







Luence高效本地索引查询,本机环境Luence4.3
1、用户model
public class User {
private String name;
private String id;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
public String getId()
{
return id;
}
public void setId(String id)
{
this.id = id;
}
}
2、下面mian方法中luence.db();创建本地索引,luence.search(keyWord);根据关键字检索数据
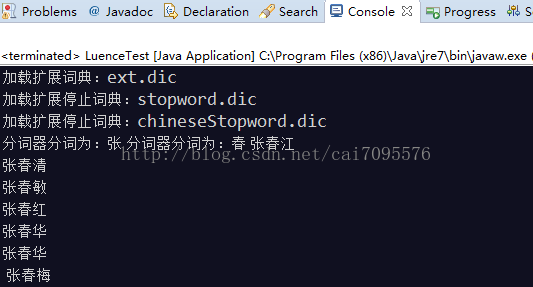
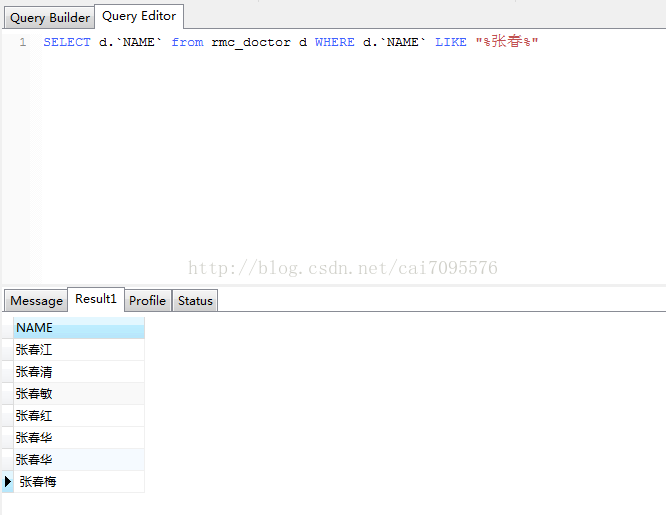
luence.search(“张春”);相当于数据库执行
SELECT d.`NAME` from rmc_doctor d WHERE d.`NAME` LIKE "%张春%"
具体实现方法如下:
import java.io.File;
import java.io.IOException;
import java.io.StringReader;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.TermToBytesRefAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* @Description: 数据库取值写入luence索引,查询本地索引
* @ClassName: LuenceTest.java
* @Package:
* @Date: 2015年5月11日 下午5:50:57
* <ModifyLog>
* @ModifyContent:
* @Author:
* @Date:
* </ModifyLog>
*/
public class LuenceTest {
//索引位置
public static final String IndexUrl ="F://medIndexText";
//全局indexsearcher
public static IndexSearcher searcher = null;
public static void main(String[] args)
{
//数据库取值--放入索引
LuenceTest luence = new LuenceTest();
luence.db();
//查询本地索引
String keyWord = "张春";
try {
searcher = luence.getIndexSearcher();
luence.search(keyWord);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* @Description: 取数据库值,并增加到luence
* @Date: 2015年5月11日 下午5:50:51
*/
public void db()
{
//驱动程序名
String driver = "com.mysql.jdbc.Driver";
//URL指向要访问的数据库名
String url = "jdbc:mysql://127.0.0.1:3306/rmc_core";
//MySQL配置时的用户名
String user = "rmc";
//MySQL配置时的密码
String password = "123456";
//Connection conn
Connection conn = null;
//结果集
ResultSet rs = null;
try {
//加载驱动程序
Class.forName(driver);
//连接MySQL数据库
conn = DriverManager.getConnection(url, user, password);
if (!conn.isClosed()) {
System.out.println("Succeeded connecting to the Database!");
//statement用来执行SQL语句
Statement statement = conn.createStatement();
//要执行的SQL语句
String sql = "select * from rmc_doctor";
try {
rs = statement.executeQuery(sql);
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("-----------------");
System.out.println("执行结果如下所示:");
System.out.println("-----------------");
String name = null;
User myUser = new User();
while(rs.next()) {
//选择name这列数据
name = rs.getString("name");
//输出结果
System.out.println(rs.getString("doc_id") + "\t" + name);
myUser.setName(name);
myUser.setId(rs.getString("doc_id"));
addUserIndex(myUser);
}
}
} catch (Exception e) {
} finally {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 初始化IndexWriter对象
*
* @param indexPath 索引库路径
* @return
*/
/**
* @Description: TODO
* @return
* @Author: caiyl13664@hundsun.com
* @Date: 2015年5月11日 下午5:53:10
*/
public IndexWriter getIndexWriter(){
IndexWriter writer = null;
Analyzer ik = new IKAnalyzer();
try {
//索引库路径不存在则新建一个
File indexFile=new File(IndexUrl);
if(!indexFile.exists()) indexFile.mkdir();
Directory fsDirectory = FSDirectory.open(indexFile);
IndexWriterConfig confIndex = new IndexWriterConfig(Version.LUCENE_46, ik);
confIndex.setOpenMode(OpenMode.CREATE_OR_APPEND);
if (IndexWriter.isLocked(fsDirectory)) {
IndexWriter.unlock(fsDirectory);
}
writer =new IndexWriter(fsDirectory, confIndex);
} catch (Exception e) {
e.printStackTrace();
}
return writer;
}
/**
* @Description: 增加索引
* @param user
* @return
* @throws Exception
* @Date: 2015年5月11日 下午5:53:17
*/
public Boolean addUserIndex(User user) throws Exception{
IndexWriter iwriter = getIndexWriter();
try {
Document doc = new Document();
String name = user.getName();
String id = user.getId();
//4,创建Field并添加到Document中,一个Field对应一行数据的一个字段
if(null==name||null==id){
return false;
}
