







有人说count() 我难道不会?不就是计数么? sql的入门语法呀。
可是要知道不同的数据库或者查询引擎有着不同的优化或者计算方式。所以都要学习。
照例官网地址
COUNT Function
An aggregate function that returns the number of rows, or the number of non-NULL rows.
注意这里说了是计算所有行,或者非空行!!说明这里有两种计数!!
Syntax:
COUNT([DISTINCT | ALL] expression) [OVER (analytic_clause)]count(distinct col) count(*) , 也可以配合开窗函数使用
Depending on the argument, COUNT() considers rows that meet certain conditions:
- The notation
COUNT(*)includesNULLvalues in the total. - The notation
COUNT(column_name)only considers rows where the column contains a non-NULLvalue. - You can also combine
COUNTwith theDISTINCToperator to eliminate duplicates before counting, and to count the combinations of values across multiple columns.
根据count()括号里的表达式不同计算的东西也不同
count(*) 代表所有行包括null
count(col)代表该col非空的行
count(distinct col) 代表对非空行进行过滤
When the query contains a GROUP BY clause, returns one value for each combination of grouping values.
测试
select count(1) from ia_fdw_b_profile_product_info --162403159
select count(*) from ia_fdw_b_profile_product_info --162403159 第一列不为空 count(1)和count(*)效果一样
select count(company_id) from ia_fdw_b_profile_product_info --158435163 --company_id该列有null
select count(*) from ia_fdw_b_profile_product_info where company_id is null -- 3967996
select count(distinct company_id )from ia_fdw_b_profile_product_info --27664540
select count(1) from (select company_id from ia_fdw_b_profile_product_info group by company_id)t --27664541 group by会比 count(distinct )多个null!!!Return type: BIGINT
返回值是bigint 不是int 注意了因为impala对类型要求严格
Usage notes:
If you frequently run aggregate functions such as MIN(), MAX(), and COUNT(DISTINCT) on partition key columns, consider enabling the OPTIMIZE_PARTITION_KEY_SCANS query option, which optimizes such queries. This feature is available in Impala 2.5 and higher. See OPTIMIZE_PARTITION_KEY_SCANS Query Option (Impala 2.5 or higher only) for the kinds of queries that this option applies to, and slight differences in how partitions are evaluated when this query option is enabled.
使用事项。你过你经常要根据分区字段做聚合运算max min count(),考虑OPTIMIZE_PARTITION_KEY_SCANS 查询,这个的计算方式和普通的不一样。
此时我们先学习下count()在开窗函数的使用
create table test.int_t (x int ,property string ) stored as PARQUET
insert into test.int_t values
