







CommonRdbmsWriter 类里
fillPreparedStatementColumnType方法里
String str = column.asString();
if (DataBaseType.PostgreSQL.compareTo(dataBaseType)==0&&StringUtils.isNotEmpty(str)&&str.indexOf('\u0000')>-1){
//如果writer是postgresql 并且字段类型是text vachar 然后值value!=null 同时含有这个特殊字符
str = str.replace('\u0000',' ').replace(" ","");
}
if (DataBaseType.Oracle.compareTo(dataBaseType)==0){
if (columnSqltype==Types.VARCHAR&&str!=null&&str.getBytes(StandardCharsets.UTF_8).length>=4000){
//全中文3000字 9000 字节 -> 1333字符 4000字节
//全英文5000字 5000字节 -> 4000字符 4000字节
//中文1500 英文1000 字节5500 -> 2000(中1500英500) 5000字符 -> 1333字符
str = str.substring(0, Math.min(str.length(), 4000));
if (str.getBytes(StandardCharsets.UTF_8).length>=4000){
str = str.substring(0, 1333); //直接认为全是中文
}
}
if (columnSqltype==Types.NVARCHAR&&str!=null&&str.length()>=2000){
//2000中文 2000英文
if (str.getBytes(StandardCharsets.UTF_8).length>2000){
//有中文
str = str.substring(0, 1333);
}else { //有中英文
str= str.substring(0, 1500 );
}
}
}
preparedStatement.setString(columnIndex + 1, str);
break;说下优化点
1.优化输出到postgresql里时候 有个特殊字符\u0000 在插入的时候会报错直接替换为无了。这个不会影响结果,因为这个字符本身大多时候就没有意义
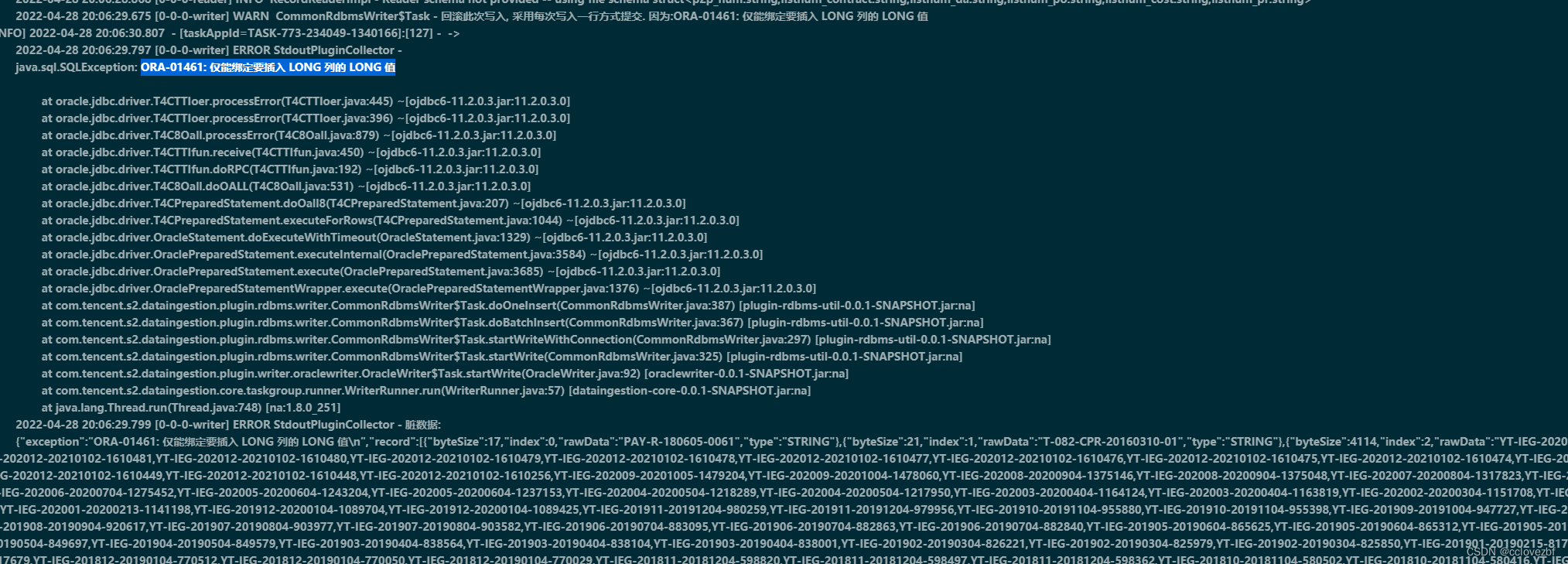
2.优化oraclewriter时,由于hive的string是不限长度的,但是oracle的varhcar2最长是4000字节,1333汉字,nvarchar2000是2000字符。
但是在insert into oracle_table values ("2000个汉字的时候") 会报一个下面的错 【仅能绑定要插入的LONG列的LONG值的错】
在insert into oracle_table values ("1500个汉字的时候") 不会报错....
但是在直接向表里粘贴2000汉字时候,不会报错
有熟悉这块的可以自行更改。。这个改动的目的是保证所有数据都插入到oracle即使部分数据残缺。

