






爬取豆瓣书籍的列表页、详情页、评论、以及作者信息的三级页面,再将获取的书籍在京东进行搜索,获取书籍的销售情况,最后将数据上传至MySQL和MongoDB中进程存储。
一、列表页
首先我们需要爬取书籍的列表页,我们需要知道我们要爬取哪些内容。
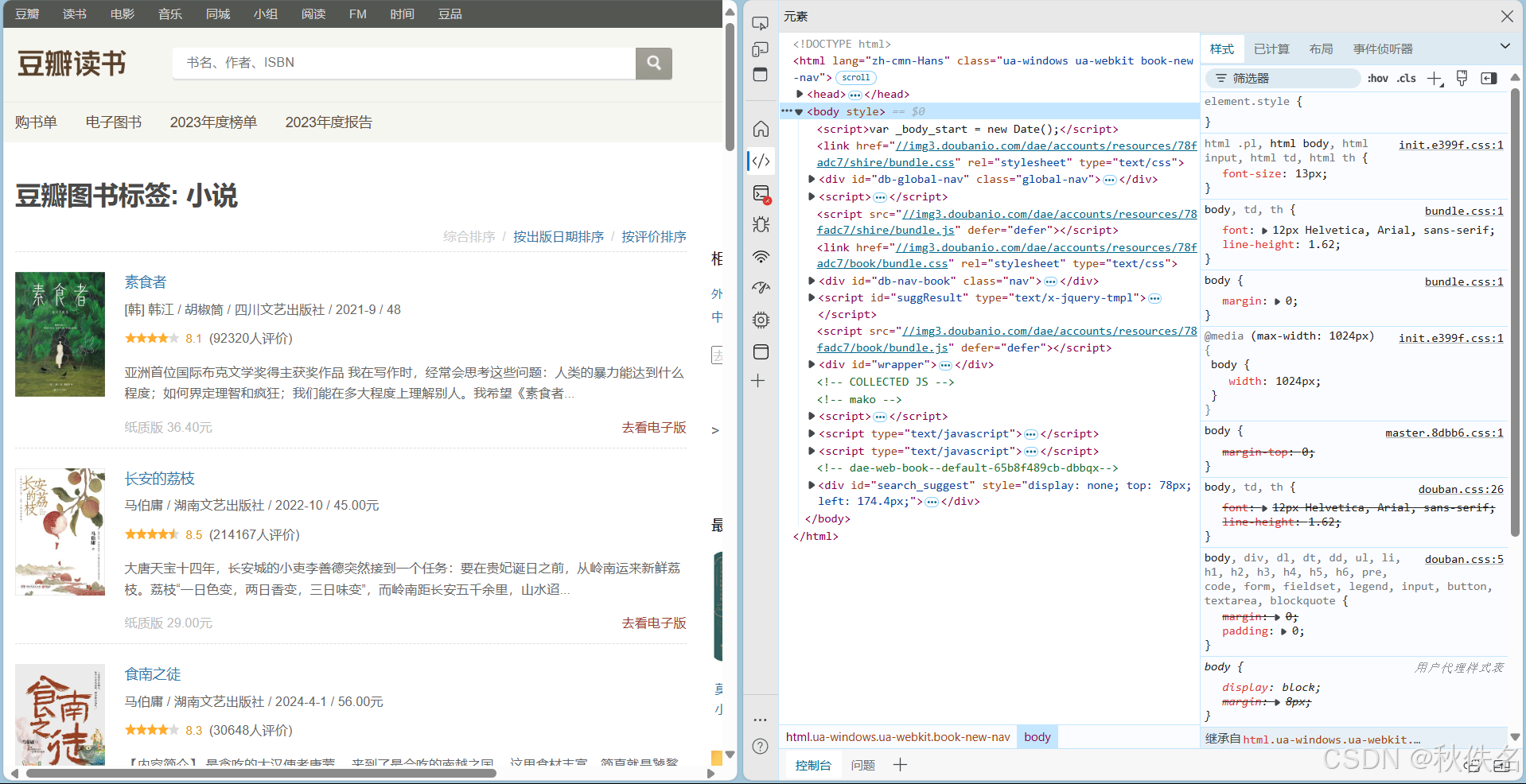
右键检查查看页面代码,选择检查页左上角,再点击左边的页面可以快捷查看对应的代码,我们通过获取列表的代码,来爬取对应的数据。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By首先是导入库,第一个是设置间隔时间,一般用于爬取完信息后自动切换页面,设置的时间就是预留给电脑爬取信息的时间,根据自己电脑爬取的速度来设置。而Selenium则是一个强大的自动化测试框架,常用于Web应用的功能性测试和爬虫开发。
def main():
page_count = 51
f = open("dbs_list.csv", mode='a', encoding='utf-8')
f.write(f"dbs_id,book,data,price,url\n")
web = webdriver.Chrome()
web.get("https://www.douban.com/")
setCookies(web)
getListPage(web, page_count, f)
time.sleep(5)
web.quit()
f.close()
if __name__ == '__main__':
main()先写mian函数,使用open函数创建或打开一个名为dbs_list.csv的CSV文件,模式为追加('a'),编码为UTF-8。
调用f.write方法,写入CSV的表头行,包含列名dbs_id, book, data, price, 和 url。
创建一个Chrome WebDriver实例,这会开启一个新的Chrome浏览器窗口。
导航至目标网址:使用web.get方法使浏览器导航至豆瓣网站(https://www.douban.com/)。调用未显示定义的setCookies函数,传入web参数,推测此函数用于设置特定的cookies,可能用于登录状态保持或其他用途。
调用getListPage函数,传入web、page_count和文件句柄f,猜测此函数负责遍历多页并抓取数据。使用time.sleep(5)让脚本暂停5秒,给手动检查或交互留出时间。
使用web.quit()方法关闭浏览器窗口。使用f.close()方法关闭之前打开的文件。判断条件if __name__ == '__main__':确保当此脚本作为主程序运行时才会调用main()函数。
其中setCookies,可以让我保持登录状态。
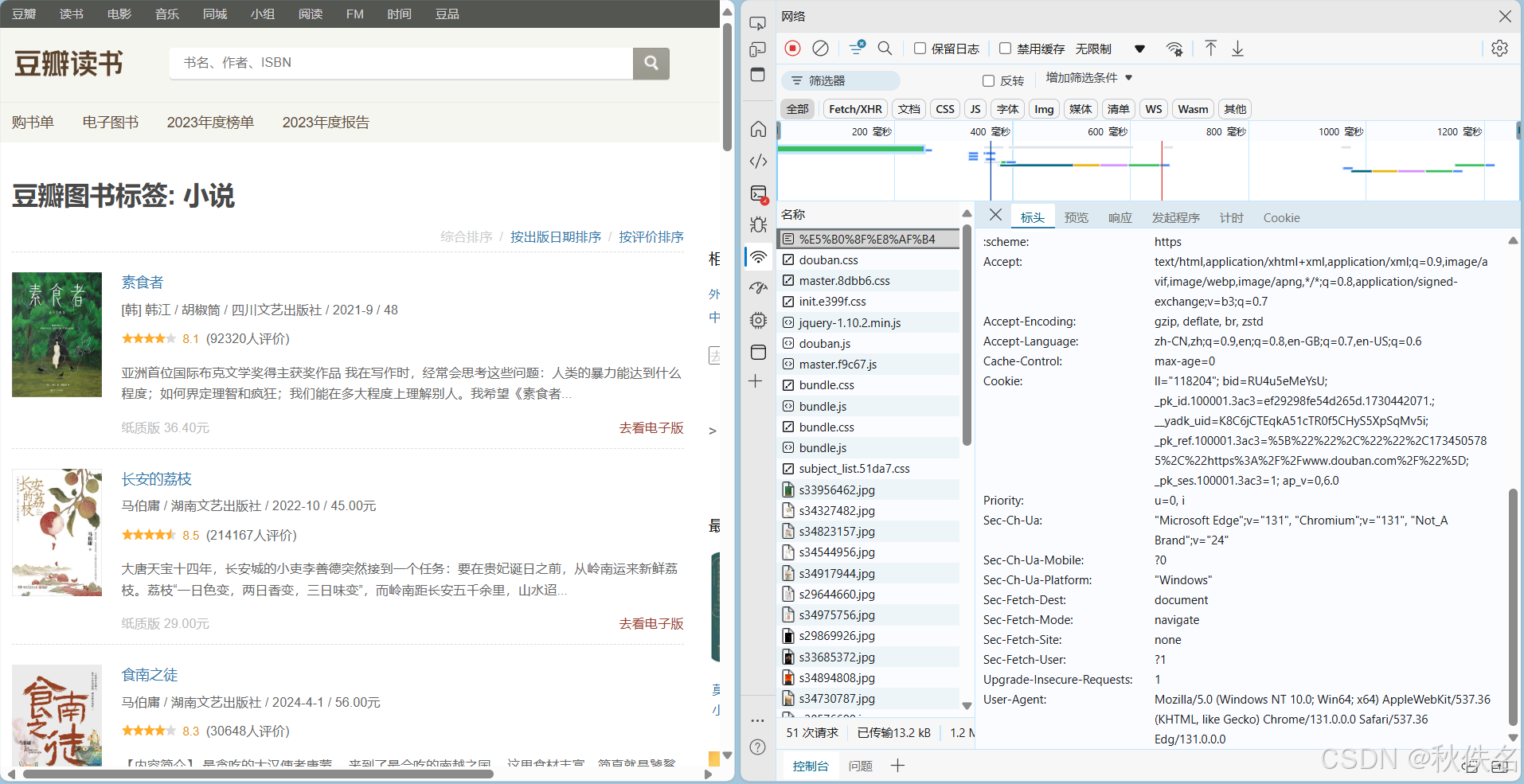
setCookies的获取在检查页选择网络,选择最上面的信息,复制里面的Cookie,代替下面图中的cookie_string。
def setCookies(web):
cookie_string = 'gr_user_id=2e7902c9-eab2-4401-b6cc-f05ea468c934; bid=nQ1f0GgSnYg; ll="118204"; _pk_id.100001.3ac3=d38c9a8cd567c783.1716875325.; viewed="1007305"; __yadk_uid=jT2gH2d0EXTfw5WTO56MNphXZCfT2Vxx; _pk_ses.100001.3ac3=1; ap_v=0,6.0; ct=y; dbcl2="280885228:VYStY/lphSI"; ck=SxuP; push_noty_num=0; push_doumail_num=0'
cookies = [] # 用于添加到driver内的cookies列表
for cookie in cookie_string.split(';'):
name = cookie.split('=')[0].strip()
value = cookie.split('=')[1].strip()
domain = '.douban.com'
cookies.append({
"name":name,
"value":value,
"domain":domain
})
for cookie in cookies:
web.add_cookie(cookie)函数接收一个参数web,这是一个Selenium WebDriver的实例,用于操作浏览器。cookie_string变量包含了多个cookies的信息,每个cookie由等号分割开的键值对组成,而不同的cookie之间以分号;分隔。
cookies = [],准备存放格式化后的cookies字典。遍历cookie_string中的每一部分(即每一个单独的cookie)。
将每个cookie按=分割,分别得到名字和值。名字和值两边可能存在空白字符,使用strip()去除。构建一个字典,包含name、value和domain三个字段,domain默认为'.douban.com'。
这里domain指定了cookie的有效域,意味着这个cookie只对.douban.com有效。把构造好的字典添加进cookies列表。
再次遍历cookies列表,对每一条cookie调用web.add_cookie()方法,将其添加到WebDriver实例上。这样一来,所有处理过的cookies都会被添加到web中,随后的任何请求都将携带这些cookies进行。
def getListPage(web, page, f):
global dbs_id
for i in range(0, page * 20, 20):
web.get(f"https://book.douban.com/tag/%E4%BC%A0%E8%AE%B0?start={i}&type=T")
dbs_lis = web.find_elements(By.XPATH, '//*[@id="subject_list"]/ul/li')
for dbs in dbs_lis:
dbs_id = dbs_id +1
book = "".join(dbs.find_element(By.XPATH, './div[2]/h2/a').text)
intel = dbs.find_element(By.XPATH, './div[2]/div[1]').text
parts = intel.rsplit(',', 2)
if len(parts) >= 3:
data = parts[-2].strip()
price = parts[-1].strip()
else:
data = ""
price = ""
url = dbs.find_element(By.XPATH, './div[1]/a').get_property("href")
print(dbs_id, book, data, price, url)
