






在資料表使用 DML 資料操縱語言 - 進階 (續)
使用 OUTPUT 子句處理異動資料
-
有時候必須在 DML 期間,針對每一筆影響的資料列,額外再進行其它的作業,例如:
- 只用來顯示異動前後的資料
- 存入到自訂的異動追蹤資料表
- 比對異動的資料是否符合需求
- 這些結果可以傳回給負責處理的應用程式,以便用在確認訊息、封存或其他這類應用程式需求等用途上,這些結果也可以插入資料表或資料表變數中
-
T-SQL 提供 OUTPUT 子句,可從 INSERT、UPDATE、DELETE 或 MERGE 所影響的每個資料列傳回資訊。學習者就當作有一個 SELECT 或 SELECT…INTO…寫在上述陳述式中,只是將 SELECT 關鍵字改為 OUTPUT 而已。
- 陳述式執行期間,所有受影響的資料列會暫時保留在 INSERTED 或 DELETED 兩個快照的虛擬資料表副本中
注意事項:
inserted 資料表會儲存被 INSERT 及 UPDATE 陳述式影響的資料列副本
deleted 資料表會儲存被 DELETE 及 UPDATE 陳述式影響的資料列副本
UPDATE 就像是刪除後再插入的動作;首先,舊資料列被複製到 deleted 資料表,接著將新資料列再複製到資料表以及 inserted 資料表
inserted 和 deleted 資料表可使用的環境有:
DML 的 OUTPUT 子句
觸發程序 (後續會說明)
-
陳述式執行結束或交易結束,兩個快照的虛擬資料表副本也會同時移除
-
兩個快照虛擬資料表 (暫時保留) 的內容如下:(和目標資料表綱要結構相同)
| DML 作業 | INSERTED | DELETED |
|---|---|---|
| INSERT | 保留 INSERT 後的新記錄 | |
| UPDATE | 保留 UPDATE 後的新記錄 | 保留 UPDATE 前的舊記錄 |
| DELETE | 保留 DELETE 前的舊記錄 | |
| MERGE | 保留 INSERT / UPDATE 後的新記錄 | 保留 UPDATE / DELETE 前的舊記錄 |
 |
- 若要從 OUTPUT 子句中,取得那些暫時保留的欄位資料時,必須在那些欄位名稱的前面加上 INSERTED 或 DELETED 前置詞,例如:inserted.empid 或 deleted.empid
SELECT + INTO vs. OUTPUT + INTO
- SELECT + INTO 會自動建立資料表
- OUTPUT + INTO 不會自動建立資料表,所以資料表必須事先定義好 (CREATE TABLE),可用來保存每一次 DML 作業的歷程記錄
- OUTPUT 若沒有指定 INTO,可將結果集資料輸出 (傳回給呼叫端程式),這點和 SELECT 相同
- 若要保存這些異動前後的記錄,必須事先建立資料表,可依照異動追蹤的需求來設計此資料表欄位結構,這個資料表可以是:
- 標準資料表 (使用者自訂資料表)
- 暫存資料表:要注意中斷連線時會自動刪除
- 資料表變數:要注意指令結束即釋放變數
基本語法:
- INSERT + OUTPUT 基本語法:
INSERT [INTO] 資料表名稱 [(欄名1, 欄名2, ... , 欄名n)]
[OUTPUT INSERTED.* [INTO 資料表]]
VALUES (欄值1, 欄值2, ..., 欄值n);
- UPDATE + OUTPUT 基本語法:
UPDATE 資料表名稱
SET 欄名1 = 欄值1,
[欄名2 = 欄值2,
...
欄名n = 欄值n]
[OUTPUT INSERTED.*, DELETED.* [INTO 資料表]]
[WHERE 篩選條件];
- DELETE + OUTPUT 基本語法:
DELETE 資料表名稱
[OUTPUT DELETED.* [INTO 資料表]]
[WHERE 篩選條件];
- MERGE + OUTPUT + $action 基本語法:
MERGE [INTO] 目的資料表名稱 [ AS 資料表別名 ]
USING 來源資料表名稱 [ AS 資料表別名 ]
ON 搜尋條件
[ WHEN MATCHED [ AND 搜尋條件 ] THEN
{ UPDATE | DELETE } ]
[ WHEN NOT MATCHED [BY TARGET] [ AND 搜尋條件 ] THEN
{ INSERT } ]
[ WHEN NOT MATCHED BY SOURCE [ AND 搜尋條件 ] THEN
{ UPDATE | DELETE } ]
[ OUTPUT $action, INSERTED.*, DELETED.* [INTO 資料表] ]
;
注意事項:
$action 是 nvarchar(10) 類型的資料行
$action 會針對當時對每個資料列的影響作業,傳回以下 3 個值之一:
‘INSERT’
‘UPDATE’
‘DELETE’
Demonstration:DML 作業 + OUTPUT
- 範例 A: 此範例會將兩個原始資料表的某些資料列,搬移到另外兩個副本資料表,再透過兩種大量插入資料列的方式,再將這些資料列搬回來到原始資料表 (只為說明如何搭配 INSERT + SELECT 和 INSERT + PROCEDURE 的使用,無合理的使用情境)
- 使用 SELECT … INTO … 新增「新產品資料表」 NewProducts 和「新訂單明細表」 NewOrderDetails 等兩個副本,各用來存放產品編號 >= 70 以後的記錄
- 將原始的「產品資料表」Sales.Products 和「訂單明細表」 Sales.OrderDetails 等兩個資料表,刪除產品編號 >= 70 以後的記錄,同時 OUTPUT 顯示受影響的資料列
- 新增一個預存程序 Production.AddNewProducts,只用來查詢「新產品資料表」 NewProducts,並傳回所有記錄
- 使用 INSERT + PROCEDURE,將預存程序傳回的結果集,INSERT 到原始的「產品資料表」Sales.Products
- 使用 INSERT + SELECT,將 SELECT 「新訂單明細表」 NewOrderDetails 傳回的結果集,INSERT 到原始的 Sales.OrderDetails 資料表,同時 OUTPUT 顯示受影響的資料列
-- 新增一個「新產品資料表」副本,只存放產品編號 >= 70 的記錄
DROP TABLE IF EXISTS NewProducts
GO
SELECT * INTO NewProducts
FROM PRODUCTION.PRODUCTS WHERE ProductID >= 70
GO
-- 新增一個「新訂單明細表」副本,只存放產品編號 >= 70 的記錄
DROP TABLE IF EXISTS NewOrderDetails
GO
SELECT * INTO NewOrderDetails
FROM SALES.OrderDetails WHERE ProductID >= 70
GO
-- 刪除原始資料表產品編號 >= 70 以後的記錄,並顯示受影響的記錄
DELETE FROM SALES.OrderDetails
OUTPUT DELETED.*
WHERE ProductID >= 70
GO
