






首先让我们依然从一开始的putVal方法讲起
(建议看过上篇对于Java集合框架的整理与理解(Hashmap底层源码解析:添加数据篇(红黑树在下篇))再看这篇。)
这里推荐个红黑树可视化的网址
红黑树可视化
源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
书接上文,从我们上次跳过的内容讲起
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
其中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
这一行本文后面再提,这是已经转化成红黑树了
因此,我们从阙值开始讲
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
进入这个else,可以发现初始就是一个for循环
一路遍历,首先就是第一个if
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
可以看出先是将p的下一个结点赋值给e,然后判断e是否为空,很好理解,如果这个链表后面指向空,那么这个链表就到头了。
因此,这个if意思就是让你到了链表尽头,咱再进行判定
现在因为要转红黑树了,所以假设现在已经遍历到尽头了
先是将新建了个结点,然后将p结点指向它,然后这个新结点的下一个结点指向null
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
TREEIFY_THRESHOLD 之前有提到过,
树型阙值,默认为8
但是注意这一段for
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
可以看到,binCount这段是从0开始
然后需要binCount大于等于7,实际上binCount现在看上去是七
但由于它是从0开始计数,因此实际上它代表的链表长度为8,
这样看上去为8好像正等于阙值,为啥要进入树化?
注意for循环上一句
p.next = newNode(hash, key, value, null);
这里新建了一个结点,并将p结点和它连接上了
因此,当前链表的真正长度为9,大于链表高度阙值8
因此,进入树化方法treeifyBin
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
首先依然是定义几个变量
然后进入判断,如果tab等于空数组,或者数组的长度小于MIN_TREEIFY_CAPACITY也就是定义好的最小树容量,64,刚开始是链表大于8进入这个方法,然后同时需要数组长度大于64,
才将其转换为树,如果不满足条件,就进行扩容resize();方法
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
现在由于不满足,所以要进行树化的第一步了
e = tab[index = (n - 1) & hash]) != null
判断很熟悉是吧
依然是根据hash值计算出应该存放的数组位置
TreeNode<K,V> hd = null, tl = null;
这里依然是先看看树结点的定义
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
父节点,左结点,右结点,上结点,以及默认为红色
构造方法也很简单,可以理解为继承了单向链表,所以构造方法与node是一样的
然后将树的头结点和尾结点先定义好
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
进入do while循环
首先是将一开始的单向链表的结点转换为了树结点
通过方法replacementTreeNode,也就是将单向链表转换为树结点的方法
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
当然这个方法也很简单
输入一个结点,然后将这个结点的hash值,key,value转换为树结点的参数,next也就是下一个结点默认为空
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
转换完后,如果tl等于空,尾结点为空,意味着什么都没有,
因此将头节点设置为当前的p
并将尾结点也设置为当前的p(只有一个结点时,头尾结点相同
接着由于就是将e的下一个结点赋值给e,如果不为空,就继续判断
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
依然是将e转化为p
这时因为尾结点不为空,
因此进入else
将p的前一个结点指向tl也就是原来的尾结点
并将尾结点的下一个结点指向现在的p
然后依然是将尾结点设置成当前的结点。
与此循环反复,直至将这个链表给遍历完
进入下一步
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
最后一步
if ((tab[index] = hd) != null)
hd.treeify(tab);
hd是头结点,index是刚刚计算好了的根据hash值应该存放的位置
如果不等于空,就使用treeify方法继续树化
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
Forms tree of the nodes linked from this node.
这个treeify方法的注释是这样的,意思就是从这个结点开始,形成一个树
从哪个结点开始,自然是上个方法的hd头结点了
TreeNode<K,V> root = null;
一开始的root熟悉把?根节点的意思,刚开始树化,因此root当然为空
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
进入长长的for
先看循环条件
for (TreeNode<K,V> x = this, next; x != null; x = next)
初始化,this的意思就是刚开始传入的hd结点,next和x同样属于树结点
如果x不为空就继续遍历,每次遍历都让x等于next
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
先分段来讲,next就等于x的下一个结点,这个没啥问题
x的左节点右结点全部没得,所以是空
然后便是第一次虚拟换,当前肯定root根节点是空的,因此准备将x变成根结点
x的父结点为空,根节点就是最上面的,当然没有
x.red = false,不是红色,那不就黑色吗,红黑树
root结点为x
现在第一次循环过了
第二次
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
依然是
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
然后这次有根结点了,所以进入else
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
依然是变量初始化
K k = x.key;
int h = x.hash;
Class<?> kc = null;
k是x的key,x是x的hash值,kc是空的,也不确定是哪个类
初始化后就进入else里面的for循环
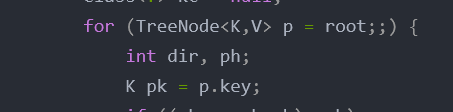
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
这次for循环的条件就一个了
for (TreeNode<K,V> p = root;;)
从root结点开始,p=root
int dir, ph;
K pk = p.key;
变量含义等赋值的时候在和你们说
pk就是p的key
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
进入判断,第一个,ph是p的hash值还记得把
h是啥还记得吗
现在是第二次循环,h是root的下一个结点x的hash值
接着进行对比
如果上一个结点的hash大于当前结点x的hash,
就赋值dir=-1,现在应该知道dir是啥了把
位置嘛
如果上一个结点的hash大于当前结点的hash,就把当前结点放在左边,也就是-1
否则就是1,放在右边
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
接着这句话啥意思呢
其实就是不死心,继续比。总得给人个位置不是
kc==null,这是肯定的
kc = comparableClassFor(k))
这个方法不是重点,就先看看注释就行
Returns x’s Class if it is of the form "class C implements Comparable ", else null.
翻译过来就是
如果传入的变量的类实现了 Comparable这个接口,就告诉你他是啥类,如果没实现,就返回null
k是当前结点x的key值
接着看一下compareComparables方法
依然看下注释就行
Returns k.compareTo(x) if x matches kc (k’s screened comparable class), else 0.
dir = compareComparables(kc, k, pk)
其实也简单,如果当前结点和上一个结点是可比较的,就将其进行比较
传入的kc是k的类,如果不可比较,就返回0
按理来说这么多次判断总该不等于吧,但是恰巧又等于了
那就进行最后的比较
dir = tieBreakOrder(k, pk);
这个方法就狠了,你不管咋样,不给你为0,要么-1,要么1
不然不行啊,红黑树要么在左要么在右,相等没法子放
具体咋实现的呢
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
接下来进行判断
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
.getClass().getName()这个方法返回啥呢,其实就是返回
String a = "1";
System.out.println(a.getClass().getName());
返回

