







目录
一、前言介绍
二、collyx框架
三、源码分享
四、实战展示
五、心得分享

一、前言介绍
前言:colly 是 Go 实现的比较有名的一款爬虫框架,而且 Go 在高并发和分布式场景的优势也正是爬虫技术所需要的。它的主要特点是轻量、快速,设计非常优雅,并且分布式的支持也非常简单,易于扩展。

github地址: github.com/gocolly/colly
colly官网地址:http://go-colly.org/
从上图中,我们可以看出colly在github社区有着超高的人气。今天我们即将引出collyx爬虫框架,下面我将通过源码分享介绍这个框架给各位读者。
二、collyx框架介绍
框架简介:基于colly框架及net/http进行封装,实现的一款可配置分布式爬虫架构。使用者只需要配置解析、并发数、入库topic、请求方式、请求url等参数即可,其他代码类似于scrapy,不需要单独编写。
框架优势:实现了重试机制,各个功能可插拔,自定义解析模块、结构体模块等,抽象了调度模块,大大减少代码冗余,快速提高开发能力;其中对于feed流并发的爬虫也能够生效,不止基于深度优先爬虫;也可以用于广度优先。
collyx架构图预览:
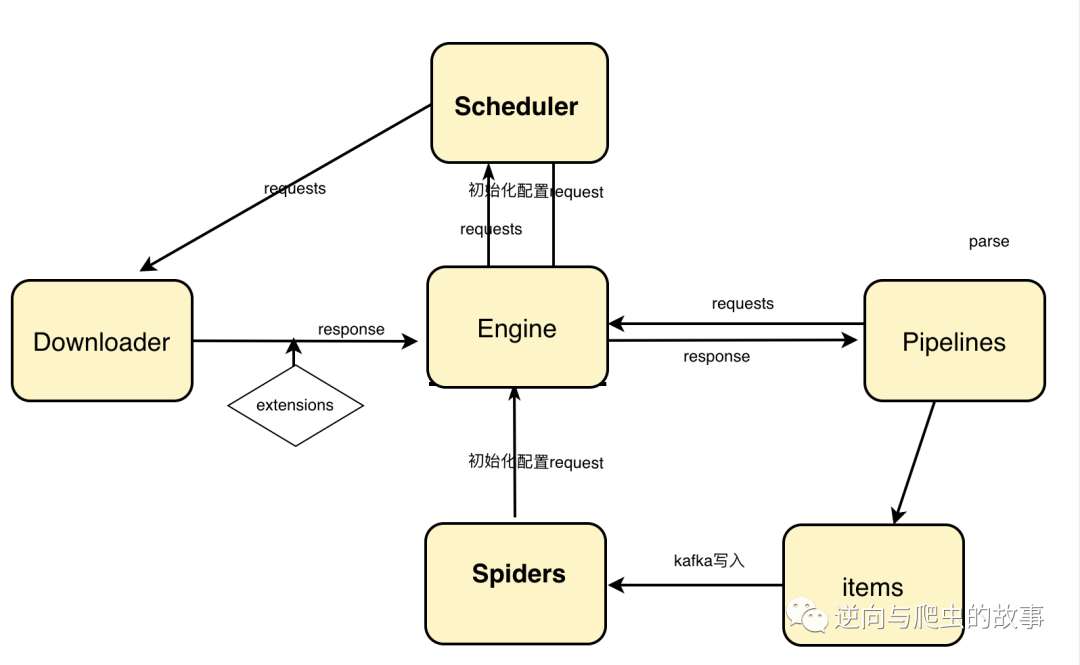
三、源码分享
根据上面的架构图,我们可将框架分为6个组件,分别为:spiders、engine、items、downloader、pipelines、scheduler。下面,我们将从这几个部分逐一讲解collyx的整个源码,同时也将展示一部分extensions源码。完整目录如下:
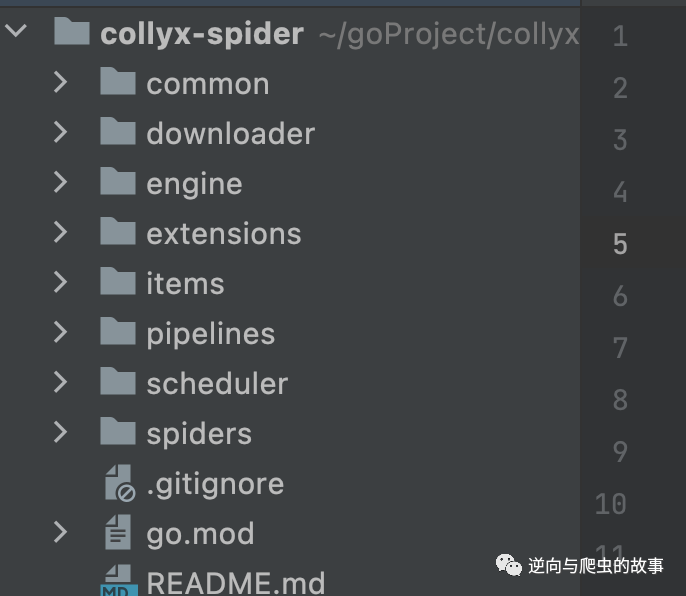
1、spiders模块分享,自定义代码结构,代码如下所示:
// Package spiders ---------------------------
// @author : TheWeiJun
package main
import (
"collyx-spider/common"
"collyx-spider/items/http"
"collyx-spider/pipelines"
"collyx-spider/spiders/crawler"
)
func main() {
request := http.FormRequest{
Url: "https://xxxxx",
Payload: "xxxxx",
Method: "POST",
RedisKey: "ExplainingGoodsChan",
RedisClient: common.LocalRedis,
RedisMethod: "spop",
Process: pipelines.DemoParse,
Topic: "test",
}
crawler.Crawl(&request)
}说明:只需要配置抓取的url、payload、method、redis、kafka等参数即可;如果某些参数不想使用,可以去掉。
2、engine模块源码如下,对colly进行初始化参数配置:
package engine
import (
"collyx-spider/common"
downloader2 "collyx-spider/downloader"
extensions2 "collyx-spider/extensions"
"collyx-spider/items/http"
"collyx-spider/scheduler"
"github.com/gocolly/colly"
"time"
)
var Requests = common.GetDefaultRequests()
var TaskQueue = common.GetDefaultTaskQueue()
var Proxy = common.GetDefaultProxy()
var KeepAlive = common.GetDefaultKeepAlive()
var kafkaStatus = common.GetKafkaDefaultProducer()
var RequestChan = make(chan bool, Requests)
