







一.Table的逻辑结构
Table也叫SSTable(Sorted String Table),是数据在.sst文件中的存储形式。Table的逻辑结构如下所示,包括存储数据的Block,存储索引信息的Block,存储Filter的Block:
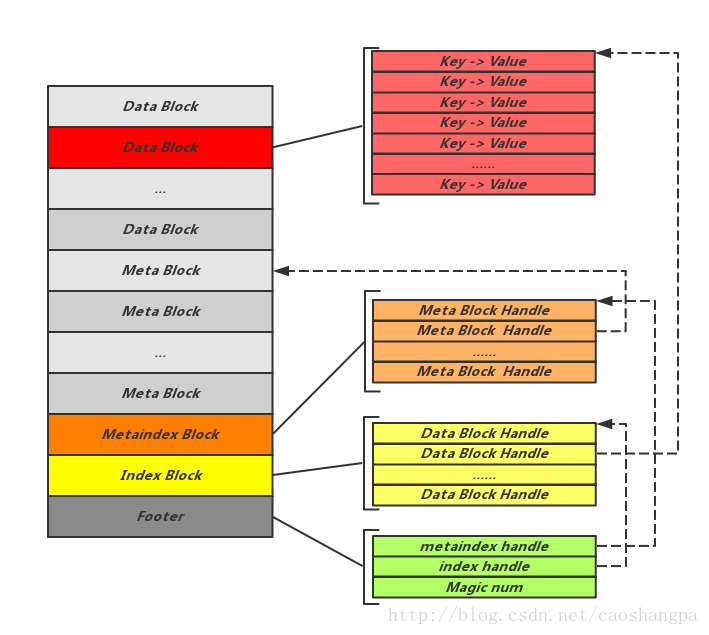
Footer:为于Table尾部,记录指向Metaindex Block的Handle和指向Index Block的Handle。需要说明的是Table中所有的Handle是通过偏移量Offset以及Size一同来表示的,用来指明所指向的Block位置。Footer是SST文件解析开始的地方,通过Footer中记录的这两个关键元信息Block的位置,可以方便的开启之后的解析工作。另外Footer种还记录了用于验证文件是否为合法SST文件的常数值Magicnum。
Index Block:记录Data Block位置信息的Block,其中的每一条Entry指向一个Data Block,其Key值为所指向的Data Block最后一条数据的Key,Value为指向该Data Block位置的Handle。
Metaindex Block:与Index Block类似,由一组Handle组成,不同的是这里的Handle指向的Meta Block。
Data Block:以Key-Value的方式存储实际数据,其中Key定义为:
DataBlock Key := UserKey + SequenceNum + Type
Type := kDelete or kValueMeta Block:比较特殊的Block,用来存储元信息,目前LevelDB使用的仅有对布隆过滤器的存储。写入Data Block的数据会同时更新对应Meta Block中的过滤器。读取数据时也会首先经过布隆过滤器(Bloom Filter)过滤,我看的源码还未用到Bloom Filter,可参考: BloomFilter——大规模数据处理利器。Meta Block的物理结构也与其他Block有所不同:
[filter 0]
[filter 1]
[filter 2]
...
[filter N-1]
[offset of filter 0] : 4 bytes
[offset of filter 1] : 4 bytes
[offset of filter 2] : 4 bytes
...
