






超详细正则表达式总结
在线练习
RegexOne (https://regexone.com/): 这个网站提供了一个互动的学习平台,逐步教授正则表达式的基础知识和语法。它结合了理论和实践,通过练习来帮助您巩固所学内容。 
Regular-Expressions.info (https://www.regular-expressions.info/): 这个网站是一个全面的正则表达式教程和参考指南。它提供了详细的解释和示例,涵盖了各种正则表达式的用法和技巧。
Regex101 (https://regex101.com/): 这是一个交互式的正则表达式测试和调试工具。您可以在网站上编写正则表达式,并立即看到匹配结果。它还提供了详细的解释和调试功能,帮助您理解和调试复杂的正则表达式。 
RegExr (https://regexr.com/): 这是一个在线的正则表达式测试和学习工具。它提供了一个可视化的界面,让您可以直观地构建和测试正则表达式。它还提供了一个正则表达式参考指南和常见用例的示例。
Learn Regular Expressions (https://www.learnregex.net/): 这个网站提供了一个逐步的正则表达式教程,从基础知识到高级技巧都有涵盖。它以简洁明了的方式解释了正则表达式的各个方面,并提供了练习来帮助您巩固所学内容。
正则介绍
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),可以用来描述和匹配字符串的特定模式。
正则表达式是一种用于模式匹配和搜索文本的工具。
正则表达式提供了一种灵活且强大的方式来查找、替换、验证和提取文本数据。
正则表达式可以应用于各种编程语言和文本处理工具中,如 JavaScript、Python、Java、Perl 等。
为什么使用正则表达式?
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。
通过使用正则表达式,可以:
测试字符串内的模式。 例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。 替换文本。 可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。 基于模式匹配从字符串中提取子字符串。 可以查找文档内或输入域内特定的文本。 例如,您可能需要搜索整个网站,删除过时的材料,以及替换某些 HTML 格式标记。在这种情况下,可以使用正则表达式来确定在每个文件中是否出现该材料或该 HTML 格式标记。此过程将受影响的文件列表缩小到包含需要删除或更改的材料的那些文件。然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换标记。
正则表达式语法
正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。
正则表达式可以在文本中查找、替换、提取和验证特定的模式。
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)。
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次或1次)。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
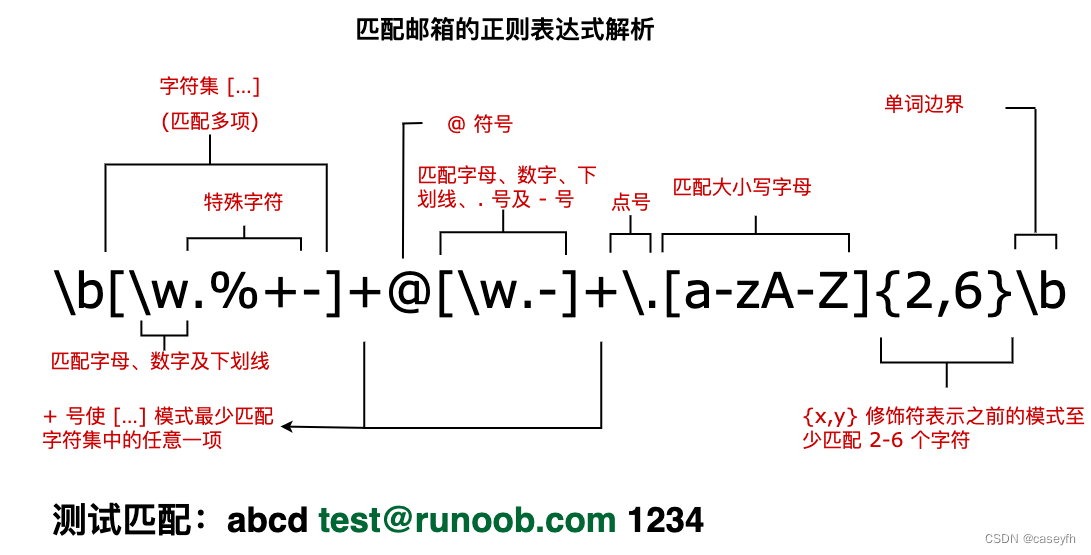
正则表达式的模式
正则表达式的模式可以包括以下内容:
| 字面值字符(普通字符) | 例如字母、数字、空格等,可以直接匹配它们自身。 |
|---|---|
| 特殊字符 | 例如点号 .、星号 *、加号 +、问号 ? 等,它们具有特殊的含义和功能。 |
| 字符类 | 用方括号 [ ] 包围的字符集合,用于匹配方括号内的任意一个字符。 |
| 元字符 | 例如 \d、\w、\s 等,用于匹配特定类型的字符,如数字、字母、空白字符等。 |
| 量词 | 例如 {n}、{n,}、{n,m} 等,用于指定匹配的次数或范围。 |
| 边界符号 | 例如 ^、$、\b、\B 等,用于匹配字符串的开头、结尾或单词边界位置。 |
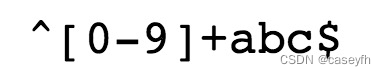
^ 为匹配输入字符串的开始位置。
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
abc匹配字母𝑎𝑏𝑐并以𝑎𝑏𝑐结尾,匹配字母abc并以abc结尾, 为匹配输入字符串的结束位置。
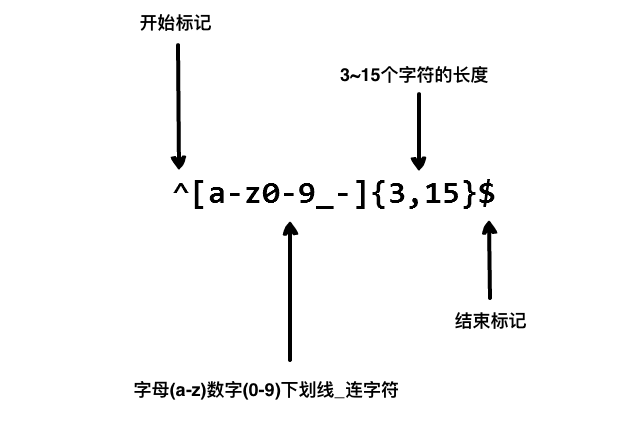
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符 -,并设置用户名的长度,我们就可以使用以下正则表达式来设定。
字符匹配
| 普通字符 | 普通字符按照字面含义进行匹配,是什么匹配什么 | 例如匹配字母 "a" 将匹配到文本中的 "a" 字符。 |
|---|---|---|
| 元字符 | 元字符具有特殊的含义 | 例如 \d 匹配任意数字单字符,\w 匹配任意字母数字单字符,. 匹配任意单字符(除了换行符)等。 |
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
[ABC] 匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。
[^ABC] 匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字符。
[A-Z] [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。
