







原文链接:http://media.pkusz.edu.cn/achievements/?p=40
AVS2采用了传统的混合编码框架,整个编码过程包括帧内预测、帧间预测、变换量化、环路滤波和熵编码等模块。具有如下技术特征:

图1 AVS2编码框架
1.编码结构划分
为了满足高清和超高清分辨率视频对压缩效率的要求,AVS2采用了更加灵活的基于四叉树的块划分结构,最大编码单元(Coding Unit, CU)为64×64,最小编码单元为8×8。同时, AVS2还采用了灵活的预测单元(PredictionUnit,PU)和变换单元(Transform Unit,TU)。待编码图像先被分割成固定大小的最大编码单元(Largest Coding Unit,LCU),然后按四叉树的方式迭代划分为一系列的CU。每个CU包含一个亮度编码块和两个对应的色度编码块(下文中块单元的大小指亮度编码块)。

图2 原始图像、LCU和CU之间的关系以及四叉树的划分结构。
预测单元PU是进行帧内预测和帧间预测的基本单元,它的尺寸不能超过当前所属CU。AVS2在上一代标准中的正方形帧内预测块的基础上,增加了非正方形的帧内预测块划分,同时,帧间预测也在对称预测块划分的基础上,增加了4种非对称的划分方式。

图3 帧内和帧间预测单元划分方式
除了CU和PU,AVS2还定义了用于预测残差变换和量化的变换单元TU。TU是变换和量化的基本单元,与PU一样,定义在CU之中。对于帧内模式,TU同PU绑定,大小相同。对于帧间模式,TU可以选择大块划分或小块划分。大块划分即将整个CU作为一个TU;小块划分时,CU块将被划分成4个小块TU,其尺寸的选择与对应的PU相关联,如果当前CU被划分为非方形PU,那么对应的TU将使用非方形的划分;否则,使用相应的方形划分类型。
2.帧内预测编码
帧内预测可以消除待编码图像在空域上的冗余。AVS2支持33种帧内预测模式 ,包括DC预测模式、Plane预测模式、Bilinear预测模式和30种角度预测模式。相比于AVS1和H.264/AVC,AVS2提供了更丰富、更细致的帧内预测模式。同时,为了提高精度,AVS2采用了1/32精度的分像素插值技术,分像素的像素点由4触头的线性滤波器插值得到。在色度块上有5种模式:DC模式、水平预测模式、垂直预测模式、Bilinear预测模式以及新增的亮度导出(Derived mode, DM)模式。