[offset of filter N-1] : 4 bytes
[offset of beginning of offset array] : 4 bytes
lg(base) : 1 byte关于Block的结构详见:LevelDB源码分析之十二:block
与Block类似,Table的管理也是读写分离的,读取后的遍历查询操作由table类实现,构建则由TableBuilder类实现。
二.Table的构建
leveldb通过TableBuilder类来构建每一个.sst文件,TableBuilder类的成员变量只有一个结构体Rep* rep_,Rep的结构为:
struct TableBuilder::Rep {
Options options;
Options index_block_options;
WritableFile* file;//要生成的.sst文件
uint64_t offset;//累加每个Data Block的偏移量
Status status;
BlockBuilder data_block;//存储KV对的数据块
BlockBuilder index_block;//数据块对应的索引块
std::string last_key;//上一个插入的key值,新插入的key必须比它大,保证.sst文件中的key是从小到大排列的
int64_t num_entries;//.sst文件中存储的所有记录总数。关于记录可以参考LevelDB源码分析之十二:block
bool closed;// 调用Finish()或Abandon()时,closed=true,表示Table构建结束。
bool pending_index_entry;//当一个Data Block被写入到.sst文件时,为true
BlockHandle pending_handle; //BlockHandle只有offset_和size_两个变量,用来记录每个Data Block在.sst文件中的偏移量和大小
std::string compressed_output;//Data Block的block_data字段压缩后的结果
Rep(const Options& opt, WritableFile* f)
: options(opt),
index_block_options(opt),
file(f),
offset(0),
data_block(&options),
index_block(&index_block_options),
num_entries(0),
closed(false),
pending_index_entry(false) {
index_block_options.block_restart_interval = 1;//Index Block的block_data字段中重启点的间隔
}
};1.Add函数
通过Add函数向.sst文件中写入一个Data Block。
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
// 当一个Data Block被写入到磁盘时,为true
if (r->pending_index_entry) {
// 说明到了新的一个Data Block
assert(r->data_block.empty());
// 考虑这两个key"the quick brown fox"和"the who", 进FindShortestSeparator
// 处理后,r->last_key=the r。这样的话r->last_key就大于上一个Data Block的
// 所有key,并且小于后面所有Data Block的key。
r->options.comparator->FindShortestSeparator(&r->last_key, key);
// 将上一个Data Block的偏移和大小编码后作为Value存放到index_block中
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
r->last_key.assign(key.data(), key.size());
r->num_entries++;
r->data_block.Add(key, value);
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
// 如果Data Block的block_data字段大小满足要求,准备写入到磁盘
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}当一个Data Block大小超过设定值(默认为4K)时,执行Flush()操作。
void TableBuilder::Flush() {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return;
assert(!r->pending_index_entry);
WriteBlock(&r->data_block, &r->pending_handle);
if (ok()) {
r->pending_index_entry = true;
// 将Data Block实时写入到磁盘,防止缓存中的file过大
r->status = r->file->Flush();
}
}3.WriteBlock
void TableBuilder::WriteBlock(BlockBuilder* block, BlockHandle* handle) {
// File format contains a sequence of blocks where each block has:
// block_data: uint8[n]
// type: uint8
// crc: uint32
assert(ok());
Rep* r = rep_;
// 返回完整的block_data字段
Slice raw = block->Finish();
Slice block_contents;
CompressionType type = r->options.compression;
// TODO(postrelease): Support more compression options: zlib?
switch (type) {
case kNoCompression:
block_contents = raw;
break;
// 采用Snappy压缩,Snappy是谷歌开源的压缩库
case kSnappyCompression: {
std::string* compressed = &r->compressed_output;
if (port::Snappy_Compress(raw.data(), raw.size(), compressed) &&
compressed->size() < raw.size() - (raw.size() / 8u)) {
block_contents = *compressed;
} else {
// Snappy not supported, or compressed less than 12.5%, so just
// store uncompressed form
// 如果不支持Snappy压缩,或者压缩比小于12.5%,那就使用原始数据
block_contents = raw;
type = kNoCompression;
}
break;
}
}
// 设置Data Block的偏移和该Data Block的block_data字段的大小
// 第一个Data Block的偏移为0
handle->set_offset(r->offset);
handle->set_size(block_contents.size());
r->status = r->file->Append(block_contents);
if (r->status.ok()) {
char trailer[kBlockTrailerSize];
trailer[0] = type;
// 为block_contents添加校验
uint32_t crc = crc32c::Value(block_contents.data(), block_contents.size());
// 为type也添加校验
crc = crc32c::Extend(crc, trailer, 1);
// 将校验码拷贝到trailer的后四个字节
EncodeFixed32(trailer+1, crc32c::Mask(crc));
// 向文件尾部添加压缩类型和校验码,这样一个完整的Block Data诞生
r->status = r->file->Append(Slice(trailer, kBlockTrailerSize));
if (r->status.ok()) {
// 偏移应该包括压缩类型和校验码的大小
r->offset += block_contents.size() + kBlockTrailerSize;
}