DELETE FROM Production.Products
OUTPUT DELETED.*
WHERE ProductID >= 70
GO
-- 新增一個預存程序 Production.AddNewProducts
-- 用來查詢「新產品資料表」 NewProducts,並傳回所有記錄
DROP PROCEDURE IF EXISTS Production.AddNewProducts
GO
CREATE PROCEDURE Production.AddNewProducts
AS
BEGIN
SELECT Productid, productname, SupplierID, CategoryID, listprice, discontinued, InStock FROM NewProducts
END
GO
-- 使用 INSERT + PROCEDURE
-- 將預存程序傳回的結果集
-- INSERT 到原始的「產品資料表」Production.Products
INSERT INTO Production.Products (Productid, productname, SupplierID, CategoryID, listprice, discontinued, InStock)
EXEC Production.AddNewProducts;
SELECT * FROM Production.Products
WHERE productid >= 70
GO
-- 使用 INSERT + SELECT
-- SELECT 「新訂單明細表」 NewOrderDetails 傳回的結果集
-- INSERT 到原始的 Sales.OrderDetails 資料表,同時 OUTPUT 顯示受影響的資料列
INSERT Sales.OrderDetails (orderid, productid, unitprice, qty, discount)
OUTPUT INSERTED.*
SELECT [orderid], [productid], [unitprice], [qty], [discount] FROM NewOrderDetails
GO
-- -- Clean up the database
DROP TABLE NewProducts
GO
DROP TABLE NewOrderDetails
GO
DROP PROCEDURE Production.AddNewProducts
GO
- 範例 B:DML + OUTPUT … INTO
-- 根據 hr.employees 產生測試的來源資料表 hr.copy_emp
drop table if exists hr.copy_emp
select empid + 0 empid,
lastname,
salary,
hiredate into hr.copy_emp
from hr.Employees
where empid < 5;
go
select * from hr.copy_emp;
go
-- 建立歷程記錄資料表 hr.copy_emp_log
-- 根據需求定義資料行和屬性清單
drop table if exists hr.copy_emp_log
create table hr.copy_emp_log
( empid int,
salary money );
go
select * from hr.copy_emp_log
-- INSERT + OUTPUT ... INTO
-- 只新增 5 號以後的員工編號
insert into hr.copy_emp ([empid], [lastname], [salary], [hiredate])
output inserted.empid, inserted.salary into hr.copy_emp_log
select [empid], [lastname], [salary], [hiredate]
from hr.Employees
where empid >= 5;
go
select * from hr.copy_emp;
select * from hr.copy_emp_log
go
-- UPDATE + OUTPUT ... INTO
-- 只更新 5 號以後的員工編號
update hr.copy_emp
set salary += 999
output deleted.empid, deleted.salary into hr.copy_emp_log
where empid >= 5;
go
select * from hr.copy_emp;
select * from hr.copy_emp_log
go
-- DELETE + OUTPUT ... INTO
-- 只刪除 5 號以後的員工編號
delete hr.copy_emp
output deleted.empid, deleted.salary into hr.copy_emp_log
where empid >= 5;
go
select * from hr.copy_emp;
select * from hr.copy_emp_log;
go
-- Clean Up
drop table if exists hr.copy_emp_log;
drop table if exists hr.copy_emp;
- 範例 C:MERGE + OUTPUT
-- 假設己經有一個預先建立好的資料表 sales.Emp_2007 (執行下列 T-SQL 來完成),它是用來儲存2007年度的銷售相關資料,且目前只有 4 位銷售人員的資料 (仍有其他銷售人員還未加入)
use tsql2;
drop table if exists sales.Emp_2007
select empid + 0 EmpID,
ordermonth,
0 SalesAmount
into sales.Emp_2007
from sales.EmpOrders
where empid < 5 and ordermonth >= '20070101' and ordermonth < '20080101';
go
--- 假設現在 sales.Emp_2007 如下列查詢的結果
select * from sales.Emp_2007
go
--- 根據來源檢視表 Sales.EmpOrders 的記錄,統計各員工在 2007 年各月份的銷售業績,若記錄相符則 UPDATE,否則 INSERT
begin tran
merge into sales.Emp_2007 t
using sales.EmpOrders s
on s.empid = t.empid and s.ordermonth = t.ordermonth
when matched then
update set t.SalesAmount = s.val
when not matched by target and s.ordermonth >= '20070101' and s.ordermonth < '20080101' then
insert (EmpID, OrderMonth, SalesAmount) values (s.empid, s.OrderMonth, s.val)
output $action, inserted.*, deleted.* --< 若加入 INTO 可附加到事先建立好的異動記錄資料表