f.write(f"{dbs_id},{book},{data},{price},{url}\n")
web.implicitly_wait(20)
time.sleep(3)该函数getListPage的目标是从豆瓣图书的特定标签下抓取多页数据,数据包括书籍名称、出版日期、价格和链接,然后把这些信息保存到CSV文件中。
在开头设置全局变量dbs_id,用来记录书籍编号。
接收三个参数:web (Selenium WebDriver实例),page (要抓取的总页数), 和 f (文件句柄,用于写入数据)
循环次数取决于page参数,每次请求间隔20条记录。
每次请求的URL通过web.get()构造,利用动态拼接字符串的方式生成带参数的URL,start参数控制起始位置,实现翻页。
使用XPath选择器'//*[@id="subject_list"]/ul/li'找到所有的书籍元素。对每个<li>元素进行遍历,从中提取书籍详情。提取书籍标题、出版信息、发布日期、价格和链接。
URL通过 './div[1]/a' 的href属性取得。出版信息通过 './div[2]/div[1]' 获取,进一步处理成发布日期和价格。标题通过XPath './div[2]/h2/a'选取。
使用print输出当前书籍的信息。同时,将信息写入文件,采用CSV格式。
使用web.implicitly_wait(20)设置隐式等待,确保元素完全加载完成后再继续执行,提高稳定性。time.sleep(3) 引入额外的时间等待,防止因速度过快导致的问题。
至此为止,我们爬取了豆瓣书籍页的信息。完整代码如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
dbs_id = 0
def setCookies(web):
cookie_string = 'gr_user_id=2e7902c9-eab2-4401-b6cc-f05ea468c934; bid=nQ1f0GgSnYg; ll="118204"; _pk_id.100001.3ac3=d38c9a8cd567c783.1716875325.; viewed="1007305"; __yadk_uid=jT2gH2d0EXTfw5WTO56MNphXZCfT2Vxx; _pk_ses.100001.3ac3=1; ap_v=0,6.0; ct=y; dbcl2="280885228:VYStY/lphSI"; ck=SxuP; push_noty_num=0; push_doumail_num=0'
cookies = [] # 用于添加到driver内的cookies列表
for cookie in cookie_string.split(';'):
name = cookie.split('=')[0].strip()
value = cookie.split('=')[1].strip()
domain = '.douban.com'
cookies.append({
"name":name,
"value":value,
"domain":domain
})
for cookie in cookies:
web.add_cookie(cookie)
def getListPage(web, page, f):
global dbs_id
for i in range(0, page * 20, 20):
web.get(f"https://book.douban.com/tag/%E4%BC%A0%E8%AE%B0?start={i}&type=T")
dbs_lis = web.find_elements(By.XPATH, '//*[@id="subject_list"]/ul/li')
for dbs in dbs_lis:
dbs_id = dbs_id +1
book = "".join(dbs.find_element(By.XPATH, './div[2]/h2/a').text)
intel = dbs.find_element(By.XPATH, './div[2]/div[1]').text
parts = intel.rsplit(',', 2)
if len(parts) >= 3:
data = parts[-2].strip()
price = parts[-1].strip()
else:
data = ""
price = ""
url = dbs.find_element(By.XPATH, './div[1]/a').get_property("href")
print(dbs_id, book, data, price, url)
f.write(f"{dbs_id},{book},{data},{price},{url}\n")
web.implicitly_wait(20)
time.sleep(3)
def main():
page_count = 51
f = open("dbs_list.csv", mode='a', encoding='utf-8')
f.write(f"dbs_id,book,data,price,url\n")
web = webdriver.Chrome()
web.get("https://www.douban.com/")
setCookies(web)
getListPage(web, page_count, f)
time.sleep(5)
web.quit()
f.close()
if __name__ == '__main__':
main()
二、详情页及评论
详情页我们选择爬取书名,作者,出版社,书籍评分和评论数,以及当前页面的短评,评论的爬取并未在第三级页面。
from selenium.common.exceptions import NoSuchElementException这一行代码的作用是从Selenium的异常模块中导入了NoSuchElementException类。在使用Selenium进行Web自动化操作时,这个异常是非常常见的,尤其是在尝试定位页面元素但元素不存在的情况下。
def main():
f = open("dbs_deatil.csv", mode='a', encoding='utf-8')
f.write(f'dbs_id,book,author,cbs,pf,db_comment\n')
f1 = open("dbs_comment.csv", mode='a', encoding='utf-8')
f1.write(f'dbs_id,comment_id,book,comment\n')
web = webdriver.Chrome()
web.get("https://www.douban.com/")
setCookies(web)
dbs_items = getGoodsDetailUrl(web)
for dbs_item in dbs_items[:]:
dbs_item = dbs_item.split(",")
dbs_id = dbs_item[0].strip()
