








http://spark.apache.org/docs/2.4.3/structured-streaming-programming-guide.html
建议看官网,官网最权威
注意点
1、该outputMode为update模式,即只会输出那些有更新的数据!!
2、该开窗窗口长度为10min,步长5min,水印为eventtime-10min,(需理解开窗规则)
3、官网案例trigger(Trigger.ProcessingTime("5 minutes")),但是测试的时候不建议使用这个
4、未输出数据不代表已经在内存中被剔除,只是由于update模式的原因
5、建议比对append理解水印
个人测试案例
object WaterMarkUpdate {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("chenchi").master("local[2]").getOrCreate()
import spark.implicits._
spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", "1234")
// .option("includeTimestamp", true) // 给产生的数据自动添加时间戳
.load()
.as[String]
.map(x=>{
val split: Array[String] = x.split(",")
(split(0),Timestamp.valueOf(split(1)))
})
.toDF("word", "time")
.withWatermark("time","10 minutes")
.groupBy(
window($"time", "10 minutes", "5 minutes"),
$"word"
)
.count()
.writeStream
.format("console")
.outputMode("update")
//.trigger(Trigger.ProcessingTime("5 minutes"))
.option("truncate","false")
.start()
.awaitTermination()
}
}测试数据和官网一样
dog,2019-09-25 12:07:00
owl,2019-09-25 12:08:00
dog,2019-09-25 12:14:00
cat,2019-09-25 12:09:00
cat,2019-09-25 12:15:00
dog,2019-09-25 12:08:00
owl,2019-09-25 12:13:00
owl,2019-09-25 12:21:00
owl,2019-09-25 12:17:00
第一次输入
dog,2019-09-25 12:07:00
owl,2019-09-25 12:08:00
得到结果

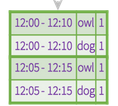
这个主要是因为我输入两条数据的时候两条数据时间有间隔,所以会出现两次,两次结果合起来和官网一样,
batch2输出的是因为update模式,不出输出dog,因为dog中的内容没有更新
第二次输入


与官网一样
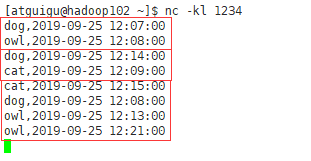
第三次输入数据
cat,2019-09-25 12:15:00
dog,2019-09-25 12:08:00
owl,2019-09-25 12:13:00
owl,2019-09-25 12:21:00

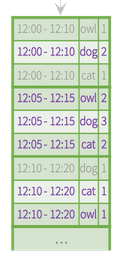
这个又是因为trigger时间没有设置,属于尽快模式,只输出更新内容,官网那里12:20下面那里.....省略了12:21owl这条数据的输出,这个不是我错了,
其实更新模式很简单,都不想写了再坚持一下。
第四次入内容
owl,2019-09-25 12:17:00
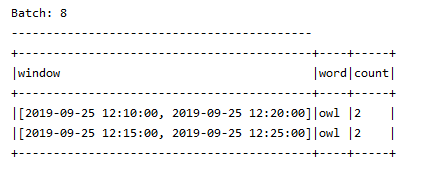

这个也是官网省略了一条记录,不是我这里多了一条记录,到这里明白发现我还是错了,就用那个trigger设置一下时间好点,这样显示结果容易观看,
其实个人觉得update模式有弊端,
1、数据已经被剔除,比如原先内存已经存了12:00-12:10 ,dog ,5 ,此时内存里有5个dog,但是到后面水印比如为12:20,根据水印,这个5个dog已经过期会在内存里被剔除,但是我新增一条数据 dog,12:24,结果会显示dog:6,这样根本看不出数据是否过期
当然有可能是我的想法太狭隘,感觉不到这个的好处
————————————————————————————————————————————————————————
下面我将解释下append模式下的 watermark作用

上述代码修改下
.outputMode("append").trigger(Trigger.ProcessingTime("3 minutes"))测试数据
dog,2019-09-25 12:07:00
owl,2019-09-25 12:08:00
dog,2019-09-25 12:14:00
cat,2019-09-25 12:09:00
cat,2019-09-25 12:15:00
dog,2019-09-25 12:08:00
owl,2019-09-25 12:13:00
owl,2019-09-25 12:21:00
donkey,2019-09-25 12:04:00
owl,2019-09-25 12:26:00
owl,2019-09-25 12:17:00
cat,2019-09-25 12:09:00
还是之前的数据
第一次输入
dog,2019-09-25 12:07:00
owl,2019-09-25 12:08:00
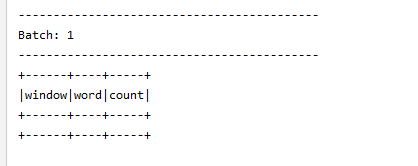
就是空数据!!官网也为空
第二次输入
dog,2019-09-25 12:14:00
cat,2019-09-25 12:09:00
没错还是空数据,官网也是空, 这又是为啥,稍后再说
第三次输入
cat,2019-09-25 12:15:00
dog,2019-09-25 12:08:00
owl,2019-09-25 12:13:00
owl,2019-09-25 12:21:00