图4 亮度块帧内预测模式
3.帧间预测编码
与帧内预测不同,帧间预测用于消除时域上的冗余。和上一代AVS1和H.264/AVC编码标准相比,AVS2的帧间预测技术在预测模式上进行了加强和创新。
传统的帧间预测技术只有P帧和B帧,P帧是前向参考帧,预测单元只能向前参考一帧图像中的预测块,B帧是双向参考帧,预测单元可以向前和/或向后各参考一帧图像中的预测块。AVS2在此基础上,增加前向多假设预测F帧;针对视频监控、情景剧等特定的应用,设计了场景帧(G帧和GB帧)和参考场景帧S帧。
对于B帧,除了传统的前向、后向、双向和skip/direct模式,AVS2拥有独特的对称模式。在对称模式中,仅需对前向运动矢量进行编码,后向运动矢量通过前向运动矢量推导得到。
对于F帧,预测单元可以参考前向两个参考块,相当于P帧的多帧参考。AVS2将双假设预测分为两类,分别是时域双假设和空域双假设。时域双假设的当前预测块利用预测块加权平均作为当前块的预测值,但运动矢量差MVD和参考图像索引都只有一个,另外一个MVD和参考图像索引根据时域上的距离按线性缩放推导出来。而空域双假设预测也叫方向性多假设预测(Directional multi-hypothesis prediction,DMH),通过融合初始预测点周围的两个预测点得到,而且初始预测点位于这两个预测点的连线上。
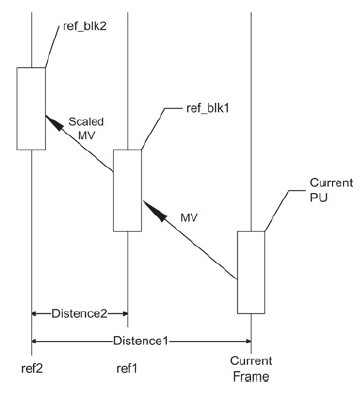
图5 时域的双假设预测
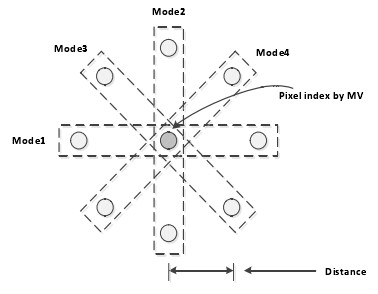
图6 空域的双假设预测(DMH)
4.运动矢量预测
运动矢量预测技术利用了相邻块的相关性,根据已编码相邻块的运动信息对当前待编码块的运动矢量进行预测,只对运动估计得到的运动矢量MV和预测运动矢量MVP的差值进行编码,从而降低用于编码运动矢量的比特数,节省码率。
在AVS2中,针对不同的帧间预测模式,采用了4种运动矢量预测方法:均值预测、空域预测、时域预测、空域和时域混合预测。为了进一步节省码率,当MVP和运动估计得到的MV大于某一阈值时,使用1/2精度的MV和MVD,否则仍然使用1/4精度。
预测方法 | 具体方法说明 |
均值预测 | 使用已编码相邻块的运动矢量的均值作为预测值 |
空域预测 | 使用已编码相邻块的运动矢量作为预测值 |
时域预测 | 使用时域上位置相同的块的运动矢量缩放值作为与预测值 |
空域和时域混合预测 | 使用时域上位置相同的块的运动矢量加上已编码相邻块的运动矢量差得到的运动矢量作为预测值 |
5. 变换
变换的目的在于去除空间上的相关性,将空间信号的能量集中到频域的小部分低频系数上,然后对这些变换系数进行后续编码处理。AVS2中的变换编码主要使用整数DCT变换。对于4×4、8×8、16×16、32x32大小的变换块直接进行整数DCT变换。而对于64×64大小的变换块则采用一种逻辑变换,先进行小波变换,再进行整数DCT变换。在DCT变换完成后,AVS2对低频系数的4×4块再进行二次4×4变换,从而进一步降低系数之间的相关性,是能量更集中。
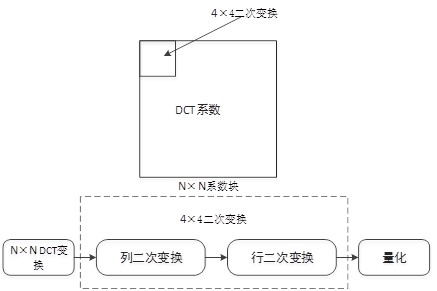
图7 4×4二次变换
6.熵编码
AVS2的熵编码首先将变换系数分为4×4大小的系数组(Coefficient Group,CG),然后根据系数组进行zig-zag扫描和基于上下文的二元算术编码。系数编码先编码含有最后一个非零系数的CG位置,接着编码每一个CG,直到CG系数都编码完为止,这样可以使得0系数在编码过程中更集中。
7.环路滤波
为了消除块效应、振铃效应、色度偏移和图像模糊等影响主观视觉的不良效果,AVS2的环路滤波包含三个部分:去块滤波、自适应样点偏移和样本补偿滤波。去块滤波的目的在于消除由于变换量化引起的块效应,基本的滤波单元为8×8的块,首先对垂直边界进行滤波,然后是水平边界。对每条边界根据滤波强度不同选择不同的滤波方式。
在去块滤波之后,采用自适应样本偏移补偿进一步减小失真。有两种补偿模式:边界补偿和边带补偿。边界补偿又分为垂直、水平、斜上和斜下四个滤波方向。边带补偿根据像素点重建值的振幅对每条边带加上不同的偏移值。
在去块滤波和样本偏移补偿之后,AVS2又添加了自适应滤波器,一种7×7十字加3×3方形中心对称的维纳滤波。利用原始无失真图像和编码重构图像计算最小二乘滤波器系数,并对重构图像进行滤波,降低重建图像中的压缩失真,提升参考图像质量。
8.场景编码
对监控视频、情景剧等特殊场景来说,视频图像的冗余很大一部分来自于背景。因此,AVS2设计了一种基于背景模型的监控工具来提高这些特定场景的压缩效率。未打开监控工具时,I帧只给下个随机访问点之前的图像做参考。打开监控工具后,AVS2会用视频中的某一帧做场景图像G帧,G帧对于后面的图像可以作为长期参考。此外,为了防止编码背景帧导致码率陡增,在传输上产生较大的延迟,AVS2采用了一种基于块更新的背景参考帧技术,在每一帧编码图像中选择不超过一定比例的LCU作为背景刷新块,在编完一帧之后对背景帧参考图像进行刷新。

图8 基于背景模型的场景帧
总结
AVS2在传统的编码技术上进行了很多的改进和创新,例如帧间预测部分新增了F帧、背景帧等,因此才能将视频的压缩效率大幅提高。尤其是场景编码,基于背景模型的编码方法大大提高监控视频等场景的压缩效率,比国际同期标准超过了一倍。以上就是AVS2标准的技术概述,接下来的《标准解说》专栏将对AVS2中的技术按模块进行详细地介绍。
(本文为原创作品,转载请注明来源)
欢迎关注公众号,及时接收更多技术干货















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









