







Hive概述
Apache Hive是构建在Hadoop之上的数据仓库,支持通过SQL接口查询分析存储在Hadoop中的数据。
在Hive出现之前,数据分析人员需要编写MapReduce作业分析Hadoop中的数据,这种方式繁琐低效,对数据分析人员不友好,因为数据分析人员大部分比较精通SQL,但是编程功底较浅。
在这种背景下,2007年Facebook在论文Hive-A Warehousing Solution Over a Map-Reduce
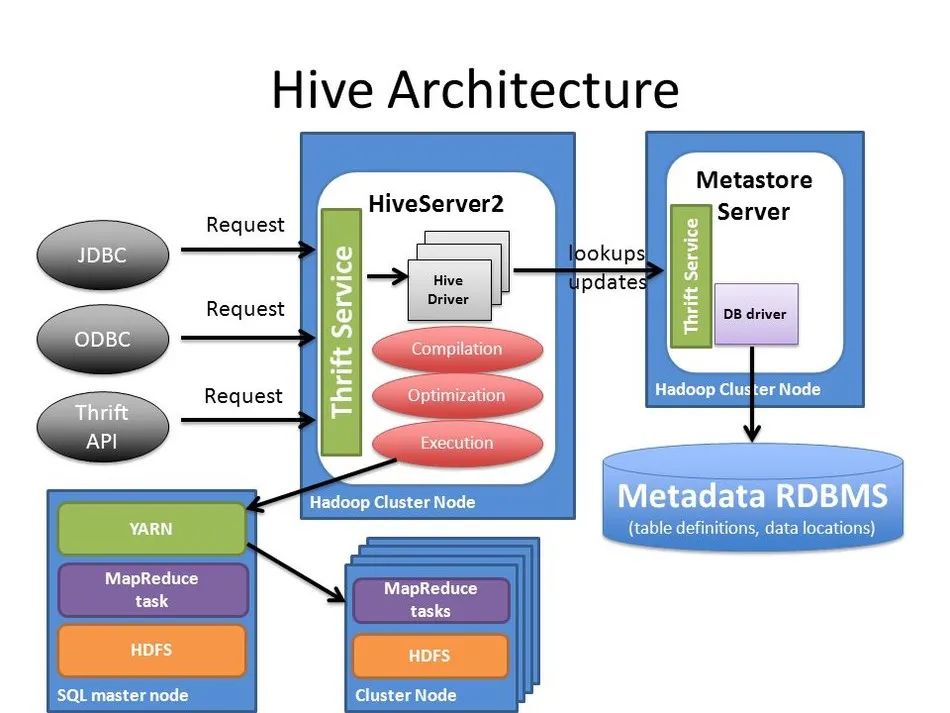
中阐述了Hive的架构:Hive提供了一个SQL解析引擎hiveserver,客户端向hiveserver发送SQL请求,hiveserver将SQL翻译成MapReduce作业并提交到Hadoop集群上运行,最终将运行结果返回给客户端。
客户端一般使用Hive的JDBC驱动,连接Hiveserver2,Hiveserver2是采用Thrift RPC框架实现的JDBC服务端。客户端将SQL语句发送给Hiveserver2,Hiveserver2进行SQL的解析、编译、优化,这个过程中Hiveserver2会跟Hive Metastore服务通信以得到数据库表的元数据,Metastore服务会将数据库的元数据信息存储到数据库中。最终Hiveserver2将SQL编译为MapReduce作业运行在MapReduce/Tez/Spark分布式计算引擎上。
数据脱敏概述
数据脱敏,指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。这样就可以在开发、测试和其它非生产环境以及外包环境中安全地使用脱敏后的真实数据集
百度百科
数据脱敏系统,按照使用场景的不同,可以分为动态脱敏
系统和静态脱敏
系统。
动态脱敏系统一般作为代理,部署在应用系统和数据库之间,应用连接动态脱敏系统,动态脱敏连接数据库,动态脱敏一般通过SQL改写
或者结果集改写
方式遮蔽、仿真、替换敏感数据,从而达到去标识化的目的。
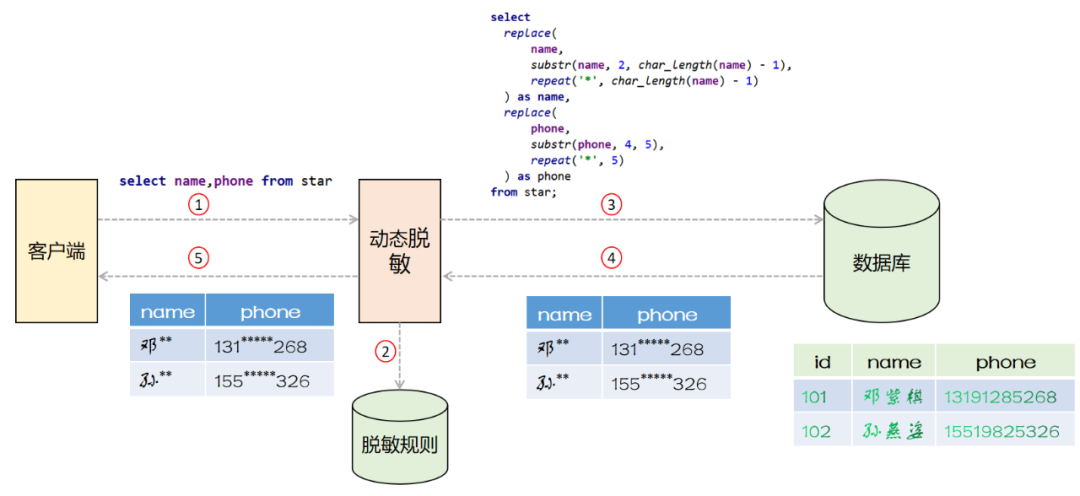