可以看出来,这个方法返回的是一个类名
d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0
再将俩个类名赋值给d,如果d还是等于0
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
那就调用System的identityHashCode方法继续生成一个hash值进行比较,不同的是可以发现
小于等于也返回-1,也就是在左边。
获得当前结点在前一个结点的左边还是右边后
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
回到这里
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
先将前一个结点p保存为xp
TreeNode<K,V> xp = p;
开始判断
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
dir小于0,就让前一个结点p=p的左边,否则就是p的右边
如果定位后的值为空
(p = (dir <= 0) ? p.left : p.right) == null
就进入判断
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
令x也就是当前结点的父节点等于前一个结点xp
如果位置dir小于0,前一个结点xp的右孩子为当前结点
否则就相反,
接着便要执行balanceInsertion的方法了,该方法把根结点和当前结点x传入
用以判断是否满足红黑树的条件:
- 性质1. 结点是红色或黑色。
- 性质2. 根结点是黑色。
- 性质3. 所有叶子都是黑色。(叶子是NIL结点)
- 性质4. 每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
- 性质5. 从任一节结点其每个叶子的所有路径都包含相同数目的黑色结点。
这样看着挺复杂,不过慢慢来就行
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
首先是将传入的x,也就是当前结点x的颜色默认设置为红色,也就是true
进入超长的for循环
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
刚开始依然是先初始化
for (TreeNode<K,V> xp, xpp, xppl, xppr;;)
这几个变量名具体意义等会在说
第一个判断,刚刚初始化的xp,让他先等于当前结点x的父结点,如果为空
意思就是没有父结点,就把当前结点的颜色改成黑色,因为他是父节点,然后返回结点x。
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
第二步,如果不是当前结点不是父结点就要进入这个了
如果xp现在是当前结点x的父结点要记住,
令xpp等于xp的父结点
也就是还记得传入的俩个参数嘛
一个是root,一个是x
其中root是前一个结点,x是当前结点
令xpp等于xp,
xp是当前结点的前一个结点,其实也就是等于root
因此令xpp等于前一个结点root的父结点,
如果为空,证明root结点时父结点,因此直接返回root就行
else if (!xp.red || (xpp = xp.parent) == null)
return root;
接着
xpp等于前一个结点root的父结点现在
如果前前个结点xpp的左边正好就是xp,也就是当前结点
听着有点拗口,我把图给大家看就知道了