. 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。
[\s\S] 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
\w 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 \,runo*ob 匹配字符串 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特殊字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 正则表达式分组和捕获,要匹配这些(和),标记一个子表达式的开始和结束位置,子表达式可以获取供以后使用请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。等效{0,} |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。等效{1,} |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。等效{0,1} |
| [] | 标记一个中括号表达式的开始,一个字符组合簇。要匹配 [和],请使用 \[和\]。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, '\n' 匹配换行符。匹配\,用\\;反向引用时,用\1对应第一个分组内容,\2对应第二个分组内容,以此类推。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \.。等效[^\n] |
| ^ | 匹配输入字符串的开始位置,在中括号表不取字符组合。要匹配 ^ 字符本身,请使用 \^。 |
| {} | 标记限定符表达式的开始。要匹配 {和},请使用\{和\}。 |
| | | 指明两项之间的一个选择,用于指定多个模式的选择。要匹配|,使用|。 |
*和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配
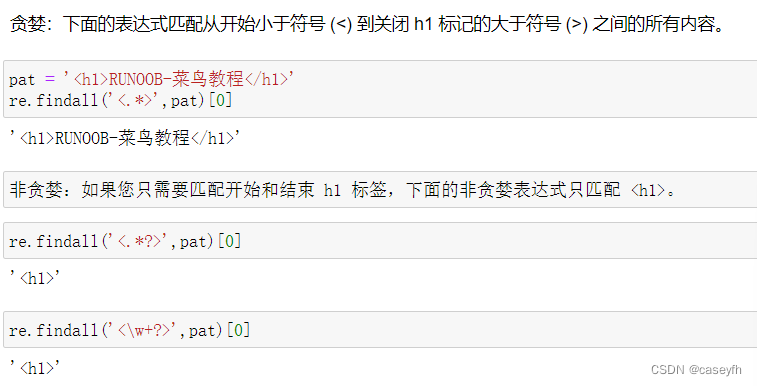
通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从"贪婪"表达式转换为"非贪婪"表达式或者最小匹配。 贪婪就是会匹配到很多,非贪婪是只匹配到所需要的
匹配0到36的数字正则表达式:[12][0-9]|3[0-6]|[0-9],一般没有单独去匹配数字,加上预查可以判断和筛选以及检索,有没有36以内的内容
ss = ''
for i in range(100):
ss = ss + str(i) + "这是"+str(i)+"个测试"
#匹配30-70之间的长度为7的内容
re.findall('(?<=[3-6][0-9]|70).{7}(?=\d+)',ss)
输出:
['这是30个测试',
'这是31个测试',
'这是32个测试',
'这是33个测试',
……
]
字符类
| [] | 匹配括号内的任意一个字符 | 例如,[abc] 匹配单个字符 "a"、"b" 或 "c"。 |
|---|---|---|
| [^] | 匹配除了括号内的字符以外的任意一个字符,这里的'^'表示不取 | 例如,[^abc] 不会匹配单个字符 "a"、"b" 或 "c"。 |
字符簇
在 INTERNET 的程序中,正则表达式通常用来验证用户的输入。当用户提交一个 FORM 以后,要判断输入的电话号码、地址、EMAIL 地址、信用卡号码等是否有效,用普通的基于字面的字符是不够的。
所以要用一种更自由的描述我们要的模式的办法,它就是字符簇。要建立一个表示所有元音字符的字符簇,就把所有的元音字符放在一个方括号里:
[AEIOUaeiou]
这个模式与任何元音字符匹配,但只能表示一个字符。用连字号可以表示一个字符的范围: [a-z] // 匹配所有的小写字母 [A-Z] // 匹配所有的大写字母 [a-zA-Z] // 匹配所有的字母 [0-9] // 匹配所有的数字 [0-9\.\-] // 匹配所有的数字,句号和减号 [ \f\r\t\n] // 匹配所有的白字符,换页符、回车符、制表符、换行符
同样的,这些也只表示一个字符,这是一个非常重要的。如果要匹配一个由一个小写字母和一位数字组成的字符串,比如 "z2"、"t6" 或 "g7",但不是 "ab2"、"r2d3" 或 "b52" 的话,用这个模式:
^[a-z][0-9]$
尽管 [a-z] 代表 26 个字母的范围,但在这里它只能与第一个字符是小写字母的字符串匹配。
前面曾经提到^表示字符串的开头,但它还有另外一个含义。当在一组方括号里使用 ^ 时,它表示"非"或"排除"的意思,常常用来剔除某个字符。还用前面的例子,我们要求第一个字符不能是数字:
^[^0-9][0-9]$
这个模式与 "&5"、"g7"及"-2" 是匹配的,但与 "12"、"66" 是不匹配的。
下面是几个排除特定字符的例子:
[^a-z] //除了小写字母以外的所有字符
[^\\\/\^] //除了(\)(/)(^)之外的所有字符
[^\"\'] //除了双引号(")和单引号(')之外的所有字符
特殊字符 .(点,句号)在正则表达式中用来表示除了"新行"之外的所有字符。所以模式 ^.5$ 与任何两个字符的、以数字5结尾和以其他非"新行"字符开头的字符串匹配。模式 . 可以匹配任何字符串,换行符(\n、\r)除外。
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| \cx | 匹配由x指明的控制字符 x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符 | 例如, \cM 匹配一个 Control-M 或回车符 |
