






File类
File类表示文件或者文件夹,比如File file = new File("dog.gif");代表了当前文件夹下的dog.gif这个文件,或者File file = new File("images");代表了当前文件夹下的images这个文件夹。File类的常见操作有:
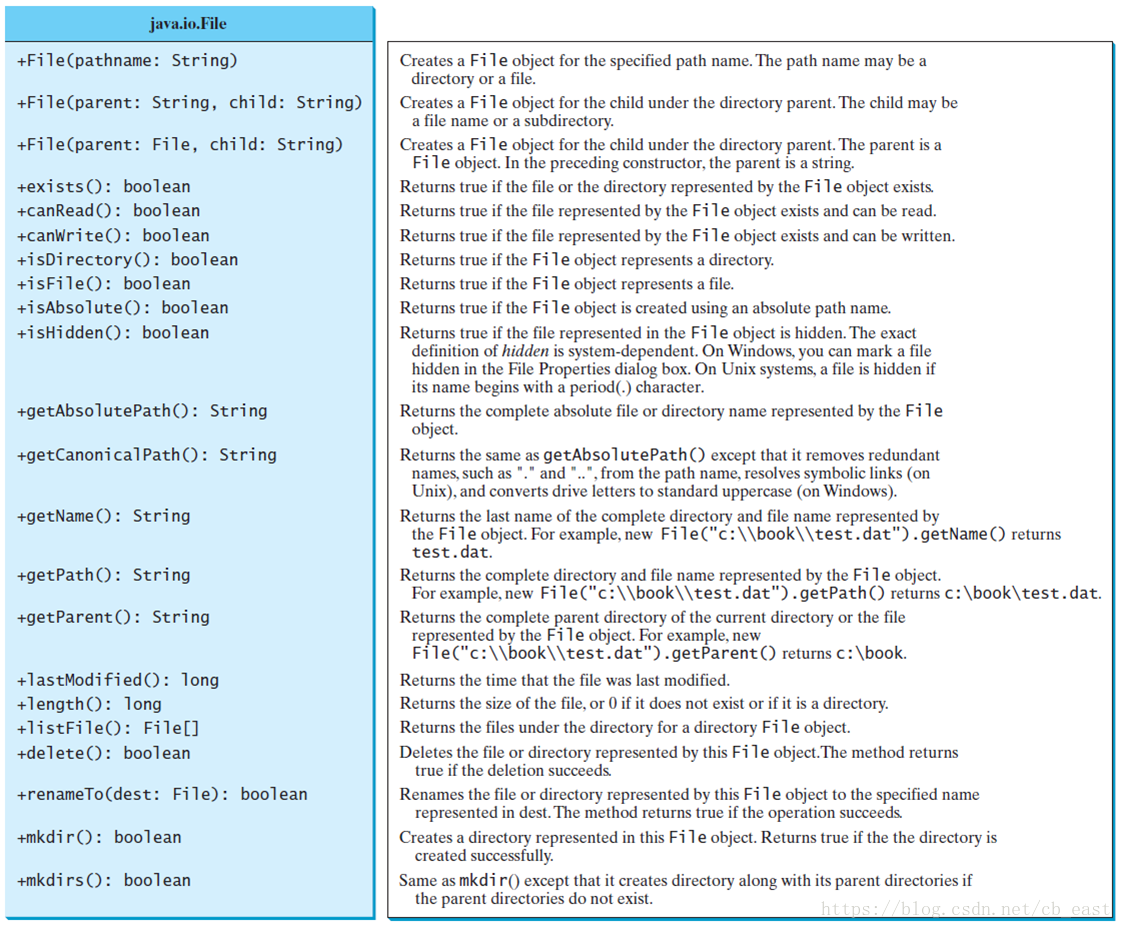
创建File对象时,构造函数File(String pathname)中的字符串是文件或者文件夹的路径,这个路径可以是相对路径,也可以是绝对路径。像dog.gif,images\dog.gif就是相对路径,像Windows下的d:\images\dog.gif,UNIX下的/home/test/images/dog.gif就是绝对路径。
因为在Java中,\表示转义字符,因此在字符串字面量中\表示路径分隔符要写成\\,或者可以写成/,/是UNIX中的路径分隔符,也可以用在Windows系统中。因此在Windows系统里,路径d:\images\dog.gif的写法有:
- “d:\\images\\dog.gif” 正确
- “d:/images/dog.gif” 正确
注意,下面的写法是错误的
- “d:\images\dog.gif”
例子:
public class TestFileClass {
public static void main(String[] args) {
java.io.File file = new java.io.File("image/us.gif");
System.out.println("Does it exist? " + file.exists());
System.out.println("The file has " + file.length() + " bytes");
System.out.println("Can it be read? " + file.canRead());
System.out.println("Can it be written? " + file.canWrite());
System.out.println("Is it a directory? " + file.isDirectory());
System.out.println("Is it a file? " + file.isFile());
System.out.println("Is it absolute? " + file.isAbsolute());
System.out.println("Is it hidden? " + file.isHidden());
System.out.println("Absolute path is " +
file.getAbsolutePath());
System.out.println("Last modified on " +
new java.util.Date(file.lastModified()));
}
}文本(Text)输入/输出
File类没有创建文件以及向文件写/读数据的方法,向文件文件中写数据也称为输出Output,从文件中读数据也称为输入Input,合起来称为文件输入输出IO。
输出用PrintWriter类
可以用java.io.PrintWriter类来创建文本文件,以及向它里面写文本。
首先创建PrintWriter类对象
PrintWriter output = new PrintWriter(filename);
或者
PrintWriter output = new PrintWriter(new File(filename));
然后可以调用PrintWriter类的print(),println(),printf()等方法来写数据到文件中。

下面的程序向文件scores.txt中写两行文本,每行文本由字符串和整数组成。
public class WriteData {
public static void main(String[] args) throws java.io.IOException {
java.io.File file = new java.io.File("scores.txt");