;
rollback
--commit
Exercises:使用 UPDATE + OUTPUT 子句處理異動資料
-
以客戶資料表 Sales.Customers 為例,請試著為欄位 Phone 設計一個異動歷程記錄表 Sales.Cust_PhoneLog,並有下列的需求:
- 只要有更改欄位 Phone 的內容,就要留下記錄
- 客戶資料表 Sales.Customers 的欄位 Phone,記錄目前有效的電話資料
- 當 Sales.Customers 更改欄位 Phone 內容時,舊的資料必須寫入異動歷程記錄表
- 異動歷程記錄表除了儲存過去無效電話資料以外,還必須記錄此筆何時建立
- 如果可能,還要為 Sales.Customers 提供一個用來記錄最近一次修改日期時間的欄位
解題流程:
-
決定異動歷程記錄表是使用標準資料表、暫存資料表、資料表變數?
-
定義一個異動歷程記錄表,包含需要哪些資料行、資料類型、是否 NULL
-
撰寫並測試 UPDATE + OUTPUT + INTO,直到完成需求 (測試時,可加入 begin tran … rollback,待滿足需求後,再將其移除)
create table Sales.Cust_PhoneLog
( custid int,
phone nvarchar(24),
CreatedDate datetime
)
update [Sales].[Customers]
set [phone] = N'999-9999',
[ModifiedDate] = getdate()
output deleted.custid, deleted.phone, getdate() into Sales.Cust_PhoneLog
where custid = 2
select * from [Sales].[Customers] where custid = 2
select * from Sales.Cust_PhoneLog
alter table [Sales].[Customers]
add ModifiedDate datetime default (getdate()) -- 只針對 INSERT 有效
INSERT INTO [Sales].[Customers] ([companyname], [contactname], [contacttitle], [address], [city], [region], [postalcode], [country], [phone], [fax])
SELECT [companyname], [contactname], [contacttitle], [address], [city], [region], [postalcode], [country], [phone], [fax]
FROM [Sales].[Customers]
WHERE CUSTID = 2
SELECT TOP 1 * FROM [Sales].[Customers] ORDER BY CUSTID DESC
根據來源資料表 UPDATE 目標資料表
很多時候必須根據某資料表去更新另一個資料表,例如:人為失誤不小心錯改資料,此時可以根據過去的歷程記錄更正為正確的資料。少量更正資料的作業或許人工可以負擔,但大量更正資料,人工就不適合了,也會引發人為失誤的隱憂;這種情形下,MERGE 陳述式可以協助更正的作業,但是 UPDATE 陳述式會更適合。
完整語法:
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
- 注意上述語法中:
- UPDATE 可接資料表別名。
- 可使用 FROM 子句,在 SELECT 和 DELETE 都支援這個子句。
- 利用聯結 JOIN 技術 Mapping 到正確資料列,就更新指定資料表別名的資料列。
簡單案例
假設作業中發生人為失誤,誤值入多筆不正確的數值到 Salary,要如何復原記錄到正確的數值?
先執行以下 T-SQL
-- 根據 hr.employees 產生測試的來源資料表 hr.copy_emp
drop table if exists hr.copy_emp
select empid + 0 empid,
lastname,
salary,
hiredate into hr.copy_emp
from hr.Employees
where empid < 5;
go
-- 建立歷程記錄資料表 hr.copy_emp_log
-- 根據需求定義資料行和屬性清單
drop table if exists hr.copy_emp_log
create table hr.copy_emp_log
( empid int,
salary money );
go
-- 模擬人為失誤 (只能改一次)
update hr.copy_emp
set salary += 999
go
select * from hr.copy_emp;
select * from hr.copy_emp_log
go
如何復原記錄
-- 模擬人為失誤 (只能改一次)
update hr.copy_emp
set salary += 999
output deleted.empid, deleted.salary into hr.copy_emp_log --< 必須加入
go
update t
set t.salary = s.salary
from hr.copy_emp_log s
join hr.copy_emp t on t.empid = s.empid
對資料列進行分組和彙總 (數據分析) - 基礎
- 前面練習曾經做過一題 INSERT + SELECT 統計特定幾筆訂單編號的銷售小計,T-SQL 如下:
-- insert into Sales.OrderEmp_200710
select o.empid, e.lastname, od.qty * unitprice SalesAmount
from sales.orders o
join sales.OrderDetails od on od.orderid = o.orderid
join hr.Employees e on e.empid = o.empid
where o.orderid in (10689, 10692, 10721, 10723);
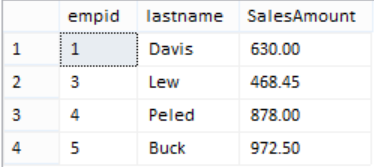
當時只挑這幾筆的原因是:訂單中的 2007 年 10 月份,只有這幾筆訂單,其訂單明細僅各有一筆;可試試再加入其它訂單看看,就會看到重複的員工編號的銷售業績,這不是資料有問題,而是聯結 JOIN 的天性,例如:
select o.empid, e.lastname, od.qty * unitprice SalesAmount
from sales.orders o
join sales.OrderDetails od on od.orderid = o.orderid
join hr.Employees e on e.empid = o.empid
where o.orderid in (10689, 10692, 10721, 10723, 10724, 10725)
order by empid;