|---|---|---|
| \f | 匹配一个换页符 | 等价于 \x0c 和 \cL |
| \n | 匹配一个换行符 | 等价于 \x0a 和 \cJ |
| \r | 匹配一个回车符 | 等价于 \x0d 和 \cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等 | 等价于 [ \f\n\r\t\v]。 注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符 | 等价于 [^ \f\n\r\t\v] |
| \t | 匹配一个制表符 | 等价于 \x09 和 \cI |
| \v | 匹配一个垂直制表符 | 等价于 \x0b 和 \cK |
元字符
| \d | 匹配一个数字字符。等价于 [0-9] |
|---|---|
| \D | 匹配一个非数字字符。等价于 [^0-9] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
| \w | 匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_] |
| \W | 匹配任何非单词字符。等价于 [^A-Za-z0-9_] |
量词-限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。n和m为非负整数。
| * | 匹配前面的模式零次或多次。 | 等效{0,} |
|---|---|---|
| + | 匹配前面的模式一次或多次 | 等效{1,} |
| ? | 匹配前面的模式零次或一次。 | 等效{0,1} |
| {n},n为非负整数 | 匹配前面的模式恰好 n 次。 | # |
| {n,} | 匹配前面的模式至少 n 次。 | # |
| {n,m},n和m为非负整数 | 匹配前面的模式至少 n 次且不超过 m 次。左闭右开 | # |
确定重复出现
到现在为止,你已经知道如何去匹配一个字母或数字,但更多的情况下,可能要匹配一个单词或一组数字。一个单词有若干个字母组成,一组数字有若干个单数组成。跟在字符或字符簇后面的花括号({})用来确定前面的内容的重复出现的次数。
| 字符簇 | 描述 |
|---|---|
| ^[a-zA-Z_]$ | 所有的字母和下划线 |
| ^[[:alpha:]]{3}$ | 所有的3个字母的单词 |
| ^a$ | 字母a |
| ^a{4}$ | aaaa |
| ^a{2,4}$ | aa,aaa或aaaa |
| ^a{1,3}$ | a,aa或aaa |
| ^a{2,}$ | 包含多个两个a的字符串 |
| ^a{2,} | aardvark和aaab,但apple不行 a{2,} 如:baad和aaa,但Nantucket不行 |
| a{2,} | baad和aaa,但Nantucket不行 |
| \t{2} | 两个制表符 |
| .{2} | 所有的两个字符 |
我们可以把模式扩展到更多的单词或数字:
^[a-zA-Z0-9_]{1,}$ // 所有包含一个以上的字母、数字或下划线的字符串
^[1-9][0-9]{0,}$ // 所有的正整数
^-{0,1}[0-9]{1,}$ // 所有的整数
^[-]?[0-9]+\.?[0-9]+$ // 所有的浮点数
最后一个例子不太好理解,是吗?这么看吧:以一个可选的负号 ([-]?) 开头 (^)、跟着1个或更多的数字([0-9]+)、和一个小数点(\.)再跟上1个或多个数字([0-9]+),并且后面没有其他任何东西($)。下面你将知道能够使用的更为简单的方法。
^[-]?[0-9]+\.?[0-9]+$等效于^[-]{0,1}[0-9]{0,}\.[0-9]{1,}$
定位符-边界匹配
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
| ^ | 匹配字符串的开头,如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 | ^a可以匹配ab,不能匹配ba |
|---|---|---|
| $ | 匹配字符串的结尾,如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 | ^b可以匹配ba,不能匹配ab |
| \b | 匹配单词边界,即字与空格间的位置。 | \b\w+\b可以匹配Hello完整单词 |
| \B | 匹配非单词边界 | \B\w+\B匹配Hello的ell |
注意事项
起始和结束定位符
不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
-
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆,即是不要在中括号使用^去匹配开始位置。
-
若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。
若要在搜索章节标题时使用定位点,下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字,并且出现在行首:
/^Chapter [1-9][0-9]{0,1}/
真正的章节标题不仅出现行的开始处,而且它还是该行中仅有的文本。它既出现在行首又出现在同一行的结尾。下面的表达式能确保指定的匹配只匹配章节而不匹配交叉引用。通过创建只匹配一行文本的开始和结尾的正则表达式,就可做到这一点。
/^Chapter [1-9][0-9]{0,1}$/
单词边界符
匹配单词边界稍有不同,但向正则表达式添加了很重要的能力。单词边界是单词和空格之间的位置。非单词边界是任何其他位置。下面的表达式匹配单词 Chapter 的开头三个字符,因为这三个字符出现在单词边界后面:
/\bCha/ \b 字符的位置是非常重要的。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项\bCha。如果它位于字符串的结尾,它在单词的结尾处查找匹配项ter/b。
例如,下面的表达式匹配单词 Chapter 中的字符串 ter,因为它出现在单词边界的前面:
/ter\b/
下面的表达式匹配 Chapter 中的字符串 apt,但不匹配 aptitude 中的字符串 apt:
/\Bapt/
字符串 apt 出现在单词 Chapter 中的非单词边界处,但出现在单词 aptitude 中的单词边界处。对于 \B 非单词边界运算符,不可以匹配单词的开头或结尾,如果是下面的表达式,就不匹配 Chapter 中的 Cha:
\BCha
分组(选择)、捕获和可选标志
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)。
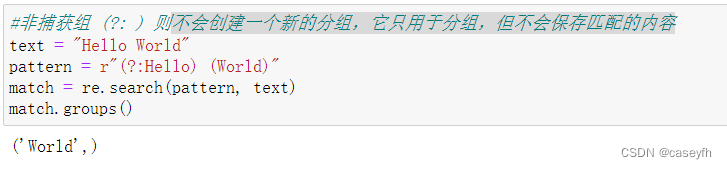
但用圆括号会有一个副作用,使相关的匹配会被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用,匹配的内容就不会被缓存。
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?!,这两个还有更多的含义,前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
| () | 用于分组和捕获子表达式。 | (\d{4}-\d{2}-\d{2})匹配2023-08-17这样的格式字符串,并保存该内容到临时缓存区,方便返回 |
|---|---|---|
| (?:) | 用于分组但不捕获子表达式。 | (?:\d{4}-\d{2}-\d{2})匹配2023-08-17这样的格式字符串,但保存返回 |
| (?=) | 正向预查:用于匹配某个位置后面紧跟着指定模式的情况。 只是对当前位置进行判断,并不会改变匹配的位置。 它只是用于辅助条件判断,而不会在匹配结果中包含预查的内容。 | 验证密码强度:可以使用^(?=.*[A-Z])(?=.*[0-9])(?=.*[!@#$%^&*])来判断密码是否包含至少一个大写字母、一个数字和一个特殊字符。 查找包含特定字符的单词:可以使用\b\w+(?=ing\b)来匹配所有以"ing"结尾的单词,但不包括"ing"本身。 零宽度断言:可以使用(?=...)结合其他正则表达式元字符,如(?=.*\d)来匹配包含数字的字符串,而不会捕获数字本身。 |
| (?<=) | 正向回顾语法结构,用于匹配当前位置之前的内容是否符合指定模式。 只能匹配固定宽度的模式,而不能使用像.*这样的可变宽度模式。 | 查找前缀:可以使用(?<=prefix)\w+来匹配以"prefix"开头的单词。 查找固定长度的数字:可以使用(?<=\D)\d{3}(?=\D)来匹配前后都不是数字的长度为3的数字。 查找特定格式的字符串:例如,使用(?<=\b[A-Z]{3}-)\d{3}(?=\b)可以匹配类似于"ABC-123"的字符串中的数字部分。 |
| (?!) | 负向预查语法结构,用于匹配当前位置之后的内容是否不符合指定模式。 只能匹配固定宽度的模式,而不能使用可变宽度模式。 | 排除特定后缀:可以使用\w+(?!suffix)来匹配不以"suffix"结尾的单词。 排除特定格式的字符串:例如,使用\d{3}(?![A-Z]{3}-)可以匹配不以类似于"ABC-"结尾的字符串中的三位数字。 |
| (?<!) | 负向回顾语法结构,用于匹配当前位置之前的内容是否不符合指定模式。 只能匹配固定宽度的模式,而不能使用可变宽度模式。 | 排除特定前缀:可以使用(?<!prefix)\w+来匹配不以"prefix"开头的单词。 排除特定格式的字符串:例如,使用(?<![A-Z]{3}-)\d{3}可以匹配不以类似于"ABC-"开头的字符串中的三位数字。 |
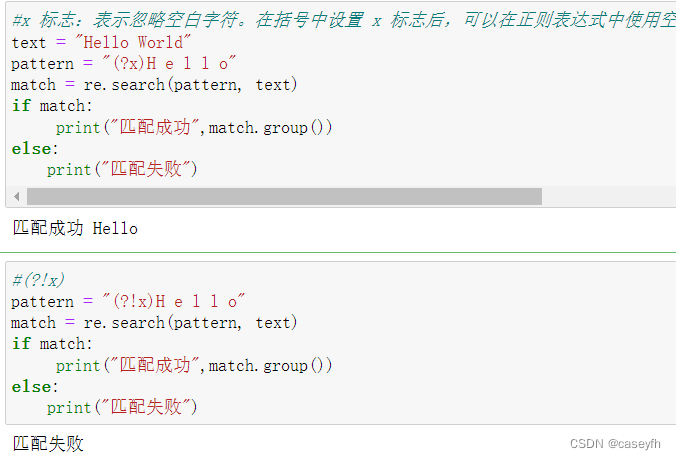
| (?#) | 写注释不会匹配内容 | text = "Hello World" pattern = "(?#正向肯定预查+可选标志)(?i)[a-z]+(?= World)" match = re.search(pattern, text) match.group() |
| (?imx) | 在括号中使用i, m, 或 x 可选标志 | i 标志:表示忽略大小写。在括号中设置 i 标志后,正则表达式会忽略大小写进行匹配。pattern = r"(?i)hello" m 标志:表示多行模式。在括号中设置 m 标志后,正则表达式中的 ^ 和 $ 会匹配每一行的开头和结尾,而不仅仅是整个文本的开头和结尾。pattern = r"(?m)hello" x 标志:表示忽略空白字符。在括号中设置 x 标志后,可以在正则表达式中使用空格和换行符来增加可读性,这些空白字符会被忽略。pattern = r"(?x)hello" |
| (?!imx) (?imx:) | 在括号中不使用i, m, 或 x 可选标志 | pattern = r"(?!i)hello" pattern = r"(?i:)hello" |
反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
可以使用非捕获元字符 ?:、?= 或 ?! 来重写捕获,忽略对相关匹配的保存。
在正则表达式中,可以使用反向引用来匹配之前已经匹配到的内容反向引用使用\数字的形式,其中数字表示之前捕获的分组的编号。例如,\1表示对第一个捕获分组的引用,\2表示对第二个捕获分组的引用,以此类推。