url = dbs_item[-1].strip()
get_detail_page(web, dbs_id, url, f, f1)
web.close()
f.close()
if __name__ == '__main__':
main()我们仍然从main函数开始,这段代码旨在从豆瓣网站抓取书籍的详细信息以及相关评论,具体流程包括初始化文件、浏览器、设置cookies、获取商品详情页面URL,然后遍历这些URL以抓取更多细节及评论数据。
创建两个CSV文件,一个是dbs_deatil.csv,另一个是dbs_comment.csv,均采用追加模式和UTF-8编码。
分别写入各自的表头行,dbs_deatil.csv有dbs_id,book,author,cbs,pf,db_comment,而dbs_comment.csv有dbs_id,comment_id,book,comment。
创建一个Chrome WebDriver实例,这将启动一个Chrome浏览器窗口。
使浏览器导航至豆瓣官网。
调用setCookies函数,假设其目的是为了维护登录状态或一些特定的身份验证需求。
调用getGoodsDetailUrl函数返回一个URL列表,其中每个元素代表一个商品的详情页面链接。
对获取到的每个URL进行遍历。
URL前会被预处理,分割成dbs_id和url两部分。
调用get_detail_page函数,传递当前dbs_id、URL及文件句柄f和f1,用于后续的数据抓取。
关闭浏览器窗口和两个CSV文件。
确保直接运行此文件时才调用main函数开始执行。
def get_detail_page(web, dbs_id, url, f, f1):
web.get(url)
book = web.find_element(By.XPATH, '//*[@id="wrapper"]/h1/span').text
author = web.find_element(By.XPATH, '//*[@id="info"]/span[1]').text
try:
cbs = web.find_element(By.XPATH, '//*[@id="info"]/a[1]').text
except NoSuchElementException:
cbs = "未知出版社"
pf = web.find_element(By.XPATH, '//*[@id="interest_sectl"]/div/div[2]/strong').text
try:
db_comment = web.find_element(By.XPATH, '//*[@id="comments-section"]/div[1]/h2/span[2]/a').text
except NoSuchElementException:
db_comment = "未知"
print(dbs_id, book, author, cbs, pf, db_comment)
f.write(f'{dbs_id}, {book}, {author}, {cbs}, {pf}, {db_comment}\n')
getComments(dbs_id, book, web, f1)这段代码主要功能是抓取单个书籍的详细信息,并调用另一函数抓取评论。
使用web.get(url)打开指定的书籍详情页面。
通过XPath定位并获取书名book,作者author,出版社cbs,评分pf,和豆瓣评论数量db_comment。
如果出版社信息不可得,则设定为"未知出版社"。
如果评论数量不可得,则设定为"未知"。
使用try-except结构来处理NoSuchElementException,确保即使页面中缺少某项信息也不致程序中断。
将抓取到的所有信息打印到控制台。
将相同信息写入文件f,以便永久保存。
调用getComments函数,传入书籍ID、书名和web对象,用于抓取并处理书籍的评论。
def getComments(dbs_id, book, web, f1):
global comment_id
dp = web.find_elements(By.XPATH, '//*[@id="score"]/ul/li')
for element in dp:
comment_id += 1
try:
comment = element.find_element(By.XPATH, './div/p/span').text
except NoSuchElementException:
print("评论没有数据")
return
print(comment_id, comment)
f1.write(f'{dbs_id},{comment_id}, {book}, {comment}\n')这段代码的功能是抓取书籍评论,并将评论信息写入文件。这里是详细的代码解析:
利用XPath '//*[@id="score"]/ul/li' 定位到所有评论项目。dp 变量储存了这些元素的集合。
针对每个评论元素(element),递增comment_id作为评论标识符。
尝试使用By.XPATH './div/p/span' 来获取具体的评论内容。
如果元素不存在,抛出NoSuchElementException异常,此时打印提示“评论没有数据”,并提前结束函数执行。
如果评论内容成功获取,打印出来并在文件f1中记录。
每条评论的格式是:书籍ID,评论ID,书名,评论内容。使用逗号分隔后写入文件。
在这里便可以将爬取的数据在爬取的同时一并上传至MySQL和MongoDB中,但我当时是边写边改,为了减少每次爬取的工作量,选择在将所有数据爬取完后再将数据上传。
详情页及评论爬取完整代码如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
dbs_id = 0
comment_id = 0
def setCookies(web):
cookie_string = 'gr_user_id=2e7902c9-eab2-4401-b6cc-f05ea468c934; bid=nQ1f0GgSnYg; ll="118204"; _pk_id.100001.3ac3=d38c9a8cd567c783.1716875325.; viewed="1007305"; __yadk_uid=jT2gH2d0EXTfw5WTO56MNphXZCfT2Vxx; _pk_ses.100001.3ac3=1; ap_v=0,6.0; ct=y; dbcl2="280885228:VYStY/lphSI"; ck=SxuP; push_noty_num=0; push_doumail_num=0'
cookies = [] # 用于添加到driver内的cookies列表
for cookie in cookie_string.split(';'):
name = cookie.split('=')[0].strip()
value = cookie.split('=')[1].strip()
domain = '.douban.com'
