似性)。
- 帧内编码:帧内编码是空间域编码,利用图像空间性冗余度进行压缩,处理的是一幅独立的图像,不会跨越多幅图像。
- 帧间编码:帧间编码是时间域编码,利用一组连续图像间的时间性冗余度进行压缩。通过分析相邻帧之间的像素变化,推测物体的运动方向和速度,从而只保存运动部分的信息,减少数据量。
视频编解码的名词和概念很多,为了便于理解,本文对一些基本概念及操作做一些介绍。
2 基本概念
2.1 图像格式 PIX_FMT
图像的格式及名词很多,这里做个简单的介绍,对实际编解码过程中出现的名词有个直观的概念。
2.1.1 Planar vs Packet
Planar,多个平面存储
Packet,单平面交替存储,或叫线性存储?
我们平时使用的格式,绝大部分是 Planar方式
2.1.2 Planar vs Semi Planar
Planar:三平面, Y U V每个维度占一个平面
Semi Planar: 两平面,Y占一个平面,UV共用一个平面
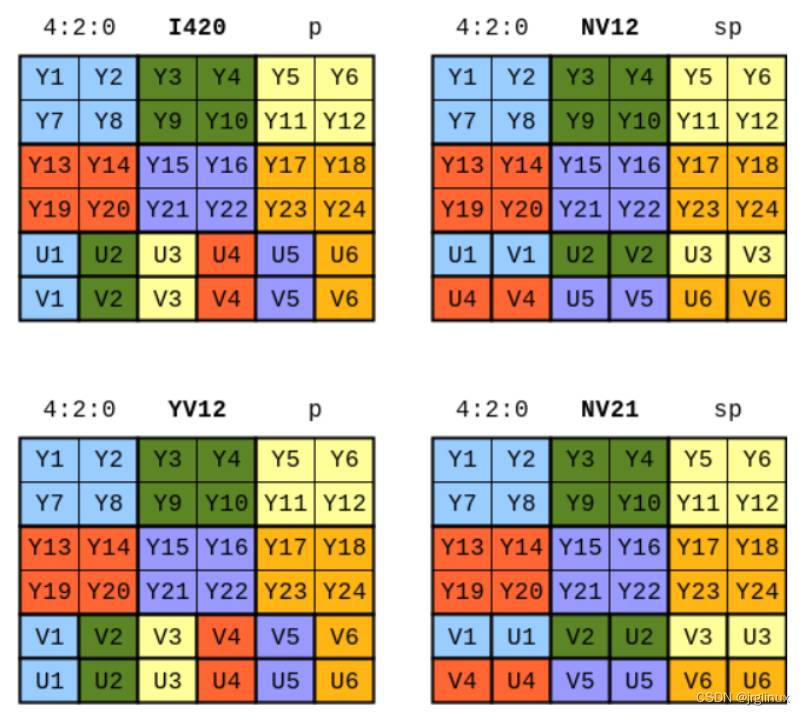
例如,YUV420P 指的是三平面方式;YUV420SP 指两平面方式。
三平面:
- Y U V 排列
-
- 如下图 左上
- 命名规则,YUV4XXP,或I4XX,如:YUV420P, YU12 或 I420
- Y V U排列
-
- 如下图 左下
- 命名规则,YVU4XXP, 或YVXX, 如: YVU420, 或 YV12
- 注:我们平时使用到的三平面格式,绝大多数都是YUV排列,具体称谓,有的IP习惯称YUV420P,有的IP习惯称I420,要能判断两种称谓是一个格式
两平面:
- Y, UVUV 排列
-
- 如下图,右上
- 命名规则:YUVXXXSP 或 NVXX,如:YUV420SP 或 NV12
- Y, VUVU 排列
-
- 如下图,右下
- 命名规则:YUVXXXSP 或 NVXX,如:YVU420SP 或 NV21
- 注意:我们平时使用的两平面格式,绝大部分是 NV12,且称谓也以NV12居多。但要知道 YUV420SP和NV12是同一格式。
至于三平面和两平面,哪个使用的多,感觉差不多。NV12略微多一些。
2.1.3 不同平面的比例
420, 422, 444, 400
420:U+V是Y的1/2, 一个PIX 12 bit (假设8bit位深,下同)
422: 相对好理解,Y:U:V=1:1/2:1/2, 一个PIX 16bit
444: Y:U:V=1:1:1, 一个PIX 24bit
400:只有Y分量,没有UV
422P 称谓:
- I422/YU16:排列方式 YYYY UU VV
- YV16: 排列方式 YYYY VV UU
422SP 称谓
- NV16:排列方式 YYYY UVUV
- NV61: 排列方式 YYYY VUVU
400 称谓
- 只有Y分量,所以,没有2/3平面之说
- Y only
- YUV400
- Monochrome
我们平时使用较多的是 420 比例,当然,很多IP都要求支持422, 444。应该说,420比例最常用
2.1.4 Packet方式
直接用字母表示存储的顺序和比例
YUV422的Packet方式:YUYV=YUY2, YVYU, UYVY, VYUY
我们平时基本不用Packet方式。
2.2 编解码器 Codec
视频编解码器(Video Codec)是一种用于压缩或解压数字视频的软件、硬件或两者的结合。编解码器(Codec)是“编码器”(Encoder)和“解码器”(Decoder)的组合,负责将视频数据压缩成适合存储或传输的格式,并在需要时将其解压缩以便播放或处理。
视频编解码标准包括:
- H.26x系列:由ITU-T开发,包括H.261、H.262、H.263、H.264(AVC)和H.265(HEVC)。
- MPEG系列:由ISO/IEC开发,包括MPEG-1、MPEG-2、MPEG-41。
- VP系列:是On2 Technologies开发的视频编码标准,最初由On2 Technologies开发,后被Google收购并进一步发展。这些编码标准主要用于网络视频和实时通信等领域。Google收购前,已有VP6, VP7, Google收购后,发布VP8、VP9。VP9之后应该不再有,AV1被称为VP9的替代者。
- AV1:由开放媒体联盟(AOMedia)开发。https://blog.csdn.net/u011686167/article/details/113806322
- AVS系列:国标
- VC-1:微软标准
常用或主流的标准:
- H264 (AVC)
- H265 (HEVC)
- VP9
- AV1
这些也是我们测试覆盖的重点。
2.3 编解码与封装
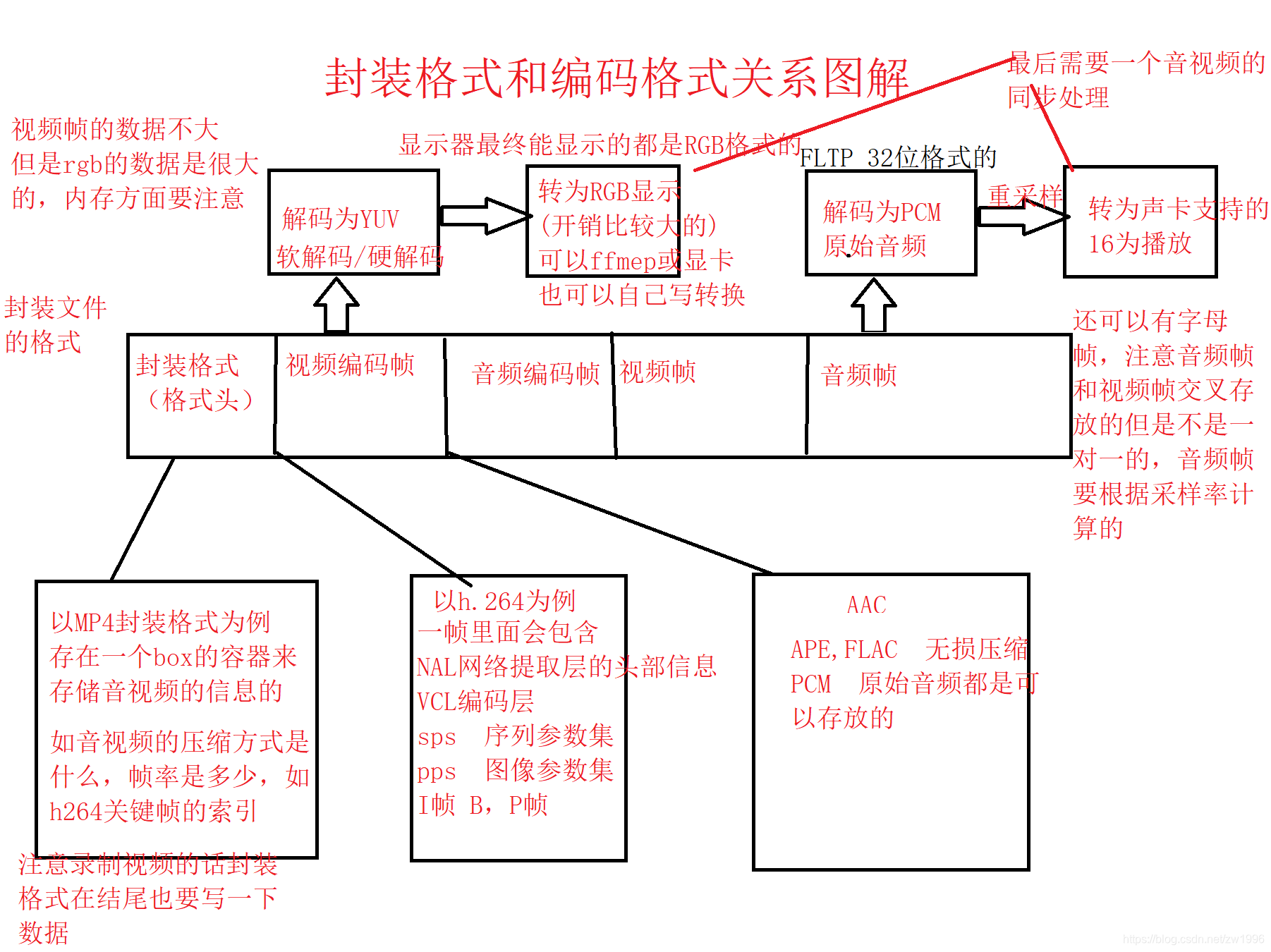
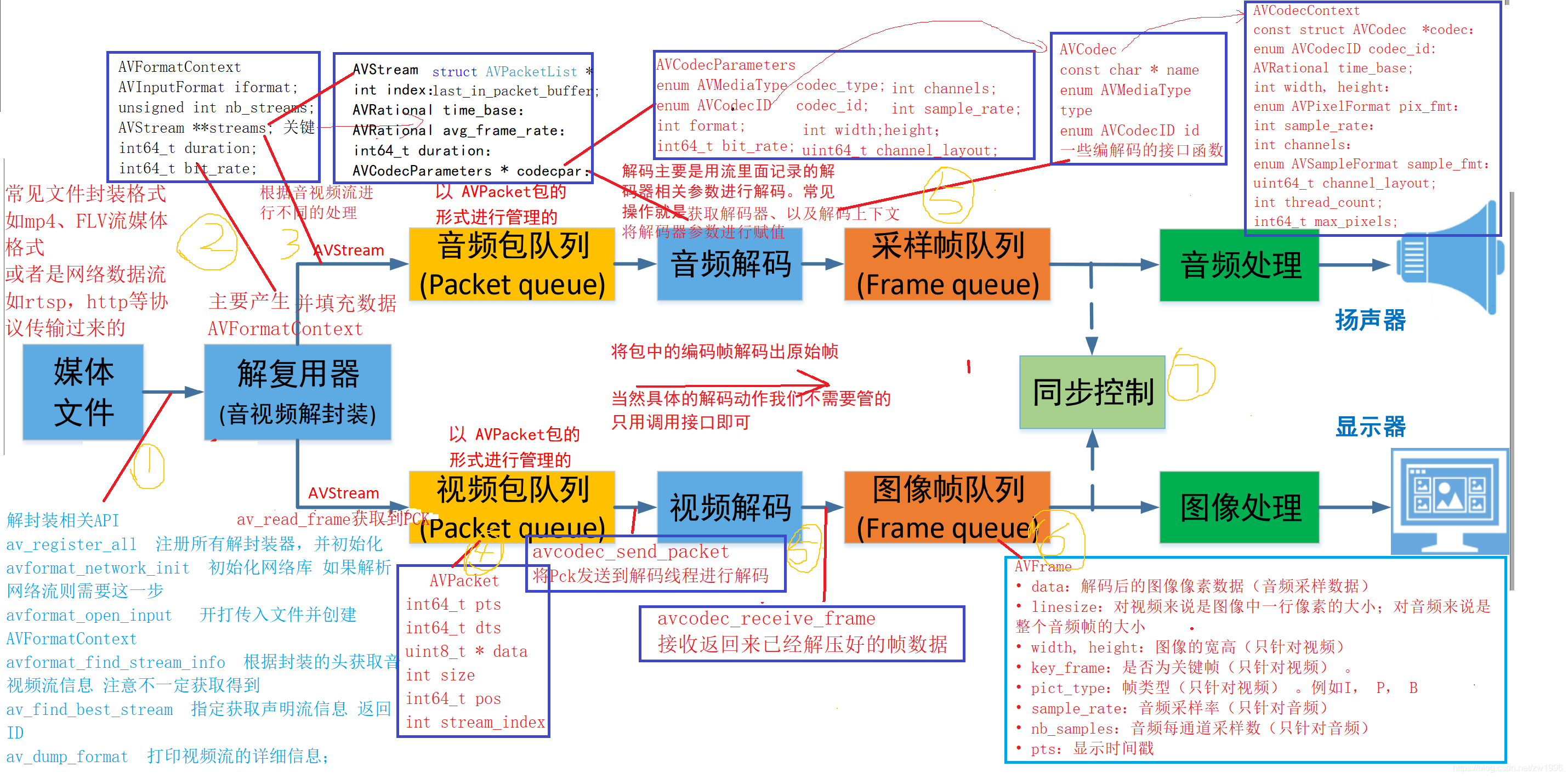
3 视频编码的基本原理及工作流程
参考资料:
https://segmentfault.com/a/1190000021049773
https://zhuanlan.zhihu.com/p/557065236
3.1 前提假设
因为人眼睛的视杆细胞(亮度)比视锥细胞多很多,所以一个合理的推断是相比颜色,我们有更好的能力去区分黑暗和光亮。我们的眼睛对亮度比对颜色更敏感
编码技术以这个假设为前提。

3.2 视频编码技术概述
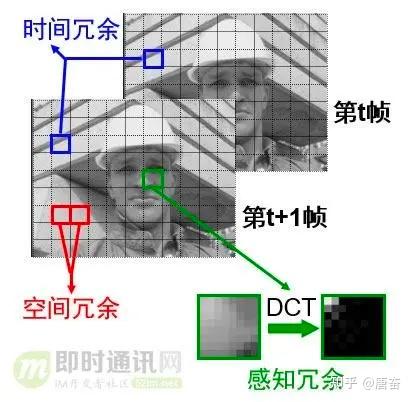
编码的目的是为了压缩,所谓编码算法,就是寻找规律构建一个高效模型,将视频数据中的冗余信息去除。
常见的视频的冗余信息和对应的压缩方法如下表:
| 种类 | 内容 | 压缩方法 |
| 空间冗余 | 像素间的相关性 | 变换编码,预测编码 |
| 时间冗余 | 时间方向上的相关性 | 帧间预测,运动补偿 |
| 图像构造冗余 | 图像本身的构造 | 轮廓编码,区域分割 |
| 知识冗余 | 收发两端对人物共有认识 | 基于知识的编码 |
| 视觉冗余 | 人对视觉特性 | 非线性量化,位分配 |
| 其他 | 不确定性因素 |
视频帧冗余信息示例如下图所示:
3.2 帧类型
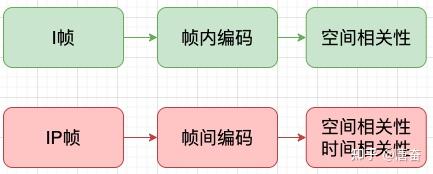
我们知道视频是由不同的帧画面连续播放形成的,视频的帧主要分为三类,分别是(1)I 帧;(2)B 帧;(3)P 帧。
- I 帧(关键帧,帧内编码):是自带全部信息的独立帧,是最完整的画面(占用的空间最大),无需参考其它图像便可独立进行解码。视频序列中的第一个帧,始终都是I帧。
- P 帧(预测):“帧间预测编码帧”,需要参考前面的I帧和/或P帧的不同部分,才能进行编码。P帧对前面的P和I参考帧有依赖性。但是,P帧压缩率比较高,占用的空间较小。
- B 帧(双向预测):“双向预测编码帧”,以前帧后帧作为参考帧。不仅参考前面,还参考后面的帧,所以,它的压缩率最高,可以达到200:1。不过,因为依赖后面的帧,所以不适合实时传输(例如视频会议)。
对 I 帧的处理,是采用帧内编码(帧间预测)方式,只利用本帧图像内的空间相关性。