if (file.exists()) {
System.out.println("File already exists");
System.exit(0);
}
// Create a file
java.io.PrintWriter output = new java.io.PrintWriter(file);
// Write formatted output to the file
output.print("John T Smith ");
output.println(90);
output.print("Eric K Jones ");
output.println(85);
// Close the file
output.close();
}
}运行完毕,文件scores.txt中的内容如下:
John T Smith 90
Eric K Jones 85
try-with-resources来自动关闭资源
上面的程序中,如果注释掉output.close()可能会发生的情况是数据没有实际写到文件中,这是因为PrintWriter往文件中写文字可能是带有缓冲的,写函数先将文字写到缓冲区中,当缓冲区被写满了才将缓冲区里的文字一次性写到文件中,这样可以提高程序的运行速度。但是有时程序员会忘记调用output.close()方法。从JDK 7开始Java支持一种新的语法来自动调用对象的close()方法。一种语法称为try-with-resources语法。
try(声明和创建资源){
处理资源
}这样的资源变量的类必须实现了AutoClosealbe接口,这个接口里面只声明了一个close()方法。PrintWriter就实现了AutoClosealbe接口。当大括号里处理资源代码处理完成,不论其中是否有异常抛出,在try括号里声明的资源对象变量会被自动调用close()方法。因此上述代码可以写成
public class WriteDataWithAutoClose {
public static void main(String[] args) throws Exception {
java.io.File file = new java.io.File("scores.txt");
if (file.exists()) {
System.out.println("File already exists");
System.exit(0);
}
try (
// Create a file
java.io.PrintWriter output = new java.io.PrintWriter(file);
) {
// Write formatted output to the file
output.print("John T Smith ");
output.println(90);
output.print("Eric K Jones ");
output.println(85);
}
}
}用Scanner来读取文本
可以用java.util.Scanner类来从控制台和文件中读取文本和数值,Scanner把输入视为以分隔符(默认为空白字符)分开的字符串”token”。
从键盘上读取,可以创建一个Scanner,并把它和System.in关联起来,
Scanner input = new Scanner(System.in);
从文件中读取,需要把Scanner与文件关联,
Scanner input = new Scanner(new File(filename));
或者
Scanner input = new Scanner(filename);

假设scores.txt中是
John T Smith 90
Eric K Jones 85
import java.util.Scanner;
public class ReadData {
public static void main(String[] args) throws Exception {
// Create a File instance
java.io.File file = new java.io.File("scores.txt");