采用SQL改写
方式实现的动态脱敏系统的架构如下图所示
动态脱敏系统作为代理坐落在客户端和数据库之间,客户端向动态脱敏系统发送SQL语句
动态脱敏系统拦截网络流量,解析数据库协议,得到SQL语句,最后查询脱敏规则库
动态脱敏根据脱敏规则改写SQL语句并将改写后的SQL语句发送给数据库
数据库执行改写后的SQL语句并返回
客户端拿到脱敏后的数据
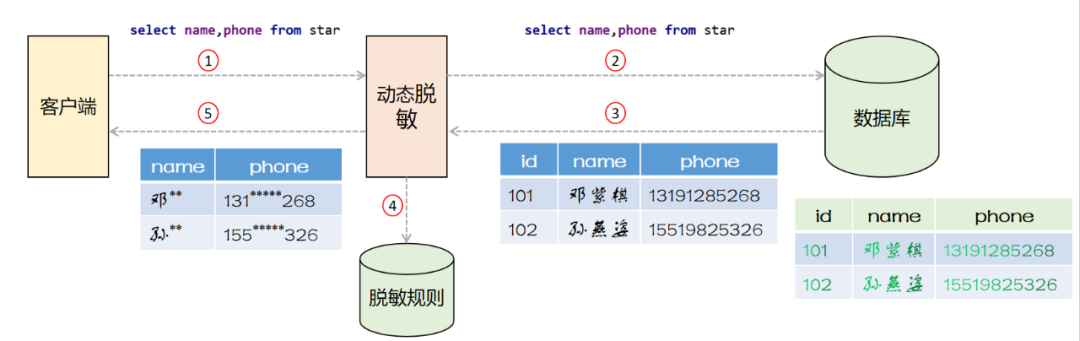
采用结果集改写
方式实现的动态脱敏系统的架构如下图所示
动态脱敏系统作为代理坐落在客户端和数据库之间,客户端向动态脱敏系统发送SQL语句
动态脱敏系统将SQL语句原样转发给数据库
数据库执行SQL语句并返回结果集给动态脱敏系统
动态脱敏系统查询脱敏规则库,改写结果集
客户端拿到脱敏后的数据
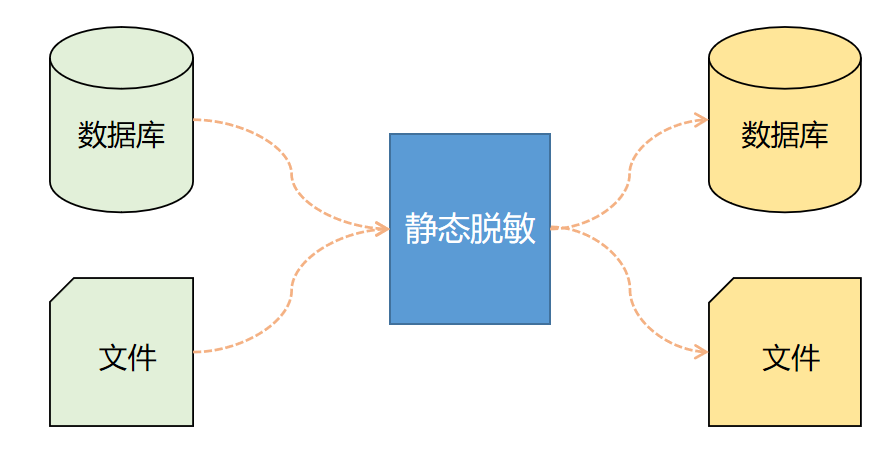
静态脱敏系统,一般不会坐落在应用和数据库之间,而是作为单独的系统存在。静态脱敏一般应用于离线场景,比如测试人员需要一批测试数据,这种场景下只需在静态脱敏系统中新建脱敏任务,指定源数据库/文件的信息和目标数据库/文件的信息,指定要脱敏的源表和限定条件,静态脱敏系统从源端读取数据,应用脱敏规则后,将脱敏后的数据存储到目标端,整个过程要保证脱敏前的原始数据不落地。
安装Hive
下面简单介绍Hive的安装部署,省略了部分排错过程,排错过程读者可以亲自体验,以加深理解。
-
Hive Metastore服务需要将Hive的元数据存储到数据库中,自行安装mariadb赋予权限
create database hive; grant all on *.* to root@'%' identified by 'root'; flush privileges; -
下载hive并进行解压
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz tar zxvf apache-hive-3.1.2-bin.tar.gz -
进入
apache-hive-3.1.2-bin
