







目录
- 简介
- 架构图
- 主从复制实践
- 主从复制原理
- 总结
- 相关配置说明
1. 简介:
就是我们常见的master/slave模式,把redis的数据库复制多个副本部署在不同的服务器上,如果其中一台服务器出现故障,也能快速迁移到其他服务器上提供服务
2. 架构图
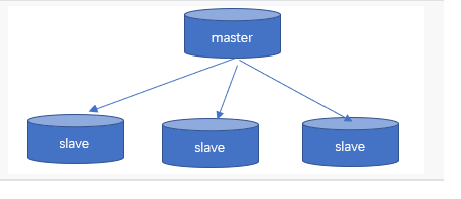
3. 主从复制实践
3.1 从服务配置redis.conf
# bind 127.0.0.1 //主从都注释掉,可以让别的主机访问
slaveof 192.168.127.131 6379 //设置主服务的IP+端口
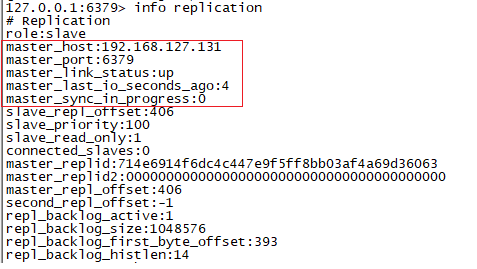
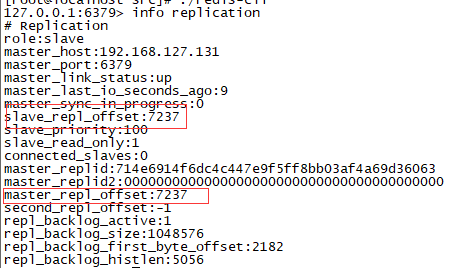
3.2 用info replication命令查看结果
4. 主从复制原理
4.1 三种复制方式:
- 全量备份
- 增量备份
- 无磁盘备份
4.2 全量备份
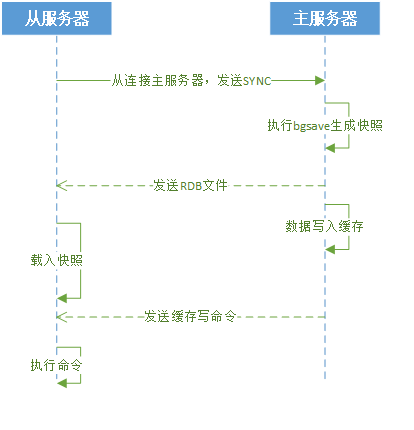
流程:
- 从服务器向主服务发送SYNC命令
- 主服务器收到SYNC命令后执行bgsave命令,在后台生成RDB文件,并用一个缓存区记录从现在开始执行的写命令
- 将RDB生成的快照文件发送给从服务器
- 从服务器收到快照后载入该文件,将自己服务器数据更新到和主服务器执行bgsave时同样的数据
- 主服务器将记录在缓冲区记录的数据发送给从服务器,从服务器执行这些命令,将自己数据和主服务器数据同步
时序图:
说明: 主从策略是容忍一定时间内主从不一致,是最终的一致性。
配置参数说明:
#表示只有当3个或以上的slave连接到master,master才是可写的
min-slaves-to-write 3
#表示允许slave最长失去连接的时间,如果10秒还没收到slave的响应,则master认为该slave已断开
min-slaves-max-lag 10
4.3 增量备份 从2.8版本之后开始支持
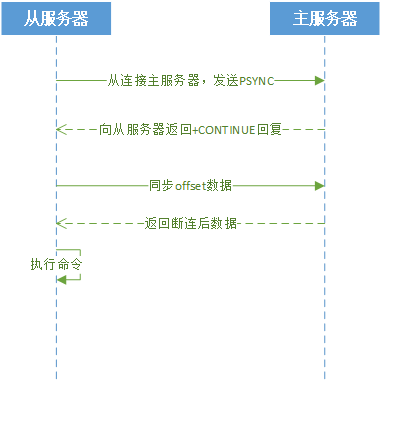
流程:
- 短线重连后,从服务器向主服务器发送PSYNC命令
- 主服务器向从服务器返回CONTINUE回复,准备开始增量备份
- 从服务接收到CONTINUE回复后准备开始复制
- 主从同步上次的offset数据
- 主服务器发送断连后的数据给从服务器
- 从服务器执行接收到的命令
时序图:
offset数据可以通过info replication查看
4.4 无磁盘复制
master**在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了,整体流程和RDB的方式差不多,只是少了写入RDB文件的过程
repl-diskless-sync yes
5. 总结:
Redis目前的复制是异步的,只保证最终一致性,而不是强一致性(主从数据库的更新还是分先后,先主后从)。要是一致性要求高的应用,目前还是读写都在主库上去
6. 相关配置说明
来源:https://www.cnblogs.com/zhoujinyi/p/5570024.html
# 主从配置选项 slaveof复制对应的master
# slaveof <masterip> <masterport>
# 如果服务端配置了密码,从库连接需要设置密码
# masterauth <master-password>
# 作为从服务器,默认情况下是只读的(yes)
slave-read-only yes
# 是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式
repl-diskless-sync no
#diskless复制的延迟时间,防止设置为0。一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。所以最好等待一段时间,等更多的slave连上来。
repl-diskless-sync-delay 5
#slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。
# repl-ping-slave-period 10
#复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时。
# repl-timeout 60
#复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有slave的一段时间,内存会被释放出来,默认1m。
# repl-backlog-size 5mb
#master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。
# repl-backlog-ttl 3600
#当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master。而配置成0,永远不会被选举。
slave-priority 100
#redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能。
# min-slaves-to-write 3
#延迟小于min-slaves-max-lag秒的slave才认为是健康的slave。
# min-slaves-max-lag 10














 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









