







学习这个函数之前需要了解acc
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.Serializable;
/**
* @Author: cc
* @Date: 2022/4/28 16:21
*/
public class AccumulatorTest {
private static final Logger logger = LoggerFactory.getLogger(AccumulatorTest.class);
public static void main(String[] args) throws Exception {
//初始化flink的streaming环境
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
env.setParallelism(4);
DataStreamSource<Integer> source = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 0,1, 2, 3, 4, 5, 6, 7, 8, 9, 0);
source.addSink(new Sink1());
JobExecutionResult jobResult= env.execute("cas-job");
int nums = jobResult.getAccumulatorResult("elementCounter");
System.out.println("使用累加器统计的结果:"+nums);
env.execute();
}
static class Sink1 extends RichSinkFunction<Integer> {
private IntCounter elementCounter = new IntCounter();
Integer count = 0;
@Override
public void open(Configuration parameters) throws Exception {
//-2注册累加器
getRuntimeContext().addAccumulator("elementCounter", elementCounter);
super.open(parameters);
}
@Override
public void close() throws Exception {
super.close();
}
@Override
public void invoke(Integer value, Context context) throws Exception {
this.elementCounter.add(1);
count+=1;//非累加器
Serializable elementCounter = getRuntimeContext().getAccumulator("elementCounter").getLocalValue();
System.out.println("count="+count+",acc="+elementCounter.toString());
}
}
}
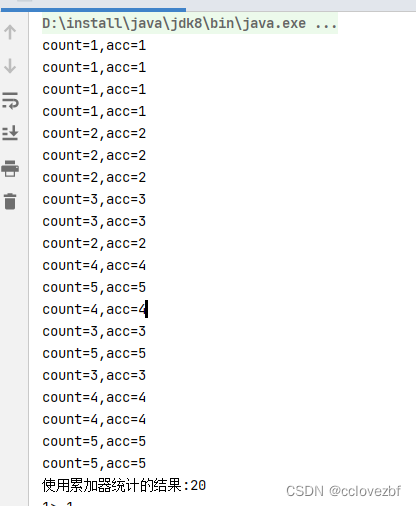
为什么要使用累加器,有时候我们想知道处理了多少数据量 比如 name=cc的数据量
为什么count++ 不行呢?因为是分布式计算,累加器在多台机器++,然后最后会聚合一次。或者我们需要的累加值,其实这里和spark的累加器好像是一个意思。
public interface Accumulator<V, R extends Serializable> extends Serializable, Cloneable {
/** @param value The value to add to the accumulator object */
void add(V value); //累加器调用add方法的处理逻辑
/** @return local The local value from the current UDF context */
R getLocalValue();// 获取值
/** Reset the local value. This only affects the current UDF context. */
void resetLocal();//重置本地初始值
/**
* Used by system internally to merge the collected parts of an accumulator at the end of the
* job.
*
* @param other Reference to accumulator to merge in.
*/
void merge(Accumulator<V, R> other); //分布在不同的累加器开始merge值
/**
* Duplicates the accumulator. All subclasses need to properly implement cloning and cannot
* throw a {@link java.lang.CloneNotSupportedException}
*
* @return The duplicated accumulator.
*/
Accumulator<V, R> clone(); //
}
累加器一般用在什么情况下呢? 聚合函数aggregateFunction里。那么agg又是什么样呢?
注意这个泛型。 IN代表入参,ACC代表累加器, OUT代表出参
@PublicEvolving
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
/**
* Creates a new accumulator, starting a new aggregate.
*
* <p>The new accumulator is typically meaningless unless a value is added via {@link
* #add(Object, Object)}.
*
* <p>The accumulator is the state of a running aggregation. When a program has multiple
* aggregates in progress (such as per key and window), the state (per key and window) is the
* size of the accumulator.
*
* @return A new accumulator, corresponding to an empty aggregate.
*/
ACC createAccumulator();
/**
* Adds the given input value to the given accumulator, returning the new accumulator value.
*
* <p>For efficiency, the input accumulator may be modified and returned.
*
* @param value The value to add
* @param accumulator The accumulator to add the value to
* @return The accumulator with the updated state
*/
ACC add(IN value, ACC accumulator);
/**
* Gets the result of the aggregation from the accumulator.
*
* @param accumulator The accumulator of the aggregation
* @return The final aggregation result.
*/
OUT getResult(ACC accumulator);
/**
* Merges two accumulators, returning an accumulator with the merged state.
*
* <p>This function may reuse any of the given accumulators as the target for the merge and
* return that. The assumption is that the given accumulators will not be used any more after
* having been passed to this function.
