






什么是Ajax爬虫?
1. 浏览器中可看到正常显示的数据,但使用requests得到的结果并没有。 这是什么原因呢?
requests获取的是原始的HTML文档,而浏览器中的页面是经过JS处理数据后生成的结果。
2. 这些数据的来源有哪些情况呢?
Ajax加载、包含在HTML文档中、经过JavaScript和特定算法计算后生成
什么是Ajax?
Ajax(Asynchronous JavaScript and XML)异步的JS和XML。原理是: 利用JS在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
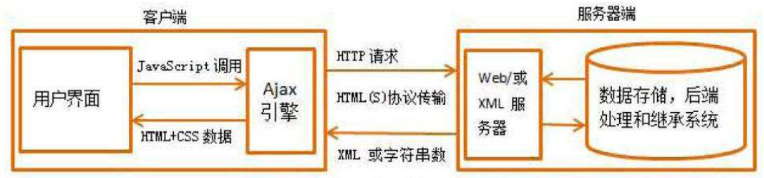
Ajax如何分析页面?
拖动刷新的内容由Ajax加载且页面的URL无变化,那么应该到哪里去查看这些Ajax请求呢?
-
开发者工具(F12)->Network选项卡, 获取页面加载过程中Browser与Server之间请求和响应。
-
筛选出所有的Ajax请求。在请求的上方有一层筛选栏,直接点击XHR(Ajax特殊的响应类型)
-
模拟Ajax请求,提取我们所需要的信息。
以手机版的微博为例分析页面:[https://m.weibo.cn]
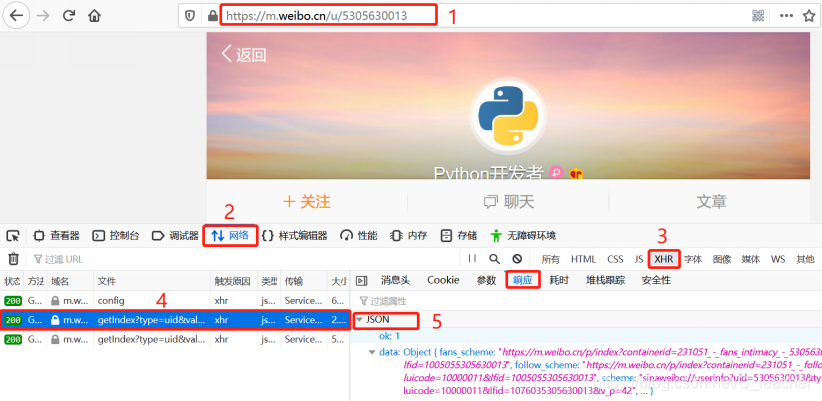
打开Ajax的XHR过滤器,然后一直滑动页面以加载新的微博内容。可以看到,会不断有Ajax请求发出。请求的参数有4个:type、value、containerid和page。page现在变成了一个时间点
https://m.weibo.cn/api/container/getIndex?type=uid&value=5305630013&containerid=1076035305630013&since_id=4494435587407740
since_id是关于分页的关键字,可以用page=n来代替
项目案例
基于Ajax和requests采集器的微博爬虫
项目描述
本项目爬取的目标是新浪微博指定用户的公开基本信息,如用户昵称、头像、用户的关注、粉丝列表以及发布的微博等,这些信息抓取之后保存至 MySQL。
项目技能点
- Requests + Ajax(XHR) + Json解析
- Scrapy + Ajax(XHR) + Json解析 + SpiderKeeper可视化工具
import json
import re
import time
import requests
from colorama import Fore
from fake_useragent import UserAgent
from requests import HTTPError
import lxml
from lxml import etree
def download_page(url,params=None):
try:
ua = UserAgent()
headers = {'User-Agent':ua.random}
response = requests.get(url,params = params,headers=headers)
except HTTPError as e:
print(Fore.RED + '[-]爬取网站%s失败:%s' %(url,str(e)))
return None
else:
# response.json()就像当于,html = response.text json字符串
# json.loads(html) 将字符串反序列化为python类型
# return response.json()
return response
def parse_html(html):
cards = html.get('data').get('cards')
count = 0
for card in cards:
try:
count += 1
text = card.get('mblog').get('text')
# print(text)
pattern = r'<.*?>'
result = re.sub(re.compile(pattern),'',text)
pics = card['mblog'].get('pics')
if pics:
for index,pic in enumerate(pics):
url = pic.get('url')
pic_content = download_page(url).content
img_name = url.split('/')[-1]
with open('weibo_pics/'+img_name,'wb') as f:
f.write(pic_content)
print('下载第%s张图片成功' %(index+1))
except Exception as e:
print('下载微博失败原因:%s' %(str(e)))
else:
print('第%s篇微博正文内容:%s' % (count, result))
if __name__ == '__main__':
uid = input('请输入爬取博主的uid:')
for page in range(1,11):
url = 'https://m.weibo.cn/api/container/getIndex?uid=%s&containerid=107603%s&page=%s' %(uid,uid,page)
html = download_page(url).json()
# print(html)
# print(type(html))
parse_html(html)














 8521
8521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









