







正则化稀疏解决方案中,确保向量党的每个分量都非常有效,每个组件都必须捕获一些有用的功能或数据模式。(只要精英,其余的die)像dropout,去除一些权重可以使得剩下的权重学习到更多的只是。
L1和L2是正则化项,又叫做罚项,是为了限制模型的参数,防止模型过拟合而加在损失函数后面的一项。
L1和L2正则化的作用
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
L2正则化可以防止模型过拟合。(一定程度上,L1也可以防止过拟合)。
L1: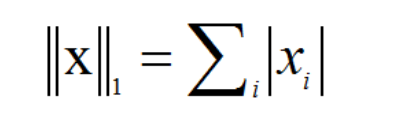
两个向量或矩阵的 L1-norm 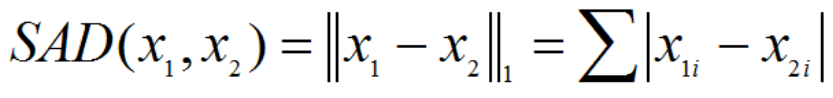
leisi
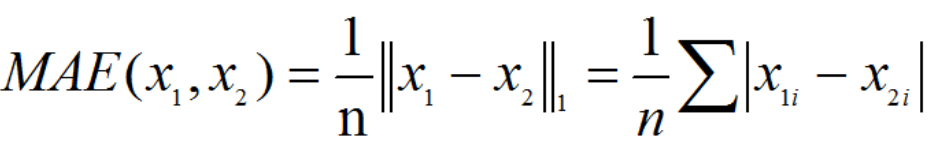
L2
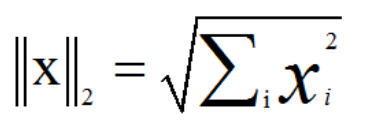
leisi
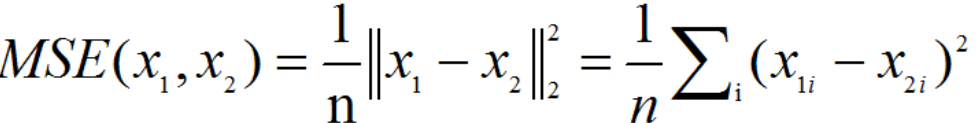
L1正则&L2正则的区别是什么?
L1正则化是指在损失函数中加入权值向量w的一范数,即各个元素的绝对值之和;L2正则化指在损失函数中加入权值向量w的平方和。
L1的功能是使权重稀疏,而L2的功能是使权重平滑。
稀疏解释:
https://blog.csdn.net/fantacy10000/article/details/90647686
L1正则为什么可以得到稀疏解?
- 以下图看的直径,x/y坐标分别是参数w1/w2。(L1在高维空间中诗歌八面体0)
下图所示为二维平面,只有w1和w2两个权重,右上角是经验损失的等值线。第一个交点就是最优解。
L2正则化相当于为参数定义了一个圆形的解空间(w12+w22),而L1正则化相当于为参数定义了一个菱形的解空间。L1“棱角分明”的解空间显然更容易与目标函数等高线在脚点碰撞。从而产生稀疏解。

2.函数叠加的角度
考虑一维的情况,横轴是参数的值,纵轴是损失函数,加入正则项之后,损失函数曲线图变化如下:
以下通过函数

3.贝叶斯先验
高斯分布
拉普拉斯分布
当均值为0时,高斯分布在极值点处是平滑的,也就是高斯先验分布认为w在极值点附近取不同值的可能性是接近的。但对拉普拉斯分布来说,其极值点处是一个尖峰,所以拉普拉斯先验分布中参数w取值为0的可能性要更高。















 1281
1281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









