







http://hi.baidu.com/wtnzone/item/beb83840a4971af4dd0f6c77
数据库最常见的操作就是查询了,我们经常要用"SELECT"语法对已有的表进行某种检索,但是在实际应用中,查询前我们并不知道该查询会如何运行、会使用多少时间、会涉及多少字段和记录,每次输入了SQL语句,点击运行,然后慢慢等待结果的出现,好的查询语句效率很高,而有时候也会遇到查询缓慢,久久没有运行完成的情况。
由于我们并不知道实际查询的时候数据库里发生了什么,数据库软件是怎样扫描表、怎样使用索引,因此我们能感知的就只有查询运行的时间,而往往在数据规模不大时,查询是瞬间的,因此在写SQL语句时也就比较随意,也很少使用索引来加速查询的速度。不过一旦数据规模增大,比如百万、千万、几亿的时候,我们写同样的查询语句却发现窗口迟迟没有结果,这个时候才知道数据规模已经限制了我们自由查询的速度。查询优化和索引也就显得很重要了。
那么,能不能在查询前就能预先估计查询究竟要涉及多少行、使用哪些索引、运行多久呢?答案是可以的,MySql和SQL Server都提供了相应的功能和语法来实现,下面用一个拥有两千多万条记录的表来说明如何进行查询分析。该表有一个访问时间字段。
MySql提供了EXPLAIN语法用来进行查询分析,在SQL语句前加一个"EXPLAIN"即可。比如我们要分析如下SQL语句,该语句获取特定时间段的访问记录总数。
EXPLAIN
SELECT COUNT(*) FROM ××××××
WHERE
TIME_INT>=UNIX_TIMESTAMP('2010-03-01 18:00:00') AND
TIME_INT<UNIX_TIMESTAMP('2010-03-01 18:15:00')
返回的结果如下

从分析结果可知,该查询涉及3674行,用到了timeindex这个索引,using index说明该查询只需要检索索引即可完成。EXPLAIN中每一项的具体描述和表达的意义如下:(来自http://www.phpweblog.net/richard-dong/archive/2008/12/15/6173.aspx)
------------------------------
table | type | possible_keys | key | key_len | ref | rows | Extra
EXPLAIN列的解释
table
显示这一行的数据是关于哪张表的
type
这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL(后面有详细说明)
possible_keys
显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key
实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len
使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
MYSQL认为必须检查的用来返回请求数据的行数
Extra
关于MYSQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
extra列返回的描述的意义
Distinct
一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
Not exists
MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
Range checked for each
Record(index map:#)
没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
Using filesort
看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using index
列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候
Using temporary
看到这个的时候,查询需要优化了。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
Where used
使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题
不同连接类型的解释(按照效率高低的顺序排序)
system
表只有一行:system表。这是const连接类型的特殊情况
const
表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
eq_ref
在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
ref
这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
range
这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况
index
这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)
ALL
这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
------------------------------
弄明白了explain语法返回的每一项结果,我们就能知道查询大致的运行时间了,如果查询里没有用到索引、或者需要扫描的行过多(比如>=几十万行),那么可以感到明显的延迟。因此需要改变查询方式或者新建索引。
比如没有建索引,或者查询写得不好(没有用到索引列),会造成如下扫描所有两千多万条记录的查询方案(type为"ALL",rows有两千多万),这显然是不可取的,运行的话至少需要一分钟的时间。

而一旦使用了索引,情况会大大改变,如下

这个时候最多扫描2624条记录,使用了索引timeindex,同时extra里有Using index,表明了列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,查询速度也成千上万倍的提升,不到0.1秒。
因此MySql中的explain语法可以帮助我们改写查询,优化表的结构和索引的设置,从而最大地提高查询效率。当然,在大规模数据量时,索引的建立和维护的代价也是很高的,往往需要较长的时间和较大的空间,如果在不同的列组合上建立索引,空间的开销会更大。因此索引最好设置在需要经常查询的字段中。
------------------------------
不仅是MySql,每个主流数据库都有相应的查询分析的功能,比如SQL Server具有强大的图形化分析功能,暂时还没有深入研究,所以就放几张图吧。它不仅能仔细分析出查询的细节,连CPU使用、IO消耗等等都能进行估计


=======http://my.oschina.net/phpnew/blog/151194
优秀的sqlyog, 我深深地感到不安及自责, 盗版用户多年, 多少有点感觉过意不去, 希望富二代们能够支持正版吧.
最近osc还在讨论什么是php大牛, 以前看过帖子, 说得非常贴切. phper, 半个运维工程师, 半个dba, 半个前端设计, 半个js动画, 半个市场营销. 如果你的公司想发展, 请招一个phper, 全能型人才哪里找, 山东可以找蓝翔, osc找phper.
回正题, 作为phper,当然在dba方面也要熟悉, 本人基础知识薄弱, 才疏学浅, 对sqlyog研究未尽深刻, 有错误的地方请指点.