doc.add(addField("userId", id,true,false));
doc.add(addField("name",name,true,false));
iwriter.addDocument(doc);
} catch (Exception e) {
throw e;
}finally{
iwriter.close();
}
return true;
}
/**
* 设置不分词
*
* @param name 名称
* @param value 实际存储值
* @param isStore 是否在索引的同时存储
* @return Field
*/
public Field addField(String name,String value,Boolean isStore,Boolean isTokenized){
FieldType f = new FieldType();
f.setTokenized(isTokenized);
f.setIndexed(true);
f.setStored(true);
return new Field(name,value,f);
}
/**
* @Description: 查询本地索引方法
* @param keyWord
* @throws IOException
* @Date: 2015年5月11日 下午5:53:48
*/
public void search(String keyWord) throws IOException{
IKAnalyzer analyzer = new IKAnalyzer();
// 分词处理
List<String> words = cutKeyWord(keyWord, analyzer);
IndexSearcher isearcher = searcher;
//Boolean组合查询,将输入后的分词集合word依次与索引中的最小单元进行匹配
List<Map<String,Object>> userlist = new ArrayList<Map<String,Object>>();
for(int i=0;i<words.size();i++){
Query blurQuery =new WildcardQuery(new Term("name","*"+words.get(i)+"*"));
Query accurateQuery = new TermQuery(new Term("name",words.get(i)));
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.add(blurQuery, Occur.SHOULD);
booleanQuery.add(accurateQuery, Occur.SHOULD);
ScoreDoc[] hits = isearcher.search(booleanQuery,1000).scoreDocs;
if(hits.length>0){
//当匹配命中后装载当前分词医院
for (int j = 0; j < hits.length; j++) {
Document hitDoc = isearcher.doc(hits[j].doc);
Map<String,Object> map = setUserData(hitDoc);
if(userlist.size()==0){
userlist.add(map);
}else{
Boolean isExsit = false;
for(int k=0;k<userlist.size();k++){
if(userlist.get(k).get("doc_id")!=null){
String hosid = userlist.get(k).get("doc_id").toString();
if(hosid.equals(map.get("doc_id").toString())){
isExsit = true;
}
}
}
if(!isExsit){
userlist.add(map);
}
}
}
}
}
for(int m=0;m<userlist.size();m++){
System.out.println(userlist.get(m).get("name"));
}
}
/**
* @TODO 中文分词
* @param keyWord
* @param analyzer
* @return
* @throws IOException
*/
public List<String> cutKeyWord(String keyWord,IKAnalyzer analyzer) throws IOException{
TokenStream tokenStream = analyzer.tokenStream("", new StringReader(keyWord));
TermToBytesRefAttribute termAtt = (TermToBytesRefAttribute) tokenStream.getAttribute(TermToBytesRefAttribute.class);
List<String> words = new ArrayList<String>();
//首先放入全称
words.add(keyWord);
while (tokenStream.incrementToken()) {
if(termAtt.toString().length()>1){
words.add(termAtt.toString());
}
System.out.print("分词器分词为:"+termAtt);
System.out.print(' ');
}
return words;
}
/**
* @TODO 封装Lucene精确查询方法
* @param key 取索引名称
* @param value 放入想匹配的值
* @param num 取前几的结果
* @return
* @throws IOException
*/
public static ScoreDoc[] accurateQuery(IndexSearcher searcher,String key,String value,Integer num) throws IOException{
Query accurateQuery = new TermQuery(new Term(key,value));
ScoreDoc[] hits = searcher.search(accurateQuery,num).scoreDocs;
return hits;
}
/**
* 装载用户元数据方法
* @param map
* @param hitDoc
* @return
*/
public static Map<String,Object> setUserData(Document hitDoc){
Map<String,Object> map = new HashMap<String,Object>();
map.put("name", hitDoc.get("name"));
map.put("doc_id", hitDoc.get("doc_id"));
return map;
}
/**
* 初始化IndexSearcher对象
*
* @param indexPath 索引库路径
* @return
*/
@SuppressWarnings("deprecation")
public IndexSearcher getIndexSearcher(){
IndexSearcher searcher = null;
if(searcher == null){
try {
IndexReader reader = IndexReader.open(FSDirectory.open(new File(IndexUrl)));
searcher = new IndexSearcher(reader);
} catch (Exception e) {
e.printStackTrace();
}
}
return searcher;
}
}
3、效果和数据库sql一致

















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