对 P 帧的处理,采用帧间编码(前向运动估计),同时利用空间和时间上的相关性。简单来说,采用运动补偿(motion compensation)算法来去掉冗余信息。
3.3 帧内编码(帧内预测)
帧内编码/预测用于解决单帧空间冗余问题。如果我们分析视频的每一帧,会发现许多区域是相互关联的。

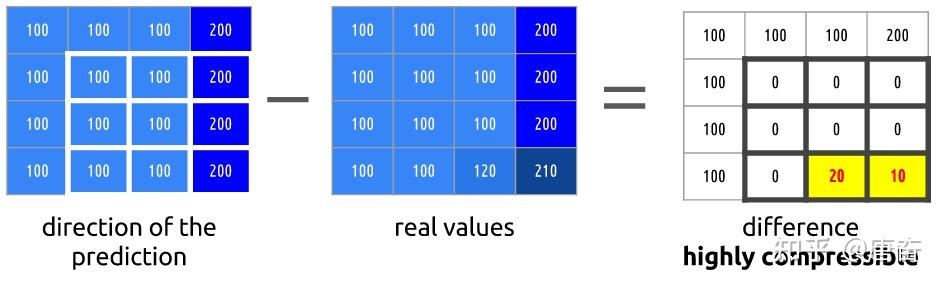
举个例子来理解帧内编码,如下图所示的图片,可以看出这个图大部分区域颜色是一样的。假设这是一个 I 帧 ,我们即将编码红色区域,假设帧中的颜色在垂直方向上保持一致,这意味着未知像素的颜色与临近的像素相同。

这样的先验预测虽然会出错,但是我们可以先利用这项技术(帧内预测),然后减去实际值,算出残差,这样得出的残差矩阵比原始数据更容易压缩。
3.4 帧间编码(帧间预测)
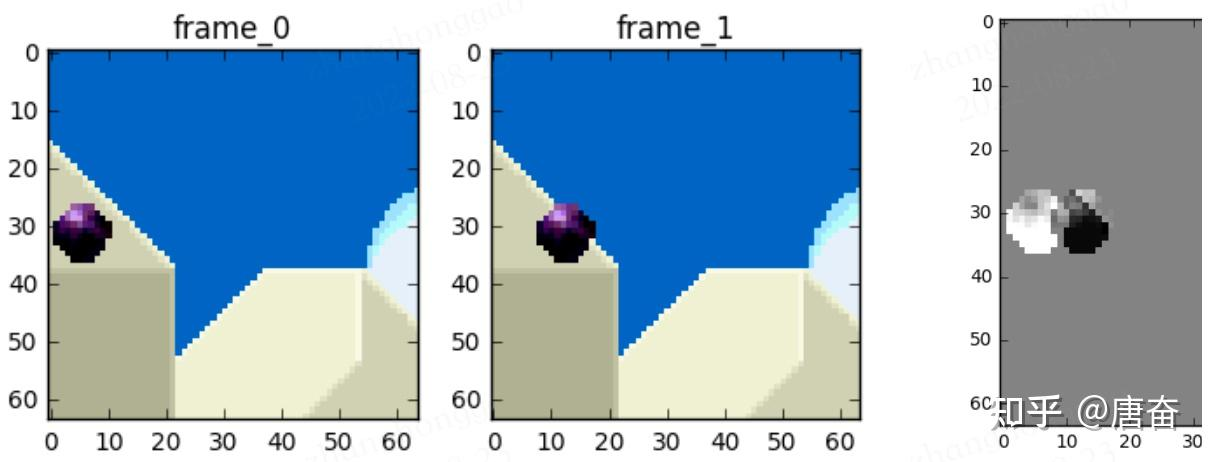
视频帧在时间上的重复,解决这类冗余的技术就是帧间编码/预测。
尝试花费较少的数据量去编码在时间上连续的 0 号帧和 1 号帧。比如做个减法,简单地用 0 号帧减去 1 号帧,得到残差,这样我们就只需要对残差进行编码。
做减法的方法比较简单粗暴,效果不是很好,可以有更好的方法来节省数据量。首先,我们将0 号帧 视为一个个分块的集合,然后我们将尝试将 帧 1 和 帧 0 上的块相匹配。我们可以将这看作是运动预测。
运动补偿是一种描述相邻帧(相邻在这里表示在编码关系上相邻,在播放顺序上两帧未必相邻)差别的方法,具体来说是描述前面一帧(相邻在这里表示在编码关系上的前面,在播放顺序上未必在当前帧前面)的每个小块怎样移动到当前帧中的某个位置去。”
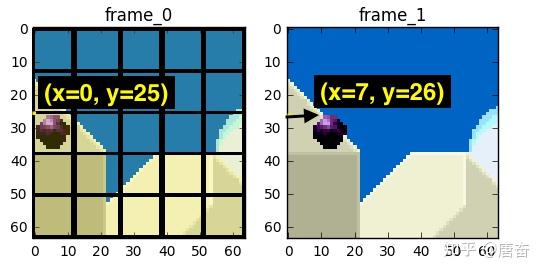
如上图所示,我们预计球会从 x=0, y=25 移动到 x=7, y=26,x 和 y 的值就是运动向量。进一步节省数据量的方法是,只编码这两者运动向量的差。所以,最终运动向量就是 x=7 (6-0), y=1 (26-25)。使用运动预测的方法会找不到完美匹配的块,但使用运动预测时,编码的数据量少于使用简单的残差帧技术,对比图如下图所示:
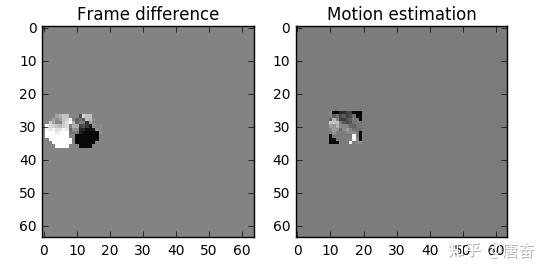
3.5 通用编码器工作流程
虽然视频编码器的已经经历了几十年的发展历史,但是其还是有一个主要的工作机制的。
3.5.1,第一步-图片分区
第一步是将帧分成几个分区,子分区甚至更多。分区的目的是为了更精确的处理预测,在微小移动的部分使用较小的分区,而在静态背景上使用较大的分区。
通常,编解码器将这些分区组织成切片(或瓦片),宏(或编码树单元)和许多子分区。这些分区的最大大小对于不同的编码器有所不同,比如 HEVC 设置成 64x64,而 AVC 使用 16x16,但子分区可以达到 4x4 的大小。

3.5.2,第二步-预测
有了分区,我们就可以在它们之上做出预测。对于帧间预测,我们需要发送运动向量和残差;至于帧内预测,我们需要发送预测方向和残差。
3.5.3,第三步-转换
在我们得到残差块(预测分区-真实分区)之后,我们可以用一种方式变换它,这样我们就知道哪些像素我们应该丢弃,还依然能保持整体质量。这个确切的行为有几种变换方式,这里只介绍离散余弦变换(DCT),其功能如下:
- 将像素块转换为相同大小的频率系数块。
- 压缩能量,更容易消除空间冗余。
- 可逆的,也意味着你可以还原回像素。
我们知道在一张图像中,大多数能量会集中在低频部分,所以如果我们将图像转换成频率系数,并丢掉高频系数,我们就能减少描述图像所需的数据量,而不会牺牲太多的图像质量。 DCT 可以把原始图像转换为频率(系数块),然后丢掉最不重要的系数。
我们从丢掉不重要系数后的系数块重构图像,并与原始图像做对比,如下图所示。
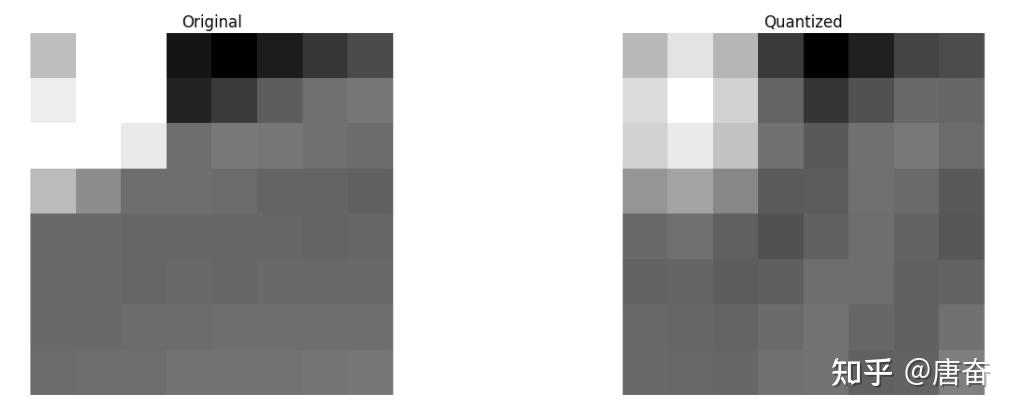
可以看出它酷似原图像,与原图相比,我们丢弃了67.1875%,而如何智能的选择丢弃系数则是下一步要考虑的问题。
3.5.4,第四步-量化
当我们丢掉一些(频率)系数块时,在最后一步(变换),我们做了一些形式的量化。这一步,我们选择性地剔除信息(有损部分)或者简单来说,我们将量化系数以实现压缩。
如何量化一个系数块?一个简单的方法是均匀量化,我们取一个块并将其除以单个的值(10),并舍入值。
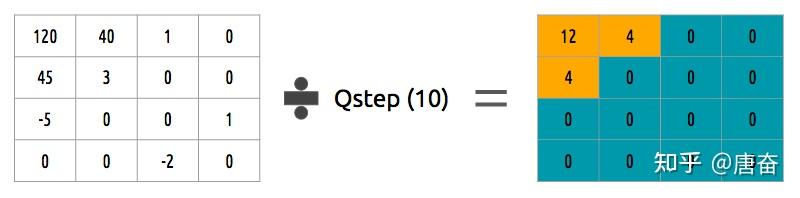
那如何逆转(反量化)这个系数块呢?可以通过乘以我们先前除以的相同的值(10)来做到。

均匀量化并不是一个最好的量化方案,因为其并没有考虑到每个系数的重要性,我们可以使用一个量化矩阵来代替单个值,这个矩阵可以利用 DCT 的属性,多量化右下部,而少(量化)左上部,JPEG 使用了类似的方法。
3.5.5,第五步-熵编码
在我们量化数据(图像块/切片/帧)之后,我们仍然可以以无损的方式来压缩它。有许多方法(算法)可用来压缩数据:
- VLC 编码
- 算术编码
3.3.6,第六步-比特流格式
完成上述步骤,即已经完成视频数据的编码压缩,后续我们需要将压缩过的帧和内容打包进去。需要明确告知解码器编码定义,如颜色深度,颜色空间,分辨率,预测信息(运动向量,帧内预测方向),档次*,级别*,帧率,帧类型,帧号等等更多信息。
4 视频编解码进阶概念及原理
4.1 Profile 与 Level
概念:
Profile 是对视频的压缩特性的描述,具体指码流中采用了那些编码算法和使用了那些编码工具
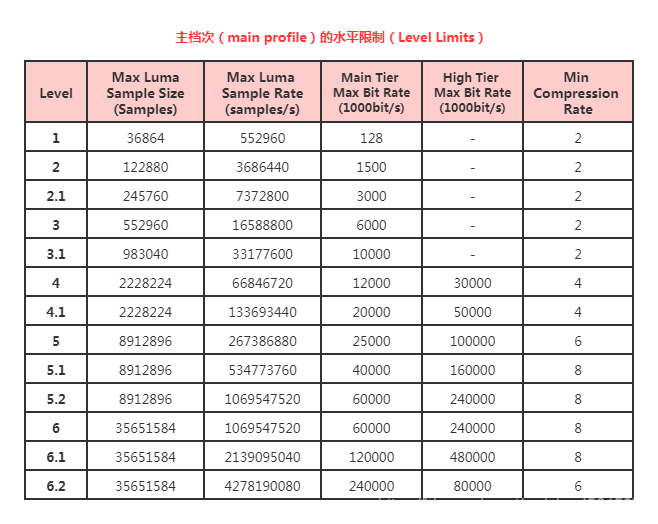
Level 指出了一些对解码端负载和内存占用影响较大的关键参数的约束,这些参数主要包括有:采样频率、分辨率、码率的最大值,压缩率的最小值、解码图形缓冲区(DPB)的容量、编码图像缓冲区(CPB)的容量;水平中还约束了每帧中垂直和水平方向的tile的最大数量,以及每秒最大的tile数量。
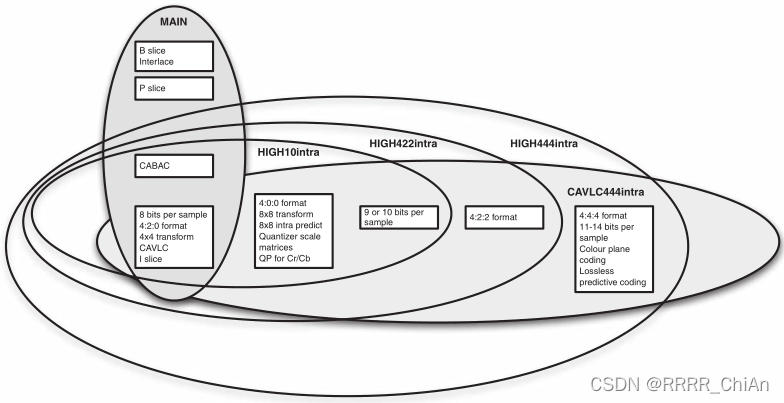
4.1.1 H265 (HEVC) 的Profile和Level
在HEVC中支持三个档次(profile),分别是主档次(main profile)、10bit主档次(main 10 profile)、静止图像主档次(main still profile),它们之间的关系如下图所示,外层档次可以兼容内层的等级
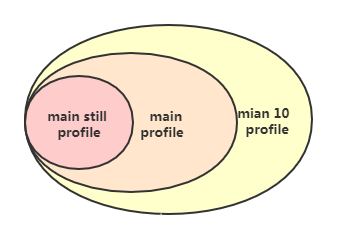
主档次(mian profile)的特点
- 比特深度限制为8bit
- 采样格式限制为4:2:0
- CTB的大小从16 * 16到64 * 64
- 解码图像的缓存容量限制为6幅图像
- 允许选择波前和片划分方式,但是不能同时选择
10比特主档次(main 10 profile)的特点
主要的特点和main profile类似,但是不同之处在于,它能够支持10比特深度
静止图像档次(main still profile)的特点