// Create a Scanner for the file
Scanner input = new Scanner(file);
// Read data from a file
while (input.hasNext()) {
String firstName = input.next();
String mi = input.next();
String lastName = input.next();
int score = input.nextInt();
System.out.println(
firstName + " " + mi + " " + lastName + " " + score);
}
// Close the file
input.close();
}
}上述代码的运行结果是
John T Smith 90
Eric K Jones 85
nextInt()、nextDouble()等方法读取字符的时候会忽略掉分隔符(默认为空白字符,即’ ‘, \t, \f, \r, 或者 \n),把连续的非分隔符读到字符串中直到遇到某个分隔符,遇到的分隔符不会被读取,留给后续的读取方法处理。然后nextInt()会把字符串解析为整数值并返回,其它的方法类似,如果不能正确解析,会抛出java.util.InputMismatchException非检查异常。next()方法不解析读取的字符串,直接返回它。
nexLine()方法读取包括分隔符在内的一行中的字符串直到遇到换行符。换行符也被读取,但是不作为字符串的一部分返回,后续的next…()方法从下一行开始读取。
流式处理
处理文件或者其它输入输出设备时,一般是将文件等视为流式数据,即要写文件就不断向文件末尾写数据,要读文件就不断从文件当前位置往后读数据,就像文件是水流一样。而不是像处理普通变量一样,在内存中对文件进行整体操作。所以有时候会称文件为文件流。
文本文件和二进制文件
文本文件处理是指处理的是人们可读的字符(数值会转换为字符),如果是写向文件,那么会把字符变量以某种编码后的字节序列写到文件中,如果是从文件中读,会把文件中的字节序列解读为以某种方式编码的字符,读取到内存中的字符变量中。举个例子,字符串“199”写向文本文件,字符1、9、9会依次写到文件中,Java中的字符是Unicode字符集中的字符,存储在2个字节的char类型的变量里,并以它的Unicode码值表示字符,字符1的Unicode码值是49,它在内存中的形式是0x0031,在把字符1存储到文件前,要把字符1,以某个编码方式转换为字节序列保存到文件中,比如,在UTF-8编码方式下,字符1的编码为1个字节的0x31,那么存储到文件中是0x31,而在UTF-16编码方式下,字符1的编码是2个字节的0x0031(Java中的字符变量char就是以UTF-16的形式表示字符的),那么存储到文件中的是0x0031。这里是用十六进制表示数值,当然最后写到文件中的是二进制形式的,比如0x31是00110001。文本文件的写用PrintWriter,读用Scanner,在计算机中打开文本文件用文本编辑器软件。
二进制文件处理,是指将内存中的数值原样存储到文件中,换句话说文件中的二进制序列就是某种类型的数据在内存中的形式。比如有一个字节类型的数值199,如果以文本的方式把它写到文本文件中,那么会把它转换为字符串“199”,并用上述方式把1、9、9这3个字符依次写到文件中。而如果以二进制方式来把它写到文件中,那么就把它在内存中的二进制11000111原样写到文件中。二进制文件的写最终要用FileOutputStream类,二进制文件的读最终要用FileInputStream类。因为二进制文件的数据不一定表示的是字符,因此没有一个统一软件可以打开,如果里面保存是影音数据,那么用播放器打开,如果保存的是pdf文档,那么用pdf阅读器打开,等等。

总之,不论文本处理还是二进制处理,在内存和文件中的都是二进制数据,文本文件把文件中的二进制数据统一看成是字符(以某种形式编码后的字符),二进制文本不一定把文件中的二进制数据看成字符,也可看成其它类型的二进制表示形式。
二进制(Binary)文件输入/输出
可以简单理解为,处理文本文件处理的是字符,而处理二进制文件处理的是字节。以二进制(字节)形式来处理输入输出的常见的类有,
