







 本文深入探讨了embedding技术在处理离散变量中的应用,如何通过低维向量捕捉词汇或物体的语义关系。同时,介绍了ResNet残差网络如何解决深度学习中的梯度消失问题,以及长时记忆在网络中的重要性。此外,还讨论了Inceptions网络的视野和上下文信息处理能力,并提到了双线性插值、同位元素相乘等技术在神经网络中的作用。最后,文章通过ablation实验展示了关键组件的影响,并提及了IoU在目标检测中的角色。
本文深入探讨了embedding技术在处理离散变量中的应用,如何通过低维向量捕捉词汇或物体的语义关系。同时,介绍了ResNet残差网络如何解决深度学习中的梯度消失问题,以及长时记忆在网络中的重要性。此外,还讨论了Inceptions网络的视野和上下文信息处理能力,并提到了双线性插值、同位元素相乘等技术在神经网络中的作用。最后,文章通过ablation实验展示了关键组件的影响,并提及了IoU在目标检测中的角色。
- embeddings:embedding就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的物体有相近的含义。在深度学习中是指将离散变量转变为连续向量的方式。
- heterogeneous,异类,指与当前已存在的方法不同,褒义
- proposed:在论文中就是只,本文的,也就是作者提出的想法
- overhead:本意翻译为开销,可以指代额外资源或配置手段
- residual network:ResNet,残差网络,由大神何凯明提出的一种经典神经网络架构
- baselines:基线,指评判标准,在实验中用于对比。
- demonstrate:演示,证明,表明
- long-range dependency:长时记忆,指神经网络训练的结果可以被神经网络记住,在后续实验中使用。
维基百科解释:
also called long memory or long-range persistence, is a phenomenon that may arise in the analysis of spatial or time series data. It relates to the rate of decay of statistical dependence of two points with increasing time interval or spatial distance between the points. A phenomenon is usually considered to have long-range dependence if the dependence decays more slowly than an exponential decay,
翻译:也称为长期记忆或长期持久性,是一种在空间或时间序列数据分析中可能出现的现象。它与两个点的统计相关性随时间间隔的增加或两个点之间的空间距离的衰减率有关。如果现象的衰减比指数衰减(通常是幂次衰减)慢,则通常认为该现象具有远距离依赖性。LRD通常与自相似过程或领域相关
- Inceptions:一种神经网络,通常是一个系列(V1-V4)
- 10上下文信息(contextual information):神经网络的特定结构和激发状态代表知识。网络中每一个神经元都受网络中所有其他神经元全局活动的潜在影响。因此,神经网络将很自然地能够处理上下文信息。 也就是说神经网络可以很好的处理此神经元与前一个和后一个神经元的信息。
- fields-of-view:视野
维基百科解释:
In machine vision the lens focal length and image sensor size sets up the fixed relationship between the field of view and the working distance. Field of view is the area of the inspection captured on the camera’s imager. The size of the field of view and the size of the camera’s imager directly affect the image resolution (one determining factor in accuracy). Working distance is the distance between the back of the lens and the target object.
翻译:在机器视觉中,镜头焦距和图像传感器尺寸会在视野和工作距离之间建立固定的关系。视场是在相机的成像器上捕获的检查区域。视场的大小和相机成像器的大小直接影响图像分辨率(精度的一个决定因素)。工作距离是镜头背面与目标物体之间的距离。
-
bilinear interpolation:双线性插值
-
element-wise multiplication:同位元素相乘,
例如:
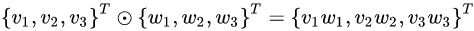
-
sigmoid:激活函数,用于将数值归一到(0,1)之间,也叫归一
-
residuals:残差,大体上说,残差就是结果的误差。举个栗子:有一个函数 f(x) = b.我们想求得其中的 x的值。 现在有一
个x的近似值x0,
那么:
残差(residuals) = f(x0) - b.
误差(error) = x - x0
当然很多情况下,我们只有x的近似值x0,所以残差是可以求得的,但是误差不能。 -
Hyper parameters: 根据经验进行设定,影响到权重和偏置的大小,比如迭代次数、隐藏层的层数、每层神经元的个
数、学习速率等 -
ablation experiments:消融实验。比如你弄了个目标检测的pipeline用了A, B, C,然后效果还不错,但你并不知道A, B, C各自到底起了多大的作用,可能B效率很低同时精度很好,也可能A和B彼此相互促进。Ablation experiment就是用来告诉你或者读者整个流程里面的关键部分到底起了多大作用,就像Ross将RPN换成SS进行对比实验,以及与不共享主干网络进行对比,就是为了给读者更直观的数据来说明算法的有效性,或者称为控制变量法?
-
IoU:交互比,“预测的边框” 和 “真实的边框” 的交集和并集的比值
-
backblone:backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。在神经网络中,尤其是CV领域,一般先对图像 进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图 像特征去做文章(比如分类,生成等等)。所以将这一部分网络结构称为backbone十分形象,仿佛是一个人站起来的支柱。
-
Bottleneck层:Bottleneck layer又称之为瓶颈层,使用的是1*1的卷积神经网络。之所以称之为瓶颈层,是因为长得比较像一个瓶颈。Bottleneck layer这种结构比较常见的出现地方就是ResNet网络。作用是很容易改变维度,灵活设计网络,减少计算量。
-
vanilla Conv layer:vanilla本意指香草,指的是原味的,一般论文中译为原始的,普通的,一般的,此处也就是指,普通的卷积层
-
fine-tuning:在实践中,由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做特征提取器。
-
patch-level:patch指的是CNN中图片的某一小块,patch-level则表示是针对CNN图片分成一个个小块进行关注,而不是针对整个图片。
-
RoI:在图像处理中,我们给定一张图片需要中出所有的物体所在的位置,这一阶段输出的是所有物体的可能的输出位置Bounding box,此区域就称之为region proposals或者 regions of interest(ROI),在这一过程中用到的方法是基于滑窗的方式和selective search。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









