







 本文介绍了MySQL这一流行的关系型数据库,因其开源免费,成为众多公司的数据库选型方案。重点分析了SQL的执行流程,包括建立连接与权限校验、查询缓存、分析器的词法语法分析、优化器建立执行计划、执行器调用存储引擎执行语句等,还提及了常见存储引擎。
本文介绍了MySQL这一流行的关系型数据库,因其开源免费,成为众多公司的数据库选型方案。重点分析了SQL的执行流程,包括建立连接与权限校验、查询缓存、分析器的词法语法分析、优化器建立执行计划、执行器调用存储引擎执行语句等,还提及了常见存储引擎。
mysql之从零开始
废话
mysql ,一个关系型的数据库,被称为目前最流行的关系型数据库,非关系型最流行的当属redis了;之所以这么多人用,重要的一个原因是开源,免费;因为免费,同时中国这个互联网如雨后春笋般崛起的时代,成本的把控成为技术影响关键的一环,(我是开公司赚钱的,能省则省),所以大部风公司都选取其作为自己的数据库选型方案;同样,也因为用的人多了,自然生态越来越好,相关的附属产物,大企业的经验,这些都是创业型公司宝贵的财富;
不多说,开始正文
mysql> select * from T where id=1
以上面这条sql为例,我们简单的分析下这条sql的执行;首先说明这条sql的几个关键数据:
- 【select】 命令位:表示查询,搜索
- 【*】 表示要查找的表的字段名,*表示全部
- 【T】 : 表示这条sql要操作的目标表名,
- 【where】 命令位,表示后面是我查找的条件
- 【id】指定名称的字段下的结果即是我要查询的结果
综上所属(连起来读): 我要查找在表T中满足条件id=1的所有的记录的所有字段信息;(英语嘛,都是反着读的)
俗话说,知其然还要知其所以然,一条sql的执行并不是那么简单;
一般的数据库都是CS模型,即一个服务端,多个客户端,服务端负责数据处理,客户端则会提供一系列API供用户使用;
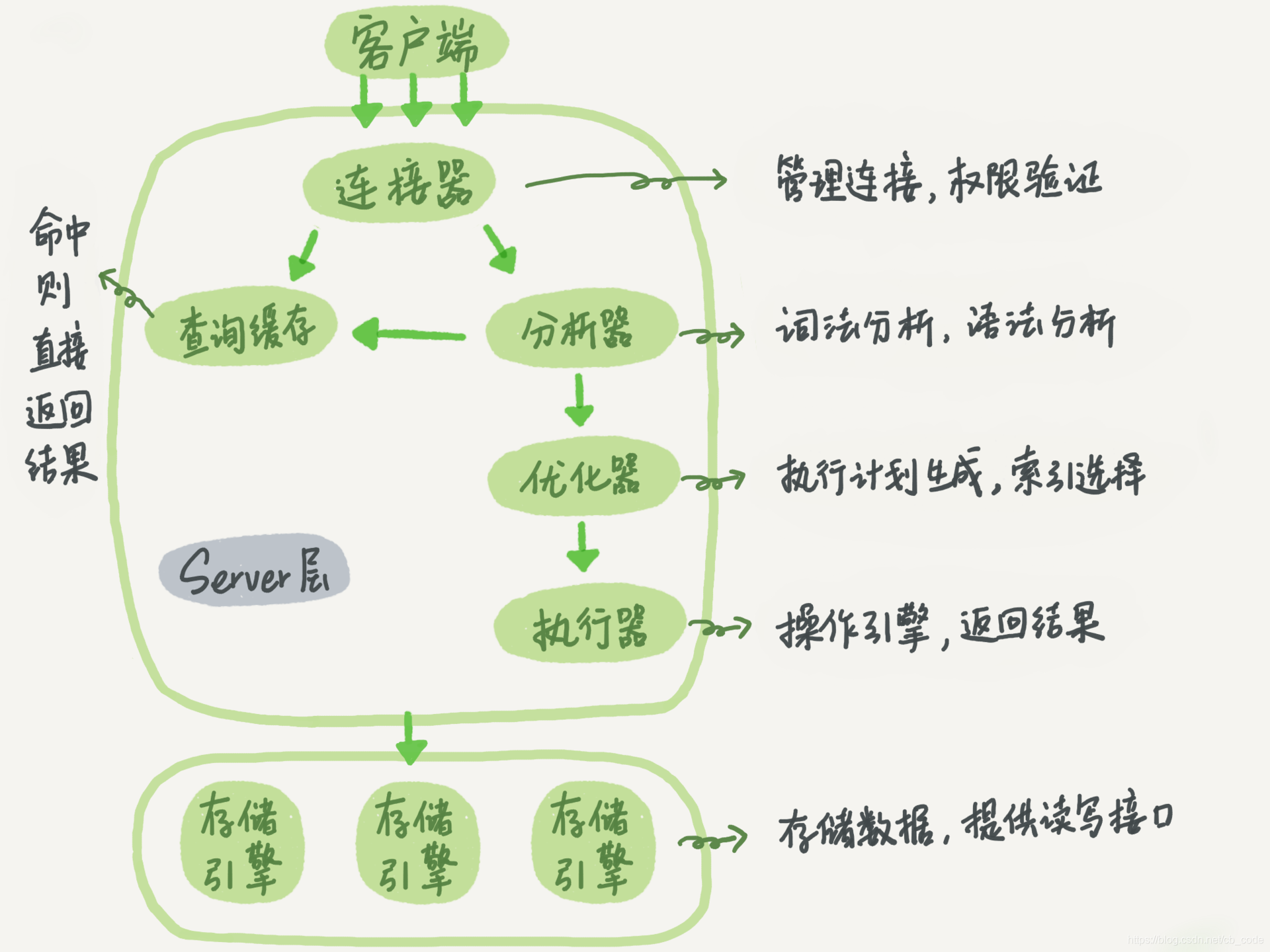
因此,sql执行的第一步即建立一个连接,连接建立时,不经是简单的网络连接建立,同时还需要进行【相应账户权限的校验】,此时会形成一个权限集合,之后的在该连接中的所有的sql执行均会在此权限集合中校验,此时,建立连接和校验权限的组件就叫做【连接器】