var TaskChan = make(chan interface{}, TaskQueue)
func CollyConnect(request *http.FormRequest) {
var c = colly.NewCollector(
colly.Async(true),
colly.AllowURLRevisit(),
)
c.Limit(&colly.LimitRule{
Parallelism: Requests,
Delay: time.Second * 3,
RandomDelay: time.Second * 5,
})
if Proxy {
extensions2.SetProxy(c, KeepAlive)
}
//if kafkaStatus {
// common.InitDefaultKafkaProducer()
//}
extensions2.URLLengthFilter(c, 10000)
downloader2.ResponseOnError(c, RequestChan)
downloader2.DownloadRetry(c, RequestChan)
request.SetConnect(c)
request.SetTasks(TaskChan)
request.SetRequests(RequestChan)
}
func StartRequests(request *http.FormRequest) {
/*add headers add parse*/
go scheduler.GetTaskChan(request)
if request.Headers != nil {
request.Headers(request.Connect)
} else {
extensions2.GetHeaders(request.Connect)
}
downloader2.Response(request)
}说明:该模块主要是做初始化调度器、请求headers扩展、初始化下载器、初始化colly等操作,是框架运行的重要模块之一。
3、scheduler模块源码展示,完整代码:
package scheduler
import (
"collyx-spider/items/http"
log "github.com/sirupsen/logrus"
"strings"
"time"
)
func GetTaskChan(request *http.FormRequest) {
redisKey := request.RedisKey
redisClient := request.RedisClient
redisMethod := request.RedisMethod
limits := int64(cap(request.TasksChan))
TaskChan := request.TasksChan
methodLowerStr := strings.ToLower(redisMethod)
for {
switch methodLowerStr {
case "do":
result, _ := redisClient.Do("qpop", redisKey, 0, limits).Result()
searchList := result.([]interface{})
if len(searchList) == 0 {
log.Debugf("no task")
time.Sleep(time.Second * 3)
continue
}
for _, task := range searchList {
TaskChan <- task
}
case "spop":
searchList, _ := redisClient.SPopN(redisKey, limits).Result()
if len(searchList) == 0 {
log.Debugf("no task")
time.Sleep(time.Second * 3)
continue
}
for _, task := range searchList {
TaskChan <- task
}
default:
log.Info("Methods are not allowed.....")
