







最近我们医院的LIS系统经常出现速度极慢的问题,而且由于LIS系统的数据库表设计本身存在问题,刚用了一年的时间某张表的数据就已经达到3千万条。
服务器:HP刀片机 1个CPU(双核),2G内存,高峰期时有700个连接。
操作系统:Windows server 2003。
数据库:Ms SqlServer2000 各种补丁都已打全。
现状:服务器CPU利用率高,工作站各种操作极慢。
针对以上情况,为了解决问题,而表结构设计及程序也无法及时大规模优化的前提下,采取了以下解决方案。
1、首先,查找出占用CPU及IO资源较多的语句,可以采用Sql Server 的事件探查器。
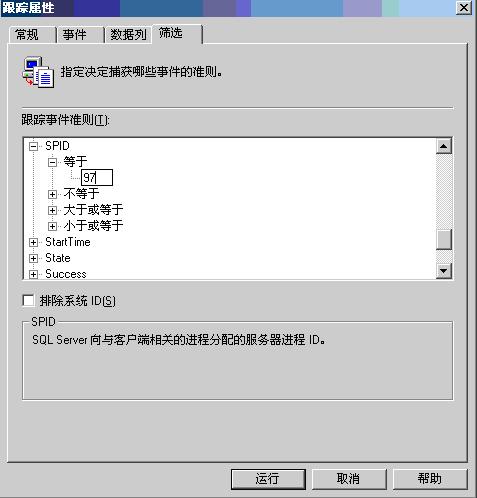
打开事件探查器,新建一个跟踪,我们可以采用跟踪某个工作站的形式进行,工作站的SPID可以在sysprocesses通过MAC地址来查,select spid from sysprocesses WHERE net_address='MAC地址';
如下图,请输入SPID后点击运行:
2、当跟踪运行一段时间后,将跟踪结果保存为跟踪文件,进行分析,找出CPU及READS占较多的语句,如下图所示,CPU为922表明占用异常,可以进行优化:
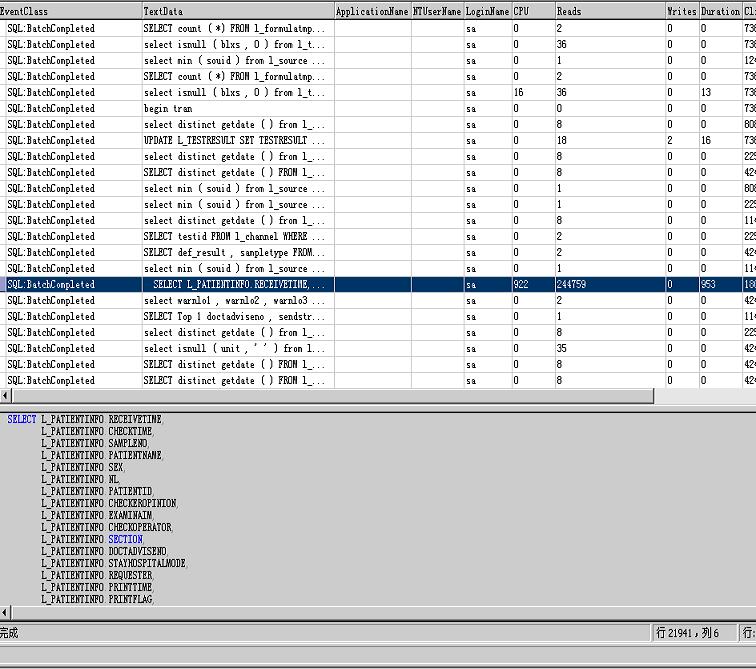
3、将得到的语句拿出来进行分析 ,发现有以下问题:
(1) 在条件中有函数;
(2) patientid 没有索引,但这个字段的使用频率较高;
SELECT vi_patient.patientname ,vi_patient.sex ,vi_patient.examinaim ,vi_patient.checkeropinion ,vi_patient.section ,vi_patient.depart_bed ,vi_patient.sampleno ,vi_patient.fee ,vi_patient.receivetime ,vi_patient.patientid ,vi_patient.resultstatus ,vi_patient.nl ,vi_patient.nldw ,vi_patient.fphm ,vi_patient.doctadviseno , vi_patient.labdepartment FROM vi_patient WHERE VI_PATIENT.RECEIVETIME >= convert(datetime,'2008-11-03 00:00:00',120) and VI_PATIENT.RECEIVETIME <= convert(datetime,'2008-11-24 23:59:59',120) and VI_PATIENT.patientid ='300039716' ORDER BY VI_PATIENT.RECEIVETIME DESC
解决方法:将语句作以下更改,并增加patientid 字段的索引,执行效率明显提高。虽然增加索引可能会减低插入及更新的效率,但综合分析patientid 查询的频率更高。