cookies.append({
"name":name,
"value":value,
"domain":domain
})
for cookie in cookies:
web.add_cookie(cookie)
def get_detail_page(web, dbs_id, url, f, f1):
web.get(url)
book = web.find_element(By.XPATH, '//*[@id="wrapper"]/h1/span').text
author = web.find_element(By.XPATH, '//*[@id="info"]/span[1]').text
try:
cbs = web.find_element(By.XPATH, '//*[@id="info"]/a[1]').text
except NoSuchElementException:
cbs = "未知出版社"
pf = web.find_element(By.XPATH, '//*[@id="interest_sectl"]/div/div[2]/strong').text
try:
db_comment = web.find_element(By.XPATH, '//*[@id="comments-section"]/div[1]/h2/span[2]/a').text
except NoSuchElementException:
db_comment = "未知"
print(dbs_id, book, author, cbs, pf, db_comment)
f.write(f'{dbs_id}, {book}, {author}, {cbs}, {pf}, {db_comment}\n')
getComments(dbs_id, book, web, f1)
def getComments(dbs_id, book, web, f1):
global comment_id
dp = web.find_elements(By.XPATH, '//*[@id="score"]/ul/li')
for element in dp:
comment_id += 1
try:
comment = element.find_element(By.XPATH, './div/p/span').text
except NoSuchElementException:
print("评论没有数据")
return
print(comment_id, comment)
f1.write(f'{dbs_id},{comment_id}, {book}, {comment}\n')
def getGoodsDetailUrl(web):
f = open("dbs_list.csv", mode='r', encoding='utf-8')
lines = f.readlines()
return lines[1:]
def main():
f = open("dbs_deatil.csv", mode='a', encoding='utf-8')
f.write(f'dbs_id,book,author,cbs,pf,db_comment\n')
f1 = open("dbs_comment.csv", mode='a', encoding='utf-8')
f1.write(f'dbs_id,comment_id,book,comment\n')
web = webdriver.Chrome()
web.get("https://www.douban.com/")
setCookies(web)
dbs_items = getGoodsDetailUrl(web)
for dbs_item in dbs_items[:]:
dbs_item = dbs_item.split(",")
dbs_id = dbs_item[0].strip()
url = dbs_item[-1].strip()
get_detail_page(web, dbs_id, url, f, f1)
web.close()
f.close()
if __name__ == '__main__':
main()三、作者页
前面的评论本应该在三级页面进行爬取,但是我选择爬取详情页中自带的短评,所以在这里补充三级页面,通过详情页到达作者页。
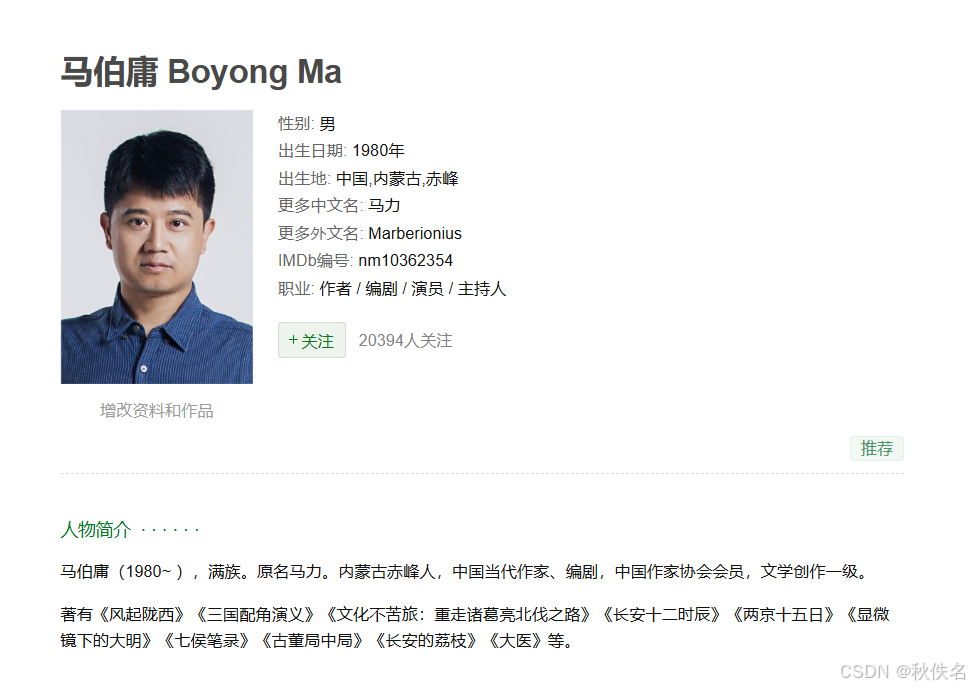
我们爬取最上方的名字,以及右边的作者信息,因为右边的作者信息并不固定,有多有少,有的甚至空空如也,所以我们不再挨个爬取,我们爬取整个信息框。
def main():
f = open("dbs_author.csv", mode='a', encoding='utf-8')
f.write(f'dbs_id,author,inf\n')
web = webdriver.Chrome()
web.get("https://www.douban.com/")
setCookies(web)
dbs_items = getAuthorlUrl(web)
for dbs_item in dbs_items[:]:
dbs_item = dbs_item.split(",")
dbs_id = dbs_item[0].strip()
url = dbs_item[-1].strip()
get_detail_page(web, dbs_id, url, f)
web.close()
f.close()
if __name__ == '__main__':
main()这段代码的主要目的从豆瓣网站抓取作者相关信息:
打开或创建一个名为dbs_author.csv的文件,准备写入作者信息。文件采用追加模式和UTF-8编码,并预先写入列标题dbs_id,author,inf。
初始化Chrome WebDriver实例,即启动一个新的Chrome浏览器会话。
浏览器导航至豆瓣网站的首页。
调用setCookies函数,通常是为了保持登录状态或其他身份验证需求,以确保后续操作不受限制。
调用getAuthorlUrl函数,获取一系列包含作者详情页面URL的列表。
遍历获取到的URL列表。
每个URL首先被按照逗号拆分为dbs_id和实际的URL地址。
然后调用get_detail_page函数,传入dbs_id、URL和之前打开的文件句柄f。
关闭浏览器窗口和已打开的文件。
def get_detail_page(web, dbs_id, url, f):
try:
web.get(url)
except Exception as e:
print("获取网页失败:", e)
return "未能获取网页,请检查链接。"
try:
author = web.find_element(By.XPATH, '//*[@id="info"]/span[1]/a').text
except NoSuchElementException:
author = "未知"
