







echo "总大小:$total\_size"
echo "已使用:$used\_capacity"
echo "可用空间:$available\_space"
echo "使用率:$usage\_percentage"
echo "挂载点:$mount\_point"
echo "主机地址:$host"
TABLE=“diskcheck_fb”
SQL_LIST=“use monitor”
mysql -h 192.168.1.225 -P 3306 -uroot -p123456 << EOF
$SQL_LIST
INSERT INTO diskcheck_fb (avail,used,size,host,mounted,cpu,date) VALUES(‘
a
v
a
i
l
a
b
l
e
_
s
p
a
c
e
′
,
′
available\_space','
available_space′,′usage_percentage’,‘
t
o
t
a
l
_
s
i
z
e
′
,
′
total\_size','
total_size′,′host’,'
m
o
u
n
t
_
p
o
i
n
t
′
,
"
mount\_point',"
mount_point′,"usage_percentage",NOW());
EOF
echo ‘nasen told you insert db success!’
done < output.txt
这段代码使用一个 while 循环来读取 output.txt 文件的每一行,并将每行分割成字段。然后,它将字段的值分别存储在变量中,并通过一些命令和脚本来获取主机地址。最后,它使用 mysql 命令将这些信息插入到数据库中,并打印出一些信息表示插入成功。
#### 5.mysql监控数据库的监控表DEMO
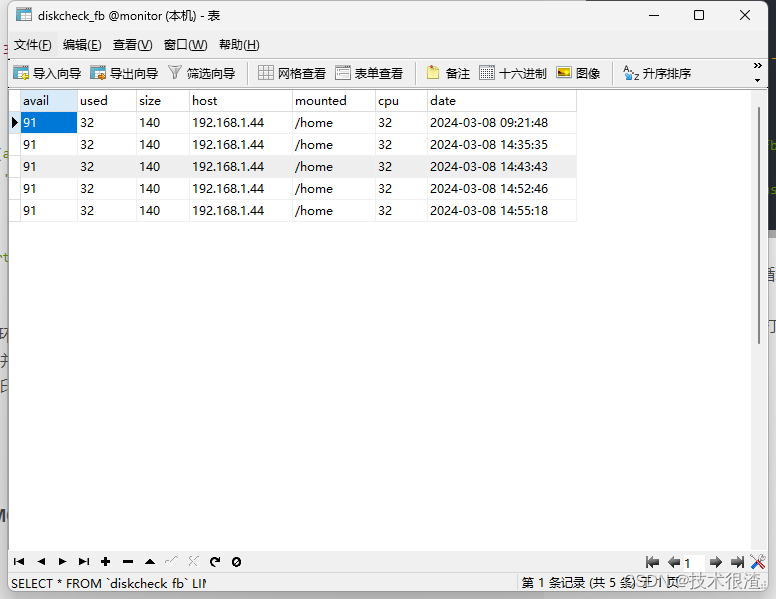
CREATE TABLE diskcheck\_fb (
avail varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT ‘硬盘空余空间’,
used varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT ‘硬盘已用空间’,
size varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT ‘硬盘空间大小’,
host varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT ‘所检查主机ip’,
mounted varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT ‘所检查硬盘目录’,
cpu varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT ‘cpu使用率’,
date timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT ‘更新时间’
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 ROW_FORMAT=DYNAMIC;
### 二、完整shell脚本代码
#!/bin/bash
echo 'get bigest disk info ’
largest_partition=“nasen”
执行 df -m 命令获取磁盘分区信息
disk_usage=$(df -m)
使用 awk 来处理 df 命令的输出,找到容量最大的分区
largest_partition= ( e c h o " (echo " (echo"disk_usage" | awk ‘NR>1 {if ($2>=max) {max=$2; part=$1} } END {print part}’)
输出容量最大的分区名称
echo “容量最大的分区名称是: $largest_partition”
如果需要同时显示最大容量数值和分区名称,可以稍作修改
largest_size_and_partition= ( e c h o " (echo " (echo"disk_usage" | awk 'NR>1 {if ($2>max) {max=$2; part=KaTeX parse error: Expected 'EOF', got '}' at position 2: 1}̲ } END {printf …largest_size_and_partition"
echo ‘nasen shell 20240307’
检查 output.txt 文件是否存在,如果不存在则创建
if [ ! -f “output.txt” ]; then
touch output.txt
fi
清空 output.txt 文件内容
output.txt