(1,"odd"),
(3,"odd"),
(5,"odd"),
(7,"odd"),
(9,"odd"),
(2,"even"),
(4,"even"),
(6,"even"),
(8,"even"),
(10,"even")
测试一
select x, property, count(x) over (partition by property) as count from int_t where property in ('odd','even');
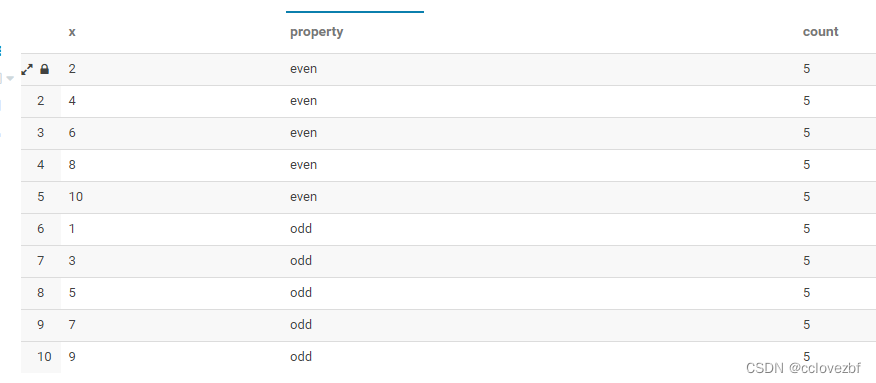
结果分析:无话可说,对property字段进行开窗,计算每个列别(even,odd)的count()数
测试二
select x, property, count(x) over (partition by property order by x ) as count from int_t where property in ('odd','even');
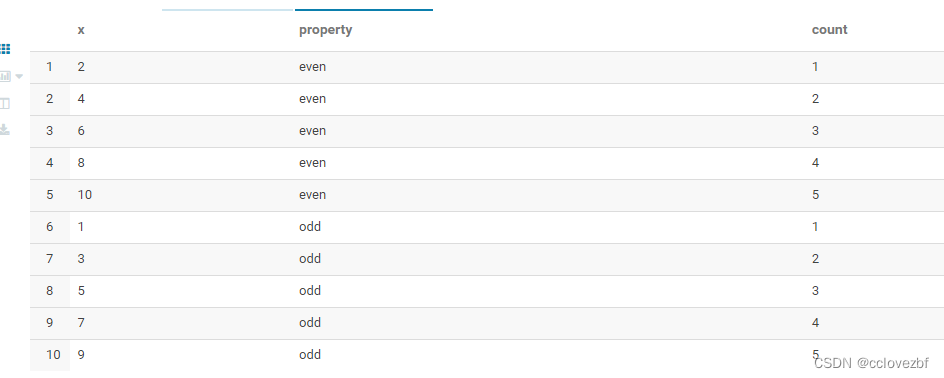
结果分析:这里惊到我了。没想到是123456.加了一个order by 对count()的结果值发生了改变,这里我感觉和row_number()有什么区别呢? 有丢丢的不理解。。
官方解释
Adding an
ORDER BYclause lets you experiment with results that are cumulative or apply to a moving set of rows (the "window"). The following examples useCOUNT()in an analytic context (that is, with anOVER()clause) to produce a running count of all the even values, then a running count of all the odd values. The basicORDER BY xclause implicitly activates a window clause ofRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, which is effectively the same asROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, therefore all of these examples produce the same results:
简单来说,加了order by 后隐式激活了一个范围在无界前行和当前行之间的窗口子句(也就是下面的那个例子!!!)
测试三
select x, property,
count(x) over
(
partition by property
order by x
range between unbounded preceding and current row
) as 'cumulative total'
from int_t where property in ('odd','even');
结果分析,结果还是和上面的一样,但是这个好理解。 range between unbounded preceding and current row ,代表的是窗口内的 unbounded preceding起始行->current row 当前行的总数。
注意这里也可以写为
rows between unbounded preceding and current row测试四
select x, property,
count(x) over
(
partition by property
order by x
rows between 1 preceding and 1 following
) as 'moving total'
from int_t where property in ('odd','even'); 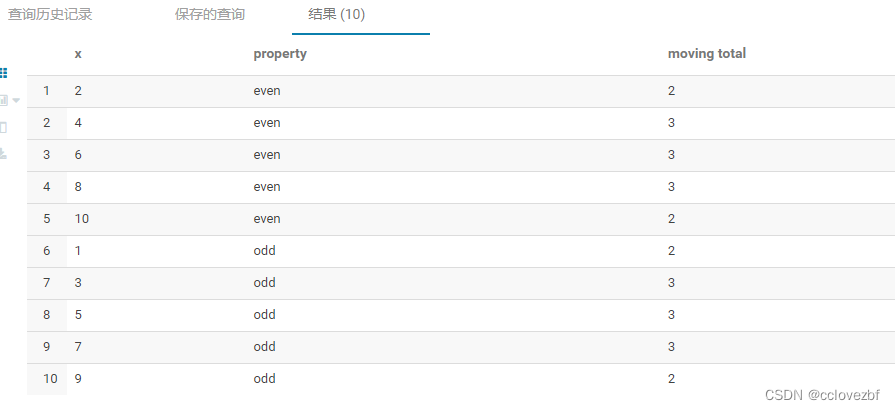
结果分析:这个也好理解,rows between 1 preceding and 1 following就是当前行的前一行到后一行数据的总量,因为第一行和最后一行的特殊性所以=2,其余的都=3
测试五
select x, property,
count(x) over
(
partition by property
order by x
range between 1 preceding and 1 following
) as 'moving total'
from int_t where property in ('odd','even');ERROR: AnalysisException: RANGE is only supported with both the lower and upper bounds UNBOUNDED or one UNBOUNDED and the other CURRENT ROW.