目录,准备配置文件cp hive-env.sh.template hive-env.sh mv hive-default.xml.template hive-default.xml mv hive-log4j2.properties.template hive-log4j2.properties touch hive-site.xml -
在/etc/profile新增环境变量
export HIVE_HOME=/software/apache-hive-3.1.2-bin export PATH=$PATH:$HIVE_HOME/bin -
修改
$HIVE_HOME/conf
目录下的hive-env.sh
新增如下内容HADOOP_HOME=/software/hadoop-3.2.2 -
将MySQL的JDBC驱动
mysql-connector-java-5.1.47.jar放到$HIVE_HOME/lib目录下 -
修改
$HIVE_HOME/conf目录下的hive-site.xml,新增如下内容<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop02.bigdata.com:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop03.bigdata.com</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop03.bigdata.com:9083</value> </property> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <property> <name>hive.execution.engine</name> <value>mr</value> </property> </configuration> -
修改
$HADOOP_HOME/etc/hadoop目录下的core-site.xml
新增如下内容,分发到集群各个节点,并重启hadoop<property> <name>hadoop.proxyuser.hive.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hive.groups</name> <value>*</value> </property> -
新建
hive
用户,后续使用hive
用户启动hive的hiveserver2和metastore进程useradd hive -g hadoop passwd hive chown -R hive:hadoop apache-hive-3.1.2-bin -
切换到
hive
用户,初始化metastore数据库su - hive bin/schematool -dbType mysql -initSchema -
后台启动hive的
hiveserver2和metastore服务nohup bin/hive --service metastore > logs/metastore.log 2>&1 & nohup bin/hive --service hiveserver2 > logs/hiveserver2.log 2>&1 &
安装ranger-hive插件
-
将编译好的
ranger-2.1.0-hive-plugin.tar.gz解压tar zxvf ranger-2.1.0-hive-plugin.tar.gz -
修改
ranger-2.1.0-hive-plugin目录下的install.properties文件,新增POLICY_MGR_URL=http://hadoop02.bigdata.com:6080 REPOSITORY_NAME=hive COMPONENT_INSTALL_DIR_NAME=/software/apache-hive-3.1.2-bin/ -
安装ranger的hive插件
./enable-hive-plugin.sh -
重启hive并登陆到ranger-admin管理控制台中

-
在ranger-admin中新增hive服务,填写如下必要信息
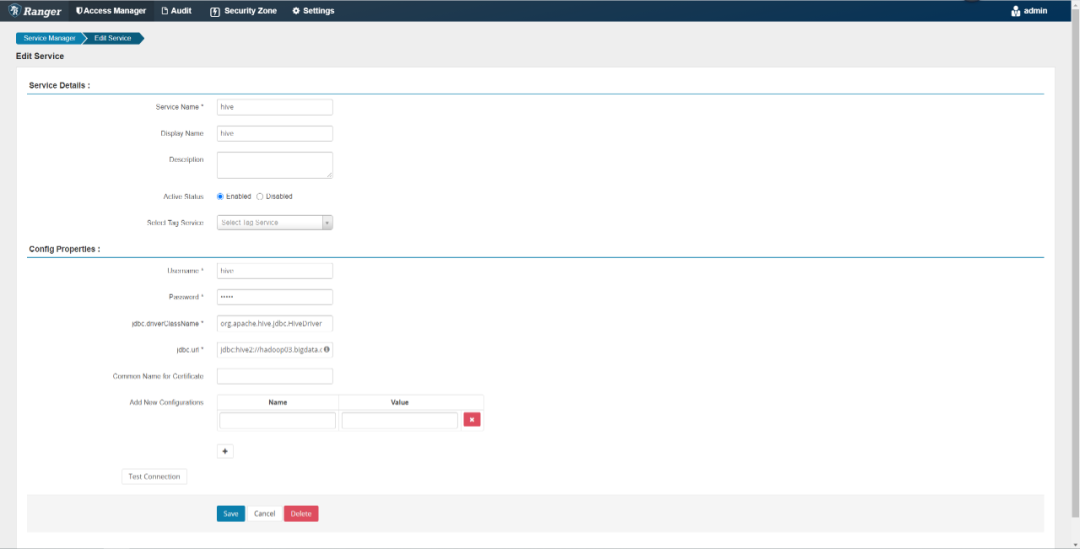
-
点击
Test Connection
按钮,确定可以连接成功
