










正则表达式的书写:
首先正则表达式对于字符串的匹配是按照字符来的,就是一个字符一个字符的比较,所以书写的概念要明白,先以字符为基础,然后构建字符串,然后构建想要的比较内容;
1. 字符的判断
例如:
匹配小写字母:[a-z]
匹配大写字母:[A-Z]
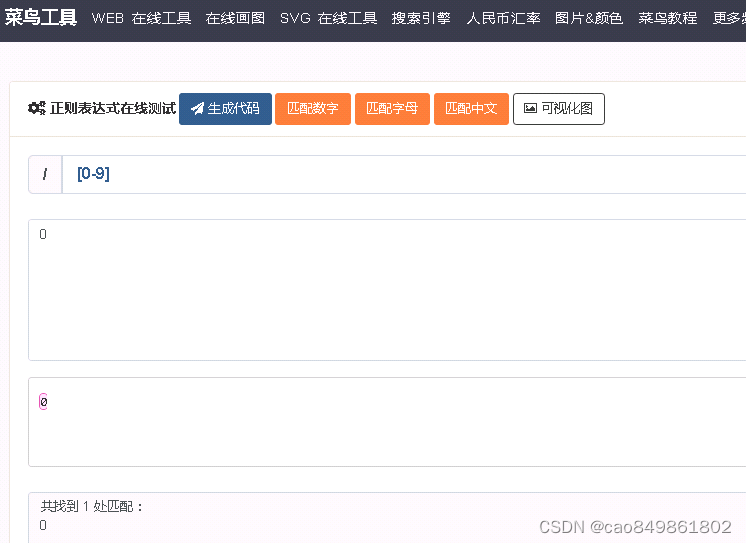
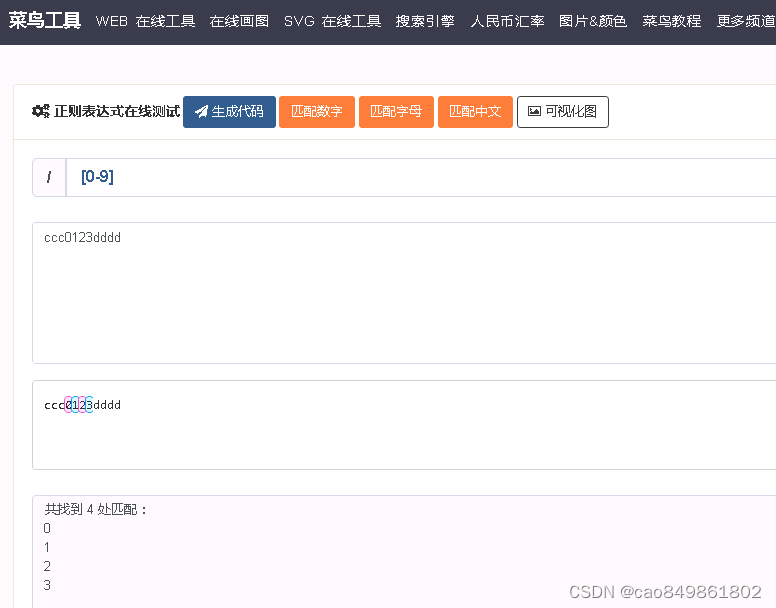
匹配数字:[0-9]
匹配空格:[ ]