主要特点和main profile类似,但区别在于它不支持帧间预测编码,视频的全部的码流只能一帧编码。
说明:
在解码器的兼容性方面,支持的某个profile的解码器必须支持该Profile及低于该Profile中的所有特性 (向下兼容);
4.1.2 H264 (AVC) 的Profile和Level
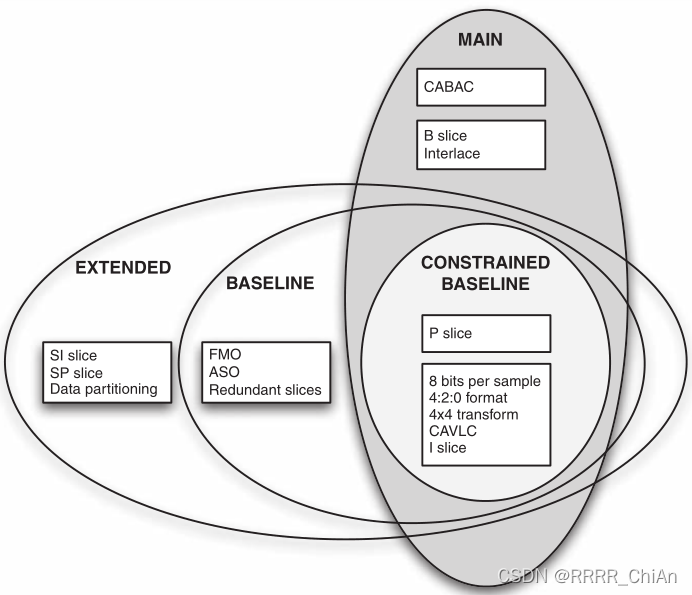
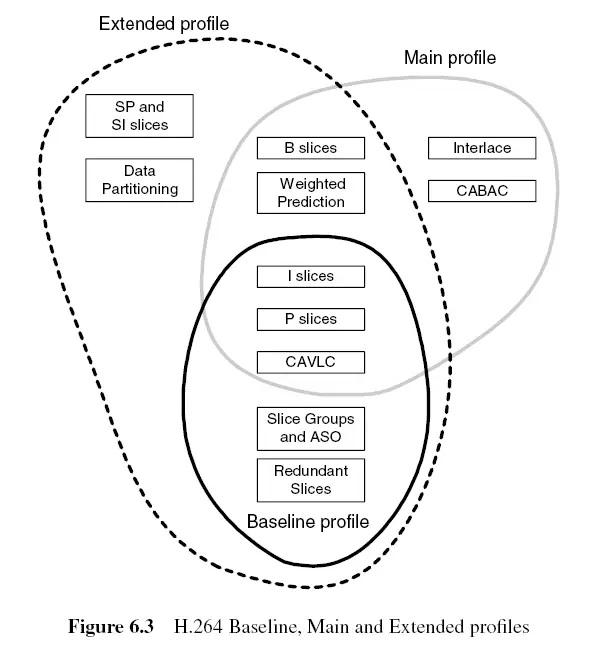
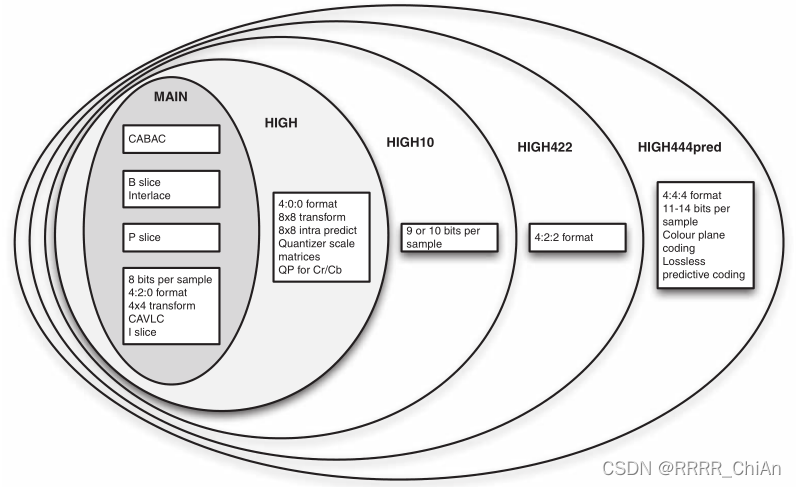
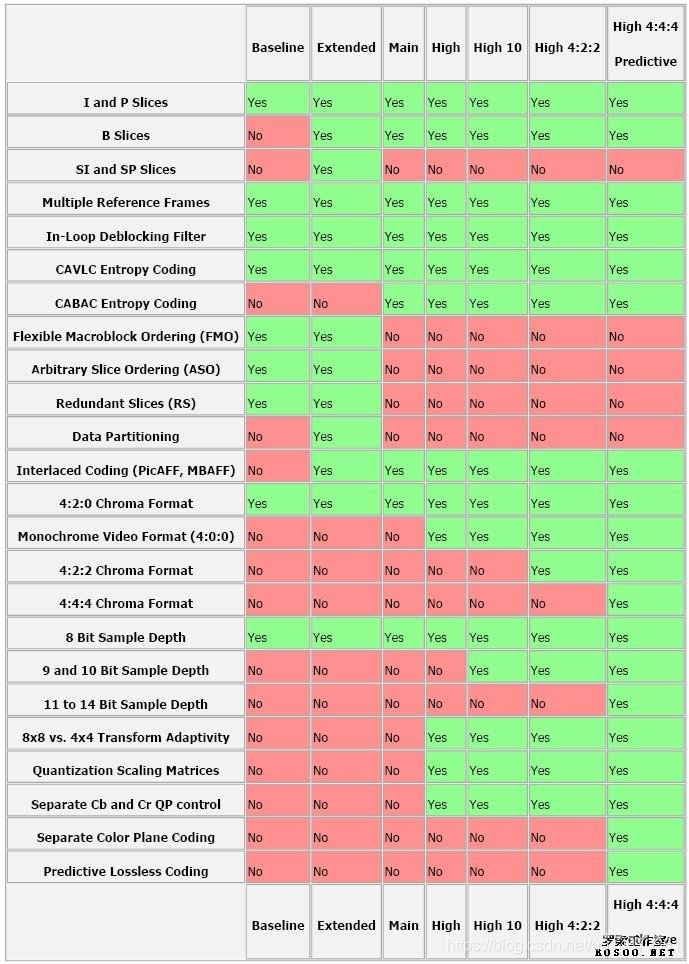
H264 的profile较多,Baseline / Constrained Baseline / Extended / Main Profile / High Profile。
每个profile都指定了264可用的编码工具的一个子集。profile限制了264解码器所需的算法。
因此,符合264 Main Profile的解码器只需要支持Main Profile中包含的工具;High Profile解码器需要支持进一步的编码工具;以此类推。
每个profile旨在对某一类应用有效。例如
- Baseline Profile对于低延迟、“会话”应用程序(如视频会议)是有效的,具有相对较低的计算需求。
- Main Profile适用于基本的电视/娱乐应用程序,如标准定义电视服务。
- High Profile在Main Profile的基础上添加了一些工具,提高了压缩效率,适用于分辨率更高的服务,如高清电视。
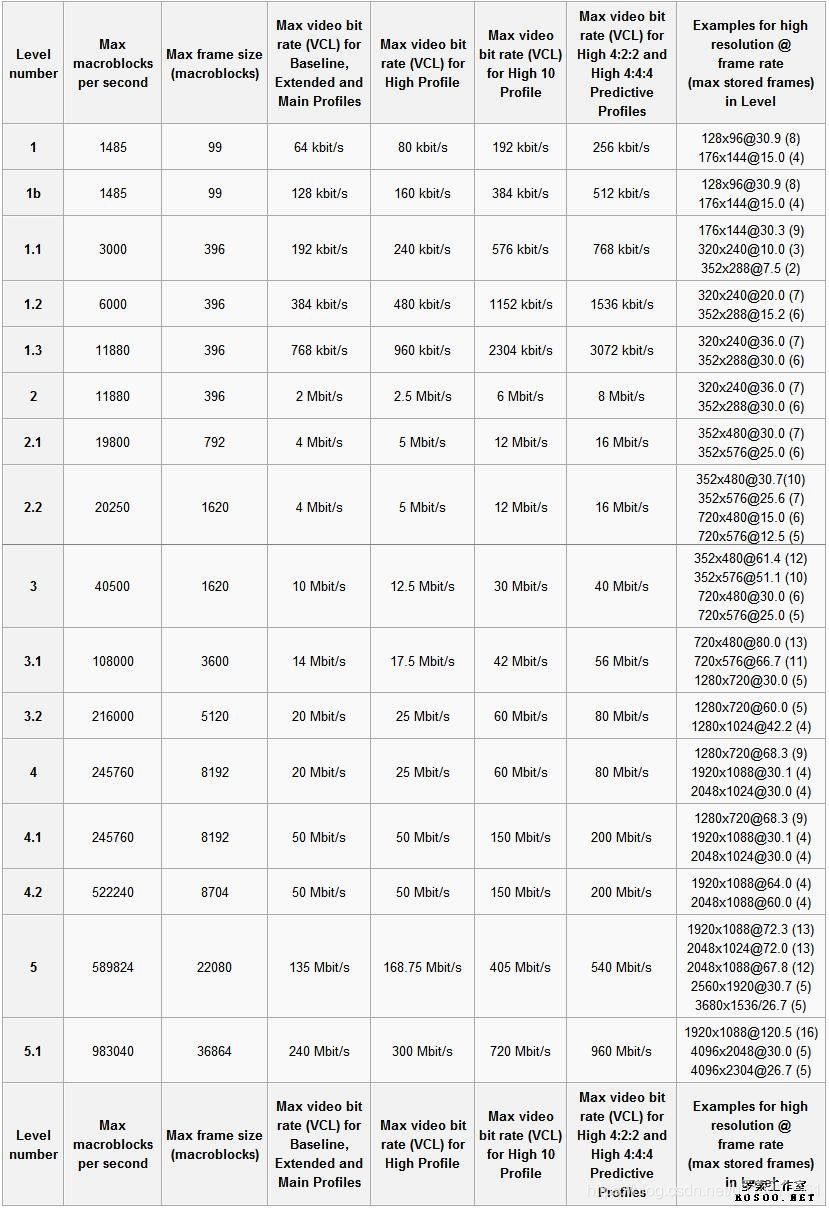
Profile和Level的组合限制了解码器的最大计算和存储需求。
Maximum macroblock processing rate(MaxMBPS):解码器每秒必须处理的宏块的最大数量(16x16的亮度+相应的色度)
Maximum frame size(MaxFS):解码帧中,宏块数量的最大值
Maximum Decoded Picture Buffer size(MaxDPB):解码器中存储已解码图像的最大内存空间值
Maximum video bit rate(MaxBR):已编码视频码流的最大值(maximum coded video bitrate)
Maximum Coded Picture Buffer size(MaxCPB):解码前存储(缓冲)编码数据所需的最大内存空间值
Vertical motion vector range(MaxVmvR):竖直运动矢量的最大范围
Mininum Compression Ratio(MinCR):未压缩视频帧与压缩视频数据大小之间的最小比率
Maximum motion vectors per two consecutive macroblocks (MaxMvsPer2Mb):在level大于3时才指定的,对(MVx, MVy)的数量的限制,出现在任何两个连续的解码宏块中。
备注:
HEVC:ffmpeg命令查到的level值,是实际的level x 30
AVC:ffmpeg命令查到的level值,是实际的level
4.2 熵编码 CAVLC和CABAC
CAVLC(Context Adaptive VariableLength Coding)是在H.264/MPEG-4AVC中使用的熵编码方式
CAVLC是CABAC的替代品,虽然其压缩效率不如CABAC,但CAVLC实现简单,并且在所有的H.264profile中都支持。
CABAC(ContextAdaptive Binary Arithmatic Coding)也是 H.264/MPEG-4AVC中使用的熵编码算法。CABAC在不同的上下文环境中使用不同的概率模型来编码。其编码过程大致是这样:首先,将欲编码的符号用二进制bit表示;然后对于每个bit,编码器选择一个合适的概率模型,并通过相邻元素的信息来优化这个概率模型;最后,使用算术编码压缩数据。
注意:
- H264支持CABAC和CAVLC两种熵编码
- H265只支持CABAC熵编码方式
- VP9使用的是BAC(Block Adaptive Coding and Context Modeling)作为其熵编码技术
- AV1采用了一种多符号上下文自适应算术编码技术
4.3 逐行扫描(Progressive),隔行扫描(Interlaced)
Progressive和Interlaced是两种不同的视频扫描方式,它们在显示效果和性能上有显著差异。
定义和原理
- Progressive(逐行扫描):逐行扫描每次显示整个扫描帧,从左到右、从上到下顺序扫描每一行,每秒钟扫描固定的帧数。这种方式可以减少闪烁,提供更平滑的图像,适用于高清晰度显示设备12。
- Interlaced(隔行扫描):隔行扫描将每一帧图像分割为两场,先扫描奇数行形成第一场,再扫描偶数行形成第二场,两场交替显示。由于视觉暂留效应,人眼会看到连续的画面,但在动态画面下可能会出现细节损失和锯齿状边缘12。
优缺点
- Progressive:
-
- 优点:画面平滑,无闪烁,适合高速运动场景和动态画面,能够提供更高的图像质量。
- 缺点:需要更高的带宽和处理能力,数据传输量大。
- Interlaced:
-
- 优点:数据传输量较小,适合带宽有限的传输环境,能够利用较低的带宽提供视频内容。
- 缺点:动态画面下可能出现细节损失和锯齿状边缘,画面质量较低。
应用场景
- Progressive:广泛应用于高清电视、电影放映和专业视频编辑中,能够提供更清晰的图像和更好的视觉体验。
4.4 Tiled(分块)与Linear(线性)
Linear(线性):
- 在线性存储中,图像数据是按照像素在屏幕上的顺序连续存储的。这通常意味着数据从图像的左上角开始,按照从左到右、从上到下的顺序排列。
- 线性布局是简单的,因为数据访问是连续的,这对于某些算法和硬件实现来说是高效的。
- 然而,线性存储可能不是最优的,特别是当处理大型图像或需要高效访问特定区域时。
Tiled(分块):
- 在分块存储中,图像被分成固定大小的块(或“tile”),每个块独立存储。
- 分块存储可以优化某些操作,特别是当这些操作仅涉及图像的一小部分时。例如,局部变换或滤波可以仅在一个或几个块上执行,而不需要处理整个图像。
- 分块存储也可以提高缓存效率,因为当处理图像时,相邻的像素往往被一起访问,而它们可能位于相同的块中。
4.5 DPB (Decoded Picture Buffer)
在H.264视频编码标准中,DPB(Decoded Picture Buffer)是一个关键组件,用于存储解码后的图像帧,以供后续的帧间预测编码和解码使用。DPB中存储的帧可以是参考帧(用于预测编码新帧)或非参考帧(不用于预测,但可能需要显示或丢弃)。
"DPB flush"是一个操作,用于清除DPB中的所有帧。在某些情况下,解码器可能需要执行DPB flush操作,以确保解码过程与编码器的预期同步,或者为了响应某些特定的解码条件或错误恢复机制。