}
time.Sleep(time.Second)
}
}说明:这里从spider里的结构体指针取值,获取任务交给TaskChan通道进行任务分发。
4、items模块源码展示
4.1 request_struct.go模块代码如下:
package http
import (
"github.com/go-redis/redis"
"github.com/gocolly/colly"
)
type FormRequest struct {
Url string
Payload string
Method string
RedisKey string
RedisClient *redis.Client
RedisMethod string
GetParamFunc func(*FormRequest)
Connect *colly.Collector
Process func([]byte, string, string) string
RequestChan chan bool
TasksChan chan interface{}
Topic string
Headers func(collector *colly.Collector)
TaskId string
}
func (request *FormRequest) SetRequests(requests chan bool) {
request.RequestChan = requests
}
func (request *FormRequest) SetTasks(tasks chan interface{}) {
request.TasksChan = tasks
}
func (request *FormRequest) SetConnect(conn *colly.Collector) {
request.Connect = conn
}
func (request *FormRequest) SetUrl(url string) {
request.Url = url
}总结:request结构体负责spiders请求自定义,设置初始化请求参数。
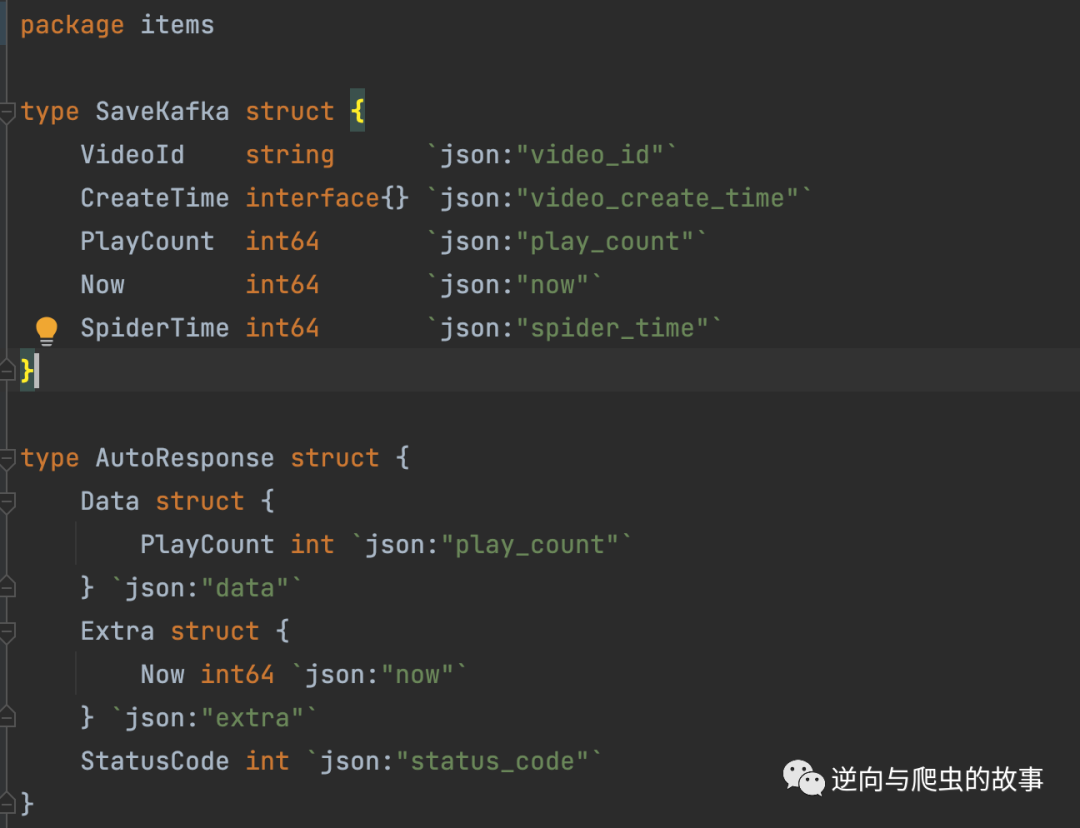
4.2 解析结构体,根据解析内容和保存内容自定义结构体,截图如下:
5、downloader模块分享,目录代码结构如下图所示:
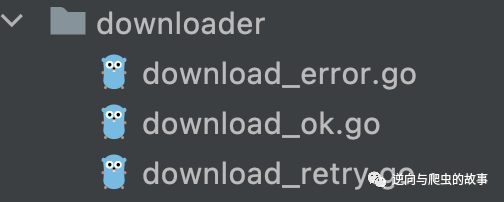
总结:该模块拥有下载成功、下载错误、下载重试三个功能,接来下分享下源代码。
5.1 download_error.go代码如下:
package downloader
import (
"github.com/gocolly/colly"
)
func ResponseOnError(c *colly.Collector, taskLimitChan chan bool) {
c.OnError(func(r *colly.Response, e error) {
defer func() {
<-taskLimitChan
}()
})
c.OnScraped(func(r *colly.Response) {
defer func() {
<-taskLimitChan
}()
})
}模块说明:该模块为捕获错误请求,并及时释放并发通道。
5.2 download_ok.go代码如下:
package downloader
import (
"collyx-spider/common"
"collyx-spider/items/http"
"github.com/gocolly/colly"
)
func Response(request *http.FormRequest) {
c := request.Connect
c.OnResponse(func(response *colly.Response) {
defer common.CatchError()
task := response.Ctx.Get("task")
isNext := request.Process(response.Body, task, request.Topic)
if isNext != "" {
request.RedisClient.SAdd(request.RedisKey, isNext)