target_partition=“$largest_partition” # 设置外部变量
echo ‘system auto get bigest disk:’
echo “$target_partition”
执行 df -h 命令获取硬盘分区信息
df -h | awk '{
filesystem = $1
size = $2
used = $3
avail = $4
use_percentage = $5
mounted_on = $6
声明变量并赋值
file_system_name = filesystem
total_size = size
used_capacity = used
available_space = avail
usage_percentage = use_percentage
mount_point = mounted_on
只匹配文件系统名称为 /dev/mapper/VolGroup-lv_home 的数据
if (filesystem == “‘$target_partition’”) {
total_size = substr(total_size, 0, length(total_size) - 1)
available_space = substr(available_space, 0, length(available_space) - 1)
used_capacity = substr(used_capacity, 0, length(used_capacity) - 1)
usage_percentage = substr(usage_percentage, 0, length(usage_percentage) - 1)
host=“192.168.1.44”
输出变量值到文件
print file_system_name, total_size, used_capacity, available_space, usage_percentage, mount_point, host >> “output.txt”
}
}’
echo ‘nasen told you system info get success!’
读取文件并输出变量值
while IFS= read -r line; do
fields=(
l
i
n
e
)
f
i
l
e
_
s
y
s
t
e
m
_
n
a
m
e
=
"
line) file\_system\_name="
line)file_system_name="{fields[0]}"
total_size=“
f
i
e
l
d
s
[
1
]
"
u
s
e
d
_
c
a
p
a
c
i
t
y
=
"
{fields[1]}" used\_capacity="
fields[1]"used_capacity="{fields[2]}”
available_space=“
f
i
e
l
d
s
[
3
]
"
u
s
a
g
e
_
p
e
r
c
e
n
t
a
g
e
=
"
{fields[3]}" usage\_percentage="
fields[3]"usage_percentage="{fields[4]}”
mount_point=“
f
i
e
l
d
s
[
5
]
"
h
o
s
t
=
"
{fields[5]}" host="
fields[5]"host="{fields[6]}”
host=`/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"`
echo "文件系统名称:$file\_system\_name"
echo "总大小:$total\_size"
echo "已使用:$used\_capacity"
echo "可用空间:$available\_space"
echo "使用率:$usage\_percentage"
echo "挂载点:$mount\_point"
echo "主机地址:$host"
TABLE=“diskcheck_fb”
SQL_LIST=“use monitor”
mysql -h 192.168.1.225 -P 3306 -uroot -p123456 << EOF
$SQL_LIST
INSERT INTO diskcheck_fb (avail,used,size,host,mounted,cpu,date) VALUES(‘
a
v
a
i
l
a
b
l
e
_
s
p
a
c
e
′
,
′
available\_space','
available_space′,′used_capacity’,‘
t
o
t
a
l
_
s
i
z
e
′
,
′
total\_size','
total_size′,′host’,'
m
o
u
n
t
_
p
o
i
n
t
′
,
"
mount\_point',"
mount_point′,"usage_percentage",NOW());
EOF
echo ‘nasen told you insert db success!’