DPB flush操作通常发生在以下几种情况:
- IDR(Instantaneous Decoding Refresh): 当解码器遇到IDR NAL单元时,它必须丢弃DPB中的所有帧,并从当前IDR AU开始重新解码。这是一种强制性的刷新机制,用于确保解码器的状态与编码器完全同步。
- Slice Header中的discardable_flag: 在Slice头部中,有一个discardable_flag标志。如果设置为1,这意味着该Slice对应的帧可以被丢弃而不影响后续帧的解码。在某些情况下,解码器可能会选择执行DPB flush操作来丢弃这些帧。
- 解码错误: 如果解码器在解码过程中遇到错误,并且无法通过其他方式恢复,它可能会选择执行DPB flush来清除所有可能受到影响的帧,并从下一个IDR AU重新开始解码。
- 序列结束: 当解码器处理完一个视频序列的所有数据时,它可能会执行DPB flush来清除DPB中的所有帧,为处理下一个视频序列做准备。
执行DPB flush操作时,解码器会清除DPB中的所有帧,并将DPB的状态重置为初始状态。这意味着所有存储在DPB中的帧都将被丢弃,不再用于后续的预测编码或解码。
MaxDpbSize(Maximum Decoding Picture Buffer Size)
在H.264/AVC(Advanced Video Coding)标准中,MaxDpbSize(Maximum Decoding Picture Buffer Size)是一个关键参数,它定义了解码器为存储解码后的图像(帧)所需的最大缓冲区大小(以帧为单位)。这个参数对于解码器实现和性能优化是非常重要的,因为它直接影响到解码器能够同时处理多少帧而不引起溢出。
MaxDpbSize的具体值取决于视频流的几个因素,包括:
- Level(级别):H.264标准定义了多个级别,每个级别都对应一个特定的MaxDpbSize最大值。级别越高,通常允许的最大MaxDpbSize也越大。级别不仅与MaxDpbSize有关,还限制了比特率、帧率和分辨率等其他参数。
- Profile(配置文件):不同的H.264配置文件(如Baseline, Main, Extended, High等)也可能对MaxDpbSize有不同的限制。
- Sequence Parameter Set (SPS):在视频流的SPS中,会明确指定MaxDpbSize的值。SPS是H.264比特流中的一个重要组成部分,用于传递序列级别的编码参数。
解码器需要确保在解码过程中不会超出MaxDpbSize所定义的缓冲区大小。如果超出了这个限制,解码器可能需要丢弃一些帧或者采取其他措施来避免缓冲区溢出。
MaxDpbSize与max_dec_frame_buffering参数有关联,但它们不是同一个概念。max_dec_frame_buffering是编码器用来指示解码器应该准备的最大解码帧缓冲区的参数。而MaxDpbSize则是解码器实际使用的最大缓冲区大小,这个值可能由编码器通过SPS指定,也可能由解码器根据级别和配置文件自动确定。
在实际应用中,理解MaxDpbSize和如何配置它是非常重要的,因为它直接影响到解码器的内存使用和性能。如果配置不当,可能会导致解码器无法正常工作或者出现性能问题。
4.6 显示顺序与解码顺序
通常情况下,解码顺序号按照帧的出现顺序递增,即每个新帧的解码顺序号比前一个帧的解码顺序号大1。然而,需要注意的是,在某些特殊情况下,如IDR(Immediate Refresh)帧,解码顺序号可能会被重置。显示顺序由图像顺序计数POC(Picture Order Count)决定。POC是一个用于标识帧显示顺序的数值,它考虑了帧之间的依赖关系和编码特性。解码器在解码过程中会计算每个帧的POC,并按照POC的顺序将帧传递给显示设备。
比如,对于IPBB这项顺序的视频序列,解码顺序为 I-P-B-B,但它的显示顺序为 I-B-B-P。

由于H.264采用了帧间预测技术,解码顺序和显示顺序之间可能会存在差异。例如,B帧在解码过程中可能需要依赖于未来的帧进行解码,但在显示时却需要被插入到它们依赖的帧之间。因此,解码器在解码完成后会根据帧的POC对帧进行重新排序,以确保它们按照正确的顺序显示。
Display Reordering(显示重排序)
在H.264视频编码标准中,Display Reordering(显示重排序)是一个重要的概念,它与解码后的帧的显示顺序有关。在视频压缩和解码过程中,由于采用了帧间预测技术,解码后的帧并不总是按照它们原始的显示顺序到达解码器输出。因此,Display Reordering机制用于调整帧的显示顺序,以确保它们按照正确的顺序在显示设备上呈现。
由于B帧依赖于未来的帧进行解码,解码器在解码B帧时可能还没有接收到所有依赖的帧。因此,解码器需要将解码后的帧存储在缓冲区中,直到所有依赖的帧都可用为止。一旦所有依赖的帧都可用,解码器就可以按照正确的顺序重新排列这些帧,并将它们传递给显示设备
4.7 QP(Quantization Parameter,量化参数
在H.264/H.265编码中,QP(Quantization Parameter,量化参数)是一个关键概念。编码时,会将每一帧的图像分为多个宏块,每个宏块编码后都有一个QP值。对于每一帧图像来说,都会有一个最大QP值和最小QP值,即max_qp和min_qp。
QP的取值范围通常为0到51。当QP取最小值0时,表示量化最精细;相反,当QP取最大值51时,表示量化是最粗糙的。QP和Qstep(量化步长)具有线性相关性,Qstep随着QP的增加而增加。量化是在不降低视觉效果的前提下减少图像编码长度,减少视觉恢复中不必要的信息。
在H.264编码中,min_qp设置编码器可以使用的最小量化器。量化参数越小,输出越接近输入。在某些情况下,编码器的输出可以和输入看起来完全一样,尽管它们并不是精确相同的。如果开启了自适应量化器(默认开启),通常不建议提高min_qp的值,因为这可能会降低帧的平坦部分的质量。
相反,max_qp是设置编码器可以使用的最大量化器,其默认值51是H.264标准中的最大值,但使用此值可能会导致输出质量非常低。
4.8 GOP, SPS,Slice
GOP(Group of Pictures)是指一组连续的画面,也可以理解为两个I帧(关键帧)之间的间隔。在视频编码中,GOP是一个重要的概念,它决定了视频流的编码结构和解码效率。
GOP的主要作用是限制编码器中参考帧的数量,从而减少编码和解码时的计算复杂度。在H.264中,每个帧都可以是I帧、P帧或B帧,其中I帧是完整编码的帧,不依赖于其他帧进行解码,而P帧和B帧则依赖于前面的I帧或P帧进行解码。为了限制参考帧的数量,编码器会将帧组织成一系列的GOP,每个GOP都以一个I帧开始,后面跟着一系列的P帧和B帧。
GOP的大小(即两个I帧之间的间隔)对视频流的编码效率和解码性能有着重要的影响。较小的GOP大小意味着编码器中需要存储的参考帧数量较少,从而减少了编码和解码时的内存占用和计算复杂度。但是,较小的GOP大小也会导致编码效率降低,因为每个GOP中的帧之间相关性较小,导致编码时的冗余信息较多。相反,较大的GOP大小可以提高编码效率,因为帧之间的相关性更大,但是会增加编码器和解码器的内存占用和计算复杂度。