这里都是比较一个字符的,就是只会看一个;然后比如字符a,b,C,0这种都是可以匹配的
2. 判断字符串
例如:
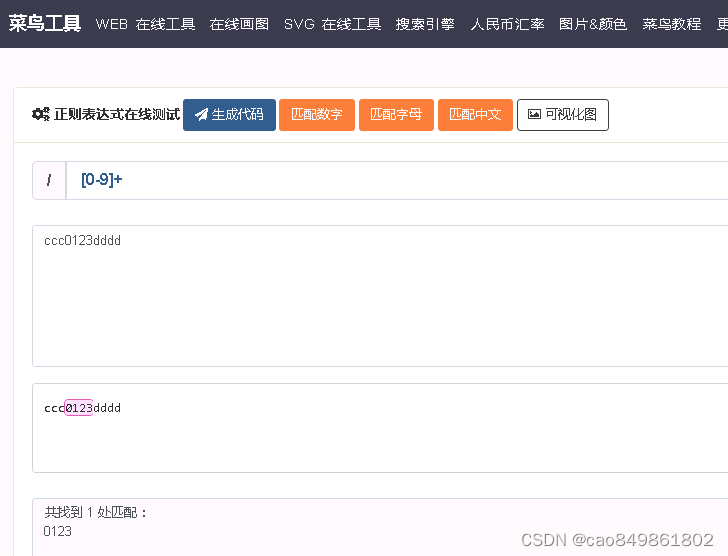
匹配数字字符串(“+”至少匹配一次):[0-9]+
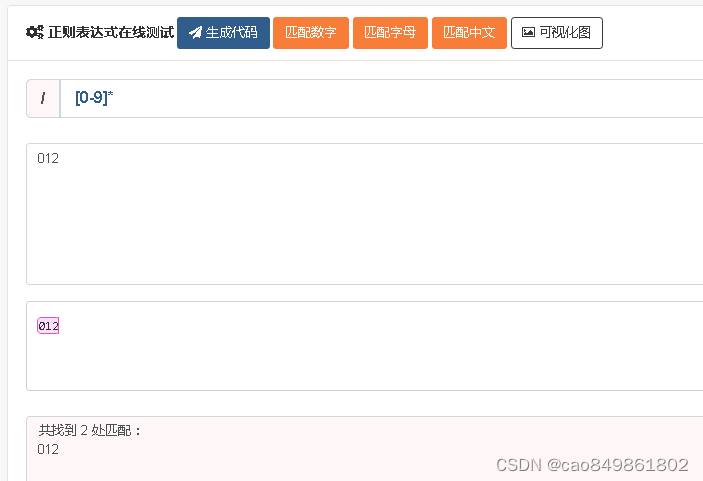
匹配数字字符串(“*”匹配0-n次):[0-9]*
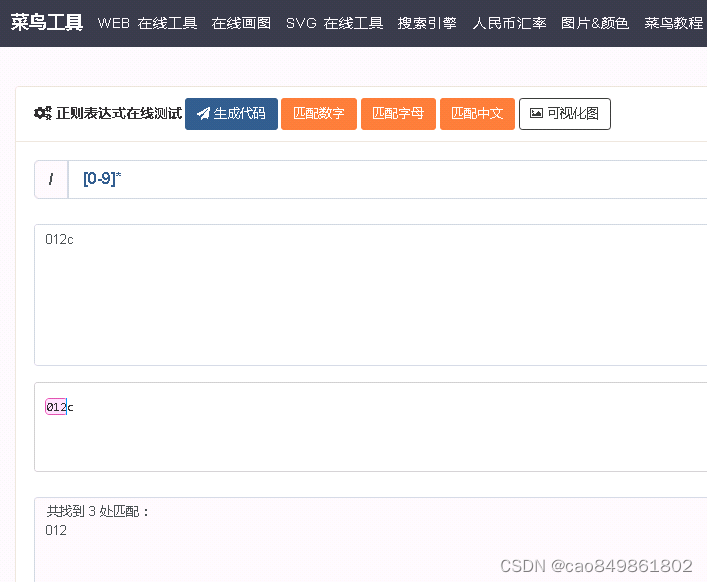
匹配数字字符串(“?”可选字符):[0-9]?