done < output.txt
### 三、代码实际验证
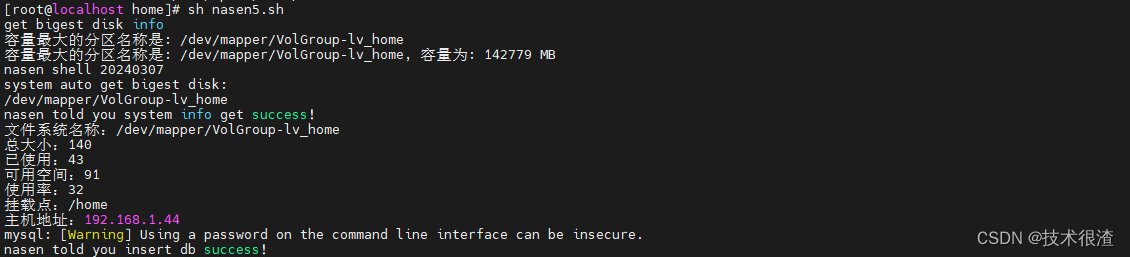
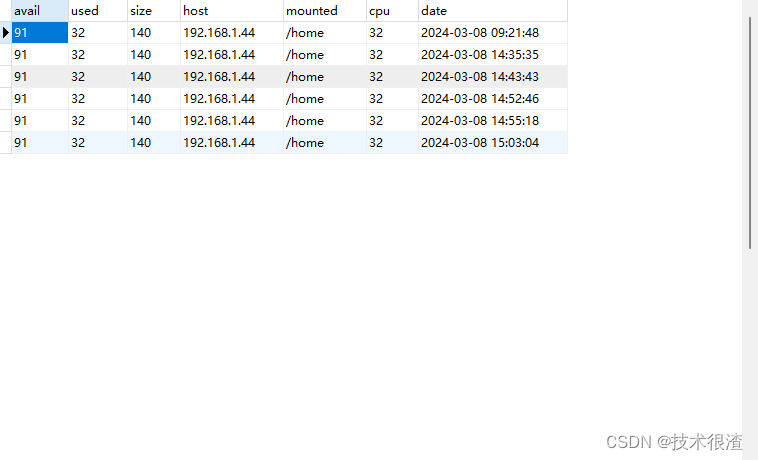
***亲测有效,同学们可以自己试试!***
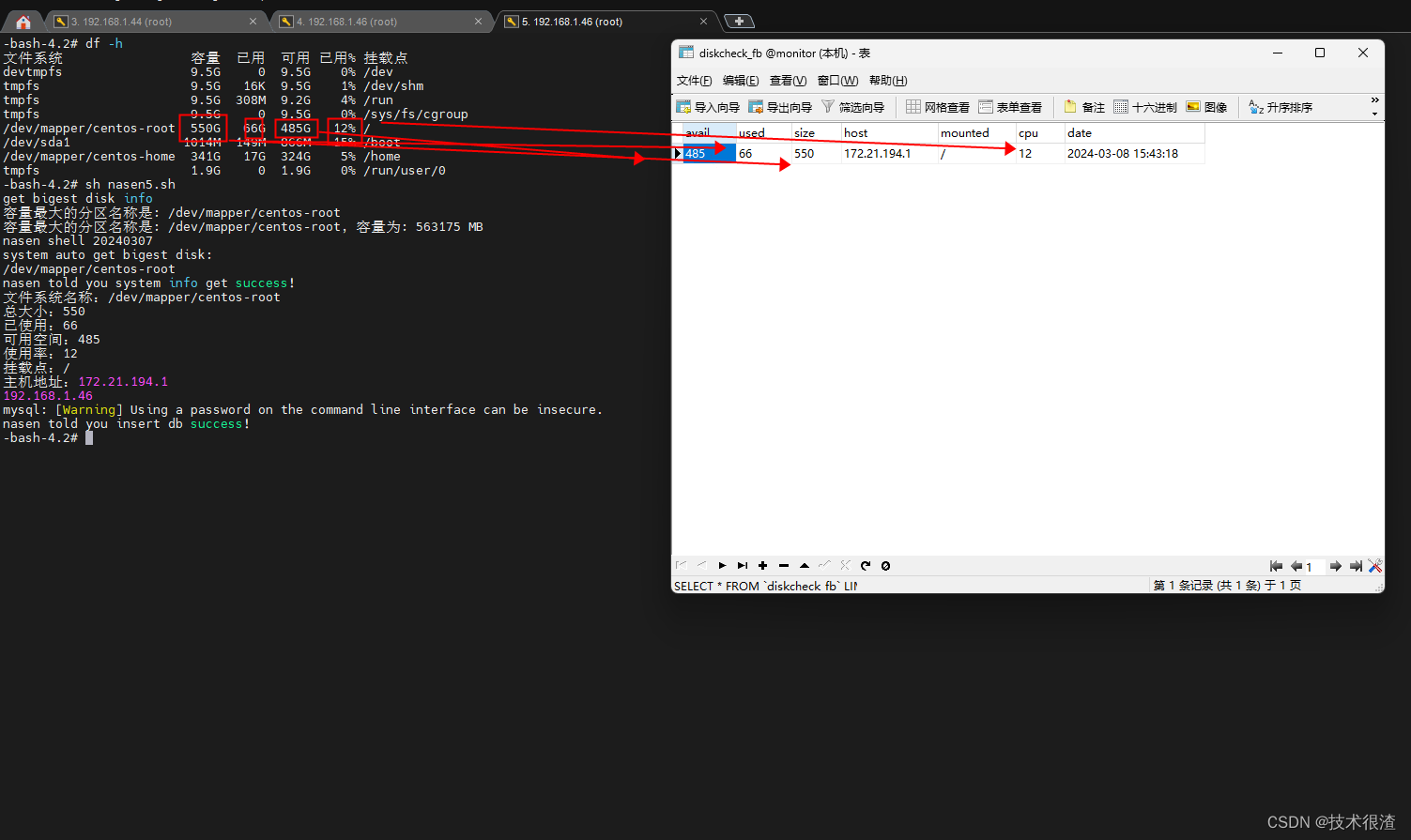
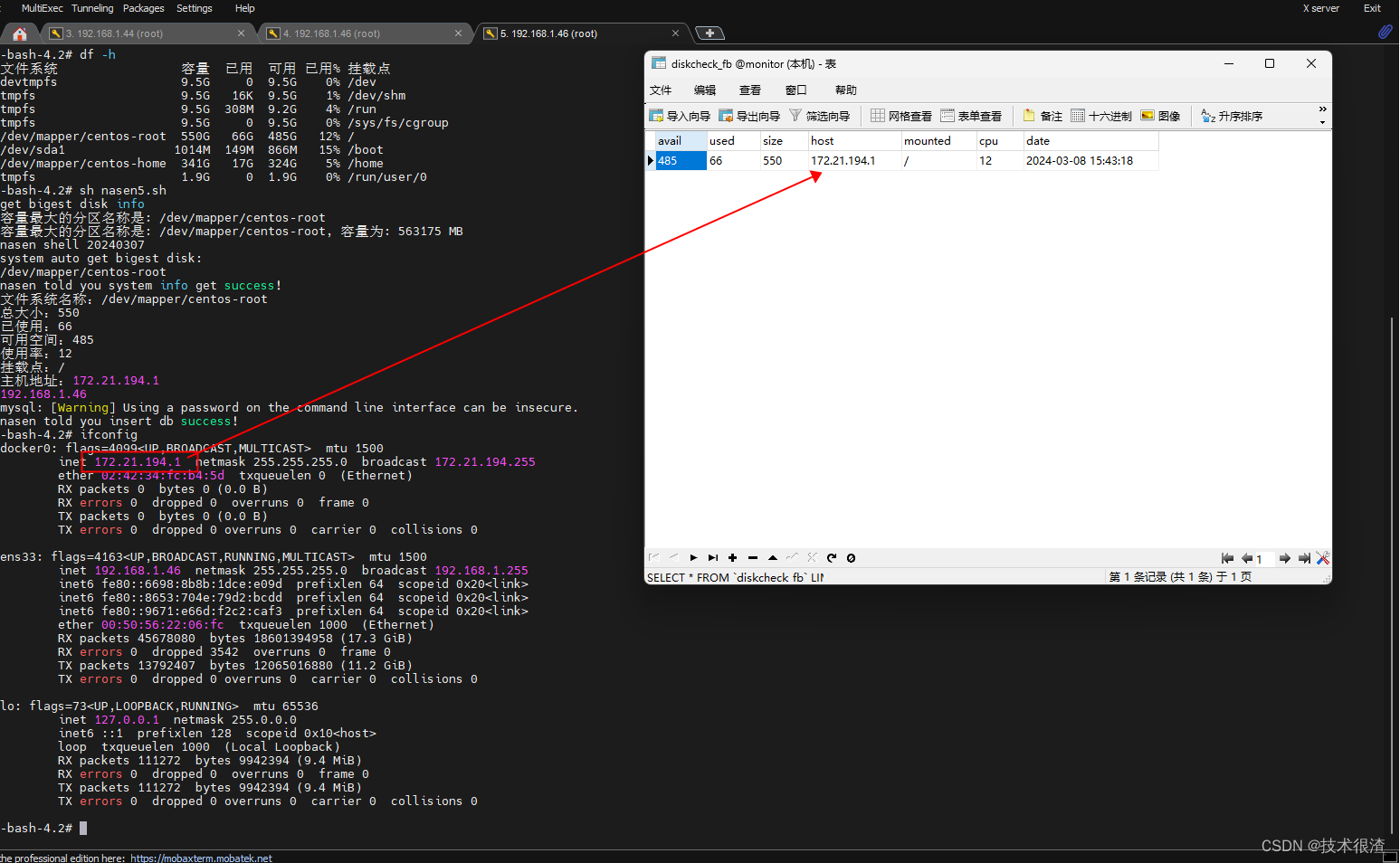
***网卡IP可以自己改一下匹配逻辑***
host=/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"
### 四、其他思路的实现代码案例
#!/bin/sh
check_disk status
author yang
datetime=date +"%Y-%m-%d/%H:%M:%S" #获取当前时间
avail=df -h | awk '{print $4}' | grep -v 已用 | tail -1| cut -d "G" -f1 -
used=df -h | awk '{print $3}' | tail -1| cut -d "G" -f1 -
host=/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"
mounted=df -h | awk '{print $6}' | tail -1
zyl=df -h | awk '{print $5}' | tail -1| cut -d "%" -f 1
size=df -h | awk '{print $2}' | tail -1| cut -d "G" -f1 -