报错了,原因在impala语法中 range between 比row between 垃圾。。。。
开始讲优化了。。我也是在慢慢学习
OPTIMIZE_PARTITION_KEY_SCANS
Enables a fast code path for queries that apply simple aggregate functions to partition key columns: MIN(key_column), MAX(key_column), or COUNT(DISTINCT key_column).
更快的聚合!!!!
Type: Boolean; recognized values are 1 and 0, or true and false; any other value interpreted as false
Default: false (shown as 0 in output of SET statement)
Note: In Impala 2.5.0, only the value 1 enables the option, and the value true is not recognized. This limitation is tracked by the issue IMPALA-3334, which shows the releases where the problem is fixed.
Added in: Impala 2.5.0
Usage notes:
This optimization speeds up common "introspection" operations over partition key columns, for example determining the distinct values of partition keys.
This optimization does not apply to SELECT statements that reference columns that are not partition keys. It also only applies when all the partition key columns in the SELECT statement are referenced in one of the following contexts:
-
Within a
MAX()orMAX()aggregate function or as the argument of any aggregate function with theDISTINCTkeyword applied. -
Within a
WHERE,GROUP BYorHAVINGclause.
简单来说就是只适合分区键。
This optimization is enabled by a query option because it skips some consistency checks and therefore can return slightly different partition values if partitions are in the process of being added, dropped, or loaded outside of Impala. Queries might exhibit different behavior depending on the setting of this option in the following cases:
-
If files are removed from a partition using HDFS or other non-Impala operations, there is a period until the next
REFRESHof the table where regular queries fail at run time because they detect the missing files. With this optimization enabled, queries that evaluate only the partition key column values (not the contents of the partition itself) succeed, and treat the partition as if it still exists. -
If a partition contains any data files, but the data files do not contain any rows, a regular query considers that the partition does not exist. With this optimization enabled, the partition is treated as if it exists.
If the partition includes no files at all, this optimization does not change the query behavior: the partition is considered to not exist whether or not this optimization is enabled.
这里主要是说明一个一致性检查,比如我们经常在hive里对一个表数据进行删除新增,impala没有及时刷新元数据,会导致不能识别hive的最新数据或者说hdfs的最新文件。
话不多说
官网实战
-- Make a partitioned table with 3 partitions.
create table t1 (s string) partitioned by (year int);
insert into t1 partition (year=2015) values ('last year');
insert into t1 partition (year=2016) values ('this year');
insert into t1 partition (year=2017) values ('next year');
-- Regardless of the option setting, this query must read the
-- data files to know how many rows to return for each year value.
-- 这里是说 没有设置参数之前,你要查询表数据必须经过全表扫描,这个很正常。
explain select year from t1;
+-----------------------------------------------------+
| Explain String |
+-----------------------------------------------------+
| Estimated Per-Host Requirements: Memory=0B VCores=0 |
| |
| F00:PLAN FRAGMENT [UNPARTITIONED] |
| 00:SCAN HDFS [key_cols.t1] |
| partitions=3/3 files=4 size=40B |
| table stats: 3 rows total |
| column stats: all |
| hosts=3 per-host-mem=unavailable |
| tuple-ids=0 row-size=4B cardinality=3 |
+-----------------------------------------------------+
-- The aggregation operation means the query does not need to read
-- the data within each partition: the result set contains exactly 1 row
-- per partition, derived from the partition key column value.
-- By default, Impala still includes a 'scan' operation in the query.
-- 这里有意思了。我之前认为这里根本就不需要读文件数据,因为分区是以目录形式存在的
explain select distinct year from t1;
+------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------+
| Estimated Per-Host Requirements: Memory=0B VCores=0 |
| |
| 01:AGGREGATE [FINALIZE] |
| | group by: year |
| | |
| 00:SCAN HDFS [key_cols.t1] |
| partitions=0/0 files=0 size=0B |
+------------------------------------------------------------------------------------+
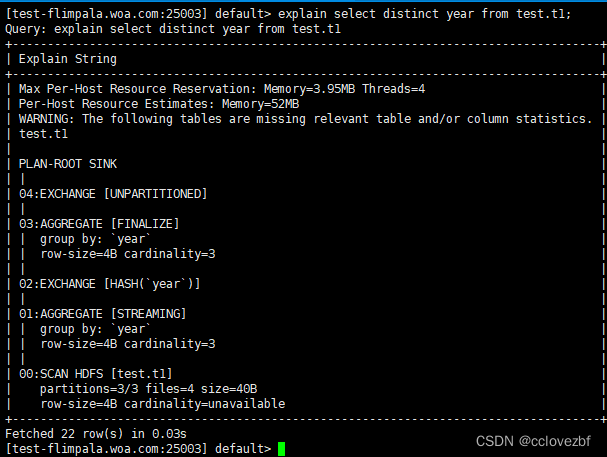
注意啊 ,官网说不用走,但是我这里还是走了。各位自己测试下!!!!!!!