}
r->compressed_output.clear();
// 重置block
block->Reset();
}4.Finish函数
Status TableBuilder::Finish() {
Rep* r = rep_;
// 为何要调用一次Flush,是因为调用Finish的时候,
// block_data不一定大于等于block_size,所以要调用Flush
// 将这部分block_data写入到磁盘
Flush();
assert(!r->closed);
r->closed = true;
BlockHandle metaindex_block_handle;
BlockHandle index_block_handle;
if (ok()) {
// 我看的源码不支持Meta Block,这里的meta_index_block也没有实际作用
BlockBuilder meta_index_block(&r->options);
// metaindex_block_handle记录了Meta Index Block的偏移和大小
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
if (ok()) {
// 最后一个Data_Block,无法进行r->last_key和key的比较,
// 所以只能调用FindShortSuccessor,直接取一个比r->last_key大的key
if (r->pending_index_entry) {
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
// index_block_handle记录了Index Block的偏移和大小
WriteBlock(&r->index_block, &index_block_handle);
}
if (ok()) {
// 组建Footer,并添加到文件结尾
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}metaindex_handle: char[p]; // Block handle for metaindex
index_handle: char[q]; // Block handle for index
padding: char[40-p-q]; // 0 bytes to make fixed length
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // == 0xdb4775248b80fb57注意,只在Finish的时候才调用WriteBlock给Index Block添加了type和crc,但是对于Data Block,每次写入到磁盘都会调用一次WriteBlock。
Mate Index Block、Index Block和Footer应该是在WritableFile析构时被写入到磁盘的,WritableFile析构时会调用其Flush函数。
关于WritableFile,详见:LevelDB源码分析之九:env
三.Table的解析
leveldb通过Table类来解析每一个.sst文件,Table类的成员变量也只有一个结构体Rep* rep_,Rep的结构为:
struct Table::Rep {
~Rep() {
delete index_block;
}
Options options;
Status status;
RandomAccessFile* file;
uint64_t cache_id;//block cache的ID,用于组建block cache结点的key
BlockHandle metaindex_handle; //用于存储从footer中解析出的metaindex_handle
Block* index_block;
};Open函数比较简单,就是打开一个本地.sst文件,然后从文件尾部读取footer,根据footer中的index_handle,调用ReadBock函数读取index_block。接着对结构体Rep赋值,并将其当做参数传给Table的构造函数。
Status Table::Open(const Options& options,
RandomAccessFile* file,
uint64_t size,
Table** table) {
*table = NULL;
if (size < Footer::kEncodedLength) {
return Status::InvalidArgument("file is too short to be an sstable");
}
char footer_space[Footer::kEncodedLength];
Slice footer_input;
Status s = file->Read(size - Footer::kEncodedLength, Footer::kEncodedLength,
&footer_input, footer_space);
if (!s.ok()) return s;
Footer footer;
s = footer.DecodeFrom(&footer_input);
if (!s.ok()) return s;
// Read the index block
Block* index_block = NULL;
if (s.ok()) {
s = ReadBlock(file, ReadOptions(), footer.index_handle(), &index_block);
}
if (s.ok()) {
// We've successfully read the footer and the index block: we're
// ready to serve requests.
Rep* rep = new Table::Rep;
rep->options = options;
rep->file = file;
rep->metaindex_handle = footer.metaindex_handle();
rep->index_block = index_block;
rep->cache_id = (options.block_cache ? options.block_cache->NewId() : 0);
*table = new Table(rep);
} else {
if (index_block) delete index_block;
}
return s;
}// 根据BlockHandle从file中读取block_data,放在*block中
Status ReadBlock(RandomAccessFile* file,
const ReadOptions& options,
const BlockHandle& handle,
Block** block) {
*block = NULL;
// n是block_data的大小
size_t n = static_cast<size_t>(handle.size());
// n + kBlockTrailerSize就是block_data+type+crc的大小
char* buf = new char[n + kBlockTrailerSize];
Slice contents;
// 根据Block的偏移读取指定内容
Status s = file->Read(handle.offset(), n + kBlockTrailerSize, &contents, buf);
if (!s.ok()) {
delete[] buf;
return s;
}
if (contents.size() != n + kBlockTrailerSize) {
delete[] buf;
return Status::Corruption("truncated block read");
}
// 从contents解析出crc并校验,可以通过options.verify_checksums配置不校验
const char* data = contents.data();
if (options.verify_checksums) {
const uint32_t crc = crc32c::Unmask(DecodeFixed32(data + n + 1));
const uint32_t actual = crc32c::Value(data, n + 1);
if (actual != crc) {
delete[] buf;
s = Status::Corruption("block checksum mismatch");
return s;
}
}
// data[n]实际上就是type字段
switch (data[n]) {
case kNoCompression:
//
if (data != buf) {
// File implementation gave us pointer to some other data.
