







学习主要参考菜鸟教程 https://www.runoob.com/r/r-data-types.html 加上一些个人理解,可以直接去菜鸟教程直接看
R 语言中的最基本数据类型主要有三种:
- 数字
- 逻辑
- 文本
首先我们要明白R语言是做什么的,R语言貌似主要做图计算。。。。暂时理解后面学习了再说
一、数字类型

赋值方式有三种 = -> <-
a = 1
b <- 2
3 -> c
d = a //因为a 已经有值a=1,所以可以把a赋值给d
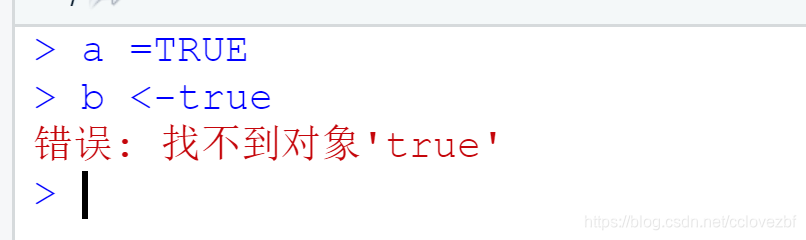
f = g //g不知道是啥 不是数字也不是另外一种数据类型文本 报错【错误: 找不到对象'g'】二、逻辑类型
注意:R 语言区分大小写,只有TRUE和FALSE,没有true,false ,True
三、文本类型
可以把它看作是java的string类型就是字符串,
四、对象类型
按对象类型来分是以下 6 种:
向量(vector) 可以理解为一维数组
用法: a = c("1",2,FALSE) 这个等式代表把向量赋值给a
注意事项:貌似如果向量里面的类型不一致会自动转 chr>num>logi
特别是 FALSE在转为chr的时候成为字符串"FALSE",在转为num的时候成为0

> a = c("1",2,FALSE) //[1] "1" "2" "FALSE"
> b = c(1,2,TRUE) //[1] 1 2 1
> c = c(TRUE,FALSE) //[1] TRUE FALSE
> b2 = c(1,2)
> b3 = c(1,2,3)
> b4 = c(1,2,3,4)
> a + b //Error in a + b : 二进列运算符中有非数值参数 因为a里面元素不是num
> b + b3 //[1] 2 4 4 前面这个[1]暂时不管 后面的121 和123相同下标相加
> b2+ b3 //[1] 2 4 4 //Warning message:In b2 + b3 : 长的对象长度不是短的对象长度的整倍数其实是121+123
> b2+ b4 //[1] 2 4 4 6 //其实就是1212+1234
> d = c(a,b,c) //[1] "1" "2" "FALSE" "1" "2" "1" "TRUE" "FALSE"
> a =1 //注意此时a的值发生变化 但是d 没有!!
> d[1] //[1] "1" //注意!!下标从1开始不是0!!向量取值
> a = c(10, 20, 30, 40, 50)
> a[2]
[1] 20
> a[1:4] # 取出第 1 到 4 项,包含第 1 和第 4 项
[1] 10 20 30 40
> a[c(1, 3, 5)] # 取出第 1, 3, 5 项
[1] 10 30 50
> a[c(-1, -5)] # 去掉第 1 和第 5 项
[1] 20 30 40
>a[-1] #不要第一项 去除2345项向量支持标量计算:
> c(1.1, 1.2, 1.3) - 0.5 //这个意思是说向量中所有元素都-0.5
[1] 0.6 0.7 0.8
> a = c(1,2)
> a ^ 2 //这个意思是说对向量中所有元素都*2
[1] 1 4函数运算
> a = c(1, 3, 5, 2, 4, 6)
> sort(a) //对向量的元素排序
[1] 1 2 3 4 5 6
> rev(a) //对向量的元素进行反转
[1] 6 4 2 5 3 1
> order(a) //order() 函数返回的是一个向量排序之后的下标向量。
[1] 1 4 2 5 3 6
> a[order(a)] //这个等价于 sort(a)
[1] 1 2 3 4 5 6向量生成
> seq(1, 9, 2) //生成1-9的向量,步长是2
[1] 1 3 5 7 9
> seq(0, 1, length.out=3) //生成等差数列 最后一个代表生成几个元素包含start end
[1] 0.0 0.5 1.0
> seq(1,10,length.out = 10) //简单的来看就是 (end-start)/(out-2)=步长 -2是因为包含头尾两个
[1] 1 2 3 4 5 6 7 8 9 10
> seq(1,10,length.out = 5)
[1] 1.00 3.25 5.50 7.75 10.00
> seq(1,10,length.out = 1)
[1] 1
> rep(0, 5) //rep 是 repeat(重复)的意思,可以用于产生重复出现的数字序列
[1] 0 0 0 0 0向量统计
| sum | 求和 |
| mean | 求平均值 |
| var | 方差 |
| sd | 标准差 |
| min | 最小值 |
| max | 最大值 |
| range | 取值范围(二维向量,最大值和最小值) |
> a=seq(1,10,1)
> sum(a) //总和
[1] 55
> mean(a) //平均值
[1] 5.5
> var(a) //方差
[1] 9.166667
> sd(a)
[1] 3.02765 //标准差
> min(a)
[1] 1
> max(a)
[1] 10
> range(a) //最小和最大值
[1] 1 10方差公式是一个数学公式,是数学统计学中的重要公式,应用于生活中各种事情,方差越小,代表这组数据越稳定,方差越大,代表这组数据越不稳定
标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同