在实际应用中,GOP大小的选择需要根据具体的应用场景和需求进行权衡。对于实时性要求较高的应用,如视频会议、视频聊天等,通常需要选择较小的GOP大小以保证解码的实时性。而对于需要较高压缩比的应用,如视频存储、流媒体传输等,可以选择较大的GOP大小以提高编码效率
GOP与SPS(序列参数集)关系
对于一个1080p的H.264序列文件,SPS(序列参数集)通常也只有一个。SPS包含了整个视频序列的全局参数,如分辨率、帧率、编码模式等。对于1080p的视频,SPS中会包含表明分辨率为1920x1080的参数。尽管在视频流中可能存在多个IDR(Instantaneous Decoding Refresh)帧,每个IDR帧可能携带新的PPS(图像参数集),但SPS通常在整个视频序列中只需要定义一次,并在整个序列中保持不变,SPS不是附在I帧或者P帧上面的,SPS是一个单独的NALU type,是与IPB帧同级别的NALU slice
intraPeriod
在H.264编码中,GOP结构定义了帧的排列方式,包括I帧、P帧和B帧的数量和顺序。intra_period通常用于指定在编码过程中插入I帧的周期。换句话说,它定义了连续两个I帧之间应有多少个非I帧(P帧和B帧)。这个值决定了GOP的长度和编码视频流的特性。intra_period和gop size在视频编码中都与关键帧(I帧)的插入间隔有关,但它们的具体含义和用途可能略有不同。gop size是较为普遍和直接的概念,它指的是两个连续的I帧之间的帧数。换句话说,它定义了一个GOP(Group of Pictures)中除了I帧以外的P帧和B帧的数量。而intra_period在某些上下文中可能与gop size相似,但并不是一个通用或标准的术语。它可能是特定编码库或工具中的参数,用于指定插入I帧的周期。虽然其本质目的与gop size相似,即控制I帧的插入频率,但具体实现和用法可能因工具或库的不同而有所差异
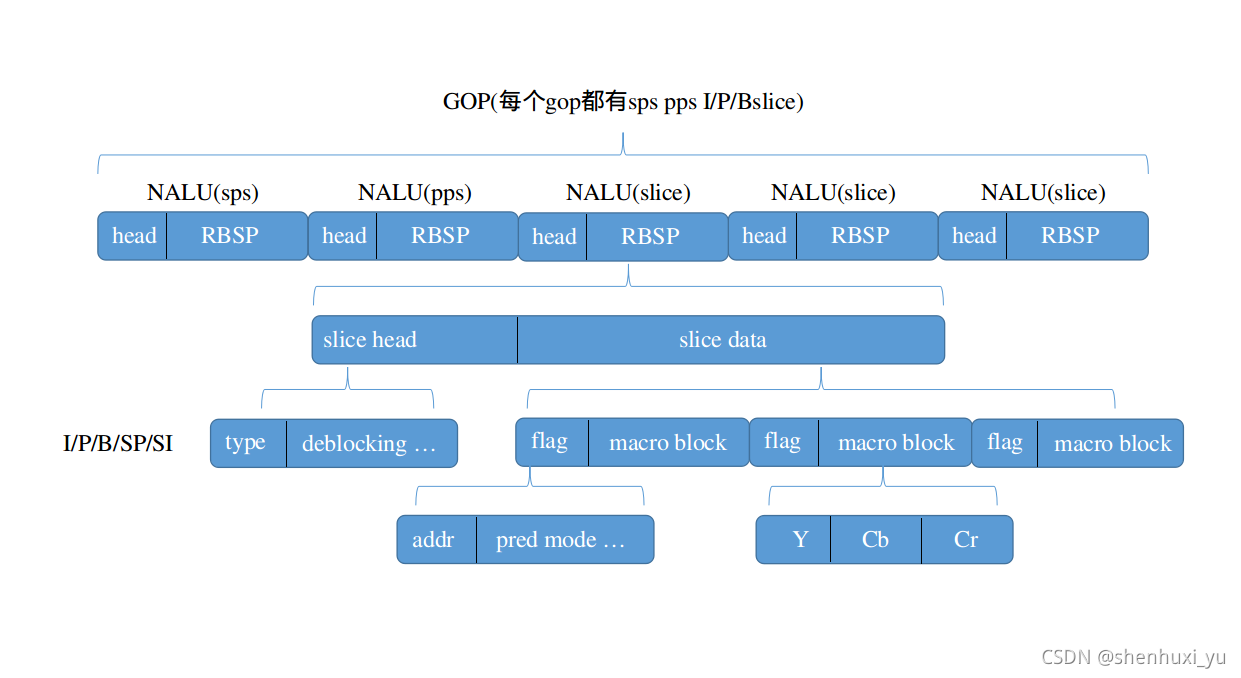
Slice
在H.264编码中,Slice的内部结构主要由Slice Header和Slice Data两部分组成。
- Slice Header:Slice Header包含了Slice的一些重要信息,用于解码器正确解码Slice Data。Slice Header的主要内容包括:
-
- Slice类型:这决定了Slice的编码方式,例如I-Slice只包含I宏块,P-Slice包含P宏块,B-Slice包含B宏块。
- 宏块类型:这决定了宏块的编码方式,如是否进行帧内预测、帧间预测等。
- Slice的起始和结束宏块地址:这告诉解码器Slice在帧中的位置。
- 量化参数(Quantization Parameter, QP):这影响了视频的质量和压缩比。
- 其他参数:如参考帧信息、滤波参数等。
- Slice Data:Slice Data是Slice的主要部分,它包含了实际的像素数据。Slice Data主要由一系列宏块(Macroblock)组成,每个宏块包含了16x16的亮度像素和附加的8x8的色度像素块。宏块中的数据是以4x4的块为单位进行编码的,每个4x4块可能进行DCT变换、量化、熵编码等步骤。
- 在H.264编码中,一帧图像可以编码为一个或多个slice。对于I帧来说,虽然它包含了完整的图像信息,但也可以根据编码器的设置和实际需求被分成多个slice
NALU与Slice的关系
在H.264视频编码标准中,编码后的视频数据被封装成NALU进行传输。每个NALU由一个NAL单元头和NAL单元载荷组成,其中NAL单元载荷部分可以包含不同类型的编码数据,而slice的编码数据就是其中之一。同样sps和pps也是nalu的负载类型之一。
当一帧图像被分割成多个slice进行编码时,每个slice的编码数据会被分别封装进不同的NALU中(尽管在某些情况下,一个slice的数据也可能被分割并封装进多个NALU中,但这种情况较少见)。这些包含slice数据的NALU在视频流中按顺序排列,解码器在解码时会按照这些NALU的顺序来恢复出原始的slice数据,并进一步恢复出完整的视频帧。
因此,可以说NALU是包含slice的,它们之间的关系是封装与被封装的关系。NALU作为网络传输的基本单元,为slice数据的传输提供了便利,同时也支持了视频数据的错误检测、同步和传输优先级控制等功能。
4.9 参考帧管理
参考文档: https://blog.csdn.net/heli200482128/article/details/127054295
H.264/AVC中的滑动窗和MMCO(Memory Management Control Opreation) 这两种参考帧管理技术,是通过传输每一个片的DPB的相对变化来实现,一旦发生数据丢失,将会有持续的影响。
H.264/AVC中采用了滑动窗和MMCO两种方式。
滑动窗管理方式,是以DPB可以存放的帧数为窗口,随着当前解码的图像,以先入先出的方式,将新的解码图像移入,将超出窗口的解码图像移出,因此,DPB中保存的是最近解码的多个图像。
MMCO是通过在码流中传输控制命令,完成对DPB中图像的状态标记的,它可以将一个“Used for reference(short-term or long-term)”标记为“Unused for reference”,也可以将当前帧或者“Used for short-term referene”的帧标记为“Used for long-term reference”等
4.10 后处理的一些概念和技术
解码的后处理过程是对解码后得到的原始帧进行一系列优化和增强操作,以提高视频的质量和观看体验。这个过程可能包括以下几个步骤:
- 去块滤波(Deblocking Filter):在视频编码过程中,为了提高压缩效率,编码器可能会引入块效应,即在块的边界处出现不连续或明显的分界线。去块滤波器的目的是减少或消除这些块效应,使图像看起来更加平滑和自然。
- 环路滤波(Loop Filter):在某些视频编码标准中,如HEVC(H.265),环路滤波器被用于进一步改善解码后的图像质量。环路滤波器可以减少编码和解码过程中引入的失真和噪声,提高图像的清晰度和细节。
- 色度子采样格式转换:在视频编码中,为了节省带宽和存储空间,通常会采用色度子采样(Chroma Subsampling)技术,即减少色度分量(通常是红色和蓝色分量)的分辨率。在解码后,可能需要将色度分量恢复到原始分辨率,以获得更好的图像质量。
- 色彩空间转换:解码器可能还需要进行色彩空间转换,将解码后的帧从一种色彩空间(如YUV)转换到另一种色彩空间(如RGB),以适应显示设备或后续处理的要求。
- 缩放和裁剪:如果解码后的帧的分辨率与显示设备的分辨率不匹配,可能需要进行缩放操作。此外,根据需要对帧进行裁剪,以去除不需要的边缘或黑边。
