






描述问题
- 下载超大共享数据。该数据是韩国人通过群晖NAS共享的深度学习数据,数据存储于国外网络,网速受到极大限制;网络波动时出现下载失败,需要重新下载,因为文件本身很大,导致所有文件均无法下载成功。如图所示:
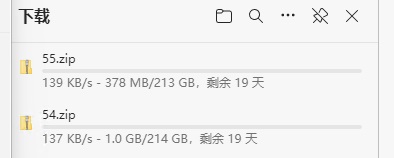
- 下载图片/文本文件。这些数据包含网站上的图片和文本,以及相对较小的说明文档和电子书等各种小文件;下载此类文件时往往出现带宽够用,但是很难充分利用带宽资源;典型的例子是百度网盘客户端,最多仅支持5个并发,带宽利用率非常低。
提出疑问
- 文件大小对下载速度有多大影响?
- 提高并发对下载速度有多大影响?
- 网络传输数据是否存直最优大小?
设计实验
测试环境
- 服务端: 2核 2.60GHz 4GB
- 客户端: 4核 2.60GHz 8GB
生成数据
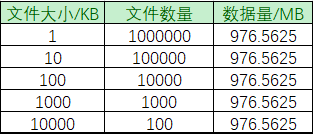
- 生成多个数据总量相同的文件组,用于模拟传输相同的数据总量;
- 文件组内的文件大小相同,用于统计该大小文件的平均传输速度;
基于上述两点考虑,生成5组数据:
搭建环境
- 安装nginx服务,相关命令如下:
# 安装
sudo apt install nginx
# 启动
sudo service nginx start
# 配置
vim /etc/nginx/nginx.conf
# 重启
sudo service nginx restart
- 配置静态资源路径,新增配置如下:
# vim /etc/nginx/sites-available/default
server{
# ...
location /files/ {
root /data/nginx/www/;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
charset utf-8;
}
# ...
}
- 重新加载配置
sudo service nginx reload
- 将生成数据存放到资源目录,目录结构如下:
root@ubuntu:/data/nginx/www/files# ll
total 31408
drwxr-xr-x 7 root root 4096 Sep 11 19:54 ./
drwxr-xr-x 3 root root 4096 Sep 11 19:52 ../
drwxr-xr-x 2 root root 29020160 Sep 11 19:54 1/
drwxr-xr-x 2 root root 2859008 Sep 11 19:54 10/
drwxr-xr-x 2 root root 241664 Sep 11 19:54 100/
drwxr-xr-x 2 root root 28672 Sep 11 19:54 1000/
drwxr-xr-x 2 root root 4096 Sep 11 19:54 10000/
开发程序
程序开启1/2/4/8个进程,从1/10/100/1000/10000目录下载1KB/10KB/100KB/1000KB/10000KB大小的文件,记录不同组合的耗时,代码核心逻辑如下:
def download(urls, session):
status = 0
try:
for url in urls:
response = session.get(url=url)
if response.status_code != 200:
status = -1
else:
data = BytesIO(response.content)
pass
except Exception:
log.error(traceback.format_exc())
status = -1
return status
if __name__ == '__main__':
# 复用会话
sessions = [requests.Session() for concurrency in range(8)]
# 循环配置进程数
for process_number in [1, 2, 4, 8]:
for size in [1, 10, 100, 1000, 10000]:
pool = multiprocessing.Pool(process_number)
# ...
parameter = [[] for concurrency in range(process_number)]
for number in range(int(1000000 / size)):
parameter[number % process_number].append('http://192.168.0.102:80/files/{}/{}.txt'.format(size, number + 1))
# 开启多进程执行
for index in range(process_number):
result = pool.apply_async(func=download, args=(parameter[index], sessions[index],))
pool.close()
pool.join()