The following examples show how the plan is made more efficient when the OPTIMIZE_PARTITION_KEY_SCANS option is enabled:
set optimize_partition_key_scans=1;
OPTIMIZE_PARTITION_KEY_SCANS set to 1
-- The aggregation operation is turned into a UNION internally,
-- with constant values known in advance based on the metadata
-- for the partitioned table.
explain select distinct year from t1;
+-----------------------------------------------------+
| Explain String |
+-----------------------------------------------------+
| Estimated Per-Host Requirements: Memory=0B VCores=0 |
| |
| F00:PLAN FRAGMENT [UNPARTITIONED] |
| 01:AGGREGATE [FINALIZE] |
| | group by: year |
| | hosts=1 per-host-mem=unavailable |
| | tuple-ids=1 row-size=4B cardinality=3 |
| | |
| 00:UNION |
| constant-operands=3 |
| hosts=1 per-host-mem=unavailable |
| tuple-ids=0 row-size=4B cardinality=3 |
+-----------------------------------------------------+
-- The same optimization applies to other aggregation queries
-- that only return values based on partition key columns:
-- MIN, MAX, COUNT(DISTINCT), and so on.
explain select min(year) from t1;
+-----------------------------------------------------+
| Explain String |
+-----------------------------------------------------+
| Estimated Per-Host Requirements: Memory=0B VCores=0 |
| |
| F00:PLAN FRAGMENT [UNPARTITIONED] |
| 01:AGGREGATE [FINALIZE] |
| | output: min(year) |
| | hosts=1 per-host-mem=unavailable |
| | tuple-ids=1 row-size=4B cardinality=1 |
| | |
| 00:UNION |
| constant-operands=3 |
| hosts=1 per-host-mem=unavailable |
| tuple-ids=0 row-size=4B cardinality=3 |
+-----------------------------------------------------+自己测试的。
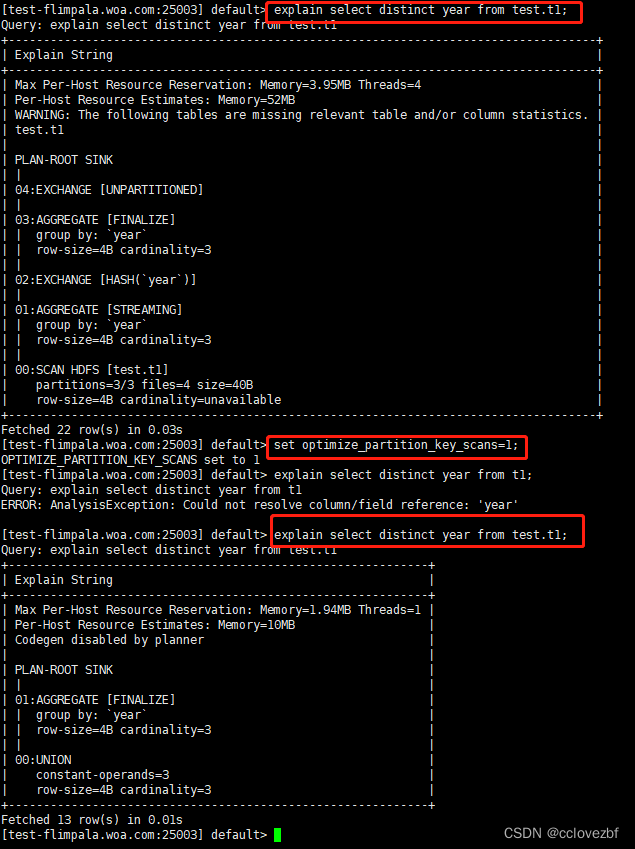
其实我觉得就是官网的搞错了。
注意是max min count(distinct) 有优化!!但是count()是没有优化的。















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