author_elements = web.find_elements(By.XPATH, '//*[@id="info"]/span[1]/a')
if author_elements:
author_elements[0].click()
else:
print("")
try:
inf = web.find_element(By.XPATH, '/html/body/div[3]/div[1]/div/div[1]/section[1]/div[1]/div[2]/ul')
inf_text = inf.text.replace('\n', ' / ')
except NoSuchElementException:
inf_text = "作者信息尚未填写"
print(dbs_id, author, inf_text)
f.write(f'{dbs_id}, {author}, {inf_text}\n')这段代码的目标是在豆瓣网站上抓取作者的详细信息,具体包括作者名称和作者的额外信息,如简介或经历等。
尝试通过web.get(url)访问给定的作者详情页。
若出现异常(如网络问题、超时等),则捕获异常,输出错误信息,并返回一条友好的消息建议检查链接是否正确。
通过XPath '//*[@id="info"]/span[1]/a' 获取作者姓名。
如果该元素不存在,将作者设为“未知”。
再次尝试获取相同的元素列表,如果列表不为空,点击第一个元素。
此步可能是为了进入作者的个人主页或展开更多信息。
尝试定位更深入的信息部分,利用XPath '/html/body/div[3]/div[1]/div/div[1]/section[1]/div[1]/div[2]/ul'。
若信息缺失,设默认值为“作者信息尚未填写”。
抓取到的内容可能包含换行符\n,使用replace方法替换成空格分隔的斜杠/,便于阅读和写入文件。
将抓取到的dbs_id、作者名字和详细信息打印出来。
同样,将这些信息以逗号分隔的形式写入文件f。
def getAuthorlUrl(web):
f = open("dbs_list.csv", mode='r', encoding='utf-8')
lines = f.readlines()
return lines[1:]这个函数getAuthorlUrl的目的是从一个名为dbs_list.csv的文件中读取除首行之外的所有行,这些行通常包含了待抓取的作者详情页的URLs。
以只读模式和UTF-8编码方式打开dbs_list.csv文件。
调用readlines()方法一次性读取文件中的所有行,每一行作为一个元素储存在list中。
返回除了列表的第一行外的所有行。这通常是因为第一行往往是表头或者不必要的信息,不包含实际的URL数据。
以下是作者页完整代码:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
dbs_id = 0
def setCookies(web):
cookie_string = 'gr_user_id=2e7902c9-eab2-4401-b6cc-f05ea468c934; bid=nQ1f0GgSnYg; ll="118204"; _pk_id.100001.3ac3=d38c9a8cd567c783.1716875325.; viewed="1007305"; __yadk_uid=jT2gH2d0EXTfw5WTO56MNphXZCfT2Vxx; _pk_ses.100001.3ac3=1; ap_v=0,6.0; ct=y; dbcl2="280885228:VYStY/lphSI"; ck=SxuP; push_noty_num=0; push_doumail_num=0'
cookies = [] # 用于添加到driver内的cookies列表
for cookie in cookie_string.split(';'):
name = cookie.split('=')[0].strip()
value = cookie.split('=')[1].strip()
domain = '.douban.com'
cookies.append({
"name":name,
"value":value,
"domain":domain
})
for cookie in cookies:
web.add_cookie(cookie)
def get_detail_page(web, dbs_id, url, f):
try:
web.get(url)
except Exception as e:
print("获取网页失败:", e)
return "未能获取网页,请检查链接。"
try:
author = web.find_element(By.XPATH, '//*[@id="info"]/span[1]/a').text
except NoSuchElementException:
author = "未知"
author_elements = web.find_elements(By.XPATH, '//*[@id="info"]/span[1]/a')
if author_elements:
author_elements[0].click()
else:
print("")
try:
inf = web.find_element(By.XPATH, '/html/body/div[3]/div[1]/div/div[1]/section[1]/div[1]/div[2]/ul')
inf_text = inf.text.replace('\n', ' / ')
except NoSuchElementException:
inf_text = "作者信息尚未填写"
print(dbs_id, author, inf_text)
f.write(f'{dbs_id}, {author}, {inf_text}\n')
def getAuthorlUrl(web):
f = open("dbs_list.csv", mode='r', encoding='utf-8')
lines = f.readlines()
return lines[1:]
def main():
f = open("dbs_author.csv", mode='a', encoding='utf-8')
f.write(f'dbs_id,author,inf\n')
web = webdriver.Chrome()
web.get("https://www.douban.com/")
setCookies(web)
dbs_items = getAuthorlUrl(web)
for dbs_item in dbs_items[:]:
dbs_item = dbs_item.split(",")
dbs_id = dbs_item[0].strip()
url = dbs_item[-1].strip()
get_detail_page(web, dbs_id, url, f)
web.close()
f.close()
if __name__ == '__main__':