看样子方差和标准差应该差不多,那么为什么要又标准差呢?由于方差是数据的平方,与检测值本身相差太大,人们难以直观的衡量,所以常用方差开根号换算回来这就是我们要说的标准差。
向量中常会用到 NA 和 NULL ,这里介绍一下这两个词语与区别:
- NA 代表的是"缺失",NULL 代表的是"不存在"。
- NA 缺失就想占位符,代表这里没有一个值,但位置存在。
- NULL 代表的就是数据不存在。
> length(c(NA, NA, NULL))
[1] 2
> c(NA, NA, NULL, NA)
[1] NA NA NA逻辑型
逻辑向量主要用于向量的逻辑运算,例如:
> c(1, 2, 3) > 2
[1] FALSE FALSE TRUE个人测试,感觉R语言对类型好像不太敏感会自动转化 chr类型"1"会自动转化为num的1 还有FALSE->0
> d=c("1","2")
> d>1
[1] FALSE TRUE
> c=c(FALSE,TRUE)
> c
[1] FALSE TRUE
> c<1
[1] TRUE FALSEwhich 函数是十分常见的逻辑型向量处理函数,可以用于筛选我们需要的数据的下标:
> a = c(1, 2, 3)
> b = a > 2
> print(b)
[1] FALSE FALSE TRUE
> which(b)
[1] 3
> which.max(a) //查看哪个下标是最大值,记住下标从1开始
[1] 3例如我们需要从一个线性表中筛选大于等于 60 且小于 70 的数据:
> vector = c(10, 40, 78, 64, 53, 62, 69, 70)
> vector
[1] 10 40 78 64 53 62 69 70
> which(vector>60 & vector<70) //which获取>60 <70的坐标
[1] 4 6 7
> vector[which(vector>60 & vector<70)]
[1] 64 62 69逻辑函数还有all 和any等
> all(c(TRUE, TRUE, TRUE))
[1] TRUE
> all(c(TRUE, TRUE, FALSE))
[1] FALSE
> any(c(TRUE, FALSE, FALSE))
[1] TRUE
> any(c(FALSE, FALSE, FALSE))
[1] FALSEall() 用于检查逻辑向量是否全部为 TRUE,any() 用于检查逻辑向量是否含有 TRUE。
———————————————————————————————————————————————————————————————————————————————————————————
字符串
字符串数据类型本身并不复杂,这里注重介绍字符串的操作函数:
> toupper("Runoob") # 转换为大写
[1] "RUNOOB"
> tolower("Runoob") # 转换为小写
[1] "runoob"
> nchar("中文", type="bytes") # 统计字节长度
[1] 4
> nchar("中文", type="char") # 总计字符数量
[1] 2
> substr("123456789", 1, 5) # 截取字符串,从 1 到 5
[1] "12345"
> substring("1234567890", 5) # 截取字符串,从 5 到结束
[1] "567890"
> as.numeric("12") # 将字符串转换为数字
[1] 12
> as.character(12.34) # 将数字转换为字符串
[1] "12.34"
> strsplit("2019;10;1", ";") # 分隔符拆分字符串
[[1]]
[1] "2019" "10" "1"
> gsub("/", "-", "2019/10/1") # 替换字符串
[1] "2019-10-1"R 支持 perl 语言格式的正则表达式: 详情https://www.runoob.com/perl/perl-regular-expressions.html 没学过perl。。。暂时不研究
> gsub("[[:alpha:]]+", "$", "Two words") //
[1] "$ $"———————————————————————————————————————————————————————————————————————————————————————————
矩阵 https://www.runoob.com/r/r-matrix.html
R 语言为线性代数的研究提供了矩阵类型,这种数据结构很类似于其它语言中的二维数组,但 R 提供了语言级的矩阵运算支持。
矩阵里的元素可以是数字、符号或数学式。首先看看矩阵的生成:
一个 M x N 的矩阵是一个由 M(row) 行 和 N 列(column)元素排列成的矩形阵列。
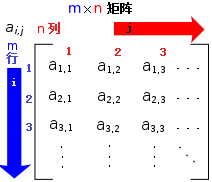
R 语言的矩阵可以使用 matrix() 函数来创建,语法格式如下:
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,dimnames = NULL)参数说明:
-
data 向量,矩阵的数据 备注:教程上说明了向量,那么应该只能是向量
-
nrow 行数
-
ncol 列数
-
byrow 逻辑值,为 FALSE 按列排列,为 TRUE 按行排列。 个人觉得一般是按行摆,结果不是!!!默认FALSE 大写!!