}
})
}模块说明:该模块为处理200状态码请求,并将调用spiders提前定义的解析函数进行数据抽取。
5.3 download_rety.go代码如下:
package downloader
import (
"collyx-spider/common"
"github.com/gocolly/colly"
"log"
)
func RetryFunc(c *colly.Collector, request *colly.Response, RequestChan chan bool) {
url := request.Request.URL.String()
body := request.Request.Body
method := request.Request.Method
ctx := request.Request.Ctx
RequestChan <- true
c.Request(method, url, body, ctx, nil)
}
func DownloadRetry(c *colly.Collector, RequestChan chan bool) {
c.OnError(func(request *colly.Response, e error) {
if common.CheckErrorIsBadNetWork(e.Error()) {
taskId := request.Request.Ctx.Get("task")
log.Printf("Start the retry task:%s", taskId)
RetryFunc(c, request, RequestChan)
}
})
}模块说明:通过自定义的错误函数捕获错误类型,并开启重试机制进行重试,弥补了colly请求失败数据缺失问题。
6、pipelines模块分享,完整代码如下:
package pipelines
import (
"collyx-spider/common"
"collyx-spider/items"
"encoding/json"
log "github.com/sirupsen/logrus"
)
func DemoParse(bytes []byte, task, topic string) string {
item := items.Demo{}
json.Unmarshal(bytes, &item)
Promotions := item.Promotions
if Promotions != nil {
data := Promotions[0].BaseInfo.Title
proId := Promotions[0].BaseInfo.PromotionId
common.KafkaDefaultProducer.AsyncSendWithKey(task, topic, data+proId)
log.Println(data, Promotions[0].BaseInfo.PromotionId, topic)
} else {
log.Println(Promotions)
}
return ""
}模块说明:pipelines在框架中职位主要是负责数据解析、数据持久化操作。
7、cralwer模块分享,代码如下:
package crawler
import (
"collyx-spider/common"
"collyx-spider/engine"
"collyx-spider/items/http"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strings"
"time"
)
func MakeRequestFromFunc(request *http.FormRequest) {
for true {
select {
case TaskId := <-request.TasksChan:
ctx := colly.NewContext()
ctx.Put("task", TaskId)
request.TaskId = TaskId.(string)
if request.Method == "POST" {
request.GetParamFunc(request)
if strings.Contains(TaskId.(string), ":") {