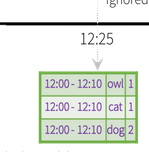
这里输出了两次
这里要说下,console输出的时候,有时候你输入一次,一下出来两个batch?。我觉得是你输入一次数据(一条数据或者一批),一批数据可能存在时间差,处理的时间不一样,就会出现多个batch,不知道我的猜想对不对
第四次输入
donkey,2019-09-25 12:04:00
owl,2019-09-25 12:26:00
owl,2019-09-25 12:17:00
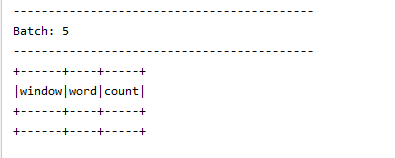


这里出现数据差异的原因
第五次输入
cat,2019-09-25 12:09:00
batch=null
附上一张统计表,比较直观点
| 数据内容 | 此时内存中的数据有 | 控制台输出的结果 | 解析 | |
| 第一次输入的数据 | dog,2019-09-25 12:07:00 owl,2019-09-25 12:08:00 | 12:00-12:10 dog 1 12:00-12:10 owl 1 12:05-12:15 dog 1 12:05-12:15 owl 1 | null | 无内存中的数据剔除 |
| 第二次输入的数据 | dog,2019-09-25 12:14:00 cat,2019-09-25 12:09:00 | 12:00-12:10 dog 1 12:00-12:10 owl 1 12:00-12:10 cat 1 12:05-12:15 dog 2 12:05-12:15 owl 1 12:05-12:15 cat 1 12:10-12:20 dog 1 | null | 无内存中的数据剔除 |
| 第三次输入的数据 | cat,2019-09-25 12:15:00 dog,2019-09-25 12:08:00 owl,2019-09-25 12:13:00 owl,2019-09-25 12:21:00 | 12:00-12:10 dog 2 12:00-12:10 owl 1 12:00-12:10 cat 1 12:05-12:15 dog 3 12:05-12:15 owl 2 12:05-12:15 cat 1 注意这个 12:10-12:20 dog 1 12:10-12:20 cat 1 12:10-12:20 owl 1 12:15-12:25 cat 1 12:15-12:25 owl 1 12:20-12:30 owl 1 | batch3:null和 Batch: 4 +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-09-25 12:00:00, 2019-09-25 12:10:00]|dog |2 | |[2019-09-25 12:00:00, 2019-09-25 12:10:00]|owl |1 | |[2019-09-25 12:00:00, 2019-09-25 12:10:00]|cat |1 | +------------------------------------------+----+-----+ | 此时这里的watermarke为12:21-10=12:11 这里输出了两段一段为空 一段中为小于12:11的所有数据,即表明这个watermark起了作用 |
| 第四次输入的数据 | donkey,2019-09-25 12:04:00 owl,2019-09-25 12:26:00 owl,2019-09-25 12:17:00 | 数据太多就不写了其中 donkey12:04<第三次的水印12:11 属于过期数据,不参与计算 | Batch: 5 null Batch: 6 |window |word|count| +------------------------------------------+----+-----+ |[2019-09-25 12:05:00, 2019-09-25 12:15:00]|owl |2 | |[2019-09-25 12:05:00, 2019-09-25 12:15:00]|dog |3 | |[2019-09-25 12:05:00, 2019-09-25 12:15:00]|cat |1 | +------------------------------------------+----+-----+ | 此时这里的watermark=12::26-10=12:16 batch6输出的内容是第三次输出数据后内存中<12:16的数据 12:00-12:10的已经被剔除了,所以此次剔除的是12:05-12:15中的数据 |
| 第四次输入的数据 | cat,2019-09-25 12:09:00 | cat同理过期 | batch7 :null | 此时没有输出,因为此时水印还是12:16,过期数据已经被删除完了 |
这里主要说明两点
1、我第四次输出结果是 owl 2 dog 3 cat 1 spark 结果是owl 2 dog 3 cat 2
出现差异的原因是,第三次输入的数据cat,2019-09-25 12:15:00这个的开窗出现了差异根据源码
* The windows are calculated as below:
* maxNumOverlapping <- ceil(windowDuration / slideDuration)
* for (i <- 0 until maxNumOverlapping)
* windowId <- ceil((timestamp - startTime) / slideDuration)
* windowStart <- windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTime
* windowEnd <- windowStart + windowDuration
* return windowStart, windowEnd
windowStart =12:15-ceil(10/5)*5=12:05 所以应该划分12:05-12:15 12:10-12:20这两个窗口
spark官方应该是划分为12:10-12:20 12:15-12:25,个人猜测.
2、就是输出时间的问题,我是在第三次和第四次输入数据后,控制台就打印了结果,spark官方图上显示的是第四次和第五次输出的结果 先来段spark官方原话
The engine waits for “10 mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window 12:00 - 12:10 is appended to the Result Table only after the watermark is updated to 12:11.
翻译:只有(只要)当水印=12:11的时候,之前的12:00 - 12:10 窗口数据就会被追加到结果表 即输出到控制台
是只有还是只要?第三次输入数据后水印已经到达12:11,然后就把12:00-12:10的数据输出了,同时这里有两个batch,个人感觉是只要
当一个批次的数据的时候,structured-streaming 先获得最大的水印,然后排除那些同批次的过期数据,然后会把一个批次的数据全部加载进内存计算出结果后,再剔除过期的内存数据
如果划分到一条条数据,有个疑问,是此条最大水印的数据输入后,立马开始清理内存,还是在下一条数据来临的时候再清理
欢迎大家探讨,这个只是自己学习时的一点想法,不一定正确,欢迎批评,但别太严厉。。。。。。















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