-
dimname 设置行和列的名称
创建矩阵
> vector=c(1:6)
> vector
[1] 1 2 3 4 5 6
> matrix(vector, 2, 3)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> matrix(vector, 2, 3,FALSE) //和FALSE一样 默认按列排的
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> matrix(vector, 2, 3,TRUE)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
> matrix(vector, nrow = 2, ncol = 3,TRUE,list(list("row1","row2"), list("col1","col2","col3"))) //知道好row和行命名
col1 col2 col3
row1 1 2 3
row2 4 5 6
//备注如果学过scala 可以知道如果制定了参数名 nrow = 2 这种 参数的位置是可以互换的
//可以只指定行数或者列数,会自动计算行列。。。转置矩阵
R 语言矩阵提供了 t() 函数,可以实现矩阵的行列互换。
例如有个 m 行 n 列的矩阵,使用 t() 函数就能转换为 n 行 m 列的矩阵。
> ma1=matrix(vector, nrow = 2, ncol = 3,TRUE,list(list("row1","row2"), list("col1","col2","col3")))
> ma1
col1 col2 col3
row1 1 2 3
row2 4 5 6
> t(ma1)
row1 row2
col1 1 4
col2 2 5
col3 3 6访问矩阵元素
先问下还记得如何访问向量元素吗? vector=seq(1:10) vector[1] vector[1:10] 取1-10个元素 vector[-2] 所有元素就不要第二个元素
如果想获取矩阵元素,可以通过使用元素的列索引和行索引,类似坐标形式。
# 定义行和列的名称
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# 创建矩阵
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)
> P
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14
# 获取第一行第三列的元素
print(P[1,3])
# 获取第四行第二列的元素
print(P[4,2])
# 获取第二行
print(P[2,])
# 获取第三列
print(P[,3])
#根据列名和行名获取数据
> P["row1"]
[1] NA
> P["row1",]
col1 col2 col3
3 4 5
# 如果采用P[1] = 3 P[2]=6 应该是会默认为第n行第一个元素矩阵计算
大小相同(行数列数都相同)的矩阵之间可以相互加减,具体是对每个位置上的元素做加减法。矩阵的乘法则较为复杂。两个矩阵可以相乘,当且仅当第一个矩阵的列数等于第二个矩阵的行数。
矩阵加减和乘除
> ma1=matrix(c(7, 9, -1, 4, 2, 3), nrow = 2)
> ma1
[,1] [,2] [,3]
[1,] 7 -1 2
[2,] 9 4 3
> ma2=matrix2 <- matrix(c(6, 1, 0, 9, 3, 2), nrow = 2)
> ma2
[,1] [,2] [,3]
[1,] 6 0 3
[2,] 1 9 2
> ma1+ma2 //同坐标下数字相加
[,1] [,2] [,3]
[1,] 13 -1 5
[2,] 10 13 5
> ma1-ma2 //同坐标下数字相减
[,1] [,2] [,3]
[1,] 1 -1 -1
[2,] 8 -5 1
> ma1*ma2 //暂时无法理解 ma1 3列 ,ma2 2行不等!!!!!