- 帧率上转换/下转换:如果解码后的视频的帧率与显示设备的帧率不匹配,可能需要进行帧率上转换(增加帧率)或帧率下转换(减少帧率)操作,以匹配显示设备的帧率。
4.11 ROI
1、什么是ROI编码
大家可能经常听到ROI这个词,但是通常说的ROI是return on investment,而视频编码ROI是region of interest。简而言之,ROI编码是提高特定区域的视频编码质量。这个特定区域,99%的案例中是人脸区域。
2、ROI编码的实现
实现ROI编码总共需要两步:
- 找出特定区域(😊)
- 提高特定区域编码质量
第一步基本上由AI包办,第二步交给编码器完成。
编码器调整特定区域编码质量的基本原理是调整量化参数qp(Quantization Parameter)。简单来说,qp越大,量化误差越大,编码质量越差;反之,qp越小,量化误差越小,编码质量越高。想增加某个区域的编码质量,即减小某个区域的qp。
typedef struct AVRegionOfInterest {
uint32_t self_size;
int top;
int bottom;
int left;
int right;
AVRational qoffset;
} AVRegionOfInterest;
其中,
self_size必须等于sizeof(AVRegionOfInterest),为了以后万一struct AVRegionOfInterest需要增加数据成员的时候。
top、bottom、left和right的单位是像素,以图像左上角为坐标原点,定义一个矩形像素区域,根据当前所用编码器的要求,此区域可能会被对齐处理。
qoffset则是对量化参数值(qp)在此矩形区域中的调整,qoffset的取值范围是[-1.0, 1.0],在传递给编码器的时候,还会先乘以当前编码器qp的取值范围,使得它和qp在数值上具有可加性,最后的加法发生在编码器内部。如果qoffset的值是0,则表示不改变qp值。如果qoffset是正数,将使得最终qp值变大,从而使得图像质量变差;如果qoffset是1.0,则按最差质量编码。如果qoffset是负数,将使得qp值减小,从而图像质量变好;如果qoffset为-1.0,这个区域内的图像将按编码器的最佳图像质量编码。之所以用AVRational而不是float来定义qoffset,是因为IEEE float无法精确表示小数值,不利于跨平台一致性。
3 对应的ffmpeg命令格式:
./ffmpeg -i input.mp4 -an -c:v libx264 -vf addroi=x=350:y=270:w=300:h=400:qoffset=-0.5 -frames 3 out.mp4
./ffmpeg -threads 1 -debug qp -i out.mp4 -f null -
4.12 OSD
参考文档:https://blog.csdn.net/li_wen01/article/details/105025111
4.12.1 OSD基本概念理解
(1)Overlay叠加
视频叠加区域,其中区域支持位图的加载、背景色更新等功能,简单理解就是可以设置透明度,也就是下面的Alpha值
(2)Cover遮挡
视频遮挡区域,其中区域支持纯色块遮挡,与Overlay叠加不同的是它不能加载图片,不能设置透明度
(3)Alpha通道
如果图形卡具有32位总线,附加的8位信号就被用来保存不可见的透明度信号以方便处理用,这就是Alpha通道。白色的alpha象素用以定义不透明的彩色象素,而黑色的alpha象素用以定义透明象素,黑白之间的灰阶用来定义半透明象素。
VPSS OVERLAY时,Alpha取值范围为[0, 255]。取值越小,越透明。
VPSS VENC 时,Alpha取值范围为[0, 127]。取值越小,越透明。
(4)Stride图像跨距
Image Stride(内存图像行跨度) 当视频图像存储在内存时,图像的每一行末尾也许包含一些扩展的内容,这些扩展的内容只影响图像如何存储在内存中,但是不影响图像如何显示出来;Stride 就是这些扩展内容的名称,Stride 也被称作 Pitch,如果图像的每一行像素末尾拥有扩展内容,Stride 的值一定大于图像的宽度值,就像下图所示:
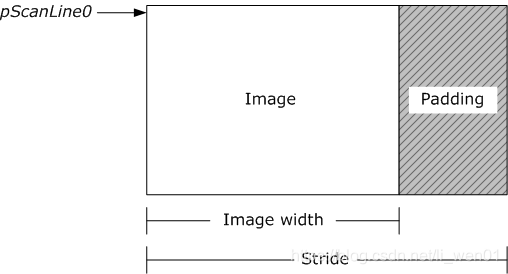
两个缓冲区包含同样大小(宽度和高度)的视频帧,却不一定拥有同样的 Stride 值,如果你处理一个视频帧,你必须在计算的时候把 Stride 考虑进去;
在做OSD水印的时候,叠加图片的stride值大于region画布的宽度时,该图像添加到画布会失败。
4.12.2 像素格式
OVERLAY VENC类型支持:Argb1555,Argb4444
OVERLAY VPSS类型支持:Argb1555,Argb4444,Argb8888
ARGB---Alpha,Red,Green,Blue.一种色彩模式,也就是RGB色彩模式附加上Alpha(透明度)通道,常见于32位位图的存储结构。
(a)格式类型
ALPHA_8:数字为8,图形参数应该由一个字节来表示,应该是一种8位的位图,常见的颜色格式:
ARGB_4444:4+4+4+4=16,图形的参数应该由两个字节来表示,应该是一种16位的位图.
ARGB_8888:8+8+8+8=32,图形的参数应该由四个字节来表示,应该是一种32位的位图.
RGB_565:5+6+5=16,图形的参数应该由两个字节来表示,应该是一种16位的位图.
Argb1555 也就是15位表示透明度和分别使用5位表示R,G,B,构成一个32位的位图,其中有两个位没有使用到。
(b)颜色格式
颜色对照表可以查看:https://tool.oschina.net/commons?type=3
同样是RGB颜色,但是颜色格式却有很多种,所以查表得到的颜色与显示的颜色是不能对应的,需要转换或是直接对应格式查找。
(c)颜色转换
三种RGB格式表示方式:
RGB555: R-5bit,G-5bit,B-5bit
RGB565: R-5bit,G-6bit,B-5bit
RGB888: R-8bit,G-8bit,B-8bit
RGB888转RGB555
RGB888 : R7 R6 R5 R4 R3 R2 R1 R0 G7 G6 G5 G4 G3 G2 G1 G0 B7 B6 B5 B4 B3 B2 B1 B0
RGB555 :0 R7 R6 R5 R4 R3 G7 G6 G5 G4 G3 B7 B6 B5 B4 B3
4.12.3 生成OSD图像
使用的现成的图片,加载到视频流中去,生成OSD图像。
以时间水印为例,要实现将时间水印添加到视频流流中去,大的流程只有两个:
- 生成带带时间的图像
- 将时间图像加载到预设置的region画布中去
参考ffmpeg命令:TBD
4.13 CTU 等编码单元的名词解释
HEVC,也有叫H.265,MPEG-H 第二部分(ISO/IEC 23008-2)的,指的都是同一个东西。一个不错的概论 出版了(一开始并不容易看懂,译者注)。
然而,一样,制定标准的作者都喜欢一些像是加密的简写。可能立马会让读者泄气的就是一些块结构编码的属于,比如 CTU,CU,CTB,CB,PB,还有TB。