main()四、京东书籍
通过上面的代码我们成功爬取了豆瓣书籍的信息,现在我们将爬取到的书籍信息输入到京东中,查看书籍在京东的店铺,我们爬取前20本书的店铺,只爬取第一页,每本30条信息。
本页面爬取只是作为拓展。
def main():
keywords = get_keywords_from_db()
with open("dbs_jd.csv", mode="a", encoding="utf-8") as f:
f.write("jd_id,jd_nm,jd_jg,jd_url\n")
web = webdriver.Chrome()
for keyword in keywords:
get_lp(web, f, keyword)
web.close()
if __name__ == '__main__':
main()这段代码的主要任务是从数据库或某个地方获取关键词列表,并针对每一个关键词搜索相关职位信息,然后将收集的数据写入CSV文件中。
调用get_keywords_from_db()函数,假设这个函数会从数据库或其他来源获取一组关键词。
使用with语句安全地打开dbs_jd.csv文件,采用追加模式和UTF-8编码,准备写入职位信息。
写入初始列名jd_id,jd_nm,jd_jg,jd_url。
创建一个Chrome WebDriver实例,用于自动化浏览器操作。
对于keywords中的每个关键词:
调用get_lp(web, f, keyword),这里假设get_lp函数实现搜索及抓取过程,可能会基于关键词搜索并解析相应的职位数据,然后写入文件f。
循环结束后,关闭WebDriver实例,确保浏览器正常退出。
def get_keywords_from_db():
keywords = []
with open("dbs_list.csv", mode='r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines[1:21]:
keyword = line.strip().split(',')[1]
keywords.append(keyword)
return keywords这段代码旨在从dbs_list.csv文件中读取特定行的数据,并从中提取关键词。
使用with语句安全地打开dbs_list.csv文件,设定读取模式为'r'(仅读)和编码为utf-8。
调用readlines()方法来读取文件中的所有行,并将它们存为一个列表。
遍历从第二行开始直到第21行的每一行数据(共计20行)。这是因为我们假定第一行通常是列名而非数据,因此跳过。
使用.strip()移除每行开头和结尾的空白字符。
然后使用,作为分隔符将行分割成若干部分。
提取第二个元素(索引为1的部分)作为关键词,并添加到keywords列表中。
最终,函数返回一个由提取出来的关键词组成的列表。
def get_lp(web, f, book):
global jd_id
web.get("https://www.jd.com/")
web.implicitly_wait(30)
time.sleep(1)
search_box = web.find_element(By.XPATH, '//*[@id="key"]')
search_box.clear()
search_box.send_keys(book)
dj = web.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button').click()
web.execute_script('window.scrollTo(0, 3000)')
web.execute_script('window.scrollTo(0, 6000)')
web.execute_script('window.scrollTo(0, 9000)')
time.sleep(2)
jd_lis = web.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li')
for jd in jd_lis:
jd_id += 1
jd_nm = jd.find_element(By.XPATH, './div/div[3]/a/em').text.replace("\n", "").strip()
jd_jg = jd.find_element(By.XPATH, './div/div[2]/strong/i').text
jd_url = jd.find_element(By.XPATH, './div/div[3]/a').get_property("href")
print(f"{jd_id},{jd_nm},{jd_jg},{jd_url}")
f.write(f"{jd_id},{jd_nm},{jd_jg},{jd_url}\n")
web.implicitly_wait(20)
time.sleep(1)这段代码的目的在于使用Selenium WebDriver自动化工具在京东网站上搜索书籍并抓取商品信息,包括商品ID、名称、价格和链接。
导航至京东首页https://www.jd.com/,并等待页面完全加载,最长等待时间为30秒。
强制等待1秒,确保页面充分渲染。
定位搜索框,并清空现有文本。
输入book变量所代表的关键词。
触发搜索按钮进行搜索。
使用JavaScript执行三次垂直滚动命令,每次增加3000像素,以便加载更多的商品项。这是为了避免由于页面懒加载机制导致的商品信息无法全部显示。
一旦页面稳定,使用XPath定位所有的商品列表项。
针对每个找到的商品项jd:
自增jd_id以生成唯一的商品ID。
提取商品名称,清除其中的换行符和多余空白。
获取商品价格。
取得商品URL链接。
输出和写入商品ID、名称、价格和URL至文件。
设置隐式等待时间,确保元素加载完成。
添加1秒的强制等待,提供缓冲时间。
至此我们获取了豆瓣书籍在京东店铺情况的数据。
以下是完整代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
jd_id = 0
def setCookies(web):
