







怎么去爬取一个网页
首先对于一个网页的组成,大家应该都十分的熟悉,毕竟大家都天天浏览网页的,比如你现在看到我这篇博文所处于的网页。作为程序员,我们更为关注的是网页部分的代码,网页部分的代码主要由HTML,JavaScript,CSS语言来编写,对于一个网页,我们在浏览器中所看到是一个十分漂亮的画面,但是实际上这是由浏览器对代码进行”翻译”后呈现出来的。从本质上说,它是一段HTML代码,加上JS,CSS。而JS和CSS的作用是起到美化的作用。有着锦上添花的意思。网页最核心的还是HTML代码那一块。此外,如何获取网页的信息?就是我们平时输入的网址,即URL。用URL来获取它的网页信息。下面我们通过一个例子来看看,是如何爬取一个网页的。
怎样去爬取网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到是一个优美的画面,但是实际上是由浏览器解释才呈现出来的,实质它是一段HTML代码,加上JS、CSS。JS、CSS起到了美化的作用,最总要的部分还是HTML。下面我们来爬取一个网页下来。
Eg. 我们爬取百度的首页。

代码部分
import urllib2
response = urllib2.urlopen(“http://www.baidu.com”)
print response.read()
你没有看错,仅仅三行的python代码,我们就爬取了一个网页的HTML代码,这就是python的魅力,很强大。我们把这三行代码保存为sample_demo1.py。至于如何去执行,想必大家应该有python的基础吧。
运行结果如下图
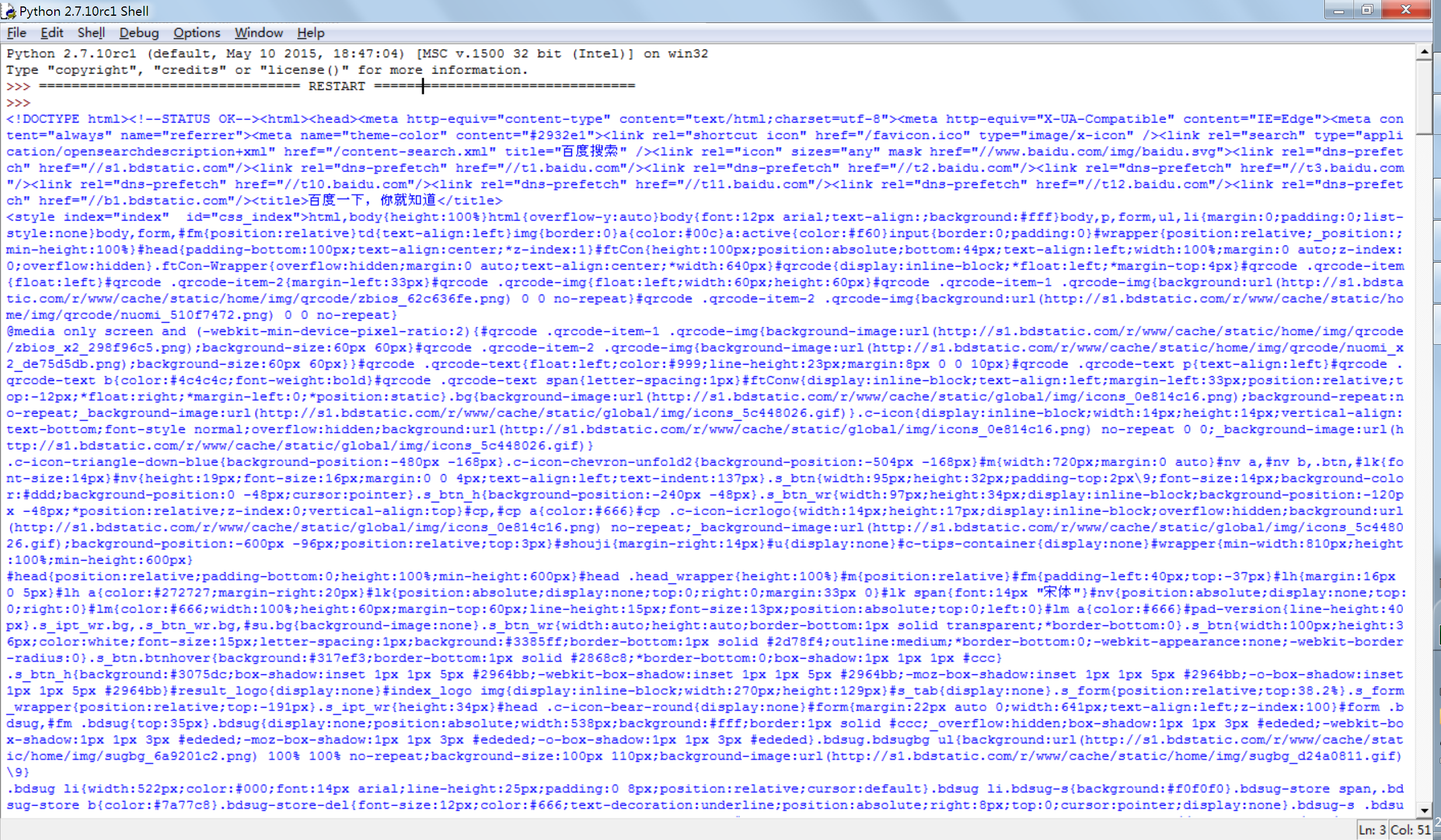
笔者用的Google浏览器,其实在Google浏览器中F12一键可以查看网页的HTML源代码。如下图
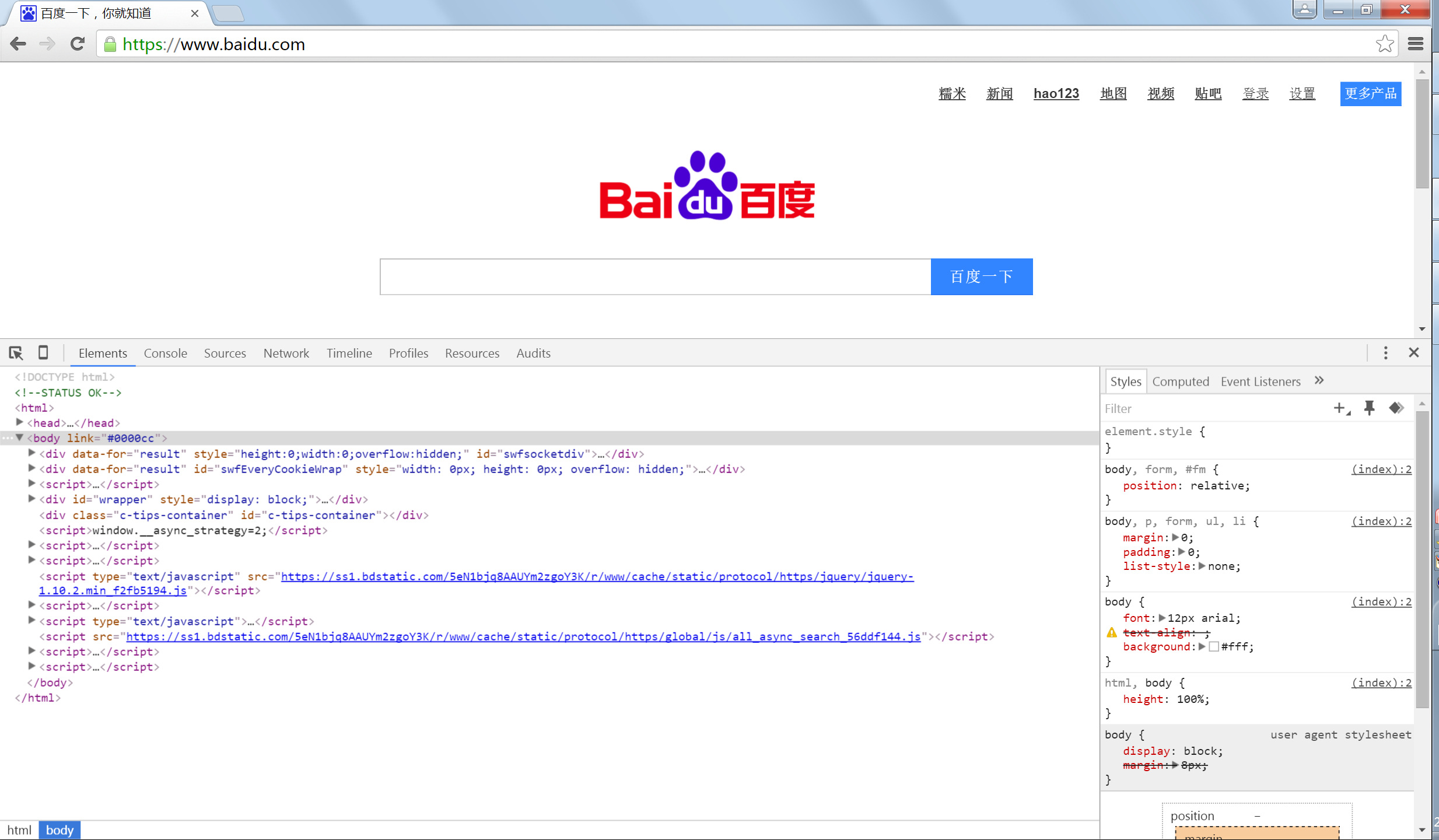
分析爬取网页的方法
在怎么去爬取网页中,我们给出了爬取百度首页的HTML代码,下面我们对上边的三行的代码进行分析。
第一行:import urllib2 我们导入了urllib2这个库。其实还有urllib这个库。所以有必要普及一下这两个库到底做些什么?引用一老外写的Python: difference between urllib and urllib2 我觉得这段介绍可以帮你分清楚urllib和urllib2.