利用 GROUP BY 就能將一大群資料,物以類聚進而分群,再使用彙總函式針對各群組的資料來統計資料;就算沒有 GROUP BY,SQL 也會將整個資料表視為一個大群組

- 這部份將說明:
- 彙總函式(數)
- 如何使用 GROUP BY
- 彙總函式 + GROUP BY
- WHERE 與 HAVING
彙總函式(數)
-
彙總函式主要工作在一群已分類群組的資料,這一群可以是整個資料表 (視為一大分類群組),也可以是特定欄名的欄值來分群 (例如:上述例子的 EmpID,隨後將會說明)
-
資料表本身是一種集合,也可以看成一個大群組,所以未使用 GROUP BY 的 SELECT + 彙總函式(數) 也可以完成數據統計
-
這裡先介紹未使用 GROUP BY 子句的 SELECT 查詢,如何使用下列常用的彙總函式(數)
- COUNT():計算各群組中的筆數
- SUM():計算各群組中數值的總和
- AVG():計算各群組中數值的平均
- MIN():計算各群組中最小值
- MAX():計算各群組中最大值
注意事項
所有彙總函式(數) 傳回結果為單一值 (Scalar Function)
所有彙總函式(數) 預設為 ALL,傳回所有記錄(包含重複值)
所有彙總函式(數) 可指定 DISTINCT,傳回唯一值(排除重複值)
所有彙總函式(數) 的 EXPRESSION:
不允許彙總函式和子查詢
除了 COUNT() 這個彙總函式(數)以外,其餘皆支援常數、資料行或函數,或任何算術、位元和字串運算子的組合
除了 COUNT(*) 以外,其餘皆會忽略空值 NULL,但可以使用 COALESCE() 或 ISNULL() 函數來解決,甚至配合 IIF() 可計算出空值 NULL 筆數
Demonstration:一次看懂 5 種常用的彙總函式(數)
- 範例 A:簡單案例,Part I
use tsql2;
-- 現有結果集如下:
select * from hr.employees;
-- 經過彙總函式的結果如下:
select count( * ) '所有員工人數',
sum( Salary ) '所有員工月薪總計',
avg( Salary ) '所有員工月均薪',
count( region ) '所有員工有 Region 資料的人數', --< 自動忽略空值 NULL
count( iif(region is null, 1, null) ) '所有員工無 Region 資料的人數', --< 示範如何只計算空值 NULL
min( hiredate ) '最資深員工到職日',
max( hiredate ) '最資淺員工到職日'
from hr.Employees;
範例 B:簡單案例,Part II
use tsql2;
-- 現有結果集如下:
select * from stats.scores;
-- 經過彙總函式的結果如下:
select count( * ) '所有測驗考生應到人數', --< 不會忽略空值 NULL
count( score ) '所有測驗考生實到人數', --< 會忽略空值 NULL
count( iif( score is null, 1, null ) ) '所有測驗缺考人數', --< 示範如何只計算空值 NULL
sum( Score ) '所有測驗成績總計', --< 忽略空值 NULL,但忽略有理
avg( Score ) '所有測驗成績平均', --< 忽略空值 NULL,但忽略無理
min( Score ) '所有測驗成績最低分', --< 忽略空值 NULL,但忽略無理
max( Score ) '所有測驗成績最高分' --< 忽略空值 NULL,但忽略有理
from stats.scores;
-- 經過改良後的彙總函式結果如下:
select count( * ) '所有測驗考生應到人數', --< 不會忽略空值 NULL
count( score ) '所有測驗考生實到人數', --< 會忽略空值 NULL
count( iif( score is null, 1, null ) ) '所有測驗缺考人數', --< 示範如何只計算空值 NULL
sum( Score ) '所有測驗成績總計', --< 忽略空值 NULL,但忽略有理
avg( coalesce( Score, 0 ) ) '所有測驗成績平均', --< 忽略空值 NULL,但己修正
min( coalesce( Score, 0 ) ) '所有測驗成績最低分', --< 忽略空值 NULL,但己修正
max( Score ) '所有測驗成績最高分' --< 忽略空值 NULL,但忽略有理
from stats.scores;
注意事項:
未使用 GROUP BY 的 SELECT 查詢,會將整個資料表視為一個大群組,再進行查詢
若能瞭解以上兩個簡單案例針對各彙總函式的說明,則可忽略以下「常用的各彙總函式」說明,直接跳到下一個內容:如何使用 GROUP BY (無彙總函式)
常用彙總函式
COUNT()
-
傳回運算式各群組中,所有值的筆數,或只傳回 DISTINCT 值的筆數
- COUNT(*) 傳回含空值 NULL 的總筆數
- COUNT(expression) 傳回非空值 NULL 的總筆數
-
傳回資料類型為 int
基本語法:
count ( { [ [ all | distinct ] expression ] | * } )
Demonstration:COUNT()
-
範例 A:統計並傳回員工資料表的:
- 所有全部人數 (包含空值 NULL)
- 所有有居住區域資料的全部人數 (不加 ALL,忽略空值 NULL)
- 所有有居住區域資料的全部人數 (加 ALL,忽略空值 NULL)
- 所有有居住區域不重複資料的全部人數 (加 DISTINCT,忽略空值 NULL)
select count(*), count(region), count(all region), count(distinct region)
from hr.Employees;

- 範例 B:統計成績資料表的測驗科目為 Test ABC,並傳回:
- 共有幾人參加測驗 (包含空值 NULL)
- 共有幾人有測驗分數 (不加 ALL,且忽略空值 NULL)
- 共有幾人有測驗分數 (加 ALL,且忽略空值 NULL)
- 共有幾人測驗分數不重複 (加 DISTINCT,忽略空值 NULL)
select count(*), count(score), count(all score), count(distinct score)
from stats.scores
where testid = 'Test ABC';

SUM()
-
傳回運算式各群組中,所有值的總和,或只傳回 DISTINCT 值的總和
-
傳回資料類型以最精確的 expression 資料類型,參官網
-
基本語法:
sum ( [ all | distinct ] expression )
Demonstration:SUM()
-
範例 A:統計並傳回員工資料表的:
- 所有員工薪資的總計 (不加 ALL,忽略空值 NULL)
- 所有員工薪資的總計 (加 ALL,忽略空值 NULL)
- 所有員工不重複薪資的總計 (加 DISTINCT,忽略空值 NULL)
select sum(salary), sum(all salary), sum(distinct salary)
from hr.Employees;

-
範例 B:統計成績資料表的測驗科目為 Test ABC,並傳回:
- 所有測驗分數的總分 (不加 ALL,忽略空值 NULL)
- 所有測驗分數的總分 (加 ALL,忽略空值 NULL)
- 所有不重複測驗分數的總分 (不加 ALL,忽略空值 NULL)
select sum(score), sum(all score), sum(distinct score)
from stats.scores
where testid = 'Test ABC';

AVG()
-
傳回運算式各群組中,所有值的平均值,或只傳回 DISTINCT 值的平均值
-
傳回資料類型以最精確的 expression 資料類型,參官網
-
基本語法:
avg ( [ all | distinct ] expression )
Demonstration:AVG()
-
範例 A:統計並傳回員工資料表的:
- 所有員工薪資的平均值 (不加 ALL,忽略空值 NULL)
- 所有員工薪資的平均值 (加 ALL,忽略空值 NULL)
- 所有員工不重複薪資的平均值 (加 DISTINCT,忽略空值 NULL)
select avg(salary), avg(all salary), avg(distinct salary)
from hr.Employees;

-
範例 B:統計成績資料表的測驗科目為 Test ABC,並傳回:
- 所有測驗分數的平均值 (不加 ALL,忽略空值 NULL)
- 所有測驗分數的平均值 (加 ALL,忽略空值 NULL)
- 所有不重複測驗分數的平均值 (加 DISTINCT,忽略空值 NULL)
select avg(score), avg(all score), avg(distinct score)
from stats.scores
where testid = 'Test ABC';

MIN()
-
傳回運算式各群組中,所有值的最小值,或只傳回 DISTINCT 值的最小值
-
傳回與 expression 相同的資料類型
-
基本語法:
min ( [ all | distinct ] expression )
Demonstration:MIN()
-
範例 A:統計並傳回員工資料表的:
- 所有員工薪資的最小值 (不加 ALL,忽略空值 NULL)
- 所有員工薪資的最小值 (加 ALL,忽略空值 NULL)
- 所有員工不重複薪資的最小值 (加 DISTINCT,忽略空值 NULL)
select min(salary), min(all salary), min(distinct salary)
from hr.Employees;