// Copy into buf[].
memcpy(buf, data, n + kBlockTrailerSize);
}
// Ok
break;
// 我用的源码比较老,不涉及Snappy压缩
case kSnappyCompression: {
size_t ulength = 0;
if (!port::Snappy_GetUncompressedLength(data, n, &ulength)) {
delete[] buf;
return Status::Corruption("corrupted compressed block contents");
}
char* ubuf = new char[ulength];
if (!port::Snappy_Uncompress(data, n, ubuf)) {
delete[] buf;
delete[] ubuf;
return Status::Corruption("corrupted compressed block contents");
}
delete[] buf;
buf = ubuf;
n = ulength;
break;
}
default:
delete[] buf;
return Status::Corruption("bad block type");
}
*block = new Block(buf, n); // Block takes ownership of buf[]
return Status::OK();
}NewIterator用于创建Table的迭代器,此迭代器是一个双层迭代器,详见:LevelDB源码分析之十四:TwoLevelIterator
Iterator* Table::NewIterator(const ReadOptions& options) const {
return NewTwoLevelIterator(
rep_->index_block->NewIterator(rep_->options.comparator),
&Table::BlockReader, const_cast<Table*>(this), options);
}4.BlockReader
// arg:Table的指针
// index_value:Data Block中block_data字段的迭代器的value值,
// 也就是Data Block的偏移和该Data Block的block_data字段大小
// 编码后的结果
// return:Data Block中block_data字段的迭代器
Iterator* Table::BlockReader(void* arg,
const ReadOptions& options,
const Slice& index_value) {
Table* table = reinterpret_cast<Table*>(arg);
Cache* block_cache = table->rep_->options.block_cache;
Block* block = NULL;
Cache::Handle* cache_handle = NULL;
BlockHandle handle;
Slice input = index_value;
// 解码得到Data Block的偏移和该Data Block的block_data字段大小
Status s = handle.DecodeFrom(&input);
if (s.ok()) {
// 1.如果Block Cache不为NULL,先去Block Cache中查找结点,
// 如果没找到,再去文件中读取Data Block的block_data字段,
// 并将该block_data插入到Block Cache
// 2.如果Block Cache为NULL,直接去文件里读
if (block_cache != NULL) {
// 组建key
char cache_key_buffer[16];
EncodeFixed64(cache_key_buffer, table->rep_->cache_id);
EncodeFixed64(cache_key_buffer+8, handle.offset());
Slice key(cache_key_buffer, sizeof(cache_key_buffer));
cache_handle = block_cache->Lookup(key);
if (cache_handle != NULL) {
block = reinterpret_cast<Block*>(block_cache->Value(cache_handle));
} else {
s = ReadBlock(table->rep_->file, options, handle, &block);
if (s.ok() && options.fill_cache) {
cache_handle = block_cache->Insert(
key, block, block->size(), &DeleteCachedBlock);
}
}
} else {
s = ReadBlock(table->rep_->file, options, handle, &block);
}
}
Iterator* iter;
// 如果block读取成功
if (block != NULL) {
iter = block->NewIterator(table->rep_->options.comparator);
// iter->RegisterCleanup函数实现会有点绕,被它注册的函数会在iter析构时被调用
// 如果block_cache为NULL,说明block不在缓存中,iter析构时调用DeleteBlock删除这个block。
// 否则调用ReleaseBlock使block_cache的cache_handle结点减少一个引用计数
if (cache_handle == NULL) {
iter->RegisterCleanup(&DeleteBlock, block, NULL);
} else {
iter->RegisterCleanup(&ReleaseBlock, block_cache, cache_handle);
}
} else {
// 否则返回错误
iter = NewErrorIterator(s);
}
return iter;
}这个函数用于估算key值所在记录的偏移,不准确。代码中的注释是我的个人理解,也不知对不对。只有看到了调用该函数的代码,才能更深入的理解。
// 估算key的偏移,不准确
uint64_t Table::ApproximateOffsetOf(const Slice& key) const {
Iterator* index_iter =
rep_->index_block->NewIterator(rep_->options.comparator);
index_iter->Seek(key);
uint64_t result;
if (index_iter->Valid()) {
BlockHandle handle;
Slice input = index_iter->value();
Status s = handle.DecodeFrom(&input);
//
if (s.ok()) {
// result比key的真实偏移小
result = handle.offset();
} else {
// Strange: we can't decode the block handle in the index block.
// We'll just return the offset of the metaindex block, which is
// close to the whole file size for this case.
// result比key的真实偏移大
result = rep_->metaindex_handle.offset();
}
} else {
// key is past the last key in the file. Approximate the offset
// by returning the offset of the metaindex block (which is
// right near the end of the file).
// result比key的真实偏移小
result = rep_->metaindex_handle.offset();
}
delete index_iter;
return result;
}
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