cookie_string = 'shshshfpa=ebd732bc-2a0d-9a8a-d064-d494ad8dec9a-1689234841; shshshfpx=ebd732bc-2a0d-9a8a-d064-d494ad8dec9a-1689234841; __jdu=16892348425801526709662; qrsc=3; unpl=JF8EAMpnNSttUENRBRwETkJHHlpUWw5YHB9RbTMBB1peGVFWTFVJRUV7XlVdWBRKEB9vYhRUXFNKUw4fACsSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrAhwbGEhfUVdYC08eAm9jBlNbWUNTAhgyGiIXe21kXl4ASxcBX2Y1VW0aHwgFHgQeExYGXVNXVQtJEgpqZAFdXFhPVwIdAxMVF0htVW5e; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_994167dafd614baf9c3e5b67c4bffcfd|1718330811996; 3AB9D23F7A4B3CSS=jdd03UVVMYYH5IGRIXHZ4INZS4R2S4FWLYLXV7UQ3LRHM5KOBOUCDMHDQHZ2UJHJJFMMGNX7W2N2CWH77MLO3OWE2UFPA54AAAAMQCR7XCYAAAAAACKXDN362QJZKFAX; areaId=16; ipLoc-djd=16-1332-0-0; mba_muid=16892348425801526709662; mba_sid=17183308227464828707410655728.1; wlfstk_smdl=kke85vljrnocssu5fjlu49bbksrq7x6r; TrackID=1-z2Wncz6qQ5zfRyCGY9aq9j4-MSEG2zYLYXnA9-OxRRriIlrCqhbFT967-iDtA8epmUC8w6CDp3weED5XeqeqVMt3H58Y428YyChdxZdl9KvLlfl7oVYWVnMbCoNlpgQ; thor=6EC8BCF205999EBA01121C8E46594AF767376263039E89D37C8F3AE178AF17B6E4AEE0E244C1D64269EBF8680C2A659C1029BCC2082105E37F5B9026E7CC44C93FFEA2F8AD5053F90AA6DE0B1CDB35F4CD12ECDA990676F6C84B7D823300325512CD2B6B7B0448FAF7A00AC2F2B39BE4110F6A4BE986DD22A308AE0E78EF2CD56EA412E7ECA73F647E21A9925B325F053AE9B9B7002D61551DA3E18A057B5994; flash=2_LgJdtcpPrOh3rwCW2C5QnNsFTRAisQnmWC35OZySsrskjVtXqTCsF43q8lEMol7B8n1h0NAW4v2nB_e8enDWMIeCSv3Mfh9_t5bO6-B768nRuJJOx8fZhcCdtgEpKC4c9QPZezAMxKNBCKyWgZjCabhs4M2uqqsV1inZeifFC6p*; pinId=R9bUD1VrOjsY6uirjfq1KQ; pin=jd_IaJFPopnKDyv; unick=jd_cgb8h6js7qct7l; ceshi3.com=000; _tp=%2BNMCMtAQdpfN5Pai8fpvpA%3D%3D; _pst=jd_IaJFPopnKDyv; jsavif=1; jsavif=1; xapieid=jdd03UVVMYYH5IGRIXHZ4INZS4R2S4FWLYLXV7UQ3LRHM5KOBOUCDMHDQHZ2UJHJJFMMGNX7W2N2CWH77MLO3OWE2UFPA54AAAAMQCR7XCYAAAAAACKXDN362QJZKFAX; __jda=143920055.16892348425801526709662.1689234843.1718277905.1718330812.10; __jdb=143920055.4.16892348425801526709662|10.1718330812; __jdc=143920055; rkv=1.0; shshshfpb=BApXct5WIF_VAIZys2Ep0PmKtveMWS11AB8tiT25X9xJ1MndvzIO2; 3AB9D23F7A4B3C9B=UVVMYYH5IGRIXHZ4INZS4R2S4FWLYLXV7UQ3LRHM5KOBOUCDMHDQHZ2UJHJJFMMGNX7W2N2CWH77MLO3OWE2UFPA54'
cookies = [] # 用于添加到driver内的cookies列表
for cookie in cookie_string.split(';'):
name = cookie.split('=')[0].strip()
value = cookie.split('=')[1].strip()
domain = '.douban.com'
cookies.append({
"name":name,
"value":value,
"domain":domain
})
for cookie in cookies:
web.add_cookie(cookie)
def get_keywords_from_db():
keywords = []
with open("dbs_list.csv", mode='r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines[1:21]:
keyword = line.strip().split(',')[1]
keywords.append(keyword)
return keywords
def get_lp(web, f, book):
global jd_id
web.get("https://www.jd.com/")
web.implicitly_wait(30)
time.sleep(1)
search_box = web.find_element(By.XPATH, '//*[@id="key"]')
search_box.clear()
search_box.send_keys(book)
dj = web.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button').click()
web.execute_script('window.scrollTo(0, 3000)')
web.execute_script('window.scrollTo(0, 6000)')
web.execute_script('window.scrollTo(0, 9000)')
time.sleep(2)
jd_lis = web.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li')
for jd in jd_lis:
jd_id += 1
jd_nm = jd.find_element(By.XPATH, './div/div[3]/a/em').text.replace("\n", "").strip()
jd_jg = jd.find_element(By.XPATH, './div/div[2]/strong/i').text
jd_url = jd.find_element(By.XPATH, './div/div[3]/a').get_property("href")
print(f"{jd_id},{jd_nm},{jd_jg},{jd_url}")