-
範例 B:統計成績資料表的測驗科目為 Test ABC,並傳回:
- 所有測驗分數的最小值 (不加 ALL,忽略空值 NULL)
- 所有測驗分數的最小值 (加 ALL,忽略空值 NULL)
- 所有測驗分數不重複的最小值 (加 DISTINCT,忽略空值 NULL)
select min(score), min(all score), min(distinct score)
from stats.scores
where testid = 'Test ABC';

MAX()
-
傳回運算式各群組中,所有值的最大值,或只傳回 DISTINCT 值的最大值
-
傳回與 expression 相同的資料類型
-
基本語法:
max ( [ all | distinct ] expression )
Demonstration:MAX()
-
範例 A:統計並傳回員工資料表的:
- 所有員工薪資的最大值 (不加 ALL,忽略空值 NULL)
- 所有員工薪資的最大值 (加 ALL,忽略空值 NULL)
- 所有員工不重複薪資的最大值 (加 DISTINCT,忽略空值 NULL)
select max(salary), max(all salary), max(distinct salary)
from hr.Employees;

-
範例 B:統計成績資料表的測驗科目為 Test ABC,並傳回:
- 所有測驗分數的最大值 (不加 ALL,忽略空值 NULL)
- 所有測驗分數的最大值 (加 ALL,忽略空值 NULL)
- 所有測驗分數不重複的最大值 (加 DISTINCT,忽略空值 NULL)
select max(score), max(all score), max(distinct score)
from stats.scores
where testid = 'Test ABC';

如何使用 GROUP BY (無彙總函式)
-
多數人都以為 GROUP BY 子句一定要搭配彙總函式,這是一個錯誤的認知
-
GROUP BY 子句會根據 <group by-list> 的資料行,相同欄值 (包含空值 NULL) 的歸成一群 (可能會有數個群組),各群組只取出「摘要值」,因此 GROUP BY 子句不需要在 SELECT 再指定 DISTINCT 子句,特別在沒有搭配任何彙總函式的情形下,就具有排除重複值的效果
-
GROUP BY 子句有下列限制:
- 出現在 <group by-list> 清單中的資料行,可選擇性地置於 SELECT 的 <select-list> 清單中
- 未出現在 <group by-list> 清單中的資料行,若要置於 SELECT 的 <select-list> 清單中,則必須包含在彙總函式中,後續課程會說明
-
基本語法:
SELECT 欄名1 [, 欄名2, ..., 欄名n] <-- <select-list>
FROM ...省略...
WHERE ...省略...
GROUP BY 欄名1 [, 欄名2, ..., 欄名n] <-- <group by-list>
注意事項:
因為 GROUP BY 子句本身限制的問題,一個結果集不能出現太多欄位,這類的 SELECT 查詢通常只是解決部份問題而已,一個完整的解決通常會再搭配其他的查詢邏輯,例如:子查詢,後面會說明
若能瞭解無彙總函式下的 GROUP BY 功用,則可直接跳到下一個內容:彙總函式 + GROUP BY
Demonstration:如何使用 GROUP BY (無彙總函式)
範例 A:傳回員工資料表中,所有員工所屬的國籍
select country
from hr.Employees
group by country;
範例 B:傳回員工資料表中,所有員工居住的區域
select region
from hr.Employees
group by region;
範例 C:傳回員工資料表中,員工職稱不是銷售助理 (Sales Assistant) 的國籍
select country
from hr.Employees
where title <> 'Sales Assistant'
group by country;
範例 D:傳回成績資料表中,有幾科考試科目
select testid
from stats.scores
group by testid;
彙總函式 + GROUP BY
- 若 SELECT 搭配彙總函數,會傳回各組的彙總值
- 基本語法:
SELECT 彙總函數(欄名x), 欄名1 <-- 欄名x 可以是 或 不是來自 <group by-list>
FROM ...省略...
WHERE ...省略...
GROUP BY 欄名1 [, 欄名2, ..., 欄名n] <-- <group by-list>
注意事項
未出現在彙總函數的欄名,必須出現在分組清單 group by-list 內
Demonstration:如何使用 彙總函式 + GROUP BY
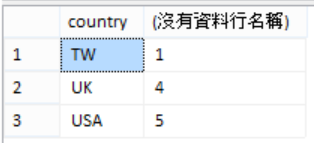
- 範例 A:傳回員工資料表中,所有員工所屬的國籍和人數
select country, count(country)
from hr.Employees
group by country;
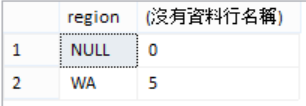
- 範例 B:傳回員工資料表中,所有員工所居住區域和人數
select region, count(region)
from hr.Employees
group by region;
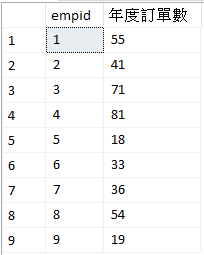
- 範例 C:統計各員工在 2007 年的訂單數,傳回 EmpID 和 年度訂單數
select empid, count(*) 年度訂單數
from sales.orders
where year(orderdate) = 2007
group by empid
- 範例 D:將前一題再加入 LastName
select o.empid, e.lastname, count(*) 年度訂單數
from sales.orders o
join hr.Employees e on e.empid = o.empid
where year(orderdate) = 2007
group by o.empid, e.lastname

