







单条的SQL语句精确的同时伴随着的也是性能的降低,操作的繁琐,因此在数据库编程过程中经常会用到存储过程和事务等功能 , 相比 SQL 语句 , 它们更方便、快速、安全,很值得我们去学习 。
存储过程
1、基本概念
我们知道在Java程序中,会由编译器先将编写Java代码编译成class字节码文件,再由JVM来执行字节码,完成程序功能。由于SQL语言也是一种编程语言,需要编译后执行,所以在数据库编程中也存在其编译完成后的文件直接执行,这就是存储过程。
存储过程 (Stored Procedure) 是在大型数据库系统中 , 一组为了完成特定功能的 SQL 语句集 , 存储在数据库中 , 经过第一次编译后再次调用不需要再次编译 , 用户通过指定存储过程的名字并给出参数 (如果该存储过程带有参数) 来执行它。
存储过程是数据库中的一个重要对象 ; 存储过程中可以包含 逻辑控制语句 和 数据操纵语句 , 它可以接受参数 , 输出参数 , 返回单个或多个结果集以及返回值。
2、存储过程的优缺点
优点 :
- 由于应用程序随着时间推移会不断更改,增删功能 ,SQL语句会变得更复杂 , 存储过程为封装此类代码提供了一个替换位置 ;
- 由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的 SQL 语句块要快 ;
- 由于在调用时只需用提供存储过程名和必要的参数信息 , 所以在一定程度上也可以减少网络流量 , 简单网络负担 ;
- 可维护性高 , 更新存储过程通常比更改 , 测试以及重新部署程序集需要较少的时间和精力 ;
- 代码精简一致 , 一个存储过程可以用于应用程序代码的不同位置 ;
- 增强安全性 :
- 通过向用户授予对存储过程 (而不是基于表) 的访问权限 , 它们可以提供对特定数据的访问
- 提高代码安全 , 防止 SQL注入 (但未彻底解决 , 例如将数据操作语言 DML 附加到输入参数)
- SQLParameter 类指定存储过程参数的数据类型 , 作为深层次防御性策略的一部分 , 可以验证用户提供的值类型 (但也不是万无一失 , 还是应该传递至数据库前得到附加验证)
缺点 :
- 如果更改范围大到需要对输入存储过程的参数进行更改 , 或者要更改由其返回的数据 , 则仍需要更新程序集中的代码以添加参数 , 等等
- 可移植性差 , 由于存储过程将应用程序绑定到 Server , 因此使用存储过程封装业务逻辑将限制应用程序的可移植性 ; 如果应用程序的可移植性在您的环境中非常重要 , 则将业务逻辑封装在不特定于 RDBMS 的中间层中可能是一个更佳的选择
3、使用存储过程
1.基本步骤

//创建一个存储过程
create procedure getUsers()
begin
select * from user;
end;
//执行(调用)存储过程
call getUsers();
//删除存储过程
drop procedure if exists getUsers;需要注意的是,MySQL的命令行客户机的语句分隔符默认为分号 ;,而实用程序也是用 ;作为分隔符,这会使得存储过程的SQL出现语法错误,解决方式如下:
DELIMITER //
create procedure getUsers()
begin
select * from user;
end //
DELIMITER ;使用DELIMITER // 告诉命令行实用程序将 // 作为新的语句结束分隔符,最后再使用 DELIMITER ;改回来。
2.参数存储过程
MySQL支持 IN (传递给存储过程) , OUT (从存储过程传出) 和 INOUT (对存储过程传入和传出) 类型的参数 , 存储过程的代码位于 BEGIN 和 END 语句内 , 它们是一系列 SQL 语句 , 用来检索值 , 然后保存到相应的变量 (通过指定INTO关键字) 。
//使用IN参数和OUT参数,输入一个用户id,返回该用户的名字
create procedure getNameByID(
in userID int,
out userName varchar(200)
)
begin
select name from user
where id = userID
into userName;
end;
//调用存储过程,查询用户名字
call getNameByID(1, @userName);
select @userName;
//查询另一个用户名字
call getNameByID(2, @userName);
select @userName;一般的SQL语句的封装难以看出存储过程的优势,只有包含着了业务逻辑等复杂处理才能显出存储过程的强大之处:
//一个根据ID获取货品的价格,并根据参数判断是否折扣的存储过程
create procedure getPriceByID(
in prodID int, //输入参数货品ID
in isDisc boolean, //是否折扣
out prodPrice decimal(8,2) //返回的价格
)
begin
//定义两个局部变量tmpPrice和prodDiscRate
declare tmpPrice decimal(8,2);
declare prodDiscRate decimal(8,2);
set prodDiscRate = 0.88;
//把查询出来的结果赋给临时变量
select price from products
where id = prodID
into tmpPrice;
//判断是否折扣