在上面的例子中,\b[a-z]+\b用于匹配一个单词,并将其捕获为第一个分组。然后,\1用于引用第一个分组,从而匹配重复的单词。
需要注意的是,反向引用只能在正则表达式中使用,而不能在替换字符串中使用。如果需要在替换字符串中使用之前匹配到的内容,可以使用替换函数或者替换回调来实现。
捕获的表达式,正如 [a-z]+ 指定的,包括一个或多个字母。正则表达式的第二部分是对以前捕获的子匹配项的引用,即,单词的第二个匹配项正好由括号表达式匹配。\1 指定第一个子匹配项。

修饰符(标记)
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
单词边界元字符确保只检测整个单词。否则,诸如 "is issued" 或 "this is" 之类的词组将不能正确地被此表达式识别。
正则表达式后面的全局标记 g 指定将该表达式应用到输入字符串中能够查找到的尽可能多的匹配。
表达式的结尾处的不区分大小写 i 标记指定不区分大小写。
多行标记 m 指定换行符的两边可能出现潜在的匹配。
标记不写在正则表达式里,标记位于表达式之外,格式如下:/pattern/flags
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore | 不区分大小写 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别 |
| g | global | 全局匹配 查找所有的匹配项 |
| m | multi line | 多行匹配 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾 |
| s | 特殊字符圆点 | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n |
正则表达式的修饰符是用来修改正则表达式模式的行为的特殊标记。下面是一些常见的正则表达式修饰符:
| 修饰符 | 全称 | 含义 |
|---|---|---|
| re.I | re.IGNORECASE | 忽略大小写匹配 |
| re.M | re.MULTILINE | 多行匹配,使^和$匹配每行的开头和结尾 |
| re.S | re.DOTALL | 使点号(.)匹配任意字符,包括换行符 |
| re.X | re.VERBOSE | 忽略在正则表达式中的空白和注释,使其更易读 |
| re.A | re.ASCII | 使\W,\w,\b,\B,\b,\d,\D,\s,\S只匹配ASCII字符 |