[,1] [,2] [,3]
[1,] 42 0 6
[2,] 9 36 6
> ma1/ma2
[,1] [,2] [,3]
[1,] 1.166667 -Inf 0.6666667
[2,] 9.000000 0.4444444 1.5000000乘法单独说下第一个矩阵的列数等于第二个矩阵的行数 A有3列=B有3行

矩阵的四则运算与向量基本一致,既可以与标量做运算,也可以与同规模的矩阵做对应位置的运算。例如:

数组
数组其实和我们java的数组一样,存放同类型元素,可以有多维数组,但是一般也就三维。。
创建方式
> dim1 <- c('a1','a2')
> dim2 <- c('b1','b2','b3')
> dim3 <- c('c1','c2','c3','c4')
> array <- array(data = 1:24, dim = c(2,3,4),dimnames = list(dim1,dim2,dim3))dim1一维的名称 dim2 二维名称 dim3 三位的名称
array 函数 生产数组的函数
data 你这个数组的数据
dim 你要形成几维,同时你每一维维度大小
dimnames 每个维度名称
注意 a <- array(1:8,c(2,2,2),list(list("a1","a2"),list("b1","b2"),list("c1","c2"))) 这样也是可以的就是dimnames 可以是list(list(),list())
数据框
data <- data.frame()
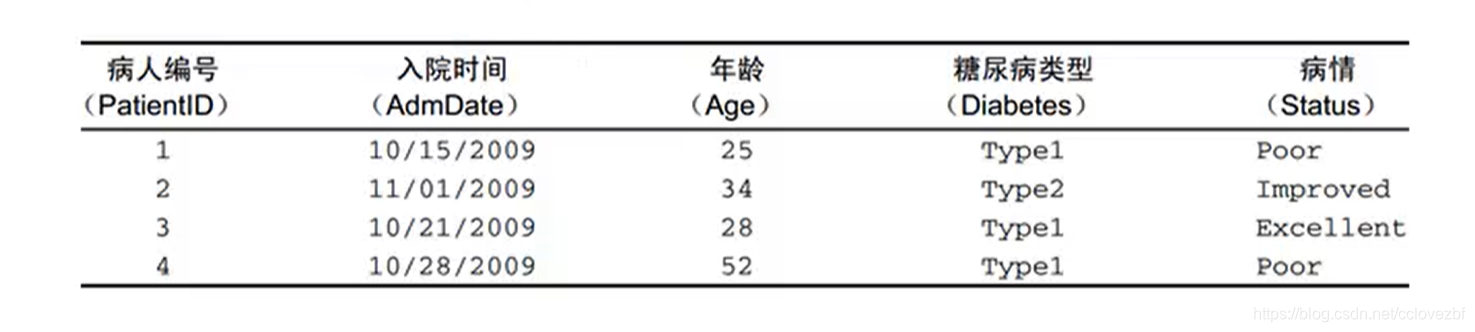
> patientId <- c(1:4)
> age <- c(25,34,28,52)
> diabetes <- c("Type1","Type2","Type3","Type2")
> status <- c("poor","Imporved","Excellent","poor")
> patientsData <- data.frame(patientId,age,diabetes,status)
> patientsData
patientId age diabetes status
1 1 25 Type1 poor
2 2 34 Type2 Imporved
3 3 28 Type3 Excellent
4 4 52 Type2 poor
> patientsData[1:2] //根据列的排列取第几列
patientId age
1 1 25
2 2 34
3 3 28
4 4 52
> patientsData[c("patientId","age")] //根据列名取数
patientId age
1 1 25
2 2 34
3 3 28
4 4 52
> patientsData$age //根据$符号取数据
[1] 25 34 28 52列表 list
> g <- "my first list"
> h <- c(1,2,3,4,5)
> j <- matrix(data = 1:10,nrow = 5,ncol = 2 ,byrow = TRUE)
> k <- c("one","two","three")
> l <- list(g,h,j,k)
访问列表
> l[1]
[[1]]
[1] "my first list" //这个取得是这个列表第一个的组成元素。是一个子列表
> l[[1]] //这个才是正宗的, 应该和上面的不一样。。。 这个取得是列表第一个的值
[1] "my first list"
> mode(l[1])
[1] "list"
> mode(l[[1]])
[1] "character"> stu <- list(stu.id=1234,stu.name="cc",stu.mark=c(99,88,77))
> stu
$stu.id
[1] 1234
$stu.name
[1] "cc"
$stu.mark
[1] 99 88 77
> names(stu) <- c("id","name","mark") //修改stu属性的名称
> stu
$id
[1] 1234
$name
[1] "cc"
$mark
[1] 99 88 77
> stu$gf <- "zbf" //增加stu的属性gf名字
> stu
$id
[1] 1234
$name
[1] "cc"
$mark
[1] 99 88 77
$gf
[1] "zbf"
> stu <- st[-4] //去掉gf属性。注意这里用的是[] 不是[[]]unlist 把所有元素转化为向量元素
> stu
$id
[1] 1234
$name
[1] "cc"
$mark
[1] 99 88 77
$gf
[1] "zbf"
> unlist(stu)
id name mark1 mark2 mark3 gf
"1234" "cc" "99" "88" "77" "zbf"


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