注意事項:
LastName 資料行必須置於 GROUP BY 子句中,因為它是未經彙總函數處理的資料行
WHERE 與 HAVING
-
WHERE 子句是分組前的篩選條件,HAVING 子句是分組後的篩選條件,兩者並沒有衝突,也沒有規定一定要同時配合 GROUP BY 子句才能使用
-
基本語法:
SELECT 彙總函數(欄名)
FROM ...省略...
WHERE 分組前的篩選條件
GROUP BY 欄名1 [, 欄名2, ..., 欄名n]
HAVING 分組後的篩選條件
注意事項
WHERE 不支援彙總函數,HAVING 支援彙總函數
若無 GROUP BY 子句,則整個資料表視為一大群組
Demonstration:如何使用 WHERE 與 HAVING
範例 A:傳回員工資料表中,所有員工所屬的國籍和人數大於 1 人以上的資料 (在有 GROUP BY 子句下僅使用 HAVING)
select country, count(country)
from hr.Employees
group by country
having count(country) > 1;
- 範例 B:傳回員工月均薪是否高於 $90,000 ?如果是,則顯示月均薪的金額 (在沒有 GROUP BY 子句下僅使用 HAVING)
select avg(salary) 月均薪
from hr.Employees
having avg(salary) > 90000;
注意事項
WHERE 不支援彙總函數
HAVING 未規定必須在 GROUP BY 子句之後
若無 GROUP BY 子句,則整個資料表視為一大群組
範例 C:? (在有 GROUP BY 子句下同時使用 WHERE 和 HAVING)
select country, count(country)
from hr.Employees
where region is not null
group by country
having count(country) > 1;
Exercises:使用和實作資料的分組和彙總
- 統計各員工在 2007 年各月份的訂單數,傳回:
EmpID
月份
訂單數
注意事項:
「訂單數」意即各月份有多少筆訂單
select
EmpID,
month(orderdate) 月份,
count(*) 訂單數
from sales.orders
where year(orderdate) = 2007
group by empid, month(orderdate)
order by empid, month(orderdate)
- 統計各員工在 2007 年各月份訂單銷售量 (qty * unitprice) 超過 $10,000 元者,傳回:
EmpID
月份
訂單銷售量
select
EmpID,
month(orderdate) 月份,
sum(qty * unitprice) 訂單銷售量
from sales.orders o
join sales.OrderDetails od on od.orderid = o.orderid
where year(orderdate) = 2007
group by empid, month(orderdate)
having sum(qty * unitprice) > 10000
order by empid, month(orderdate)
查詢最佳化工具(Query Optimizer)
查詢最佳化工具(Query Optimizer)是 SQL Server 內部的查詢處理模組,攸關 SQL Server 執行效率;不同時期版本之間可能存在差異性;它的輸出是查詢執行計畫
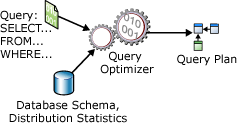
- 處理 SELECT 陳述式所使用的基本步驟如下:
- 「剖析器」會掃描 SELECT 陳述式,並將其分成數個邏輯單位,例如關鍵字、運算式、運算子和識別碼
- 然後系統會建立「查詢樹」 (有時也稱為序列樹),描述將來源資料轉換成結果集所需格式的邏輯步驟
- 「查詢最佳化工具」會分析可存取來源資料表的數種方式,接著它會選取一系列的步驟,以利使用更少的資源以最快的速度傳回結果,將會更新查詢以記錄所有的系列步驟,「查詢樹」的最後最佳版本就稱為執行計畫
- 關聯式引擎開始執行執行計畫,當在處理需要基底資料表中資料的步驟時,關聯式引擎會要求儲存引擎,從取自關聯式引擎的資料列集中傳回資料
- 關聯式引擎處理從儲存引擎傳回的資料,並將其設定成結果集所定義的格式,然後將結果集傳回給用戶端
注意事項:
「估計執行計畫」只包含上述的前 3 個步驟
「實際執行計畫」包含上述的全部 5 個步驟
子查詢
子查詢是用來解決複雜的查詢邏輯,用來分解一連串的處理邏輯,變成有系統脈絡的查詢;它是透過至少兩個 SELECT 陳述式,將一個 SELECT 置於另一個 SELECT 當中 (類似巢狀結構),其中裡面的 SELECT 就稱為「子查詢」,進而形成一個分號(;)作為結束的陳述式 (因為兩個 SELECT 陳述式要有各自的分號(;)作為結束)
許多包含子查詢的陳述式,也可以使用聯結 JOIN 來構成,意即兩者最終的結果集都是相同的;在 SELECT、INSERT、UPDATE、DELETE 等陳述式中,在支援運算式的任何位置使用子查詢,這是子查詢的最大的優勢,但劣勢就是陳述式的數量或長度是朝正面方向發展
- 一個子查詢的簡單案例如下:
select *
from stats.scores
where testid in (select testid from stats.tests);
問題
以上是否可改以「聯結 JOIN」的方式傳回相同的結果集?
可以
-
若依據子查詢的傳回結果,則可分為:(必須搭配適合的運算子,後續會說明)
- 單一資料列子查詢 (Single-row subqueries)
- 多重資料列子查詢 (Multiple-row subqueries)
注意事項:
以上的結果集通常是由單一資料行(欄名)所組成,切記!
多重資料行(欄名)不是不能處理,在 MS-SQL Server 必須改以「聯結 JOIN」處理,或者是改以「EXISTS」、「NOT EXISTS」處理
-
若依據撰寫方式,則可分為:
- 自包含子查詢 (Self-Contained Subqueries),或獨立子查詢、簡單子查詢
- 這是最經典的子查詢,後續先說明此類型的子查詢
- 相互關聯子查詢 (Correlated Subqueries),這幾乎和「聯結 JOIN」有著異曲同工效果
- 某些子查詢的設計邏輯也能轉換成聯結的設計邏輯,反之亦然,留待最後再來說明
- 自包含子查詢 (Self-Contained Subqueries),或獨立子查詢、簡單子查詢
子查詢 vs 聯結 JOIN
若 SELECT 的查詢,必須根據某一個資料表的資料,來決定另一個資料表的查詢輸出,此需求相關的做法有:「聯結 JOIN」,還有另一個就是「子查詢 Subquery」:
- 「聯結 JOIN」先天的優勢,只要順著資料表的關聯性,就能容易撰寫和設計,但處理效率就不怎麼好,因為它的起手式就是 Cartesian Product
- 「子查詢 Subquery」先天的優勢就是易於理解,且可分解複雜的篩選邏輯,在某些應用情境的子查詢處理效率甚至比聯結還快,但寫起來就比較複雜,也造成 Developers 使用意願不高
注意事項:
「聯結 JOIN」 vs 「子查詢 Subquery」處理效率誰快?沒有絕對答案
使用分析工具解決處理效率的疑慮,是最直接的方式
效能最佳化的議題涵蓋範圍甚廣,也可能在不同版本的 RDBMS 有不同的結果,這裡只針對相同軟硬體條件下的語法邏輯比較
「子查詢」會根據傳回值數量 (單一值或多重值) 使用不同比較運算子,初學者必須詳記各種做法,而「聯結 JOIN」則沒有這部份的問題 (後續課程會詳細說明)
最終的結果集
子查詢指的是在 SELECT 當中還有另一個 SELECT,因而形成巢狀式查詢,分為:
- 「外部查詢」:「外部查詢」的 <select-list> 是用來決定最終傳回的結果集,其資料行(欄名)一定是來自外部查詢所參考的資料表
- 「內部查詢」:「內部查詢」的資料表的任何欄名,不行也決不能夠出現在「外部查詢」的 <select-list> 當中
如何撰寫子查詢
- 找出所有會參考到的資料表清單
- 決定最終傳回結果集是來自哪一個資料表,該資料表就置於「外部查詢」FROM 子句後
- 在「資料庫圖表」中找出該資料表
- 再從關聯性找出其它相關資料表
- 根據關聯性決定各資料表之間的「對映欄名」,也就是撰寫聯結 JOIN 時的『欄名對欄名』之關聯條件
- 決定各子查詢層級,以及所參考的資料表 (由外而內 或 由內而外)
- 決定各 SELECT 的 Predicate 篩選條件
- 決定各 SELECT 的 Predicate 較為適合之比較運算子
例如:利用以下「資料庫圖表」內容為例,如果想傳回測驗科目名稱為『國文』的學生測驗成績,則「外部查詢」所參考的資料表就是測驗成績,「內部查詢」所參考的資料表就是測驗科目

