







数据透视表是一种分类汇总数据的方法。本文章将会介绍如何用Pandas完成数据透视表的制作和常用操作。
1,制作数据透视表
制作数据透视表的时候,要确定这几个部分:行字段、列字段、数据区,汇总函数。数据透视表的结构如图1所示。

图1 数据透视表的结构
Excel制作数据透视表很简单,选中表格数据,并点击工具栏上的“数据透视表”菜单即可,如图2所示。
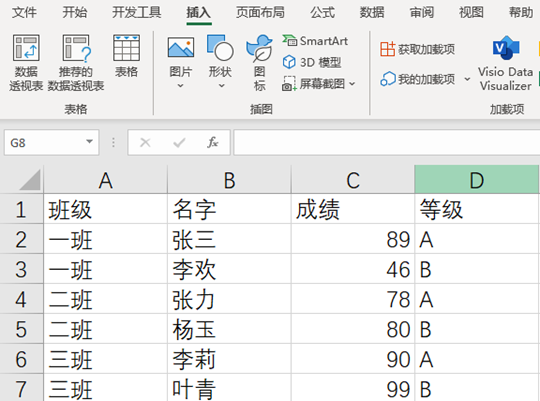
图2 Excel制作数据透视表
Pandas里制作数据透视表主要使用pivot_table方法。pivot_table方法的调用形式如下:
DataFrame.pivot(index, columns, values, aggfunc)其实index参数对应行字段,columns参数对应列字段,values参数对应数据区。aggfunc的默认值是numpy.mean,也就是计算平均值。
下面结合实例讲解pivot_table的用法,首先用以下代码导入示例数据:
import pandas as pd
import xlwings as xw
path = "D:/chapter11/数据透视表.xlsx"
wb = xw.Book(path)
sheet = wb.sheets[0]
df = sheet.range("A1:E7").options(pd.DataFrame, index=False, header=True).value用pivot_table方法制作数据透视表,商品作为行字段,品牌作为列字段,销售额放在数据区,这样设置:
pt1 = df.pivot_table(index='商品', columns='品牌', values='销售额')
sheet.range("G1").options(index=True, header=True).value = pt1结果如图3所示。这个表格计算的是销售额的平均值。
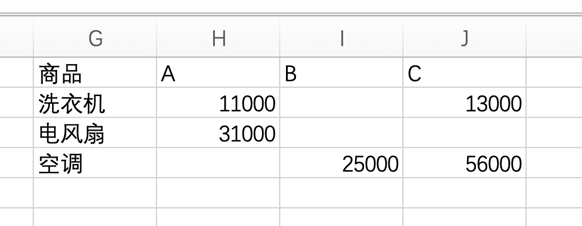
图3 商品销售数据透视表
上面的代码修改一下,把数量放在数据区,设置汇总函数是sum:
pt2 = df.pivot_table(index='商品', columns='品牌', values='数量' , aggfunc='sum')
sheet.range("G8").options(index=True, header=True).value = pt2结果如图4所示。这个表格计算的是销售数量的和。

图4 商品销售数据透视表
可以看到这两个数据透视表是有缺失值的,pivot_table有一个参数fill_value,就是用来填充这些缺失值的,例如:
df.pivot_table(index='商品', columns='品牌', values='数量', fill_value=0)pivot_table方法还支持对透视表进行统计计算,而且会新建一个列来存放计算结果。这个统计需要用到以下两个参数:
q margins,设定是否添加汇总列,一般设置为True。
q margins_name,汇总列的名称。
示例代码如下:
pt3 = df.pivot_table(index='商品', columns='品牌', values='销售额', fill_value=0, aggfunc='sum', margins=True, margins_name="汇总")
sheet.range("L1").options(index=True, header=True).value = pt3计算结果如图5所示。

图5 数据透视表汇总计算
参数index和values都可以是列表类型,例如:
pt4 = df.pivot_table(index=['品牌', '商品'], values=['销售额', '利润'], aggfunc='sum')
sheet.range("L8").options(index=True, header=True).value = pt4统计结果如图6所示。

图6 统计结果
这个数据透视表可以对利润和销售额进行不同的汇总计算,这时候aggfunc是字典类型,例如对销售额计算平均值,对利润计算总和,可以这样:
pt5 = df.pivot_table(index=['品牌', '商品'], values=['销售额', '利润'], aggfunc={
'销售额':'mean', '利润':'sum'})
sheet.range("L15").options(index=True, header=True).value = pt5统计结果如图7所示。
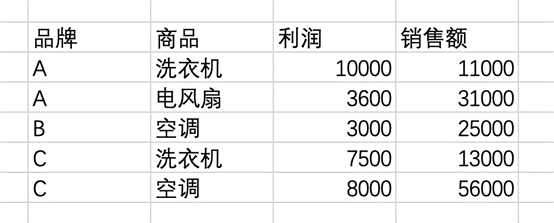
图7 统计结果
对于同一个指标可以设定多个汇总函数,例如:
pt6 = df.pivot_table(index=['品牌', '商品'], values=['销售额', '利润'], aggfunc={
'销售额':['mean', 'sum'], '利润':['mean', 'sum']})
sheet.range("L22").options(index=True, header=True).value = pt6统计结果如图8所示。