运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
|---|---|
| \ | 转义符、反向引用 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| |替换 | "或"操作字符具有高于替换运算符的优先级,使得"m |
Python 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
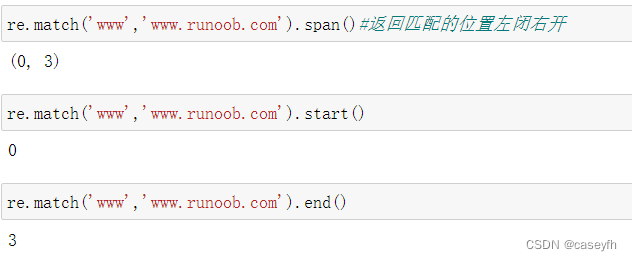
在Python的正则表达式中,span 是一个元组,用于表示匹配的子字符串在原始字符串中的起始位置和结束位置。span 元组的第一个元素是匹配子字符串的起始位置,第二个元素是结束位置(不包括在内)。
当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
match()函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
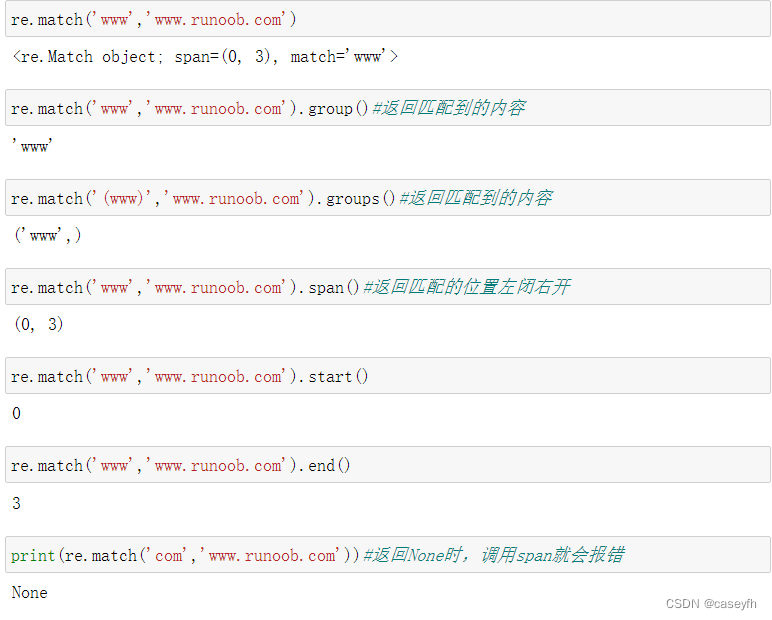
group()和groups()
group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups() 返回一个包含所有小组字符串的元组,表达式必须有圆括号,从 1 到 所含的小组号。