- FileInputStream/FileOutputStream处理文件的字节级别的读写。
- DataInputStream/DataOutputStream把数值或者字符串以内存中的形式和字节序列相互转换。
- BufferedInputStream/BufferedOutputStream开辟字节序列的缓存,使对文件的读写先读写到缓存中,当缓存满了之后再一次性的将多个字节读写到文件中,加快文件的输入和输出。
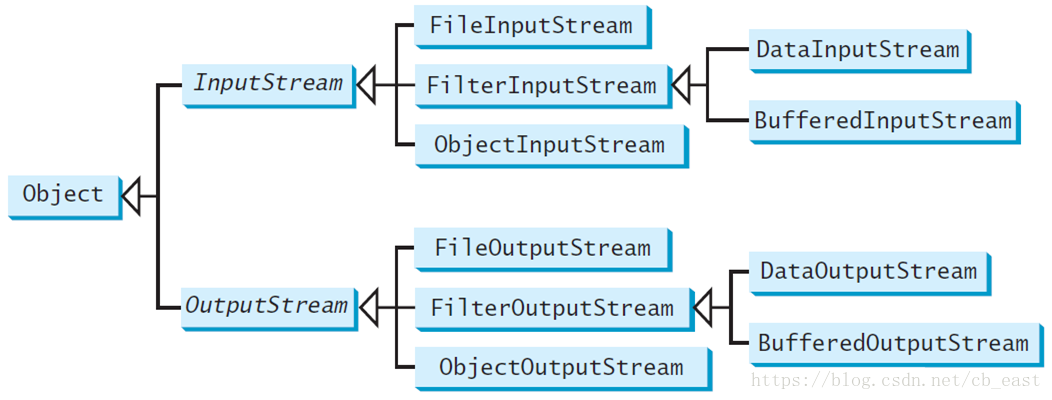
OutputStream是二进制输出的基类

InputStream是二进制输入的基类

从这两个类的方法可以看到,它们处理的都是字节一级的数据。基本所有方法都会抛出java.io.IOException或者其子类的检查异常。
二进制输入/输出到文件
二进制处理的基本含义就是把内存中的字节原样输入/输出到目标中。如果要输出到文件中,需要使用FileInputStream/FileOutputStream。FileInputStream用来从文件中以字节为单元读到内存中,FileOutputStream用来将内存中字节序列写到文件中。FileInputStream/FileOutputStream没有在它们的父类InputStream/OutputStream基础上新增新的方法,当然,它们重写了父类InputStream/OutputStream的相关方法。
FileInputStream的构造函数如下,
public FileInputStream(String filename)public FileInputStream(File file)
创建FileInputStream时,如果文件不存在,会抛出java.io.FileNotFoundException异常。
FileOutputStream的构造函数如下,
public FileOutputStream(String filename)public FileOutputStream(File file)public FileOutputStream(String filename, boolean append)public FileOutputStream(File file, boolean append)
创建FileOutputStream时,如果文件不存在,会创建一个新文件。如果文件已经存在,前两个构造函数会删除文件中的内容。后面两个构造函数可以指定是否追加数据到文件中,而不是删除文件中的内容。
在I/O类中的几乎所有的方法都会抛出java.io.IOException。因此,我们需要声明抛出它,或者捉住它。
public static void main(String[] args) throws IOException{
// I/O操作
}或者
public static void main(String[] args){
try{
// I/O操作
}
catch(IOException ex){
ex.printStackTrace();
}
}下面的例子使用binary I/O将10个从1到10的byte写到temp.dat文件中,再从文件中读回来。
import java.io.*;
public class TestFileStream {
public static void main(String[] args) throws IOException {
try (
// Create an output stream to the file
FileOutputStream output = new FileOutputStream("temp.dat");
) {
// Output values to the file
byte byteArray[] = {1,2,3,4,5,6,7,8,9, 10};
for (int i = 0; i < byteArray.length; i++)
output.write(byteArray[i]);
}
try (
// Create an input stream for the file