图8 统计结果
2,筛选数据透视表中的数据
pivot_table的运算结果是一个DataFrame类型,所以可以用DataFrame截取数据的方法筛选数据透视表中的数据。本节用于示例的数据透视表如下:
pt = df.pivot_table(index='商品', columns='品牌', values='销售额', fill_value=0, aggfunc='sum', margins=True, margins_name="汇总")在jupyter中输出pt如图9所示。
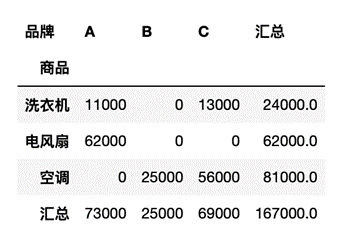
图9 输出变量pt
下面给出几个筛选数据的例子,这些例子的结果都可以通过Range对象的options方法转换成Excel表格数据。
(1)仅保留汇总列的数据。
pt['汇总']结果是一个Series,如下所示。
商品
洗衣机 24000.0
电风扇 62000.0
空调 81000.0
汇总 167000.0
Name: 汇总, dtype: float64要提取洗衣机的汇总数据,可以用以下表达式:
pt['汇总']['洗衣机'](2)获取品牌A、B、C的汇总数据。
pt[['A', 'B', 'C']]结果如图10所示。

图10 获取品牌A、B、C的汇总数据
(3)仅保留商品洗衣机的汇总数据。
pt.loc['洗衣机']结果如下所示。
品牌
A 11000.0
B 0.0
C 13000.0
汇总 24000.0
Name: 洗衣机, dtype: float64(4)仅保留商品洗衣机和电风扇的汇总数据。
pt.loc[['洗衣机', '电风扇']]结果如图11所示。

图11 仅保留结果的某些行
(5)仅保留汇总数据某些行和列。
pt[['A', 'B', 'C']].loc[['洗衣机', '电风扇']]输出结果如图12所示。

图12 仅保留汇总数据某些行和列
3,使用字段列表排列数据透视表中的数据
数据透视表是一个DataFrame,所以可以用sort_values方法来按某列排序,示例代码如下:
pt = df.pivot_table(index='商品', columns='品牌', values='销售额', fill_value=0, aggfunc='sum', margins=True, margins_name="汇总")
pt.sort_values(by="汇总")结果如图13所示。
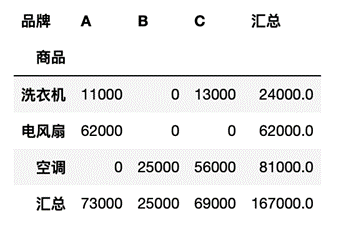
图13 按汇总列升序排列
从结果可以看出洗衣机的总销售额是最低的。
4,对数据透视表中的数据进行分组
在Excel中还支持对数据透视表中的数据进行分组,例如可以把风扇和空调的数据分为一组来计算,如图14所示。

图14 对数据透视表中的数据进行分组
用Pandas也可以实现类似的统计,示例代码如下:
代码11-9 对数据透视表中的数据进行分组统计
import pandas as pd
import xlwings as xw
path = "D:/chapter11/数据透视表.xlsx"
wb = xw.Book(path)
pt = df.pivot_table(index='商品', values='销售额', fill_value=0, aggfunc='sum',
margins=True, margins_name="总计")
pt.loc['分组1'] = pt.loc['电风扇'] + pt.loc['空调']
pt.loc['分组2'] = pt.loc['洗衣机']
# reindex方法重新排列表格
grouppt = pt.reindex(['分组1', '电风扇', '空调', '分组2', '洗衣机', '总计'])
sheet.range("A9").options(index=True, header=True).value = grouppt输出结果如图15所示。
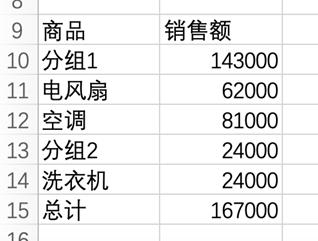
图15 数据透视表分组统计
代码中最关键的部分就是用loc属性读取数据透视表的行数据并进行相加运算得出分组统计结果。
声明:本文选自中国水利水电出版社的《
》一书,略有修改,经出版社授权刊登于此。

编辑推荐
Python Excel xlwings matplotlib Pandas 汇聚数据处理与分析的高效工具应用
全书85集配套视频 129个实例讲解
全面系统,覆盖了常用的Excel操作,从单元格操作到图表绘制,教你轻松实现Python数据分析和可视化
易学易懂,对比Excel,降低学习Python的难度,插图丰富,零基础入门学习
实例丰富,书中列举了100多个实例,用实例学习更高效
配套视频,每节配有视频教学,85集视频手把手教学,轻松实现办公自动化
包邮送出4本书,需要这本书的同学,可以后台输入:小助手,我们会在小助手的朋友圈抽奖送出,有兴趣的速来,备注暗号: 送书666















 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