select *
from stats.scores --< 「外部查詢」
where testid =
(
select testid
from stats.tests --< 「內部查詢」
where name = N'國文'
);
注意事項:
上例子查詢傳回的結果集,是屬於「單一資料列子查詢」 (Single-row subqueries)
自包含子查詢 Self-Contained Subquery (獨立子查詢)
這是一種典型的子查詢,如同前面所舉的例子一樣,但必須遵守以下規定:
- 子查詢 SELECT 前後必須以小括號圍住
- 子查詢傳回的結果集,僅用來提供給外部查詢的 Predicate (WHERE 篩選條件) 進行運算,換言之,整個子查詢是置於外部查詢的 Predicate
注意事項:
目前所介紹的典型子查詢,其資料行皆不能出現在最後傳回的結果集中
- 基本語法:
SELECT <select-list>
FROM 表1
WHERE 表1.欄名 =
(
SELECT <select-list> <-- 傳回單一值 Scalar Value
FROM 表2
WHERE 表2.欄名 = 常數 <-- 可看成是使用者在前端 App. 輸入的資料值
);
注意事項
常數可以視為使用者在前端 App. 輸入的資料值
因為外部查詢的 WHERE 子句使用比較運算子,例如等號 = ,所以內部查詢必須傳回單一值或稱為純量值 Scalar Value
若內部查詢傳回多重值 Multi-Values,外部查詢的 WHERE 子句就必須使用修改的比較運算子 (後續課程會說明)
Demonstration:如何使用 Self-Contained Subquery (獨立子查詢)
此示範將會同時比較子查詢和聯結的不同設計邏輯
範例 A:查詢訂單編號 10500 的銷售人員資料
- 子查詢
select empid, lastname, firstname, country, city
from hr.Employees
where empid =
(
select empid
from sales.orders
where orderid = 10500
);
- 聯結
select e.empid, e.lastname, e.firstname, e.country, e.city
from hr.Employees e
join sales.orders o on o.empid = e.empid
where o.orderid = 10500;
問題:
何者效率最好? ans:子查詢效率通常會較好
範例 B:查詢哪些訂單,是在客戶名稱 Customer UMTLM 的最後一天訂單之後才產生的,傳回那些訂單的所有欄位資料
- 子查詢 1 + TOP
select *
from sales.orders
where orderdate >
(
select top 1 orderdate
from sales.orders
where custid =
(
select custid
from sales.Customers
where companyname = 'Customer UMTLM'
)
order by orderdate desc
);
注意事項
當 TOP 與 ORDER BY 子句一起使用時,結果集會限制為前 N 個經過排序的資料列,否則會傳回前 N 個未經任何方式排序的資料列
TOP 子句不符合 ANSI SQL 標準,只能用在 MS-SQL Server,可改用符合 ANSI SQL 標準的 OFFSET…FETCH…
- 子查詢 2 + OFFSET…FETCH…
select *
from sales.orders
where orderdate >
(
select orderdate
from sales.orders
where custid =
(
select custid
from sales.Customers
where companyname = 'Customer UMTLM'
)
order by orderdate desc
offset 0 rows
fetch next 1 rows only
);
注意事項
OFFSET…FETCH… 子句必須搭配 ORDER BY 子句
- 子查詢 3
select *
from sales.orders
where orderdate >
(
select max(orderdate)
from sales.orders
where custid =
(
select custid
from sales.Customers
where companyname = 'Customer UMTLM'
)
);
- 子查詢 4 + 聯結
select *
from sales.orders
where orderdate >
(
select max(o.orderdate)
from sales.orders o
join sales.Customers c on c.custid = o.custid
where companyname = 'Customer UMTLM'
);
- 子查詢 5 + 聯結
select *
from sales.orders
where orderdate >
(
select o.orderdate
from sales.orders o
join sales.Customers c on c.custid = o.custid
where companyname = 'Customer UMTLM'
order by o.orderdate desc
offset 0 rows
fetch next 1 rows only
);
注意事項
若採衍生資料表就能完全以聯結的設計方式,後續課程會說明
範例 C:查詢產品名稱 Product VAIIV 被訂購數量最多的一筆訂單,傳回訂單的所有欄位資料
select *
from sales.orders
where orderid =
(
select orderid
from sales.orderdetails
where productid =
(
select productid
from Production.Products
where productname = 'Product VAIIV'
)
group by orderid
order by sum(qty) desc
offset 0 rows
fetch next 1 rows only
);
注意事項
彙總函式也能置於 order by 子句,將運算結果值排序
本範例使用 3 層巢狀式查詢,若只要傳回訂購數最多的一筆訂單,不必設計最外層的查詢
- 子查詢 2 + 聯結
select *
from sales.orders
where orderid =
(
select od.orderid
from sales.orderdetails od
join Production.Products p on p.productid = od.productid
where p.productname = 'Product VAIIV'
group by od.orderid
order by sum(qty) desc
offset 0 rows
