




 本文详细介绍了CDP中Hive3的表类型,包括内部表、外部表和事务表的创建及配置。重点讨论了`hive.create.as.acid`、`hive.create.as.insert.only`和`hive.strict.managed.tables`等参数对表行为的影响,以及如何创建CRUD支持的事务表和INSERT-only事务表。同时提到了在Impala中查询Hive事务表时遇到的问题及解决策略。
本文详细介绍了CDP中Hive3的表类型,包括内部表、外部表和事务表的创建及配置。重点讨论了`hive.create.as.acid`、`hive.create.as.insert.only`和`hive.strict.managed.tables`等参数对表行为的影响,以及如何创建CRUD支持的事务表和INSERT-only事务表。同时提到了在Impala中查询Hive事务表时遇到的问题及解决策略。
参考文章
Apache Hive 3 tablesTable type definitions and a diagram of the relationship of table types to ACID properties clarifies Hive tables. The location of a table depends on the table type. You might choose a table type based on its supported storage format. https://docs.cloudera.com/cdp-private-cloud-base/latest/using-hiveql/topics/hive_hive_3_tables.htmlCDP中的Hive3系列之Hive3使用指南-阿里云开发者社区https://developer.aliyun.com/article/786518
https://docs.cloudera.com/cdp-private-cloud-base/latest/using-hiveql/topics/hive_hive_3_tables.htmlCDP中的Hive3系列之Hive3使用指南-阿里云开发者社区https://developer.aliyun.com/article/786518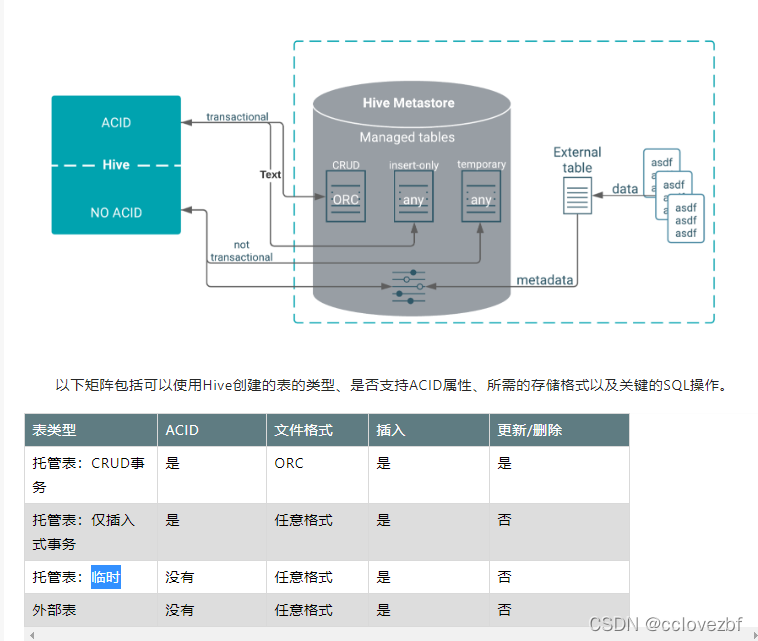
注意 我的cdp配置

这个外表路径我修改过 最初好像是/warehoue/tablespace/external/hive
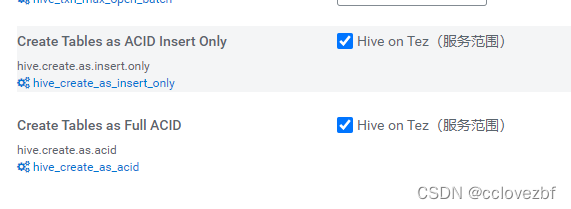
注意3.1的hive有如下默认参数
<property>
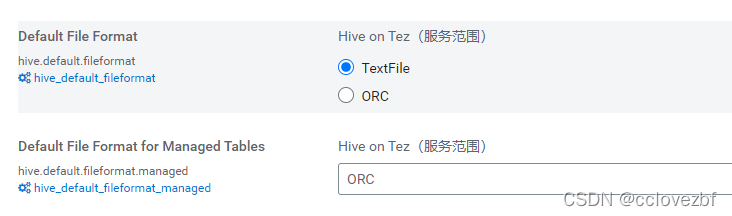
<name>hive.default.fileformat</name>
<value>TextFile</value>
<description>
Expects one of [textfile, sequencefile, rcfile, orc, parquet].