split := strings.Split(TaskId.(string), ":")
TaskId = split[0]
data := fmt.Sprintf(request.Payload, TaskId)
ctx.Put("data", data)
request.Connect.Request(request.Method, request.Url, strings.NewReader(data), ctx, nil)
}
request.RequestChan <- true
} else {
if strings.Contains(TaskId.(string), "http") {
request.Url = TaskId.(string)
} else {
request.GetParamFunc(request)
}
request.Connect.Request(request.Method, request.Url, nil, ctx, nil)
request.RequestChan <- true
}
default:
time.Sleep(time.Second * 3)
log.Info("TaskChan not has taskId")
}
}
}
func MakeRequestFromUrl(request *http.FormRequest) {
for true {
select {
case TaskId := <-request.TasksChan:
ctx := colly.NewContext()
ctx.Put("task", TaskId)
if request.Method == "POST" {
payload := strings.NewReader(fmt.Sprintf(request.Payload, TaskId))
request.Connect.Request(request.Method, request.Url, payload, ctx, nil)
} else {
fmt.Println(fmt.Sprintf(request.Url, TaskId))
request.Connect.Request(request.Method, fmt.Sprintf(request.Url, TaskId), nil, ctx, nil)
}
request.RequestChan <- true
default:
time.Sleep(time.Second * 3)
log.Info("TaskChan not has taskId.......")
}
}
}
func RequestFromUrl(request *http.FormRequest) {
if request.GetParamFunc != nil {
MakeRequestFromFunc(request)
} else {
MakeRequestFromUrl(request)
}
}
func Crawl(request *http.FormRequest) {
/*making requests*/
engine.CollyConnect(request)
engine.StartRequests(request)
go RequestFromUrl(request)
common.DumpRealTimeInfo(len(request.RequestChan))
}总结:cralwer模块主要负责engine初始化及engine信号发送,驱动整个爬虫项目运行。
8、extensions模块,代码目录截图如下:

8.1 AddHeaders.go 源码如下:
package extensions
import (
"fmt"
"github.com/gocolly/colly"
"math/rand"
)
var UaGens = []func() string{
genFirefoxUA,
genChromeUA,
}
var ffVersions = []float32{
58.0,
57.0,
56.0,
52.0,
48.0,
40.0,
35.0,
}
var chromeVersions = []string{
"65.0.3325.146",
"64.0.3282.0",
"41.0.2228.0",
"40.0.2214.93",