Hive脱敏实验
-
使用
beeline
通过jdbc连接hiveserver2beeline -u jdbc:hive2://hadoop03.bigdata.com:10000 -n hive -
新建测试数据库、数据表,并插入测试数据
create database talkingbigdata; use talkingbigdata; create table employee(id int,name string,salary double) stored as orc tblproperties('transactional'='true'); insert into employee values(4,'tomtomtomtomtom',100),(5,'jackjackjackjack',200),(6,'lilylilylilylily',400); -
登陆
ranger-admin
,点击hive
服务,打开的页面的Masking
页签可以配置脱敏规则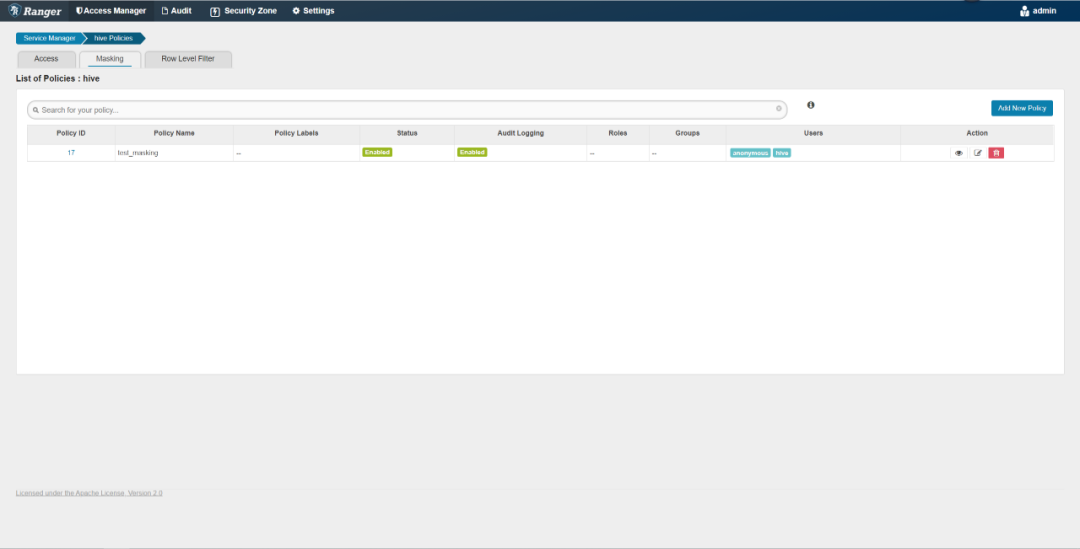
-
点击
Add New Policy
,在打开的页面中新增脱敏规则,对talkingbigdata数据库的employee表的name字段进行脱敏,只显示前四位,其余位用星号代替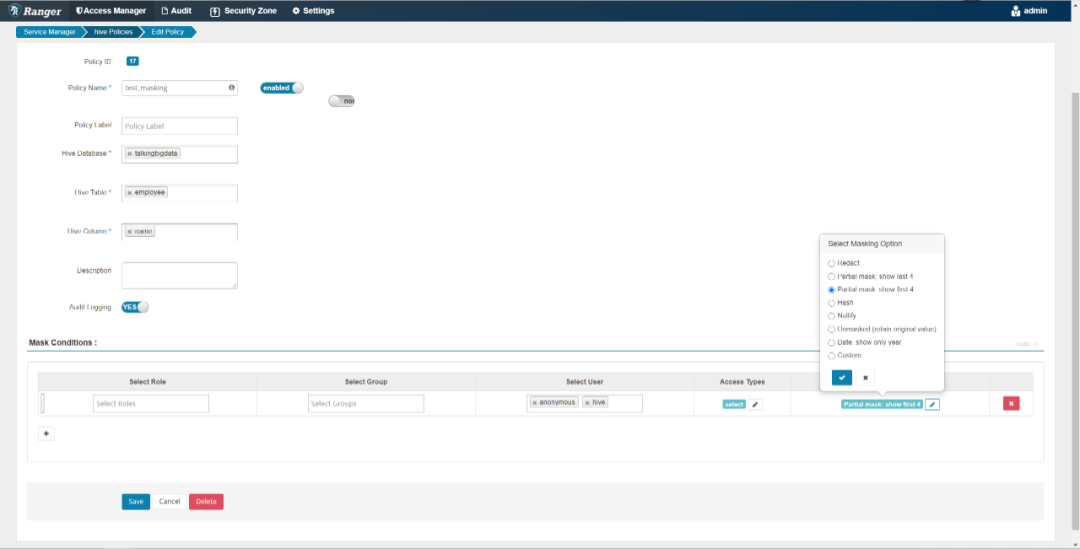
从上图中可以看出ranger针对hive的脱敏,可以针对特定的数据库、表、字段设定脱敏规则,ranger支持的脱敏规则还是比较少的,包括:除后4位外全部用星号替换、除前4位外全部用星号代替、哈希、日期只显示年。此外,还支持自定义脱敏算法。
-
在
beeline
中查询数据,验证是否可以正常脱敏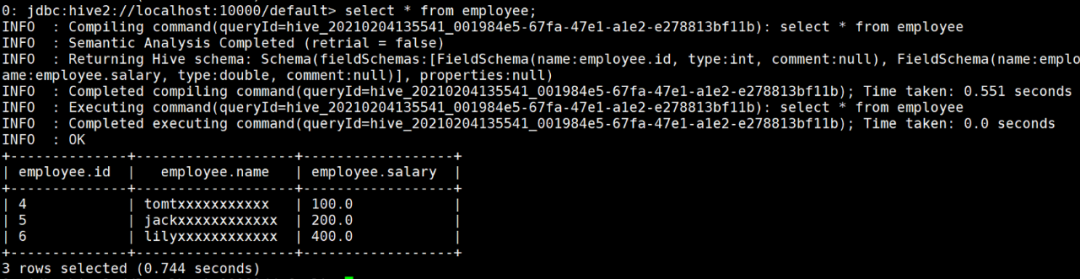
-
实验成功。当然还有很多细节有待发现,希望爱探索的你,接下来自己去探索吧。















 4686
4686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