FileInputStream input = new FileInputStream("temp.dat");
) {
// Read values from the file
int value;
while ((value = input.read()) != -1)
System.out.print(value + " ");
}
}
}处理文本文件时的文件读写操作最终也是使用这两个类的。只是有时候它们被封装到PrintWriter和Scanner类中了,我们不需要对它们直接操作。
FilterInputStream/FilterOutputStream
Filter stream是一类输入输出流,它们会关联到文件输入和输出流,对它们的输入和输出操作经过它们的“filter”后最终会操作到文件中。FiterInputStream/FilterOutputStream有两种子类:
- DataInputStream/DataOutputStream
- BufferedInputStream/BufferedOutputStream
DataInputStream/DataOutputStream
DataOutputStream将基本数值类型以及字符类型以内存中的原本二进制形式转换为字节流并输出到文件中。DataInputStream将文件中的内容转换以原本二进制形式存储到基本数值类型或字符类型的变量中。


DataOutputStream实现了DataOutput接口来写基本数值和字符。DataInputStream实现了DataInput接口来读数值和字符。可以看成它们将基本数值类型没有任何修改的在内存和文件中复制。
下面以DataOutputStream为例,来说明类中的方法,
比如,writeInt(int x)将x直接输出到文件中。例如,整数199在内存中是00000000 00000000 00000000 1100 0111这4个字节(写成十六进制是0x000000C7),writeInt(199)将这4个字节写到文件中。
有几种方法来处理字符和字符串。
writeChar(char c)将字符写入到文件中,字符类型在内存中以2个字节的Unicode值存储,那么它们就以这种2个字节的形式写到文件中。例如字符’1’在内存中存储的是’1’的Unicode码值0x0031,writeChar(‘1’)将这2个字节存储到文件中。
writeChars(String s)将字符串中的字符依次写入到文件中。它不写字符中字符的个数,因此如果要写字符串中含有字符的个数,以供读取时确定字符串的字符个数,可以在调用writeChars(String s)之前用writeInt(int v)的方法来写字符串的长度。
writeUTF(String s)首先写2个字节的字符串长度信息到输出流,紧接着将字符串s中的字符以修改的UTF-8形式写到输出流里。比如,writeUTF(“ABCDEF”)将八个字节写到文件中,这八个字节以16进制表示是00 06 41 42 43 44 45 46。与writeChars(String s)比较,writeUTF(String s)会记录字符串s的长度。而且如果字符串s中的字符大部分都是ASCII字符的话,writeUTF(String s)会比writeChars(String s)更加节省空间。
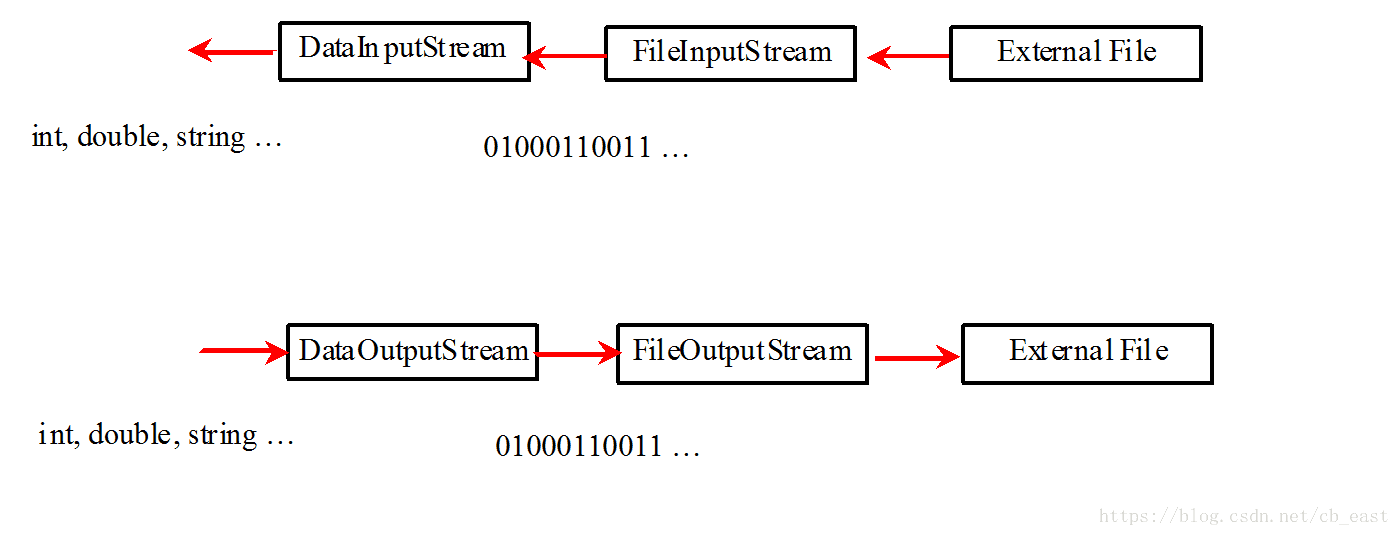
要创建DataInputStream/DataOutputStream对象,需要使用如下的构造函数:
public DataInputStream(InputStream instream)public DataOutputStream(OutputStream outstream)
下面的代码创建了一个input stream,它会从in.dat文件中读取字节流。output stream将数值写到out.data文件中。
DataInputStream input =
new DataInputStream(new FileInputStream("in.dat"));
DataOutputStream output =