(中途如果修改权限,并不会影响已经建立的连接的权限,除非断开重连;如果一个连接长时间空闲,会在指定空闲时间之后被断开,默认8小时,可配置)
【查询缓存】连接建立好之后,客户端发送sql语句,连接器接收到请求,检查是否开启了【查询缓存】,如果开启了查询缓存,则会去查询缓存中查询,如果存在相应的查询结果缓存,则返回给客户端
查询缓存查到结果时,会校验权限;
查询缓存的维护是mysql自身维护的,适合一些读多写少的场景;当表中的数据发生变更时,会全量清理缓存,如果一个数据表的变更很平凡,不建议开启查询缓存
如果查询缓存没有命中,或者没有开启,接下来开始sql真正的执行流程;
【分析器】,分析客户端传入的sql语句是否存在语法错误或词法错误,即词法分析与语法分析
表是否存在,是否存在歧义都是在此处发现的,同时还可能会校验权限,例如触发器这玩意儿
【优化器】,对sql分析,并结合表的数据信息,索引信息,建立执行计划,执行计划建立好后,选择自认为比较优秀的执行计划,交给执行器
优化器大部份情况下的处理结果都是最优的,但难免出现自以为是的情况,因此需要考虑到该部份的结果对于整体执行的影响;优化器主要来选择索引,选择多表的连接查询时的查询顺序等;
【执行器】,调用存储引擎来执行这条语句,同时会校验有没有相应表的操作权限,如果没有权限,则报错:
当有权限时,会打开表,按照表的引擎定义来调用接口查询数据;
mysql的存储引擎是以插件的方式引入,可以理解为,mysql不特别关心底层是怎么实现存储和查询的,它定义了一套接口,用户可以自己实现这套接口,实现对应接口规定的业务逻辑;就和JVM与hotspot的关系一样,一个定义一个实现;这样的做法给了用户更多的可选择性,不同的使用场景可以使用不同的实现,常见的几种实现有:【InnoDB存储引擎】【MyISAM存储引擎】【MEMORY存储引擎】,不同的存储引擎各有各的特点和优势,后续会深入的探讨下;
至此,一条查询sql算是粗略的执行完了,以上的所有均是mysql server层的内容,存储引擎层的实现需要针对存储引擎具体实现来对应了解;
上图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