他们基本上是代替了之前标准里的宏块(Macroblocks )和块(blocks )。不像十年前,现在我们视频的尺寸很大。4K已经变成现实,人们开始谈论8K。甚至移动设备也有如高于 HD 帧尺寸的 2048 x 1530 的尺寸。我们需要更大的宏块来为这些大尺寸的帧进行有效的编码。另一方面,小的细节也很重要,我们有时想在4x4的尺度上进行预测和转换。
我们如何有效地支持各种各样的块大小?这就是HEVC想用那些带缩写名词的东西来解决的。
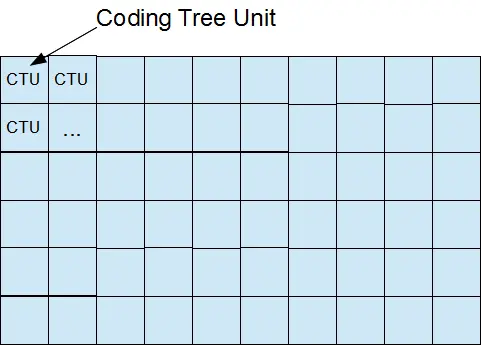
让我们从高等级的开始。假设我们有一个图像要编码。HEVC将这个图片分成很多CTU(Coding Tree Unit,编码树单元)
CTUs (Coding Tree Unit)
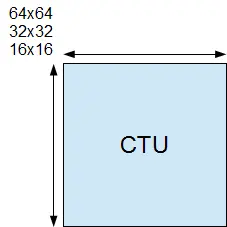
一个序列参数集将告诉我们CTU的宽和高,同时也意味着在一个视频序列里有相同的尺寸:64×64, 32×32, 或 16×16。
CTU
我们需要好好理解一下这里的一个重要的命名习惯。在HEVC标准里,如果一个东西叫 xxx单元,这就表示一个依次编码成HEVC比特流的编码逻辑单元。
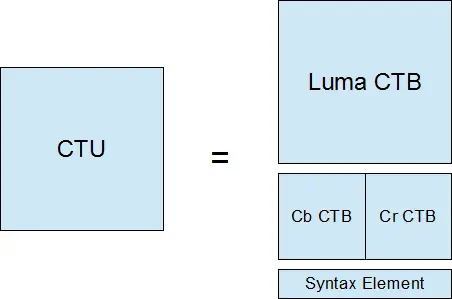
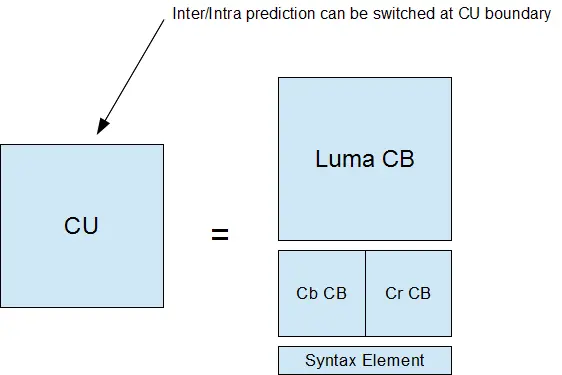
CTU--编码树单元就是这样一个逻辑单元。它通常包括三个块,也就是一个亮度块(Y)块两个色度块(Cb and Cr),除此之外它还包括相关的语法元素。这样的一个块就叫做CTB(Coding Tree Block 编码树块)。
每个编码树块(CTB)都有和编码树单元(CTU )一样的大小--64×64, 32×32, 或 16×16。然而,编码树块(CTB)--也取决于视频帧的哪一个部分--可能太大以至于很难决定我们应该施以帧间预测或者帧内预测。因此,每个编码树块(CTB)又可以相应的被分割成很多编码块(Coding Blocks,CB ),这样每个编码块(CB)就成了决定预测类型的决定点。比如,一部分编码树块(CTB)被分成一些16×16的编码块(CB)而另一部分被分割成一些8×8 的编码快(CB)。HEVC支持的编码块(CB)尺寸从编码树块(CTB)的所有尺寸直到小至8×8的尺寸。
下面这这张图片说明了 64×64 的编码树块(CTB)可以被分割成很多编码块(CB)。
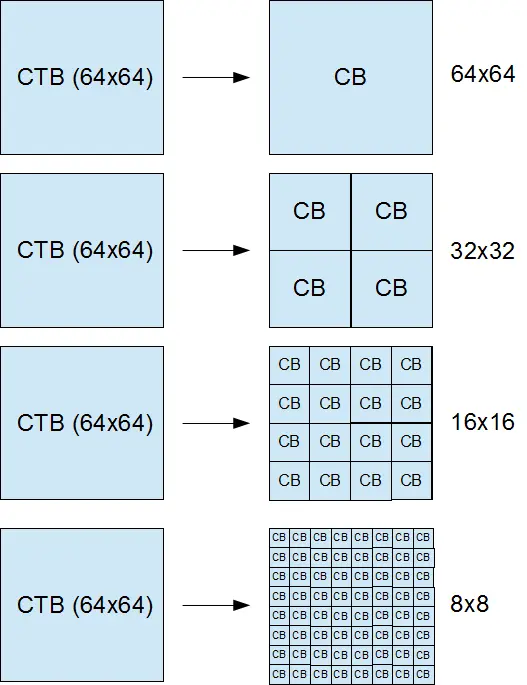
CTBs
编码块(CB)是判断执行帧间预测还是帧内预测的决定点。更精确地说,预测类型是被编码在编码单元(Coding Unit,CU)里的,编码单元(CU)包括三个编码块(Y,Cb和Cr)和相关的语法元素。
CB
编码块对于预测类型的判定是足够好的了,但是对于存储运动向量(帧间预测时要用到的)或帧内预测的模式来说还是太大了。比如,一个非常小的目标,像是下落的雪,可能总是在8×8的编码块的中间移动--而我们想要的是根据CB的不位置得来的不同的运动向量。
因此就引入了预测块(Prediction Block , PB)。每个编码块可以以不同的方式分割成多个预测块,而如何分割取决于时域和/或空域的可预测性。
PB
一旦做出了预测,我们需要对残差(预测图像和实际图像不一样的地方)经过类似离散余弦变换后进行编码。
TB
让我们阅读一个跟这些属于相关的标准草案文本。现在它们应该更容易理解了。
下面直接上原文吧:)
CTU (coding tree unit): A coding tree block of luma samples, two corresponding coding tree blocks of chroma samples of a picture that has three sample arrays, or a coding tree block of samples of a monochrome picture or a picture that is coded using three separate colour planes and syntax structures used to code the samples. The division of a slice into coding tree units is a partitioning.
CTB (coding tree block): An NxN block of samples for some value of N. The division of one of the arrays that compose a picture that has three sample arrays or of the array that compose a picture in monochrome format or a picture that is coded using three separate colour planes into coding tree blocks is a partitioning.
CB (coding block): An NxN block of samples for some value of N. The division of a coding tree block into coding blocks is a partitioning.
CU (coding unit): A coding block of luma samples, two corresponding coding blocks of chroma samples of a picture that has three sample arrays, or a coding block of samples of a monochrome picture or a picture that is coded using three separate colour planes and syntax structures used to code the samples. The division of a coding tree unit into coding units is a partitioning.
PB (prediction block): A rectangular MxN block of samples on which the same prediction is applied. The division of a coding block into prediction blocks is a partitioning.
TB (transform block): A rectangular MxN block of samples on which the same transform is applied. The division of a coding block into transform blocks is a partitioning.