if isDisc then
select tmpPrice*prodDiscRate into tmpPrice;
end if;
//最后把局部变量的值赋给输出参数prodPrice
select tmpPrice into prodPrice;
end;
//调用如下(ID为10086的打折货品的折扣价)
call getPriceByID(10086, 1, @prodPrice);//1为真,0为假
select @prodPrice;4、使用游标
MySQL检索操作返回一组称为结果集的行。这组返回的行都是与SQL语句相匹配的行(零行或多行)。使用简单的SELECT语句,例如,没有办法得到第一行、下一行或前10行,也不存在每次一行地处理所有行的简单方法(相对于成批地处理它们)。
有时,需要在检索出来的行中前进或后退一行或多行。这就是使用游标的原因。游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
create procedure simplecursor()
begin
declare youbiaoName cursor
for
select name from user;
open youbiaoName; -- 打开游标
-- //some code
close youbiaoName; -- 关闭游标,释放游标使用的所有内部内存和资源
end;这里定义了一个游标,使用declare 游标名 cursor for 来定义游标,该处查询用户表里的用户名, 存储过程处理完成后,游标就消失(因为它局限于存储过程),并没有任何返回和输出。
实际应用:
create procedure myyoubiao ()
BEGIN
declare done boolean default 0; --循环标记
declare tmp int; -- 临时存储变量
declare t DECIMAL(8,2); -- 同上
declare myyoubiao4 CURSOR for select id from user;
declare continue handler for sqlstate '02000' set done = 1;
create table if not exists mytable -- 表不存在是创建, 存在时跳过
(uId int, total decimal(8,2));
open myyoubiao4;
REPEAT
fetch myyoubiao4 into tmp;
call getTotalByUser2(tmp, 1, t); -- 根据用户id获取该用户总订单金额, 含税
insert into mytable(uId,total) values(tmp,t); --插入新表
UNTIL done end REPEAT;
CLOSE myyoubiao4;
END这个例子使用FETCH检索当前name到声明的名为tmp的变量中,FETCH是在REPEAT内,因此它反复执行直到done为真(由UNTIL done END REPEAT规定)。为使它起作用,用一个DEFAULT 0(假,不结束)定义变量done。
declare continue handler for sqlstate '02000' set done 1;
这条语句定义了一个CONTINUE HANDLER,它是在条件出现时被执行的代码。这里,它指出当SQLSTATE '02000'出现时,SET done=1。SQLSTATE '02000'是一个未找到条件,当REPEAT由于没有更多的行供循环而不能继续时,出现这个条件。
整个过程为:调用该过程时, 会自动创建一张包含用户id和用户订单总额的表mytable(若不存在), 再把遍历每一个用户, 通过之前的创建过程返回用户的订单总额,插入新创建的表中,之后可通过查询新表获得数据。
5、触发器
触发器是一种特殊类型的存储过程,不由用户直接调用。创建触发器时会对其进行定义,以便在对特定表或列作特定类型的数据修改时执行。
触发器从本质上来说,是一个存储过程,但是它与普通的存储过程不一样的地方在于,普通的存储过程是通过CALL方法进行调用的,而触发器不是用CALL调用,触发器是在我们提前设定好的事件出现以后,自动被调用的。
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件 ON 表名 FOR EACH ROW 执行语句;如下例,创建一个名为trig的触发器,触发器可在一个操作发生之前或之后执行,这里为AFTER所以是INSERT之后,触发器还指定为 FOR EACH ROW 因此代码对每一个插入行都执行。一旦在work表中有插入动作,就会自动往time表里插入当前时间。
CREATE TRIGGER trig AFTER INSERT
ON work FOR EACH ROW
INSERT INTO time VALUES(NOW());需要注意的是,尽管触发器看上去很智能,但是尽量少使用触发器,不建议使用。因为触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源;而且触发器是隐式的自动的存储过程,一旦出现问题很难排查。
事务管理
事务处理就是将多个操作或者命令绑定一起执行,所有命令全部成功执行才意味着该事务的成功,任何一个命令失败都意味着该事务的失败。即要么不执行,要么全部执行。
事务是一个最小的不可再分的工作单元。事务只和DML语句有关,或者说DML语句才有事务。
事务四大特性ACID