fetch next 1 rows only
);
- 聯結
select o.*
from sales.orders o
join sales.orderdetails od on od.orderid = o.orderid
join Production.Products p on p.productid = od.productid
where p.productname = 'Product VAIIV'
group by o.orderid, o.custid, o.empid, o.orderdate, o.requireddate, o.shippeddate, o.shipperid, o.freight, o.shipname, o.shipaddress, o.shipcity, o.shipregion, o.shippostalcode, o.shipcountry
order by sum(qty) desc
offset 0 rows
fetch next 1 rows only;
注意事項
為了輸出指定欄位,將指定欄位置於 group by 子句,效能低落,贏了面子,輸了裡子
解決 group by 子句的問題,可採 over() 函數,後續會說明
範例 E:查詢哪個部門的平均薪資高於所有員工平均薪資,傳回主管編號, 部門平均薪資
- 子查詢 (使用 HAVING 子句)
select MgrID 主管編號,
avg(salary) 部門平均薪資
from hr.Employees
group by mgrid
having avg(salary) > (select avg(salary) from hr.Employees);
注意事項:
目前範例資料庫中,並沒有部門資料表,只能取員工資料表中的主管編號 MgrID 作為區隔不同部門之用
此子查詢是位於 HAVING 子句,這和之前子查詢位於 WHERE 子句都是相同的 Predicate 之應用
因為 Predicate 中的彙總函式,只能用於 HAVING 子句
子查詢傳回值的分類
-
根據子查詢的傳回值,可分成:(再次提醒,必須由單一資料行(欄名)所以組成)
- 單一資料列子查詢(Single-row subqueries),又稱為純量值子查詢(Scalar Subquery),前面課程內容都是這種
- 多重資料列子查詢(Multiple-row subqueries),又稱為多重值子查詢
-
典型子查詢通常會採用下列格式之一:
- WHERE expression [NOT] IN (子查詢)
- WHERE expression comparison_operator [ANY | ALL] (子查詢)
- WHERE [NOT] EXISTS (子查詢)
-
在外部查詢的 Predicate 中,必須隨著子查詢的傳回值而採用不同的比較運算子:
- 若是純量值子查詢,外部查詢須使用傳統的 (單值) 比較運算子,隨後說明
- 若是多重值子查詢,外部查詢使用的運算子有下列兩種搭配:
- 使用傳統的 (多值) 比較運算子
- 使用傳統的 (單值) 比較運算子 + 修改的比較運算子,絕不可單獨使用修改的比較運算子
純量值子查詢
- 所謂純量值子查詢,是指子查詢只會傳回單一值,單一值又稱為純量值 Scalar Value
- 外部查詢只能使用傳統的 (單值) 比較運算子,例 = , > , >= , < , <= , <> 等
多重值子查詢
- 所謂多重值子查詢,是指子查詢會傳回多重值,多重值又稱為 Multi-Values
- 因為外部查詢在評估篩選條件時 (來自多重值子查詢),可能評估多重值的零個到多個值之間任一個值,也可能評估多重值的所有每一個值,所以需視情況選用不同的運算子:
- 若只需評估 有 或 沒有,可使用『存在測試運算子』,例如:EXISTS 或 NOT EXISTS 等
- 若需評估零個或多個值之間任一個值,可使用另一種『傳統的 (多值) 比較運算子』,例如:IN 或 NOT IN 等
- 若需評估所有每一個值,例如必須大於或小於,可使用『傳統的 (單值) 比較運算子 + 修改的比較運算子』,例如:> ANY , < ALL 等
比較運算子
純量值子查詢就只有使用傳統的(單值)比較運算子而已,而多重值子查詢所使用的比較運算子可分成 3 種:
-
存在測試運算子 (EXISTS 和 NOT EXISTS)
-
傳統(多值) 比較運算子 (IN 和 NOT IN)
-
傳統的(單值) 比較運算子 + 修改的比較運算子 (ANY 和 ALL)
以下分別詳細介紹: -
存在測試運算子 - EXISTS 和 NOT EXISTS
- 當子查詢是以關鍵字 EXISTS 導入時,它可作為存在測試的子查詢函式,此函式只傳回 TRUE 或 FALSE 值,外部查詢的 WHERE 子句就可以測試子查詢所傳回的資料列是否存在
- EXISTS 只管子查詢傳回的結果集是否存在資料,如果存在,EXISTS 就傳回 TRUE,否則傳回 FALSE
- NOT EXISTS 與 EXISTS 相反,如果子查詢傳回的結果集不存在資料,NOT EXISTS 就傳回 TRUE,否則傳回 FALSE
- 一般用於「相互關聯子查詢」會比較有意義,後續課程會說明
-
傳統的 (多值) 比較運算子 - IN 和 NOT IN
- 當子查詢傳回的結果集包含為零個或多個值的清單時,外部查詢的 WHERE 子句就可以根據清單中進行 Predicating
- IN 代表 = a 或 = b 或 = c,例如:IN (a, b, c)
- NOT IN 代表 not = a 且 not = b 且 not = c,例如:NOT IN (a, b, c)
-
修改的比較運算子 - ANY 和 ALL
-
在 ISO 標準語法中,SOME 等同於 ANY,兩者在 MS-SQL Server 都可以使用,但以字義上來說,ANY 會較為貼切
-
若外部查詢的 WHERE 子句,必須在子查詢傳回的結果集中,找出比所有值大或小時,就必須使用『傳統的 (單值) 比較運算子 + 修改的比較運算子』
-
-
ANY 或 SOME
- > ANY 代表大於下限(最低)值,例如:> ANY (1, 2, 3) 代表大於 1
- < ANY 代表小於上限(最高)值,例如:< ANY (1, 2, 3) 代表小於 3
- = ANY 相當於 IN,代表 = a 或 = b 或 = c
- <> ANY 不同於 NOT IN,<> ANY 代表 not = a 或 not = b 或 not = c
注意事項:
注意 <> ANY 和 NOT IN 的差異,前者僅部份滿足,後者須全部滿足
-
ALL
-
> ALL 代表大於上限(最高)值,例如,> ALL (1, 2, 3) 代表大於 3
-
< ALL 代表小於下限(最低)值,例如,< ALL (1, 2, 3) 代表小於 1
-
= ALL 無意義,會傳回空值 null
-
<> ALL 和 NOT IN 一樣,代表 not = a 且 not = b 且 not = c
注意事項:
當子查詢傳回多重資料列時,= ALL 無意義且會傳回空值 null。
當子查詢傳回單一資料列時,= ALL 可傳回結果集。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