Default file format for CREATE TABLE statement. Users can explicitly override it by CREATE TABLE ... STORED AS [FORMAT]
</description>
</property>
<property>
<name>hive.default.fileformat.managed</name>
<value>none</value>
<description>
Expects one of [none, textfile, sequencefile, rcfile, orc, parquet].
Default file format for CREATE TABLE statement applied to managed tables only. External tables will be
created with format specified by hive.default.fileformat. Leaving this null will result in using hive.default.fileformat
for all tables.
</description>
</property>上面两个参数是外部表和内部表默认的存储格式。
<property>
<name>hive.create.as.external.legacy</name>
<value>false</value>
<description>When this flag set to true. it will ignore hive.create.as.acid and hive.create.as.insert.only,create external purge table by default.</description>
</property>
<property>
<name>hive.create.as.acid</name>
<value>false</value>
<description>
Whether the eligible tables should be created as full ACID by default. Does
not apply to external tables, the ones using storage handlers, etc.
</description>
</property>
<property>
<name>hive.create.as.insert.only</name>
<value>false</value>
<description>
Whether the eligible tables should be created as ACID insert-only by default. Does
not apply to external tables, the ones using storage handlers, etc.
</description>
</property>
<property>
<name>hive.strict.managed.tables</name>
<value>false</value>
<description>Whether strict managed tables mode is enabled. With this mode enabled, only transactional tables (both full and insert-only) are allowed to be created as managed tables</description>注意如图 上述参数
set hive.create.as.insert.only; --事务表只支持插入
set hive.create.as.acid; --事务表支持crud 支持delete update 默认true
-- 该参数为false 那么默认你创建的表是只支持insert。(即使存储格式为orc)
--该参数为true,默认创建的事务表为支持curd,如果指定格式非orc则只支持insert
set hive.strict.managed.tables; --是否为严格内部表模式 --默认false
-- 这个参数是真的难搞。原文翻译也不难,说的是
-- 该参数=true 只有事务表会变成内部表。
--该参数=false??解释又不说了。所有表都可以是内部表?
set hive.create.as.external.legacy;--是否采用建表默认为外表方式 默认false。
--这个参数=true 就等于set hive.create.as.acid=false + set hive.create.as.insert.only=false
1.创建crud的事务表
create table cc1(id int );
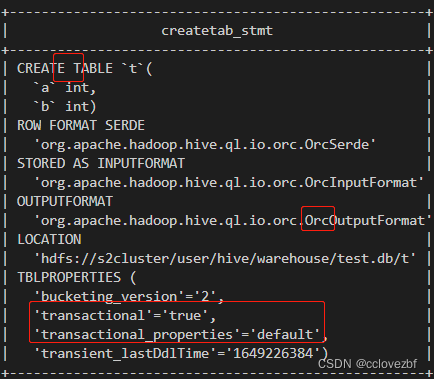
内部表+事务表crud+存储格式orc
2.创建insert-only的事务表
几种办法
1.CREATE TABLE T2(a int, b int) STORED AS ORC TBLPROPERTIES ('transactional'='true',
'transactional_properties'='insert_only');--建表的时候指定事务属性
2.CREATE TABLE T2(a int, b int) stored as textfile; --指定存储格式为非orc
3.set hive.create.as.acid=false; CREATE TABLE T2(a int, b int); --指定默认事务表为insert-only
3.创建一个外表。
两种办法
1.create external table cc(a int ,b int )
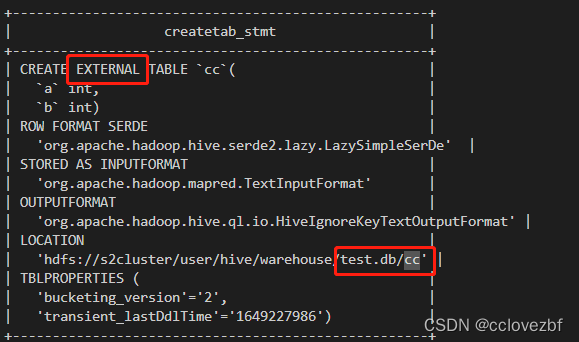
这个外部表和hive1 hive2 的外部表基本一样
2.
