







一、背景
项目中使用的是mongodb数据库,在测试数据入库的时候,会根据源数据,然后生成一个自增的id到数据库里面,然后线上和测试环境针对同一条数据的id是不一致的。某些数据又只有id与线上匹配上的时候,才能关联上更多的数据,因此,我会去写一个脚本将同一条数据,将测试环境的id改成和线上的一致。但可能由于脚本写的还不够完善,导致数据库里面可能会写入一些重复id的记录进去,然后id又没有加唯一索引。有重复的数据又会导致正常执行etl任务会报错,因此,需要查询出在mongodb里面某个字段重复的记录。
二、先来回顾一下mysql中的用法
先来看一下如果是使用mysql的话,大家会怎么样去查询重复的记录呢?
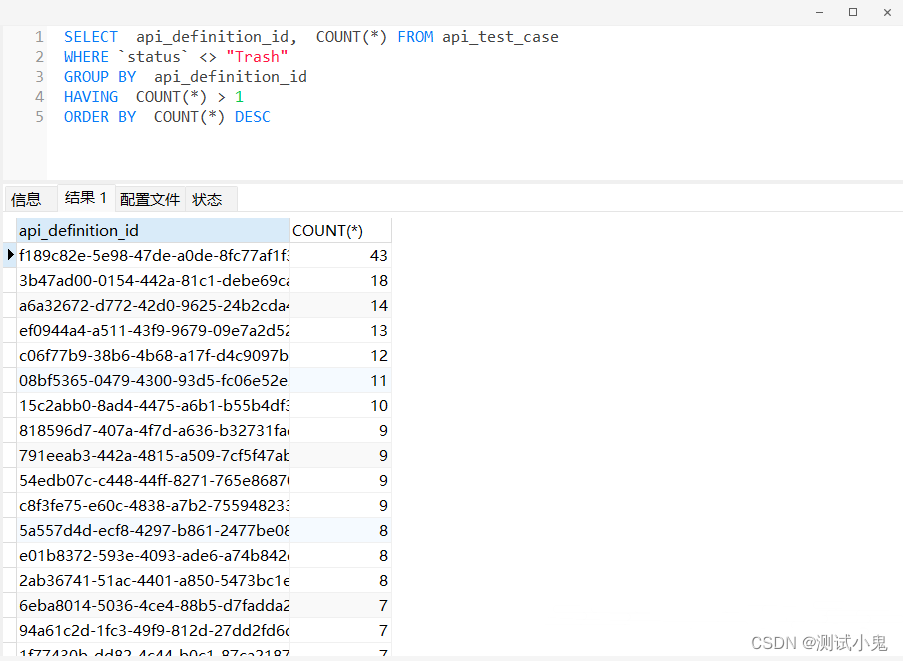
比如,以metersphere平台的数据库为例,想查找出某个接口下写了超过2个有效用例的case,应该怎么查找呢:
SELECT api_definition_id, COUNT(*) FROM api_test_caseWHERE `status` <> "Trash"GROUP BY api_definition_idHAVING COUNT(*) > 1ORDER BY COUNT(*) DESC
查出来的结果如下:
三、mongo中的用法
接下来看一下在mongo中,分组统计与筛选的用法。这里不介绍具体的用法,直接展示查询语句:
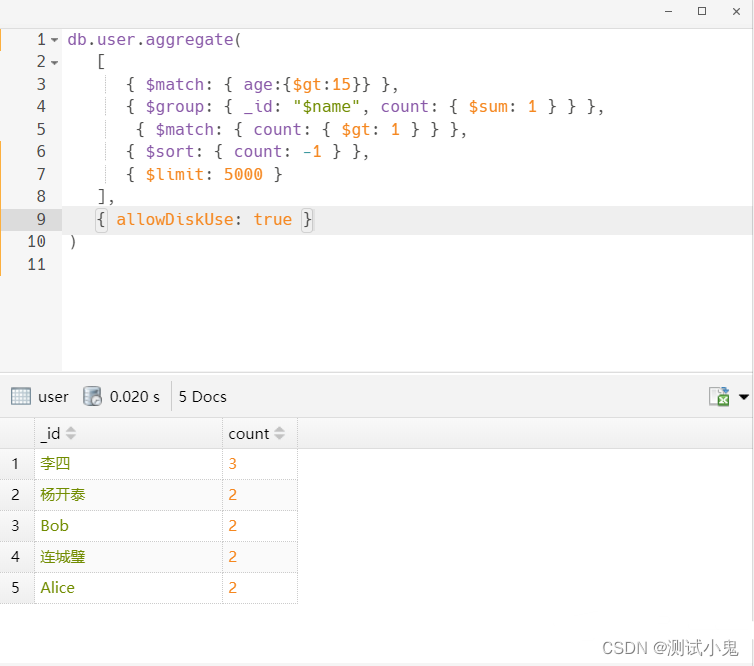
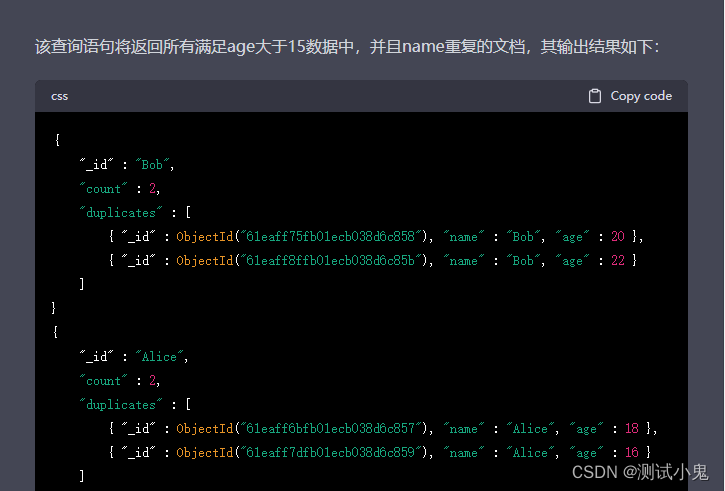
比如查询user表中满足age大于15数据中,并且name重复的记录:
db.user.aggregate(
[