SELECT vi_patient.patientname ,vi_patient.sex ,vi_patient.examinaim ,vi_patient.checkeropinion ,vi_patient.section ,vi_patient.depart_bed ,vi_patient.sampleno ,vi_patient.fee ,vi_patient.receivetime ,vi_patient.patientid ,vi_patient.resultstatus ,vi_patient.nl ,vi_patient.nldw ,vi_patient.fphm ,vi_patient.doctadviseno , vi_patient.labdepartment FROM vi_patient WHERE VI_PATIENT.patientid ='300039716'and VI_PATIENT.RECEIVETIME between '2008-11-03 00:00:00' and '2008-11-24 23:59:59'
ORDER BY VI_PATIENT.RECEIVETIME DESC
4、联合索引的问题,这个表的记录条数达到3千万条,如下图,有以下联合索引:
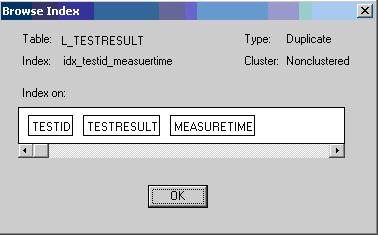
但在实际使用中一直都在单独使用MEASURETIME作为查询条件,作为联合索引使用时一定要慎重,在查询时要么索引所有的字段都在WHERE条件中,或索引的第一个字段在WHERE条件中,才会用到索引,其他字段单独作为查询条件其实该联合索引是不起任何作用的。
解决方法:增加单独的MEASURETIME索引,当使用MEASURETIME为条件查询时执行效率提高的很明显。
5、因服务器内存使用并没有问题,决定将一些常用的表常住内存,使用以下语句:
DECLARE @db_id int, @tbl_id int
USE lis
SET @db_id = DB_ID('lis')
SET @tbl_id = OBJECT_ID('L_SAMPLETYPE')
DBCC PINTABLE (@db_id, @tbl_id)
查询某张表是否常住内存:
Select ObjectProperty(Object_ID('L_SAMPLETYPE'),'TableIsPinned')
大家在实际使用过程中一定要注意,不能将太大的表常住内存,因为当服务器高速缓存满时,数据库将无法使用,只有重新启动才能使用。
6、更新一些重要表的重要索引,采用以下语句:
DBCC INDEXDEFRAG (lis,l_testresult,idx_testid_measuertime);
采取INDEXDEFRAG更新索引,可以做到在更新索引时不锁表。
6、总结:针对以上优化及改动后,服务器的CPU使用率有明显下降,工作站的操作速度也提升很多,达到了一定的效果。
在设计数据表结构时就应考虑程序的执行效率问题,如针对大表可以采取分表的策略,定期进行转储,尽量保证业务表的数据量一直很小。索引的设计一定要考虑实际的应用,一定要合理,并不是多多益善,也不是越少越好。如果系统已大规模应用再改表结构设计就不那么容易了,我采取以上方法只能治标但不能治本。
可能我的方法并不适合你,但见仁见智,仅供参考。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