后面如果不记得了可以上来看一眼
先让xppl等于xpp的左孩子
如果xp正好是xpp的左孩子
进入比较长的if
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
接着往下走
如果xppr也就是xpp结点的右孩子,不等于空,并且xppr是红色的
令xppr变黑,令xp变黑,同时,让xpp变红
因为所有红色结点的娃子都是黑色,所以让xppr和xp变黑
现在让当前结点变成x
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
令当前结点直接等于他的前前个结点xpp
因为是靠当前结点进行遍历的,因此这一步后就返回到for进行下一步遍历,当然,我们接着讲如果不满足这个条件进入else
if语句是
(xppr = xpp.right) != null && xppr.red
自然,else语句就是xppr==null,或者xppr颜色为false也就是黑
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
第一个if
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
如果x结点正好是xp结点的右结点,
然后就要蛋疼的又要进入另一个方法了
准备进行左旋!
为啥进行左旋
注意,当前红黑树为
 这个样子,很明显,都是右节点,红黑树是自平衡的,这样子就不平衡了,他就得动一动
这个样子,很明显,都是右节点,红黑树是自平衡的,这样子就不平衡了,他就得动一动
因此进行左旋
左旋的意思其实就是,
例如
 现在这课树不平衡了,那么怎么样才能平衡?
现在这课树不平衡了,那么怎么样才能平衡?
可以看到,其实也很简单,将xpp变成xp结点的左节点就可以了呀
挪完之后

又是个完美的红黑树
注意,只需要挪这三个就行,并不是进行整体的左旋,而是部分的左旋
突然想起来刚开始推荐的网站,让我们用网站来试试就知道了
 很明显,这棵树不平衡,那么如何让他变得平衡
很明显,这棵树不平衡,那么如何让他变得平衡
左旋即可

这是红黑树的重要部分,红黑树为啥能一直平衡,就是靠动来动去
本文篇幅有些长,因此左旋右旋图示,具体实现留给下一篇
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
因此,可以看到,这里主要其实就是进行红黑树的左旋及右旋操作,具体代码留给下篇
回到balanceInsertion方法中的else中,
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {就这个就这个
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
就这个
注意,前一个if条件在这给出
xp == (xppl = xpp.left)
既然是else,肯定就不满足条件,因此记住
现在xp是xppr,也就是xpp的右孩子
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
其实操作也大同小异
依然是如果
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
xpp左孩子不为空,并且xppl的颜色为红,就进行改色操作
改完颜色和上面一样,接着循环
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
这里就是红黑树进行改色
以及进行右旋,上面已经说过左旋,右旋大同小异,因此不再赘述
于是我们回到treeify方法中
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);从这一步出来了终于
break;
}
}
}
}
moveRootToFront(tab, root);
}
令root等于root = balanceInsertion(root, x);
也就是平衡完成后,结束当前循环
结束这个循环
继续从

第一个循环这里继续遍历,操作依然类似,就不细说了
进入treeify的最后一个方法
moveRootToFront(tab, root);
顾名思义,就是将根向前移动
因为Hashmap底层是数组+链表+红黑树
现在因为数组中有一个下标的链表超过了链表长度阙值
例如数组tab的第5个数据tab[4],本身存放的是链表,现在链表变成了红黑树
要保证红黑树效率,肯定要让tab[4]存放的是红黑树的首结点。
这个方法就是做这件事
看注释 Ensures that the given root is the first node of its bin.
就是我上面说的那句话
具体如何做到呢
首先定义了n
/**
* Ensures that the given root is the first node of its bin.
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
从第一个判断开始讲起
首先根节点得存在,首先数组也得先存在,并且赋值n=数组的长度并大于0才进入判断
这都是比较常见的了
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
进入循环后,index下标,靠根节点进行计算
令树结点first 等于数组[下标]的结点
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
如果根结点等于数组下标的结点了,那正好就可以了,不需要别的操作
如果不等于,就进入判断
让tab[index] = root; rp等于根节点root的前一个结点
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
接着挨个进行判断
如果rn,也就是root的下一个结点不为空
先转换rn为树结点,并使他的前一个结点变为root的前一个结点(也就是让他的下一个结点变成前一个结点)
第二个if
如果rp,也就是root结点的前一个结点不为null,就将rp的下一个结点变成rn(也就是将他的下一个结点和前一个结点连接起来)
第一步和第二步其实可以看出来是对称的
第三个就是如果当前tab[index]存放的结点不为空,就让这个结点的前一个结点变为root
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
最后进行俩步,
将root的下一个结点指向原本的首结点first
将root的前一个结点置空
root.next = first;
root.prev = null;
这样就达成了将tab[index]结点更新成了树节点的根节点root。
最后的断言assert
可以不用管,java的断言默认是关闭的
一般用于开发或者测试。
assert checkInvariants(root);
结论
到这里,链表转换红黑树就告一段落了,可以看到,红黑树的结构还是挺有意思的。当然,这只是个人理解,如有错误,可以指出来我进行改正。














 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