4.14 码率控制
5 常用工具
5.1 ffmpeg
参考文档:https://blog.csdn.net/baiyang20140704/article/details/139308224

5.1.1 ffmpeg支持的编解码器,封装,像素格式
- 查看ffmpeg支持的 codec/encoders/decoders(编解码器),format(封装),pix_fmts(像素格式)
-
- ffmpeg -codecs
- ffmpeg -encoders
- ffmpeg -decoders
- ffmpeg -formats
- ffmpeg -pix_fmts
5.1.2 ffmpeg编码
编码是将yuv文件转化成某种视频编码格式的操作,命令如下
- ffmpeg -pix_fmt <yuv格式> -s <宽>x<高> -i <输入文件> -vcodec <编码的目标格式> <输入文件名>
举个栗子
- ffmpeg -pix_fmt yuv420p -s 1920x1080 -i input.yuv -vcodec h264 out.h264
解析每个部分的参数:
- -pix_fmt 代表着输入源的格式 yuv420p 代表 i420格式的limit range,如果要使用full range需要使用yuvj420p
-
- 注:支持的pix_fmt,可以用5.1.1节的命令 ffmpeg -pix_fmts查看
- -s 后面用x的形式输入对应的宽高
- -i 输入的源文件
- -vcodec 后面跟着使用的编码器,这里例子用的是h264, 还可以是hevc等
-
- 注:支持的codec,可以用5.1.1节的命令 ffmpeg -codecs查看
5.1.3 ffmpeg解码
解码是将编码的文件转化为yuv格式的操作,命令格式如下:
- ffmpeg -i <编码文件名> -c:v rawvideo -pixel_format <输出格式> <解码文件名>
注意的是ffmpeg会根据文件名的后缀判断输入和输出文件的格式,如果是yuv的话需要给定yuv的格式
举个例子
- ffmpeg -i test_1080p.h264 -c:v rawvideo -pixel_format yuv420p out.yuv 解码h264到i420
5.1.4 ffmpeg yuv转码,缩放与拼接
yuv格式转换,不同yuv格式之间的转换,如:
- ffmpeg -s 1280x720 -pix_fmt nv12 -i flowers_nv12_1280x720.yuv -pix_fmt nv21 nv12_to_nv21_1280x720.yuv
-
- 第一个 pix_fmt 是输入的pix格式
- 第二个 pix_fmt 是输出的pix格式
- 输入输出支持的pix_fmt可以用5.1.1节的ffmpeg -pix_fmts查看
缩放,常用将yuv文件从一个分辨率缩放到另一个分辨率的操作,如:
- ffmpeg -s:v 1920x1080 -i input.yuv -vf scale=960:540 -c:v rawvideo -pix_fmt yuv420p out.yuv
-
- 使用-vf 滤镜的 scale 方法,指定缩放对方的分辨率大小
拼接两个yuv文件, 但是前提必须确保两个yuv文件的分辨率大小是一致的,否则会出错
type a.yuv b.yuv > c.yuv
5.1.5 ffmpeg视频转码
参考文档:https://blog.csdn.net/lsb2002/article/details/134965318
视频转码:更改视频格式,codec,及其他属性信息
Profile和Level值:
- ffmpeg -i input.mp4 -profile:v baseline -level 3.0 output.mp4
- ffmpeg -i input.mp4 -profile:v main -level 4.2 output.mp4
- ffmpeg -i input.mp4 -profile:v high -level 5.1 output.mp4
如果ffmpeg编译时加了external的libx264,那就这么写:
- ffmpeg -i input.mp4 -c:v libx264 -x264-params "profile=high:level=3.0" output.mp4
Codec转换:
- ffmpeg -i h265_1080p_120fps_10s.mp4 -c:v libaom-av1 -strict -2 av1_1080p_120fps_10s.mkv
5.1.6 ffmpeg视频截取
截取 截取某一个文件的特定时间段的视频
- ffmpeg -i test.mp4 -vcodec copy -acodec copy -ss 00:00:00 -to 00:39:00 test_cut.mp4 -y
5.1.7 ffplay 播放
ffmpeg的专用的播放命令,如果是编码码流或者封装码流直接使用ffplay即可
ffplay input.h264
ffplay input.mp4
如果是yuv文件需要输入宽高
ffplay -video_size 1280x720 720p.yuv
5.1.8 ffprobe 查看视频流信息
ffprobe可以查看几个级别的信息:
- ffprobe -show_streams:流的信息,一条streams由多个packets组成
- ffprobe -show_packets:包的信息,一个packets由多个frames组成
- ffprobe -show_frames:帧的信息
- ffprobe -show_entries:过滤上述输出的某些条目。如,frame=pict_type, stream=level
- ffprobe -show_format:封装信息
栗子:
- ffprobe -v error -select_streams v:0 -show_frames -show_entries frame=pict_type,key_frame,pix_fmt,pict_type,motion_vectors -of default=noprint_wrappers=1 input.264
- ffprobe -v error -show_streams -select_streams v:0 -of default=nw=1 High_10_IntraOnly_00_Cavlc_80x96.avc
5.2 其他测试工具
linux,基于ffmpeg的播放器,mpv
linux,基于gstreamer的播放器,parole
windows,yuvplayer,yuv图像查看器,也能做有限格式的转换
windows,基于ffmpeg的播放器,potplayer


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