You might be intrigued by the existence of two separate URL modules in python, urllib and urllib2 . Even more intriguing: they are not alternatives for each other. So what is the difference between urlib and urllib2, and do we need them both?
urllib and urllib2 are both python modules that do URL request related stuff buf offer different functionalities. Their two most significant differences are listed bellow:
urllib2 can accept a request object to set the headers for a url request, urllib accepts only a url That means , you cannot masquerade your User Agent string etc.
urllib provides the urlencode method which is used for the generation for GET query strings, urllib2 doesn’t have such a function. This is one of the reason why urllib is often used along with urllib2.
For other differences between urllib and urllib2 refer to their documentations, the links are given in the References section.
Tip: if you are planning to do HTTP stuff only, check out httplib2, it is much better than httplib or urllib or urllib2.
第二行:response = urllib2.urlopen(“http://www.baidu.com”) 我们首先调用urllib2库里面的urlopen方法,urlopen一般接受三个参数,具体方法形式如下:
方法:urlopen(url, data, timeout)
参数说明: url是要访问网址的url
data是访问url时要传送的数据,默认为空。
timeout是设置超时时间,默认为scoket.GLOBAL_DEFAULT_TIMEOUT
第一个参数是必须要传送的;第二个、第三个参数是可以不传送的。
其实我们把这三个参数构造成一个requst请求,那么方法变成urlopen(request)这样看起来更加清晰有逻辑。我们在后边在详细说明一下。
而第二行代码,我们只传入了一个url,所传入的网址是百度首页,协议所采用的是HTTP协议。当然,也可以是FTP、FILE。只是代表一种访问控制协议。在执行完urlopen方法之后,返回一个response对象,返回信息(百度首页的HTML代码)就保存在这个对象response对象中。
第三行:print response.read() 通过对第二行的分析,我们知道response中保存了我们想要的HTML代码。response对象中有一个read方法,可以返回获取到的网页内容。
如果不加上read方法,那么会打印出什么呢?大家动手试一试,看看response到底是什么。
构造Request
上面我们已经在urlopen方法中提及到request的概念。在上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入URL,DATA等内容。比如上面的三行代码,我们可以进行如下的改写
import urllib2
request = urllib2.Request(“http://www.baidu.com”)
response = urllib2.urlopen(request)
print respose.read()
运行结果是完全是一样的,只不过中间多了一个request对象,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样在逻辑上比较清楚明了。好了,到目前为止,对于所有的静态网页我们都可以搞定了,那么会有同学说对于动态网页的爬取怎么去做呢。请看下一篇的博文。














 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