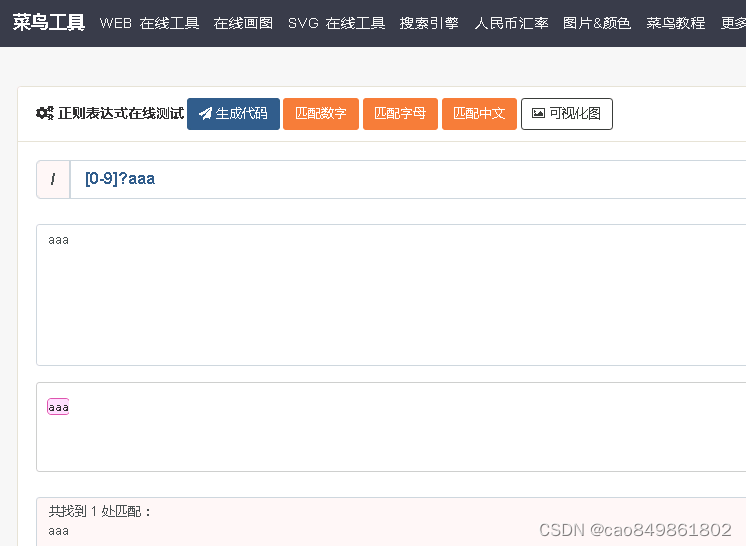
匹配变量(变量是数字字符下划线):[a-zA-Z0-9_]+

3. 常见的字符表示内容:
\s指的是空白字符集,包括[\r\n\t ]等;
\S指的是\s的取反;
\b匹配一个单词边界,即字与空格间的位置;
\B非单词边界匹配;
空格的正则表达式:[ ](单纯的空格);
需要转义的特殊字符:$,( ),*,+,.,[,?,\,^,{,|。这些字符要想使用需要加'\'
4.常见的字符串表示内容:
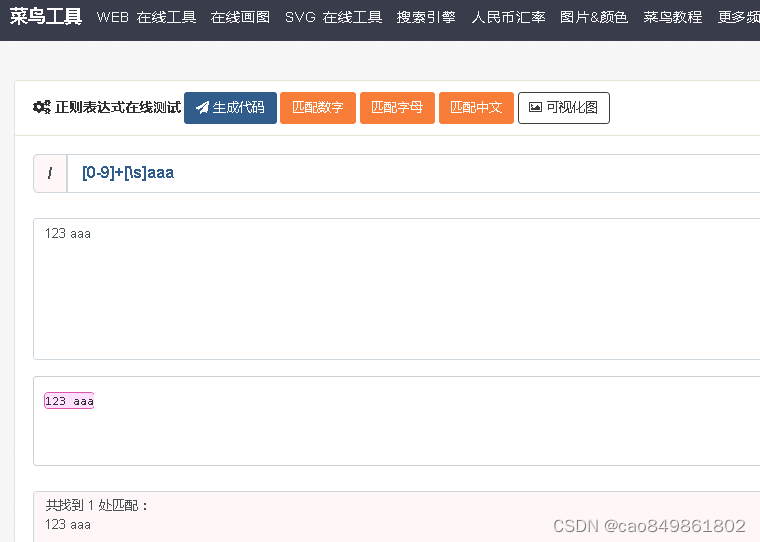
例如:[0-9]+[\s]aaa
[0-9]+:指的是0-9的数字然后匹配一个或者多个,只要能匹配就往后匹配
[\s]:指的就是空白字符
aaa:直接书写匹配的字符串
邮箱:^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
手机号:^1(3|4|5|6|7|8|9)\d{9}$
域名:^((http:\/\/)|(https:\/\/))?([a-zA-Z0-9]([a-zA-Z0-9\-]{0,61}[a-zA-Z0-9])?\.)+[a-zA-Z]{2,6}(\/)
ip:((?:(?:25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d?\d))
汉字:^[\u4e00-\u9fa5]{0,}$
变量定义:^([\s]*int[\s][\s]*[a-zA-Z0-9_\s,=]*value)|^([\s]*unsigned[\s][\s]*int[\s][\s]*[a-zA-Z0-9_\s,=]*value)
函数调用:
idbGet[\s]*\([\s]*\"[a-zA-Z0-9_]+\"[\s]*,[\s]*[a-zA-Z0-9_]+[\s]*,[\s]*[a-zA-Z0-9_]+[\s]*,[\s]*&[\s]*[a-zA-Z0-9_]+[\s]*,[\s]*&[\s]*[a-zA-Z0-9_]+[\s]*\)5. 各种括号的意义
() 是为了提取匹配的字符串。表达式中有几个()就有几个相应的匹配字符串。(\s*)表示连续空格的字符串。
[]是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字。[\s*]表示空格或者*号。
{}一般用来表示匹配的长度,比如 \s{3} 表示匹配三个空格,\s{1,3}表示匹配一到三个空格。
(0-9) 匹配 '0-9′ 本身。 [0-9]* 匹配数字(注意后面有 *,可以为空)[0-9]+ 匹配数字(注意后面有 +,不可以为空){1-9} 写法错误。
[0-9]{0,9} 表示长度为 0 到 9 的数字字符串。
6. 常见的符号表示内容:
abc+:+号用来表示前面的至少出现过一次(1/n);
abc*:*号代表可以不出现也可以出现一次或者多次(0/1/n);