new DataOutputStream(new FileOutputStream("out.dat"));例子
import java.io.*;
public class TestDataStream {
public static void main(String[] args) throws IOException {
try ( // Create an output stream for file temp.dat
DataOutputStream output =
new DataOutputStream(new FileOutputStream("temp.dat"));
) {
// Write student test scores to the file
output.writeUTF("John");
output.writeDouble(85.5);
output.writeUTF("Jim");
output.writeDouble(185.5);
output.writeUTF("George");
output.writeDouble(105.25);
}
try ( // Create an input stream for file temp.dat
DataInputStream input =
new DataInputStream(new FileInputStream("temp.dat"));
) {
// Read student test scores from the file
System.out.println(input.readUTF() + " " + input.readDouble());
System.out.println(input.readUTF() + " " + input.readDouble());
System.out.println(input.readUTF() + " " + input.readDouble());
}
}
}BufferedInputStream/BufferedOutputStream
BufferedInputStream/BufferedOutputStream也是FilterInputStream/FilterOutputStream的子类,它们的作用很单纯,给我们在内存中开辟读/写文件的缓冲区,这样不用每次调用write/read函数都直接从磁盘上文件中读/写了,因为磁盘文件操作相对内存操作来说非常的慢。可以理解成BufferedInputStream/BufferedOutputStream含有一个byte的数组。这个数组起到缓冲的作用。比如BufferedOutputStream在数组满了才把数组里面的内容一次性写到磁盘文件中,这比调用一次write函数就把字节写到磁盘文件中要快。

BufferedInputStream/BufferedOutputStream没有新增方法,它们的方法都是从InputStream/OutputStream继承下来的,当然,它们重写了父类的这些方法。
我们可以在创建DateOutputStream或者DataInputStream时添加BufferedOutputStream对象或者BufferedInputStream对象。
DataOutputStream output = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream("temp.dat")));DataInputStream input = new DataInputStream(
new BufferedInputStream(new FileInputStream("temp.dat")));对于小量数据的读写,buffered stream作用不明显,但是当读写的数据较大时,作用就比较显著。
例子
import java.io.*;
public class Copy {
/** Main method
@param args[0] for sourcefile
@param args[1] for target file
*/
public static void main(String[] args) throws IOException {