ACID,是指在可靠数据库管理系统(DBMS)中,事务(transaction)所应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
原子性:原子性是指事务是一个不可再分割的工作单位,事务中的操作要么都发生,要么都不发生。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:一致性是指事务使得系统从一个一致的状态转换到另一个一致状态。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
隔离性:多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
这指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。
持久性:是指一个事务一旦提交并执行成功,那么对数据库中数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
并发事务问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题:
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复度和幻读区别:
不可重复读的重点是修改,幻读的重点在于新增或者删除。
例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
事务隔离级别
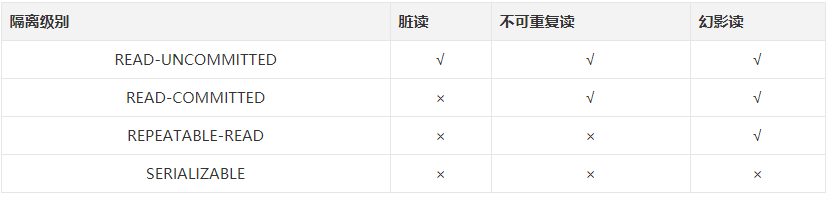
针对这些事务并发的问题,数据库设定了四个事务的隔离级别:

- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL默认的隔离级别就是可重复读。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个串行执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
事务模式
不同的事务模式限制具有不同的功能特点,具体有以下几种事务模式分类:
- 扁平化事务:在扁平事务中,所有的操作都在同一层次,这也是我们平时使用最多的一种事务。它的主要限制是不能提交或者回滚事务的某一部分,要么都成功,要么都回滚。
- 带保存点的扁平事务:为了解决第一种事务的弊端,就有了第二种带保存点的扁平事务。它允许事务在执行过程中回滚到较早的状态,而不是全部回滚。通过在事务中插入保存点,当操作失败后,可以选择回滚到最近的保存点处。
- 链事务:可以看做是第二种事务的变种。它在事务提交时,会将必要的上下文隐式传递给下一个事务,当事务失败时就可以回滚到最近的事务。不过,链事务只能回滚到最近的保存点,而带保存点的扁平化事务是可以回滚到任意的保存点。
- 嵌套事务:由顶层事务和子事务构成,类似于树的结构。一般顶层事务负责逻辑管理,子事务负责具体的工作,子事务可以提交,但真正提交要等到父事务提交,如果上层事务回滚,那么所有的子事务都会回滚。
- 分布式事务:是指分布式环境中的扁平化事务。
使用事务
关于事务的一些术语:
- 开启事务:Start Transaction
- 事务结束:End Transaction
- 提交事务:Commit Transaction
- 回滚事务:Rollback Transaction
- 保留点:savepoint
提交事务commit:commit之后即可改变底层数据库数据,不可回退
mysql> start transaction;#手动开启事务
mysql> insert into t_user(name) values('pp');
mysql> commit;#commit之后即可改变底层数据库数据
mysql> select * from t_user;
+----+------+
| id | name |
+----+------+
| 1 | jay |
| 2 | man |
| 3 | pp |
+----+------+
3 rows in set (0.00 sec)
MySQL默认情况下的行为都是自动提交的,你可以使用以下语句关闭这个自动改为手动。
SET autocommit=0;回退事务rollback:
mysql> start transaction;
mysql> insert into t_user(name) values('yy');
mysql> rollback;
mysql> select * from t_user;
+----+------+
| id | name |
+----+------+
| 1 | jay |
| 2 | man |
| 3 | pp |
+----+------+
3 rows in set (0.00 sec)可以回退INSERT、UPDATE和DELETE语句,但不能回退SELECT(实际上你回退没有任何意义,因为select不会对数据库有什么影响),也不能回退CREATE或DROP操作,因为这不属于DML语言。
使用保留点savepoint:
//设置保留点
SAVEPOINT point1;
//回退到指定保留点
ROLLBACK point1;
参考文章:
《MySQL必知必会》















 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