set hive.create.as.insert.only=false;
set hive.create.as.acid=false;
create table cc_1(a int ,b int );
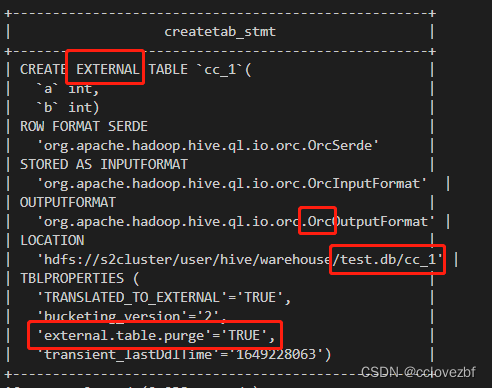
注意这里 创建的是外部表 存储格式为orc(这里我也没想明白。。按道理应该是text的)
注意这个参数external.table.purge='TRUE'这个的意思是drop external table的时候 也会删除外部表指向的数据。
看到这里大家可能有点懵了。
1.我就想创建一个非事务内部表可以吗?
不可以直接创建。 但是你可以create external table cc(a int ,b int );
alter table cc set TBLPROPERTIES ('EXTERNAL'='FALSE');
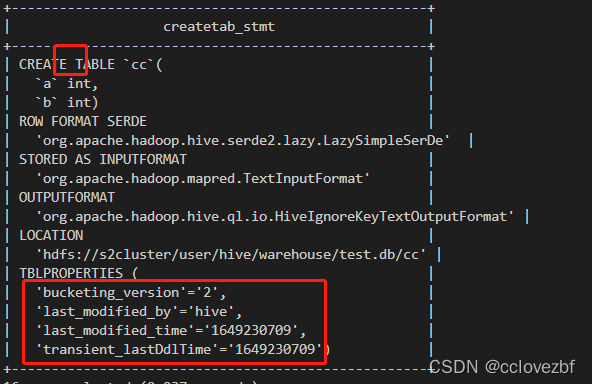
无external 也无 transcational。
上面这种方式很麻烦。那么
set hive.create.as.insert.only=false;
set hive.create.as.acid=false;
然后create table cc(a int ,b int ); 这样除了他是个外部表,但是实际和我们hive2.x建的内部表功能也一样。同时这个表也能被spark访问。。
--------------------------说个在cdp 中impala查询hive表的错误---------------------------------
select * from hive_table_on_impala
SQL 错误 [500051] [HY000]: [Cloudera][ImpalaJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: TStatus(statusCode:ERROR_STATUS, sqlState:HY000, errorMessage:AnalysisException: Table dwiadata.ia_fdw_b_profile_important_related_person_it not supported. Transactional (ACID) tables are only supported when they are configured as insert_only.
报错很明显 和事务表有关 又说了只支持当配置为insert_only的时候
查看原表 'transactional'='true',
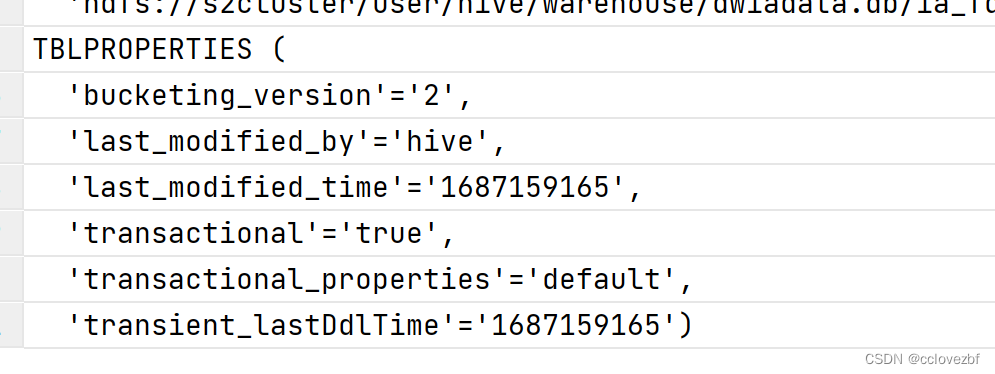
尝试将事务表改为普通表
alter table dwiadata.ia_fdw_b_profile_important_related_person_it set tblproperties ('transactional_properties'='insert_only');
报错
[08S01][40013] Error while compiling statement: FAILED: Execution Error, return code 40013 from org.apache.hadoop.hive.ql.ddl.DDLTask. Unable to alter table. TBLPROPERTIES with 'transactional_properties' cannot be altered after the table is created
只能重建表了。
set hive.create.as.acid=false;
create table xxx

















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