groupdict()命令组
在Python的正则表达式中,groupdict() 方法用于返回一个包含所有匹配子字符串的命名组的字典。命名组是使用 (?P<name>...) 语法定义的正则表达式的一部分,其中 name 是组的名称。
groupdict() 方法可以方便地获取命名组的名称和对应的匹配子字符串,使得后续的处理和分析更加灵活和可读性更高。
import re
pattern = r'(?P<fruit>apple|banana)'
text = 'I have an apple and a banana.'
matches = re.finditer(pattern, text)
for match in matches:
print(match.groupdict())
print(match.group('fruit'))
print(match.group())

span()、start()和end()
search()函数
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。 同样是match对象,有group()和groups()方法
search与match的区别就是匹配位置的限制,match必须是匹配开头,search是全局匹配返回第一个,其余用法都一样
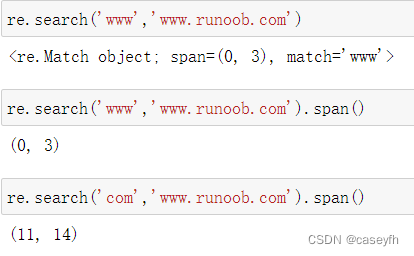
search()与match()的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到第一个匹配的对象。 其余span()和group()、groups()用法都一样
sub()函数
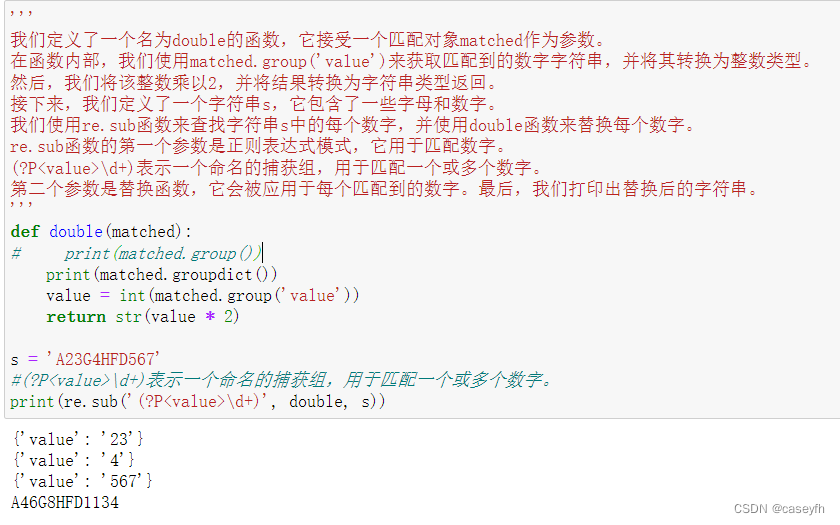
检索和替换 Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
| pattern | 正则中的模式字符串 |
|---|---|
| repl | 替换的字符串,也可为一个函数,必须有返回值 |
| string | 要被查找替换的原始字符串 |
| count | 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配 |
替换1

替换2
compile()函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags]) 参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等
具体参数为:
| 修饰符 | 全称 | 含义 |
|---|---|---|
| re.I | re.IGNORECASE | 忽略大小写匹配 |
| re.M | re.MULTILINE | 多行匹配,使^和$匹配每行的开头和结尾 |
| re.S | re.DOTALL | 使点号(.)匹配任意字符,包括换行符 |
| re.X | re.VERBOSE | 忽略在正则表达式中的空白和注释,使其更易读 |
| re.A | re.ASCII | 使\W,\w,\b,\B,\b,\d |
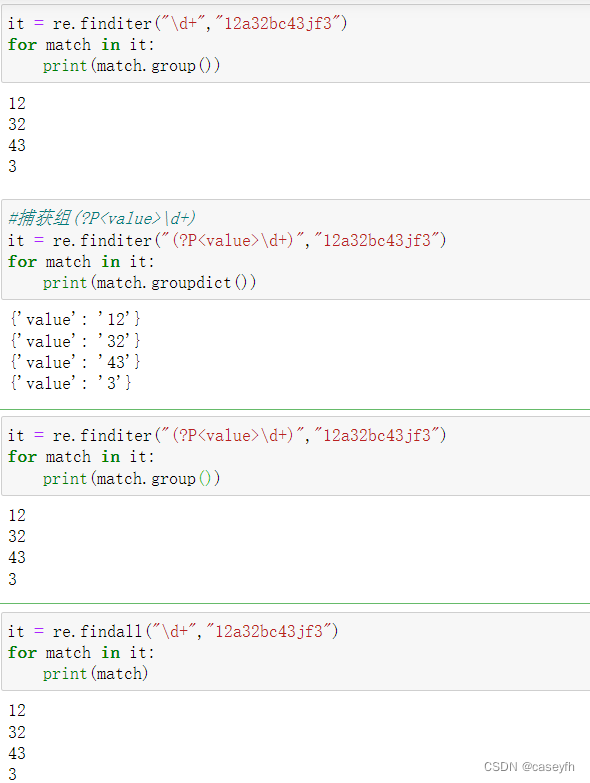
findall()函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
findall(string[, pos[, endpos]])
参数:
| string | 待匹配的字符串 |
|---|---|
| pos | 可选参数,指定字符串的起始位置,默认为 0 |
| endpos | 可选参数,指定字符串的结束位置,默认为字符串的长度 |

finditer()函数
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
split()函数
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等 |