*
* @param a An accumulator to merge
* @param b Another accumulator to merge
* @return The accumulator with the merged state
*/
ACC merge(ACC a, ACC b);
}案例-同时计算uv 和pv为, uv是用户访问量,pv是页面点击量。
数据
user1 url1
user2 url2
user2 ur1
.......
我们先要清楚怎么算uv,很明显需要去重 所以我们需要一个hashset
怎么算pv?每来一条记录 数据+1 所以用个int和long就行。
再看看接口泛型
in就是数据类型 我们用个class代替叫做event(string user,string url)
out 用个tuple。返回tuple<int ,int>.of (uv,pv)
acc怎么表示呢?注意来一个event 就要累加一次,我们既要存uv的信息也要存pv的信息
所以还是用个tuple,上面也说了uv用set ,pv用int 所以 tuple<hashset,int>
所以开搞。
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.Calendar;
import java.util.HashSet;
import java.util.Random;
public class WindowAggregateTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 所有数据设置相同的key,发送到同一个分区统计PV和UV,再相除
stream.keyBy(data -> true) //如果你是想计算每天的每个窗口的uv pv 可以data->data.day
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2)))
.aggregate(new AvgPv())
.print("res");
env.execute();
}
public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Integer>, Tuple2<Integer,Integer>> {
@Override
public Tuple2<HashSet<String>, Integer> createAccumulator() {
// 创建累加器 初始化
// 最开始这个uv和pv的数值 一般默认是0。但是如果有的公司要作假可以加大。
return Tuple2.of(new HashSet<String>(), 0);
}
@Override
public Tuple2<HashSet<String>, Integer> add(Event value, Tuple2<HashSet<String>, Integer> accumulator) {
// 属于本窗口的数据来一条累加一次,并返回累加器
//f0计算 uv f1计算pv
accumulator.f0.add(value.user);
return Tuple2.of(accumulator.f0, accumulator.f1 + 1);
}
@Override
public Tuple2<Integer,Integer> getResult(Tuple2<HashSet<String>, Integer> accumulator) {
//每个窗口结束的时候执行一次
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return Tuple2.of(accumulator.f0.size(),accumulator.f1);
}
@Override
public Tuple2<HashSet<String>, Integer> merge(Tuple2<HashSet<String>, Integer> a, Tuple2<HashSet<String>, Integer> b) {
System.out.println("merge被执行了");
//如果是并行的多个结果会执行。
HashSet<String> uv1 = a.f0;
HashSet<String> uv2 = b.f0;
HashSet<String> uv = new HashSet<>();
for (String s : uv1) {
uv.add(s);
}
for (String s : uv2) {
uv.add(s);
}
Integer pv1 = a.f1;
Integer pv2 = b.f1;
return Tuple2.of(uv,pv1+pv2);
}
}
static class ClickSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
//这里也可以发送水位线
// ctx.collectWithTimestamp();
// ctx.emitWatermark(new Watermark(1));
// 隔1秒生成一个点击事件,方便观测
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}
}
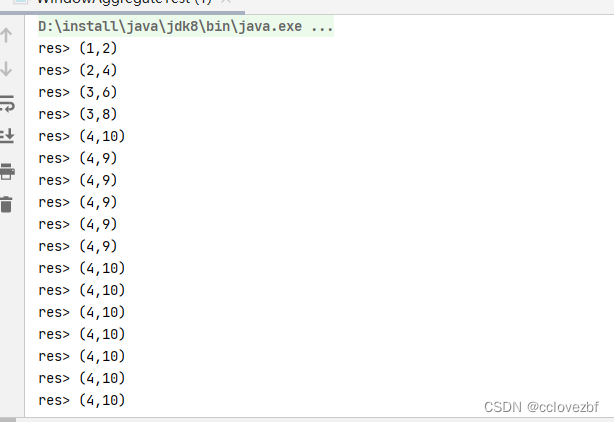
注意我在代码里打印了merge,但是这里为什么没有输出呢?
因为我设置的并行度为1?不对。。。
因为keyby data->true 就只会发送到一个分区,根本不需要merge
但是我后面测试了不管怎样。好像都没有打印merge....后面遇到了再更新
/** * Merges two accumulators, returning an accumulator with the merged state. * * <p>This function may reuse any of the given accumulators as the target for the merge and * return that. The assumption is that the given accumulators will not be used any more after * having been passed to this function. * * @param a An accumulator to merge * @param b Another accumulator to merge * @return The accumulator with the merged state */ ACC merge(ACC a, ACC b);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