{ $match: { age:{$gt:15}} },
{ $group: { _id: "$name", count: { $sum: 1 } } },
{ $match: { count: { $gt: 1 } } },
{ $sort: { count: -1 } },
{ $limit: 5000 }
],
{ allowDiskUse: true }
)运行结果如下:
注意:
默认情况下,MongoDB 会尝试在内存中完成聚合操作,但是如果数据量很大,内存可能会不足,从而导致聚合操作失败。allowDiskUse选项允许 MongoDB 将中间结果写入磁盘而不是内存,这有助于解决内存不足的问题,并且可以支持处理更大的数据集。需要注意的是,使用磁盘可能会导致聚合操作的速度变慢,因为磁盘通常比内存慢得多。因此,您应该在需要时才使用allowDiskUse选项,以避免不必要的磁盘访问。
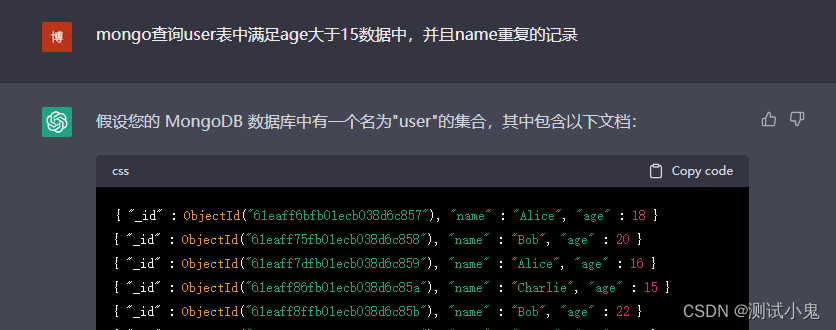
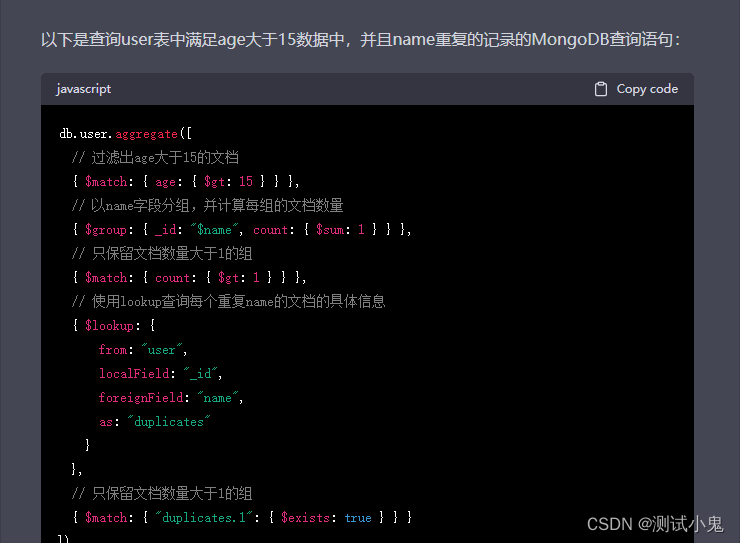
四、chatgpt能帮我们写出来这个语句吗?
在chatpgt还没有出现之前,针对这种复杂的语句,自己要去百度学习他的用法,会稍微有点复杂,也可以使用studio3t的付费版,上面支持直接写mysql语法格式的sql进行查询,也可以帮你转换为mongo的js查询语法的语句。
在chatgp出现之后,现在这些都不是难事了:
B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)
















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