Sqlyog 盗版机制做得还是不错的, 官网都不提供旗舰版下载, 可"优秀"的中国人更为强大, 这不v11.13都已经完美兼容. 有需要的同学上这儿下载: http://www.fenanr.com/read/112140.html

简单的写一句查询语句, 然后点击左上角那个执行, 或者按F12, 结果页将会显示出数据. 如果你使用过旧版, 发现数据显示后, 是可以编辑的. 而新版本抛弃了这个默认设置, 我个人觉得是非常合理的.我们先是想看看, 再决定是否修改.sqlyog这点人性化考虑非常细腻.
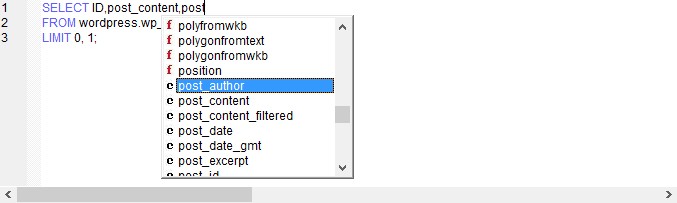
作为优秀的编辑器, 总是需要思考用户所想, 有时我们在编写sql时, 是不是想它提示出字段名呢? sqlyog在这方面做得非常强大. 可以提示字段名, 函数, 关键字,元素, 数据表,
我大概归类了一下: f: 函数. c: 字段名. k:关键字. 余下一种就是数据表. 这对于许多sql编写者来说, 是非常方便的功能.

性能优化才是互联网技术人员的关键, 优化得力可以让速度翻倍, 那我们怎么知道一条sql性能如何呢? sqlyog可以快速为语句检测一次解释. 也就是explain的语法.
执行后配置文件页将显示出结果. 具体怎么看这表, soso吧.

在phpmyadmin中, 我们碰到个问题就是, 我希望可以一次性写多条语句, 可以分开执行. 而不需要清空编辑器. sqlyog就非常智能的解决了这个问题. 你可以在编辑器中写无数条sql, 只要记得结束加分号.
鼠标光标所在的那一条, 将会被执行. 也就是你点到哪, 就执行哪一句. 这样你就可以一条语句延伸N条test语句, 直观地运行查看性能结果. 
无论多少条语句, 编写的智能提示仍然有效.

常用的四条语句, 有时要完全写出来, 还真不是件容易的事, 而在sqlyog中就容易了, 直接界面操作, 或者按快捷键.

系统默认释放的sql, 可能跟你想像中的不太一样, 或许不够直观, 特别在过程,联表, 触发器语句中, 格式化查询后的效果会非常明显.

当在创建临时表语句中, 会碰到许多里里外外的分号, 也就把sql给分隔了, 导致执行失败. sqlyog当然不会犯这种低级错误, 而是需要把语句选择起来执行, 如图片所示.
图片中演示的是一次性将两条语句执行起来. 下面会出现二个结果页. 分别代表每语句的结果. 这功能相信你不会错过.
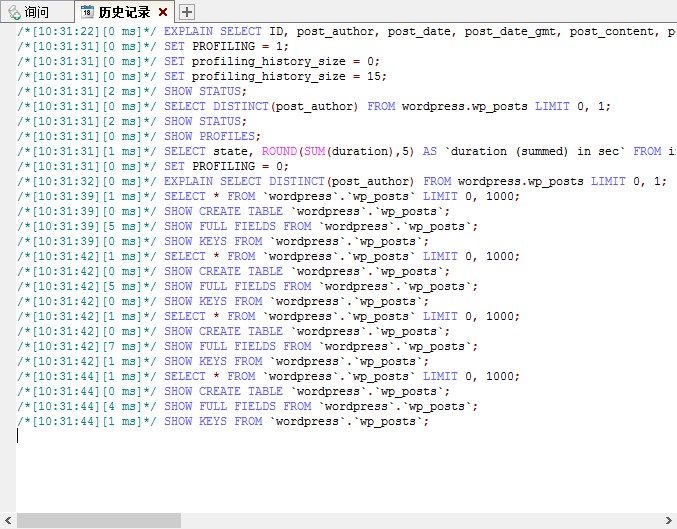
我想,sqlyog 更为强大的是历史记录功能, 非常明了的列表, 执行时间, 执行效率.















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









