






效果
es实现select sum(..), max(..) where id in (1,2,3) group by id。
背景
skywalking的trace存储在es中,主要想查询几个特定的trace_id中的span错误总数以及最大的耗时时间,在es的查询语法中通过 aggs + terms可以实现分组查询,但是无奈该组合貌似是对整体的数据进行分组区分,这个数据量特别大,非常的慢甚至到超时,而需求是仅针对几个特定的trace_id进行查询即可。
主要是通过aggs中的filters进行数据的过滤,最后针对每个数据进行特定的max和sum即可,返回的结果中就是我们在mysql中一样看到的分组效果。
es rest api实现如下:
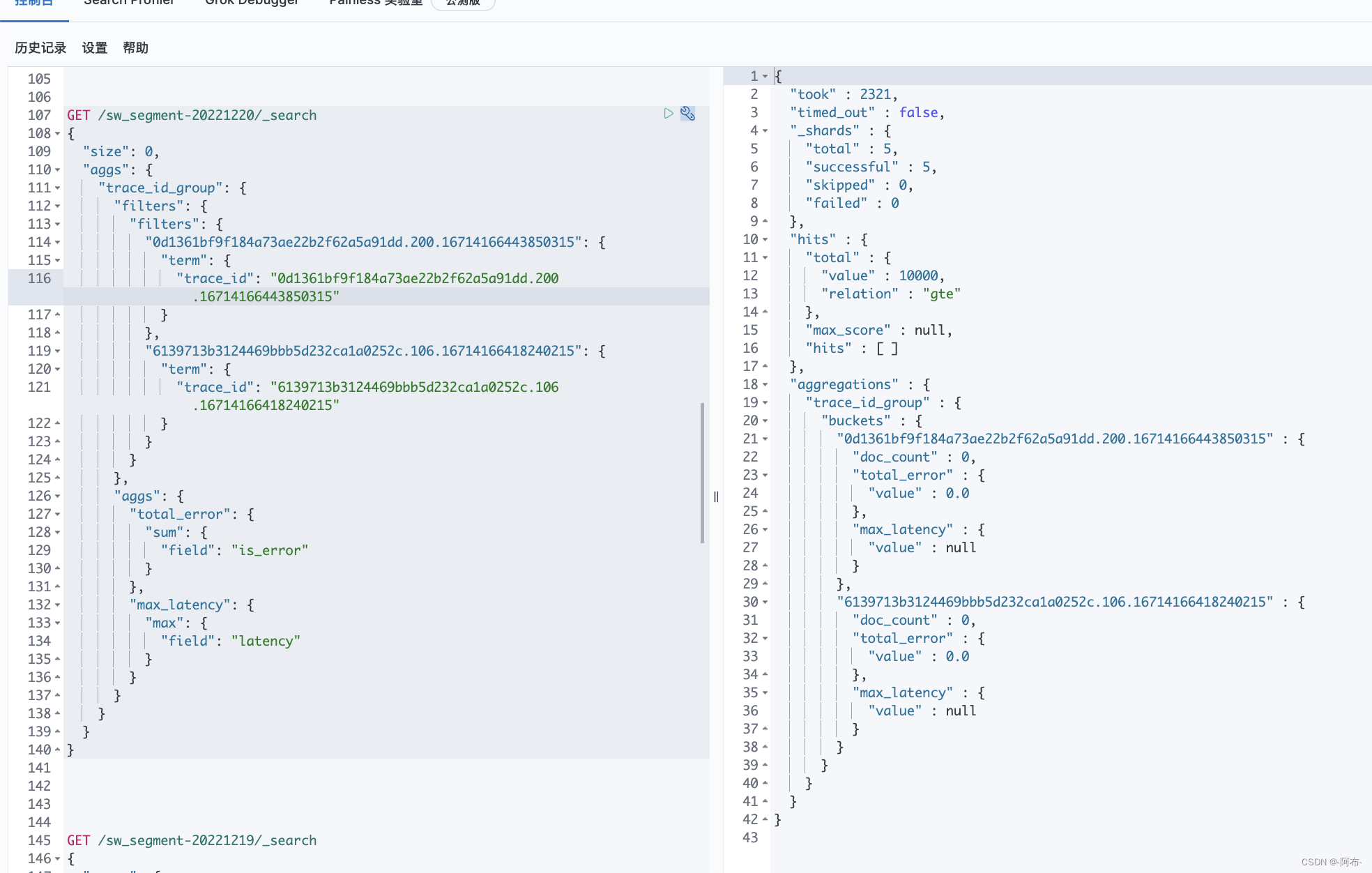
GET /sw_segment-20221220/_search
{
"size": 0,
"aggs": {
"trace_id_group": {
"filters": {
"filters": {
"0d1361bf9f184a73ae22b2f62a5a91dd.200.16714166443850315": {
"term": {
"trace_id": "0d1361bf9f184a73ae22b2f62a5a91dd.200.16714166443850315"
}
},
"6139713b3124469bbb5d232ca1a0252c.106.16714166418240215": {
"term": {
"trace_id": "6139713b3124469bbb5d232ca1a0252c.106.16714166418240215"
}
}
}
},
"aggs": {
"total_error": {
"sum": {
"field": "is_error"
}
},
"max_latency": {
"max": {
"field": "latency"
}
}
}
}
}
}
java代码的实现:
private void batchDelete(String indexName, List<String> traceIds, long maxMs) {
if (CollectionUtils.isEmpty(traceIds)) {
return;
}
// 基础设置
SearchRequest searchRequest = new SearchRequest(indexName);
// trace_id查询
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
// 构建聚合查询
List<FiltersAggregator.KeyedFilter> list = new ArrayList<>();
for (String traceId : traceIds) {
list.add(new FiltersAggregator.KeyedFilter(traceId, new TermQueryBuilder("trace_id", traceId)));
}
searchSourceBuilder.aggregation(
AggregationBuilders.filters("trace_id_group", list.toArray(new FiltersAggregator.KeyedFilter[]{}))
.subAggregation(AggregationBuilders.max("max_latency").field("latency"))
.subAggregation(AggregationBuilders.sum("total_error").field("is_error"))
);
searchRequest.source(searchSourceBuilder);
// 发起请求
client.searchAsync(searchRequest, RequestOptions.DEFAULT, new ActionListener<SearchResponse>() {
@Override
public void onResponse(SearchResponse response) {
Filters filters = response.getAggregations().get("trace_id_group");
List<String> deleteIds = new ArrayList<>();
filters.getBuckets().forEach(bucket -> {
String traceId = bucket.getKeyAsString();
Max max = bucket.getAggregations().get("max_latency");
Sum sum = bucket.getAggregations().get("total_error");
//System.out.println(traceId + " " + max.getValue() + " " + sum.getValue());
// 没有错误 并且小于最大耗时, 可以删除
if (sum.getValue() <= 0 && max.getValue() < maxMs) {
deleteIds.add(traceId);
}
});
deleteTrace(indexName, deleteIds);
}
@Override
public void onFailure(Exception e) {
log.error("batch aggregation query error", e);
}
});
}














 1699
1699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