"37.0.2062.124",
}
var osStrings = []string{
"Macintosh; Intel Mac OS X 10_10",
"Windows NT 10.0",
"Windows NT 5.1",
"Windows NT 6.1; WOW64",
"Windows NT 6.1; Win64; x64",
"X11; Linux x86_64",
}
func genFirefoxUA() string {
version := ffVersions[rand.Intn(len(ffVersions))]
os := osStrings[rand.Intn(len(osStrings))]
return fmt.Sprintf("Mozilla/5.0 (%s; rv:%.1f) Gecko/20100101 Firefox/%.1f", os, version, version)
}
func genChromeUA() string {
version := chromeVersions[rand.Intn(len(chromeVersions))]
os := osStrings[rand.Intn(len(osStrings))]
return fmt.Sprintf("Mozilla/5.0 (%s) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/%s Safari/537.36", os, version)
}
func GetHeaders(c *colly.Collector) {
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", UaGens[rand.Intn(len(UaGens))]())
})
}模块说明:负责更换随机ua,防止spider被网站gank。
8.2 AddProxy.go 源码如下:
package extensions
import (
"collyx-spider/common"
"github.com/gocolly/colly"
"github.com/gocolly/colly/proxy"
)
func SetProxy(c *colly.Collector, KeepAlive bool) {
proxyList := common.RefreshProxies()
if p, err := proxy.RoundRobinProxySwitcher(
proxyList...,
); err == nil {
c.SetProxyFunc(p)
}
}模块说明:该模块主要是给request设置代理,防止出现请求失败等错误。
8.3 URLLengthFilter.go 源码分享:
package extensions
import "github.com/gocolly/colly"
func URLLengthFilter(c *colly.Collector, URLLengthLimit int) {
c.OnRequest(func(r *colly.Request) {
if len(r.URL.String()) > URLLengthLimit {
r.Abort()
}
})
}模块说明:对于url过长请求进行丢弃,Abort在OnRequest回调中取消HTTP请求。源码分享环节到这里就结束了,接下来我们运行代码,展示一下collyx爬虫框架性能吧!
四、框架demo展示
1、启动编辑好的案例代码,运行截图如下:
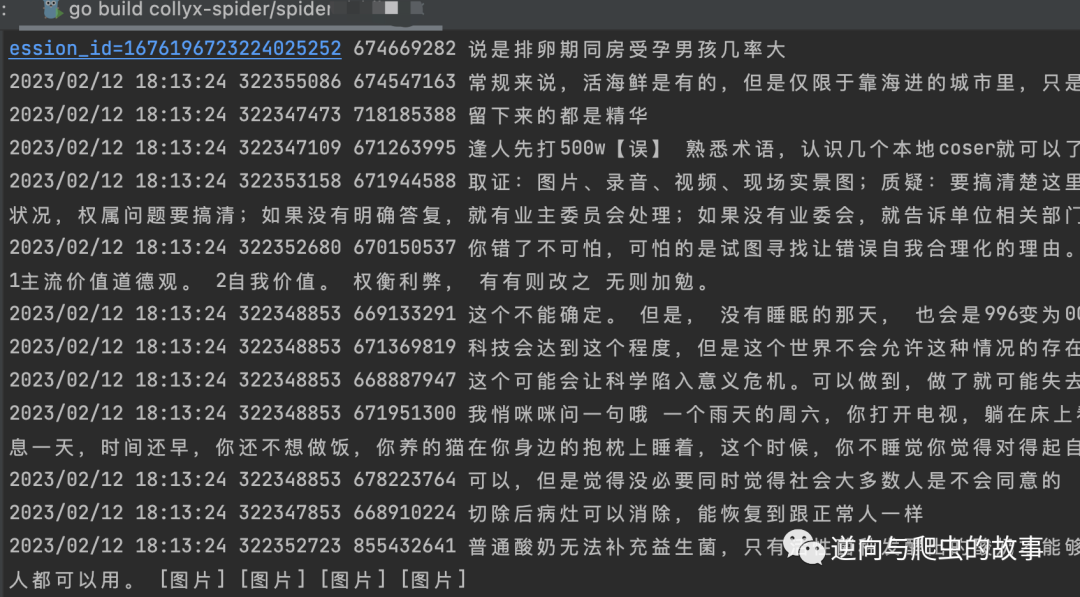
总结:爬虫运行5分钟后,在代理足够充足情况下统计,抓取该网站每分钟约产生2000条数据,可以毫不吹牛的说,这是我迄今为止见过最快的爬虫框架。
五、心得分享
今天分享到这里就结束了,对于collyx框架而言还有很长的路要走。我始终觉得只要努力,我们就会朝着目标一步步去实现。最后,感谢大家耐心阅读本文!
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|














 2382
2382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