# ...
pass
pass
sys.exit(0)
注意:下载采用内存读写的方式获取数据,数据并未写入本地磁盘;
分析结果
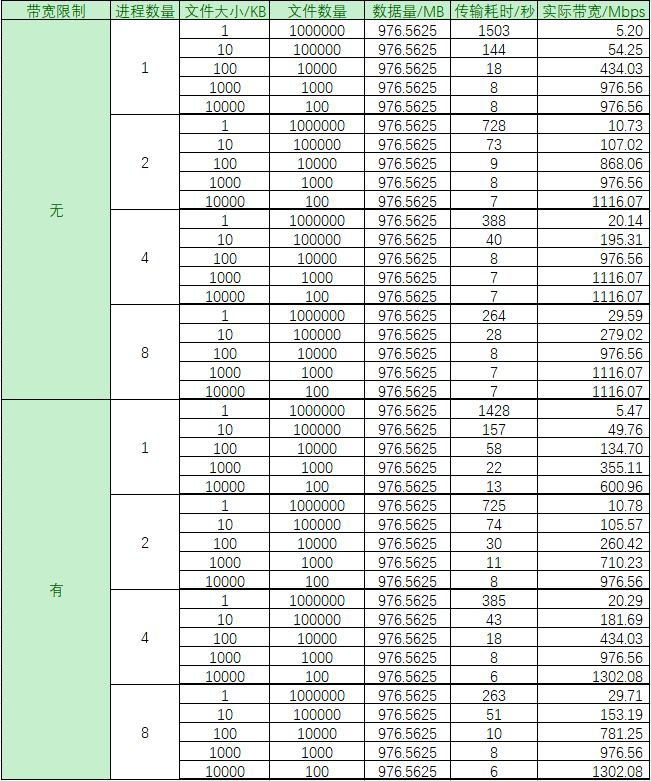
测试数据
测试过程
- 带宽限制:服务部署在华为云服务器上,该款服务器宣称最大带宽1Gbps,本次测试分为不限制带宽,和限制100Mbps带宽*;
- 进程数量:测试程序开启的进程数;
- 文件大小:单个文件大小;
- 文件数量:该大小的文件数量;
- 数据量:该大小文件总数据量;
- 传输耗时:下载该大小的所有文件的耗时;
- 实际带宽:使用数据量/传输耗时得到实际平均带宽;
注意:
# 测试中以下命令限制100Mbps带宽,该限制对实际带宽有影响,但并非将带宽限制在设置的值以内;
>> sudo wondershaper ens3 102400 102400
为了精确限制带宽,随后做了以下测试:
>> sudo wondershaper ens3 20480 20480 # 限制20Mbps带宽,实际带宽在40-50Mbps之间;
>> sudo wondershaper ens3 40960 40960 # 限制40Mbps带宽,实际带宽在300-350Mbps之间;
无法找到其规律,故该测试不再精确限制带宽。
测试分析
- 带宽是不是瓶颈时,文件下载速度随着进程数翻倍而翻倍,当开启的进程数超过CPU核心数时,速度提升不明显;
- 带宽是不是瓶颈时,文件下载速度与文件大小成正比,在测试数据表格中比例甚至可以达到1:1;
- 带宽1Gbps时,文件超过1MB才能更充分的利用带宽;
结论
解答疑问
- 带宽不是瓶颈时,文件大小对传输速度的影响与带宽有关,小文件传输速度比大文件低很多;
- 带宽不是瓶颈时,提高并发可以提高下载速度,并发数低于CPU核心数时尤为明显;
- 网络传输数据的最优大小与网络带宽有关,后面我们会分析;
推测数据
下图是理论上不同文件大小在不同带宽下传输耗时(秒):
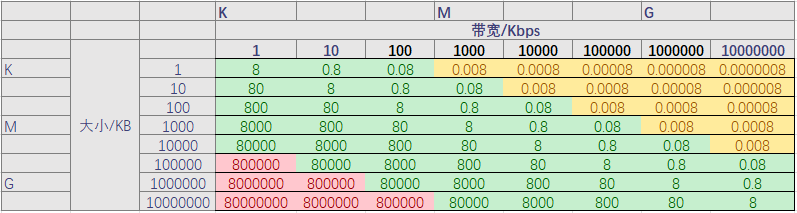
表格中填充红色的区域表示时间过长;填充黄色的区域表示带宽利用率偏低;填充绿色的区域表示耗时与带宽利用率可以接受,越靠近红色区域时间越长,越靠近黄色区域带宽利用率越低。
注:1天=86400秒;机械硬盘读写速度400-600Mbps;固态硬盘读写速度1-4Gbps;
最优选择
我们选择最合适的文件大小时,需要结合数据、环境和趋势,综合分析来做出决定;
- 一般情况下,建立网络连接是毫秒级别的,传输数据时尽量减少其时长占比,切分文件时尽量保证单次数据传输在秒级别;
- 特殊情况下,跨国传输数据时带宽受限,传输数据时考虑网络波动,耗时不能太长,尽量不要超过1天;
- 当前国内普通网络带宽在100-1000Mbps,网盘带宽在100Kbps以上,国外网络带宽大多在1Mbps以上;
- 国内正在普及1000Mbps网络,未来可能普及10000Mbps网络;
综合以上分析,结合表格,当前最合适的文件大小为100MB-1GB左右,个人更推荐1GB,理由如下:
- 家庭内网下:能在8秒钟完成数据传输;
- 普通带宽下:能在1分钟完成数据传输;
- 国外网络下:能在2小时完成数据传输;
- 网盘环境下:能在1天内完成数据传输;
- 未来网络下:能在1秒钟完成数据传输;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