DfsUtils类。如果你们新增了decimal字段类型。
注意该字段bug极多...
在读取parquet文件的时候
private void transportParquetRecord(Group group, List<String> columnName,
List<String> columnType,
List<String> columnValue,
List<Integer> columnIndex,
RecordSender recordSender, TaskPluginCollector taskPluginCollector){
Record record = recordSender.createRecord();
Column columnGenerated = null;
try {
//type不能为空
for (int i = 0; i < columnType.size(); i++){
String type = columnType.get(i);
if (columnValue.get(i)!=null){ //针对分区表 的分区字段 因为我这个自带有value 那么说明是自己定义的字段
columnGenerated=new StringColumn(columnValue.get(i));
}else {
if (0 != group.getFieldRepetitionCount(i)){//数据不为空
if (type.equalsIgnoreCase("INT")){
// LOG.info(String.format("Read parquetfile group value : [%s].", group.getInteger(columnName.get(i),0)));
if (columnName.get(i)!=null){// 写的是{"name":xx,"type:"xx"}
columnGenerated = new StringColumn(String.valueOf(group.getInteger(columnName.get(i),0))) ;
}else {
columnGenerated = new StringColumn(group.getValueToString(columnIndex.get(i),0)) ;
}
}else if(type.equalsIgnoreCase("STRING")){
// LOG.info(String.format("Read parquetfile group value : [%s].", group.getString(columnName.get(i),0)));
if (columnName.get(i)!=null){
columnGenerated = new StringColumn(String.valueOf(group.getString(columnName.get(i),0))) ;
}else {
columnGenerated = new StringColumn(group.getValueToString(columnIndex.get(i),0)) ;
}
}else if(type.equalsIgnoreCase("DOUBLE")){
// LOG.info(String.format("Read parquetfile group value : [%s].", group.getDouble(columnName.get(i),0)));
if (columnName.get(i)!=null){
columnGenerated = new StringColumn(String.valueOf(group.getDouble(columnName.get(i),0))) ;
}else {
columnGenerated = new StringColumn(group.getValueToString(columnIndex.get(i),0)) ;
}
}else if(type.equalsIgnoreCase("BIGINT")){
// LOG.info(String.format("Read parquetfile group value : [%s].", group.getInt96(columnName.get(i),0)));
if (columnName.get(i)!=null){
columnGenerated = new StringColumn(String.valueOf(group.getInt96(columnName.get(i),0))) ;
}else {
columnGenerated = new StringColumn(group.getValueToString(columnIndex.get(i),0)) ;
}
}else if (type.equalsIgnoreCase("DECIMAL")){
//https://www.shuzhiduo.com/A/rV57W2yE5P/
byte[] bytes;
if(columnName.get(i)!=null){
bytes= group.getBinary(columnName.get(i), 0).getBytes();
}else {
bytes=group.getBinary(columnIndex.get(i), 0).getBytes();
}
java.math.BigDecimal result = new BigDecimal(new BigInteger(bytes), 18);
columnGenerated = new StringColumn(result.toPlainString());
}
}else { //数据为空的情况
// LOG.info(String.format("Read parquetfile group null : [%s].", group.getString(columnName.get(i),0))); if (printFlag==0&&i==(columnType.size()-1))
columnGenerated =new StringColumn(null);
}
}
record.addColumn(columnGenerated);
}
// if (printFlag==0){
// LOG.info("record={}",record);
// }
recordSender.sendToWriter(record);
} catch (Exception e) {
taskPluginCollector
.collectDirtyRecord(record, e.getMessage());
}
}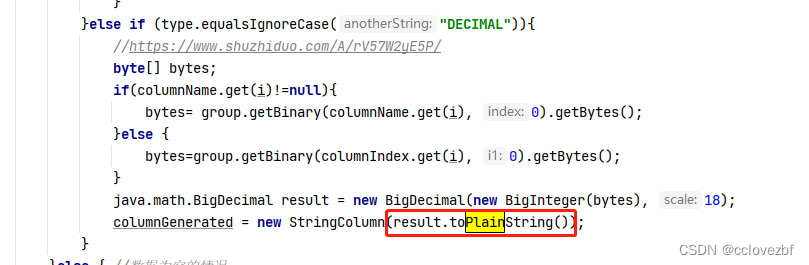
decimla 不能直接转string 否则decimal 0.000000000的时候会直接变为 0E-18
新增的kudu11writer。写的很垃圾 让我怀疑ali的水平了。
Kudu11xHelper.java