// Check command-line parameter usage
if (args.length != 2) {
System.out.println(
"Usage: java Copy sourceFile targetfile");
System.exit(1);
}
// Check if source file exists
File sourceFile = new File(args[0]);
if (!sourceFile.exists()) {
System.out.println("Source file " + args[0]
+ " does not exist");
System.exit(2);
}
// Check if target file exists
File targetFile = new File(args[1]);
if (targetFile.exists()) {
System.out.println("Target file " + args[1]
+ " already exists");
System.exit(3);
}
try (
// Create an input stream
BufferedInputStream input =
new BufferedInputStream(new FileInputStream(sourceFile));
// Create an output stream
BufferedOutputStream output =
new BufferedOutputStream(new FileOutputStream(targetFile));
) {
// Continuously read a byte from input and write it to output
int r, numberOfBytesCopied = 0;
while ((r = input.read()) != -1) {
output.write((byte)r);
numberOfBytesCopied++;
}
// Display the file size
System.out.println(numberOfBytesCopied + " bytes copied");
}
}
}装饰模式
从文本和二进制处理过程可以看到,在Java的I/O处理中,经常会出现一层套一层的现象,比如在二进制模式处理数值时,
DataOutputStream output = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream("temp.dat")));可以想象,数据流会依次经过DataOutputStream对象、BufferedOutputStream对象、FileOutputStream对象的处理,从数值变为字节保存到文件中。这种处理模式也称为装饰模式。
文本(Text)输入和输出原理
文本文件的处理和二进制文件的处理,区别在于文本首先要面对的是字符,而二进制直接面对最底层的字节。因为字符有字符编码这一过程,字符和字节处理是不一样的。
PrintWriter和Scanner的工作过程
PrintWriter工作过程
使用PrintWriter向文件中写的过程中,可以视为经过了这几步:
第1步,将二进制的数值转换为可读的文本格式,即字符序列(数组)
第2步,将字符序列中的各个字符以平台默认编码格式编码为字节序列
第3步,将字节序列(数组)原样输出到文件中
PrintWriter实质上完成的是第1步,2、3两步是借助于其它的类来完成的。第2步,将字符编码为字节序列是由OutputStreamWriter类来实现, 第3步,将字节序列写到文件中是由FileOutputStream来实现的。比如,
java.io.PrintWriter output = new java.io.PrintWriter(file);
output.print(1);也可以写成
FileOutputStream file = new FileOutputStream("text1.txt");
OutputStreamWriter writer = new OutputStreamWriter(file);