f.write(f"{jd_id},{jd_nm},{jd_jg},{jd_url}\n")
web.implicitly_wait(20)
time.sleep(1)
def main():
keywords = get_keywords_from_db()
with open("dbs_jd.csv", mode="a", encoding="utf-8") as f:
f.write("jd_id,jd_nm,jd_jg,jd_url\n")
web = webdriver.Chrome()
for keyword in keywords:
get_lp(web, f, keyword)
web.close()
if __name__ == '__main__':
main()五、数据上传
接下来将我们爬取的数据进行上传处理,以便数据的保存。
我们先将数据存入MySQL中:
import csv
from pymongo import MongoClient
# MongoDB 连接信息
mongodb_client = MongoClient('mongodb://localhost:27017/')
db = mongodb_client['douban'] # 替换为你的数据库名
# 添加数据到 MongoDB 的函数
def add_one(database, collection_name, data):
collection = database[collection_name]
result = collection.insert_one(data)
return result
# 读取 CSV 文件并保存到 MongoDB
def save_to_mongo_from_csv(db, csv_file):
try:
with open(csv_file, 'r', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
# 假设 'dbs_id' 是整数类型,确保类型转换
data_dict = {
"dbs_id": int(row['dbs_id']),
"author": row['author'],
"inf": row['inf']
}
# 保存到 MongoDB
result = add_one(db, "dbs_author", data_dict)
print("Inserted:", result.inserted_id)
except Exception as e:
print("Error saving to MongoDB:", e)
# 主程序入口
if __name__ == "__main__":
csv_file = 'dbs_author.csv' # CSV 文件路径
save_to_mongo_from_csv(db, csv_file)
mongodb_client.close() # 关闭 MongoDB 客户端连接
这段Python代码主要负责从CSV文件读取数据并将这些数据插入到MongoDB的一个集合中。
使用MongoClient创建一个客户端对象,连接本地的MongoDB服务(默认地址:localhost, 默认端口:27017)。
指定要使用的数据库,这里是douban。
add_one函数接收三个参数:数据库实例、集合名称和数据字典。
通过数据库实例和集合名定位到对应的集合。
使用insert_one方法向集合中插入一条文档(即字典形式的数据)。
返回插入操作的结果。
打开CSV文件,使用DictReader按行读取数据,自动将每一行转化为字典格式,方便后续操作。
遍历读取的每一行数据,进行必要的数据类型转换(例如将dbs_id转为整型)。
构造数据字典,包括dbs_id、author和inf三项。
调用add_one函数,将数据保存到MongoDB。
包装整个读取和插入过程在一个try-except块内,捕获并打印可能出现的任何异常。
设定CSV文件路径。
调用save_to_mongo_from_csv函数,传入数据库实例和CSV文件路径。
结束后,确保关闭MongoDB客户端连接。
随后我们再将数据上传至MongoDB,以下代码包含的MongoDB基本的存储操作:
import pymongo
def get_db(database):
conn = pymongo.MongoClient(host='localhost', port=27017)
db = conn[database]
return conn, db # 返回连接对象和数据库对象
def add_one(db, table, data):
result = db[table].insert_one(data)
return result
def add_many(db, table, data_list):
result = db[table].insert_many(data_list)
return result
def upd(db, table, condition, data):
result = db[table].update_many(condition, {'$set':data})
return result
def delete(db, table, condition):
result = db[table].delete_many(condition)
return result
def query(db, table, condition=''):
result = db[table].find(condition)
return result
这段Python代码定义了一系列函数,用于与MongoDB数据库交互,包括连接数据库、添加单个文档、批量添加文档、更新文档、删除文档以及查询文档等操作。下面是各函数的详细解释:
数据库连接 (get_db):接受数据库名称作为参数。创建MongoDB客户端,使用给定主机和端口号。返回连接对象和数据库对象,以便后续操作。
添加单个文档 (add_one):接收数据库对象、集合名称和要插入的文档数据。调用insert_one方法插入文档。返回插入结果。
批量添加文档 (add_many):类似于add_one,但是接收文档列表。利用insert_many方法批量插入多个文档。返回批量插入的结果。
更新文档 (upd):更新满足条件的文档。参数包括数据库对象、集合名称、筛选条件和新的数据。
使用update_many方法更新所有符合条件的文档,$set用于指定具体修改哪些字段。
删除文档 (delete):删除满足条件的文档。参数包括数据库对象、集合名称和删除条件。调用delete_many方法删除所有匹配的文档。
查询文档 (query):查询集合中满足条件的文档。参数包括数据库对象、集合名称和可选的筛选条件。返回查询结果游标,可用于遍历所有结果。
本博客是我学习中的一份记录,至此完整结束。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