use= ( ( (( ((used/$size))
echo $use
TIME_INTERVAL=5
time=
(
d
a
t
e
"
+
L
A
S
T
_
C
P
U
_
I
N
F
O
=
(date "+%Y-%m-%d %H:%M:%S") LAST\_CPU\_INFO=
(date"+LAST_CPU_INFO=(cat /proc/stat | grep -w cpu | awk '{print $2,$3,$4,$5,$6,$7,KaTeX parse error: Expected 'EOF', got '}' at position 2: 8}̲') LAST\_SYS\_I…(echo $LAST_CPU_INFO | awk '{print KaTeX parse error: Expected 'EOF', got '}' at position 2: 4}̲') LAST\_TOTAL\…(echo $LAST_CPU_INFO | awk ‘{print $1+$2+$3+$4+$5+$6+$7}’)
sleep
T
I
M
E
_
I
N
T
E
R
V
A
L
N
E
X
T
_
C
P
U
_
I
N
F
O
=
{TIME\_INTERVAL} NEXT\_CPU\_INFO=
TIME_INTERVALNEXT_CPU_INFO=(cat /proc/stat | grep -w cpu | awk '{print $2,$3,$4,$5,$6,$7,KaTeX parse error: Expected 'EOF', got '}' at position 2: 8}̲') NEXT\_SYS\_I…(echo $NEXT_CPU_INFO | awk '{print KaTeX parse error: Expected 'EOF', got '}' at position 2: 4}̲') NEXT\_TOTAL\…(echo $NEXT_CPU_INFO | awk ‘{print $1+$2+$3+$4+$5+$6+$7}’)
#系统空闲时间
SYSTEM_IDLE=echo ${NEXT\_SYS\_IDLE} ${LAST\_SYS\_IDLE} | awk '{print $1-$2}'
#CPU总时间
TOTAL_TIME=echo ${NEXT\_TOTAL\_CPU\_T} ${LAST\_TOTAL\_CPU\_T} | awk '{print $1-$2}'
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)

最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

-1713097767895)]
给大家整理的电子书资料:
[外链图片转存中…(img-RWrS3cpD-1713097767895)]
如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-TsadmXCi-1713097767896)]















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