java.io.PrintWriter printWriter = new java.io.PrintWriter(writer);
printWriter.print(1); // printWriter.print("1");第1步,可以理解为output在print函数里调用了String.valueOf(1)方法把整数1(内存中是0x00000001)转为字符串”1”,即字符’1’(内存中’1’是0x00000031)
第2步,可以理解为output在print函数里调用了writer(OutputStreamWriter类)的write(char[] cbuf, int off, int len)方法把字符’1’转换为平台默认编码的字节流0x31
第3步,可以理解为在write(char[] cbuf, int off, int len)方法中调用了的file(FileOutputStream类的)的write(byte[] b, int off, int len)方法把字节流0x31原样写到文件中。
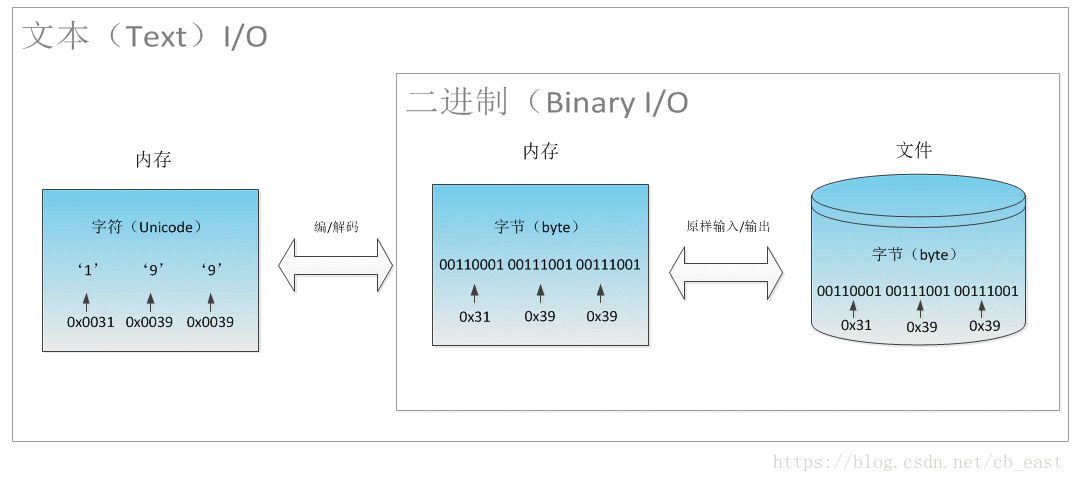
注意,上面的图对应的是PrintWriter工作过程的2、3步。PrintWrite的主要工作,即过程1并没有展示在图中。
Scanner将文件中的整数字符串扫描到整数变量中的过程可以看成PrintWriter的反过程:
第1步,将文件中的内容读入到字节序列(数组)
第2步,将字节序列以平台默认编码格式解码为字符序列(数组)
第3步,扫描字符序列(数组),将它们从可读字符解析为二进制的数值并存储到变量中
Scanner实质上完成的是第3步,1、2两步是借助于其它类来实现的。第1步,将文件中的数据读入到字节序列是由文件输入类FileInputStream来实现。第2步,将字节序列解码为字符是由InputStreamReader类来实现。
字符集和字符编码小知识
- 字符集(Character set)
字符集是指要处理的字符集合包含了哪些字符,以及这些字符的编号(码),比如ASCII字符集,包含了128个字符,并规定了其中每个字符的码值,1是49,A是65。ASCII字符集没有包含中文。Unicode字符集,是一个预期要覆盖所有字符的字符集,它兼容ASCII字符集,也就是说,它包含ASCII字符集中的所有字符,而且相同的字符码值一样。
- 字符编码(Character encoding)
字符编码是指在某个字符集中的字符最终的二进制表示形式,字符编码确定下来才能在计算机中存储和通过网络传递。
如果只要编码ASCII字符集,那就以其码值作为它的编码,并存储在1个字节中,比如1的码值是49,那么1的编码就是0x31,A的编码是0x41。在C语言中,一个char类型的变量就是这样存储一个ASCII字符的。
对于Unicode字符集,因为它包含的字符非常多,显然用1个字节进行编码就不够了,对Unicode字符集的编码实际上有多种方案,常见的有UTF-16,UTF-8。
对于UTF-16,简单来看,对于Unicode中常用的字符,我们可以视UTF-16采用的固定2个字节的编码方法,用字符的码值作为它的编码。比如,1的码值是49,其编码是0x0031,A的码值是65,其编码是0x0041,中的编码是4e2d。Java语言的char类型就是以UTF-16的方式存储字符的。
UTF-16编码的优点是常见字符所占的字节是固定2个,方便计算机内部处理,缺点是和原先ASCII编码方案不兼容,而且假如要使用的字符都是在ASCII字符集下的字符,那么本来用ASCII字符集的编码方法1个字符用1个字节编码就足够了,但是现在要用2个字节,浪费空间。因此人们想出了UTF-8编码方案。UTF-8是变长编码方案。ASCII字符集中的字符在UTF-8下仍然用1个字节表示,而且与ASCII编码完全一样,即在UTF-8编码方案下,1的编码就是0x31,A的编码是0x41。
参考文章:关于字符编码,你所需要知道的















 1397
1397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









