







“无穷小亮的科普日常”经常会发布一些鉴定网络热门生物视频,既科普了生物知识,又满足观众们的猎奇心理。今天我们也来鉴定一下网络热门植物!最近春天很多花都开了,我正好趁着清明假期到户外踏青并拍摄了不少花卉的照片。

由于对很多花不是特别熟悉,所以我们需要借助软件来识别究竟是什么花的种类。市面上的识花软件有很多,比如花伴侣、形色、百度等等,我测试后发现百度的识别效果最为优秀。于是我就有了一个想法,能不能批量调用百度的接口,对花卉照片进行识别并分类呢?(完整代码见文末)
百度图像识别
百度的图像识别接口,可以精准识别超过十万种物体和场景,包含10余项高精度的识图能力并提供相应的API服务。
https://cloud.baidu.com/product/imagerecognition
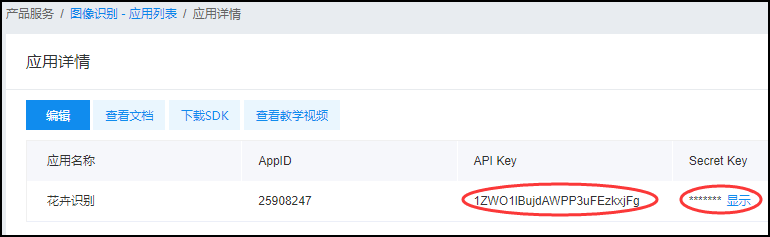
我们按照步骤创建新应用,并得到专属自己的API Key和Secret Key,具体如下图所示。
图像识别提供一个组合API接口,支持多种垂类识别服务的灵活组合调用,这里只需要调用植物识别就可以满足需求。
如何Python调用百度图像识别API接口?
第一步,调用鉴权接口获取token。
API_Key = '**********'
Secret_Key = '**********'
def get_access_token(API_Key,Secret_Key):
host = '**********'
response = requests.get(host)
return response.json()['access_token']
access_token = get_access_token(API_Key,Secret_Key)第二步,识别图像种类

在交互式环境中输入如下命令:
import requests
import base64
request_url = '**********'
# 二进制方式打开图片文件
f = open(r'D:\下载\QQ截图20220407203203.png', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json()['result'][0]['name'])输出:
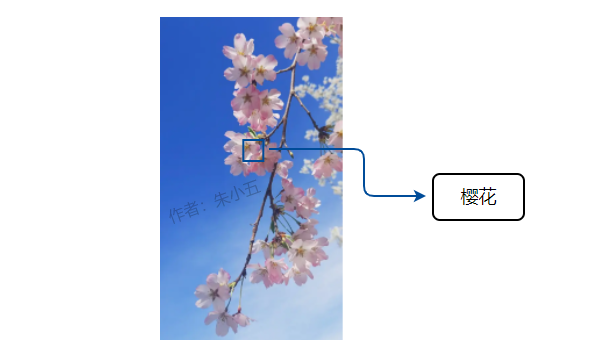
樱花调用百度图像识别接口的返回参数如下图所示,对我们来说,只需要其中的name(植物名称)参数。

读取照片文件
我将拍摄的照片存放在D:\下载\花卉合集路径下,所以需要使用os模块进行读取文件列表,方便进行后续的批量操作。
在交互式环境中输入如下命令:
import os
path = "D:\下载\花卉合集"
filenames = os.listdir(path)
filenames输出:
['QQ截图20220405223301.png',
'QQ截图20220405223320.png',
......
'微信图片_20220405225020.jpg',
'微信图片_20220405225023.jpg']os模块中的listdir()⽅法,接收⼀个路径参数path,返回的是该路径下所有⽂件的⽂件名组成的列表。这样,我们就获取了该路径下所有的花卉图片文件名,如下图所示。

整理分类照片
接着,我们便可以使用for循环语句,依次对花卉照片进行图像识别,并按照识别出的名称进行分类整理到对应的文件夹中。
在交互式环境中输入如下命令:
for i in filenames:
flower_name = get_fname(i)
file_path = os.path.join(path,i)
folder_path = os.path.join(path,flower_name)
if not os.path.exists(folder_path):
os.mkdir(folder_path)
shutil.move(file_path,folder_path)其中get_fname()函数,是我们将前文中百度图像识别代码封装为一个自定义函数,此处调用即可返回得到照片对应的花卉名称flower_name。
后续的代码与之前分享过的自动分类整理文件几乎一致,即if判断是否已经存在对应花卉名称的文件夹,若不存在则创建。最后,调用shutil模块移动花卉照片至对应文件夹。
具体执行效果,如下方动图所示。

这是我开发的机器人公众号小号,目前增加了天气查询,955公司名单,关注时间查询;后面还会增加图片功能和每日送书抽奖送书活动,以及调戏功能,欢迎来体验,捧场。
一个机器人公众号已经上线,欢迎调戏
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案
点阅读原文,看B站我的视频!

















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