abc?:?号代表前面的最多只能出现一次(0/1);
abc$:$号表示匹配结尾是否为abc;
abc{m}:{m}代表前面的只能出现n次(m);
abc{m,}:{m,}代表前面的出现m到无穷多次;
abc{n,m}:代表前面的出现n到m次;
( ): 标记一个子表达式的开始和结束位置;
. : 匹配除换行符 \n 之外的任何单字符;
{ : 标记限定符表达式的开始;
^:判断是否从字符串开始比较
注意:如果需要多个正则表达式的同时生效可以采用或的形式“()|()”
7. 简写字符集
正则表达式为常用的字符集和常用的正则表达式提供了简写。简写字符集如下:
| 简写 | 描述 |
|---|---|
| . | 匹配出换行符以外的任意字符 |
| \w | 匹配所有字母和数字的字符:[a-zA-Z0-9_] |
| \W | 匹配非字母和数字的字符: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配空格符: [\t\n\f\r\p{Z}] |
| \S | 匹配非空格符: [^\s] |
8. 标记
标记也称为修饰符,因为它会修改正则表达式的输出。这些标志可以以任意顺序或组合使用,并且是正则表达式的一部分。
| 标记 | 描述 |
|---|---|
| i | 不区分大小写: 将匹配设置为不区分大小写。 |
| g | 全局搜索: 搜索字符串中的所有匹配。 |
| m | 多行匹配: 会匹配输入字符串每一行。 |
对字符不区分大小写且全局搜索:\w\gi
对字符全局搜索多行匹配:\w\gm
9.断言
断言即满足某个条件,断言有些地方又叫零宽断言,它用于(不)匹配某些字符前面或者后面的字符。断言有以下几种:
| 符号 | 描述 |
|---|---|
| (?=exp) | 正向先行断言:正则用于匹配?=前面的内容满足?=后面是exp |
| (?<=exp) | 正向后行断言:正则用于匹配exp后面满足某个条件的内容 |
| (?!exp) | 负向正行断言:正则用于匹配exp后面不满足某个条件的内容 |
| (?<!exp) | 负向后行断言:正则用于匹配exp后面不满足某个条件的内容 |
正向先行断言用于找到某个内容后用正则去匹配它前面的内容。例如正则表达式
(H|h)(?=ello)
它用于找到ello后,如果前面是h或者H,则返回H或h。
后向先行断言用于找到某个内容后用正则去匹配它后面的内容。例如正则表达式
(?<=[h|H])ello
它用于找到H或者h后,去匹配后面内容是不是ello,如果是返回ello
(H|h)(?!ello)
找到H或h后后面不是ello,返回H或h
(?<!(H|h))ello
找到ello后,如果前面不是H或h,返回ello















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