前脚刚设置为long 后脚就强转为int ,666
不支持decimal。 kudu更类似与rdbm关系型数据库,又不像hive那样存储格式很麻烦。。不知道为啥不加上
ColumnType.java
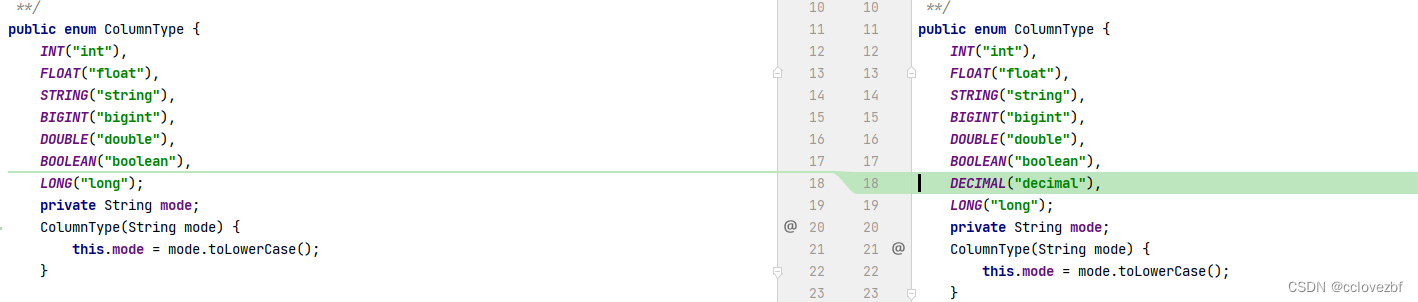
KuduWriterTask.java

此处第一新增了支持decimal
第二 对于时间格式的处理。
例如oracle date类型2022-05-20 存到kudu的string 。他不会存2022-05-20,它会存个时间戳。
上面的是最开始报错。下面的是我解决后的

这里分析下原因。 我们从oracle读的时候会获取到date 2022-05-20,然后存到dateColumn里。

原文是 column.getRawData().toString。

可以看到dateColumn实际存的是date.getTime 所以变成了时间戳。
我们至于要 column.asString就行














 2470
2470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