捕获组
捕获组是正则表达式中的一种功能,用于在匹配过程中提取特定部分的文本。它通常用于以下场景:
-
提取信息:捕获组允许我们从匹配的文本中提取出我们感兴趣的部分。例如,如果我们要从一个包含电话号码的字符串中提取出区号和号码,我们可以使用捕获组来匹配并提取这两部分。
-
替换文本:捕获组可以用于在替换操作中引用匹配的文本的特定部分。通过在替换的字符串中使用捕获组的引用,我们可以在替换过程中保留或修改特定的文本。
-
匹配重复模式:捕获组还可以用于匹配重复模式。通过在正则表达式中使用捕获组和量词,我们可以匹配并重复出现特定的模式。

命名组(?P<name>...)
groupdict() 方法用于获取匹配对象中的捕获组的字典形式表示。它适用于以下场景:
-
提取具有命名捕获组的正则表达式中的信息:当正则表达式中使用了命名捕获组(使用
(?P<name>...)语法),groupdict()可以返回一个字典,其中键是命名捕获组的名称,值是对应的匹配结果。text = "姓名:张三,年龄:25,性别:男" pattern = r"姓名:(?P<姓名>.*),年龄:(?P<age>\d+),性别:(?P<gender>\w+)" match = re.search(pattern, text) print(match) print(match.group()) if match: info = match.groupdict() print("姓名:", info["姓名"]) print("年龄:", info["age"]) print("性别:", info["gender"])
-
处理复杂的匹配结果:
groupdict()方法可以用于处理匹配结果中的多个捕获组,以字典的形式提取和处理信息ext = "日期:2022-01-01,时间:12:30" pattern = "日期:(?P<date>\d{4}-\d{2}-\d{2}),时间:(?P<time>\d{2}:\d{2})" match = re.search(pattern, text) if match: info = match.groupdict() date = info["date"] time = info["time"] print(date,time,sep='\n') # 进一步处理日期和时间... #在处理复杂的匹配结果时,`groupdict()` 方法可以提供更方便的访问和处理捕获组的方式
(?=)、(?<=)、(?!)、(?#)、(?imx)、(?!imx)
(?imx)、(?!imx)
(?!imx )正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。
(?!imx) 或(?imx:)正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。
(?i) i 标志:表示忽略大小写。在括号中设置 i 标志后,正则表达式会忽略大小写进行匹配。


(?m) m 标志:表示多行模式。在括号中设置 m 标志后,正则表达式中的 ^ 和 $ 会匹配每一行的开头和结尾,而不仅仅是整个文本的开头和结尾。


(?x) x 标志:表示忽略空白字符。在括号中设置 x 标志后,可以在正则表达式中使用空格和换行符来增加可读性,这些空白字符会被忽略
(?:)非捕获组
不会创建一个新的分组,它只用于分组,但不会保存匹配的内容
(?#...)注释
它可以用于在正则表达式中添加注释,以提高正则表达式的可读性和可维护性。注释可以是任何文本,可以用来解释正则表达式的某个部分的作用、意图或说明。
text = "Hello World"
pattern = "(?i:hello)(?#前面括号时一个非捕获组,还加了大小写敏感,不会返回内容) (World)"
match = re.search(pattern, text)
match.groups()
#输出('World',)
(?=)正向肯定预查
格式: pattern1(?=pattern2) 预查成功返回pattern1
这里pattern既可以是字符匹配(普通字符、特殊字符、字符类、非打印字符、元字符),也可以是正则模式匹配
它用于在当前位置进行匹配,并且只有当所含的正则表达式在当前位置成功匹配时,才会继续匹配后面的内容。

pattern包括了(?#注释)、(?i)忽略大小写标志
(?<=) 正向肯定回顾
它用于在当前位置之前进行匹配,并且只有当所含的正则表达式在当前位置之前成功匹配时,才会继续匹配后面的内容。

(?<=)+(?=)

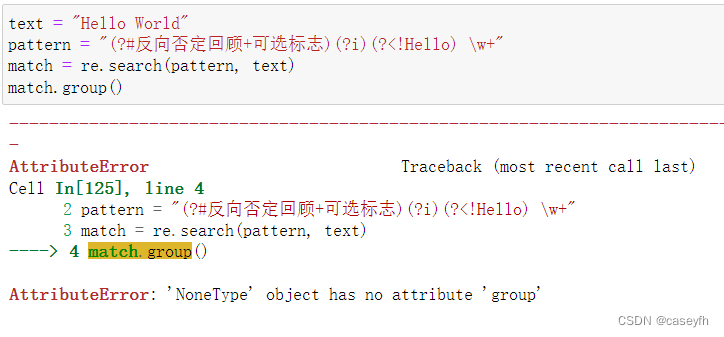
(?!)正向否定回顾
它用于在当前位置之后进行匹配,并且只有当所含的正则表达式在当前位置之后不能成功匹配时,才会继续匹配后面的内容。

注意:没有这种情况(?<!)















 5482
5482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









