



这个是爬取免费的音乐,目前收费的我还不会,只有1min的试听
1.找到我们要爬取的歌曲
进入酷狗的官方网站,找一首你想爬取的歌曲进入到播放界面
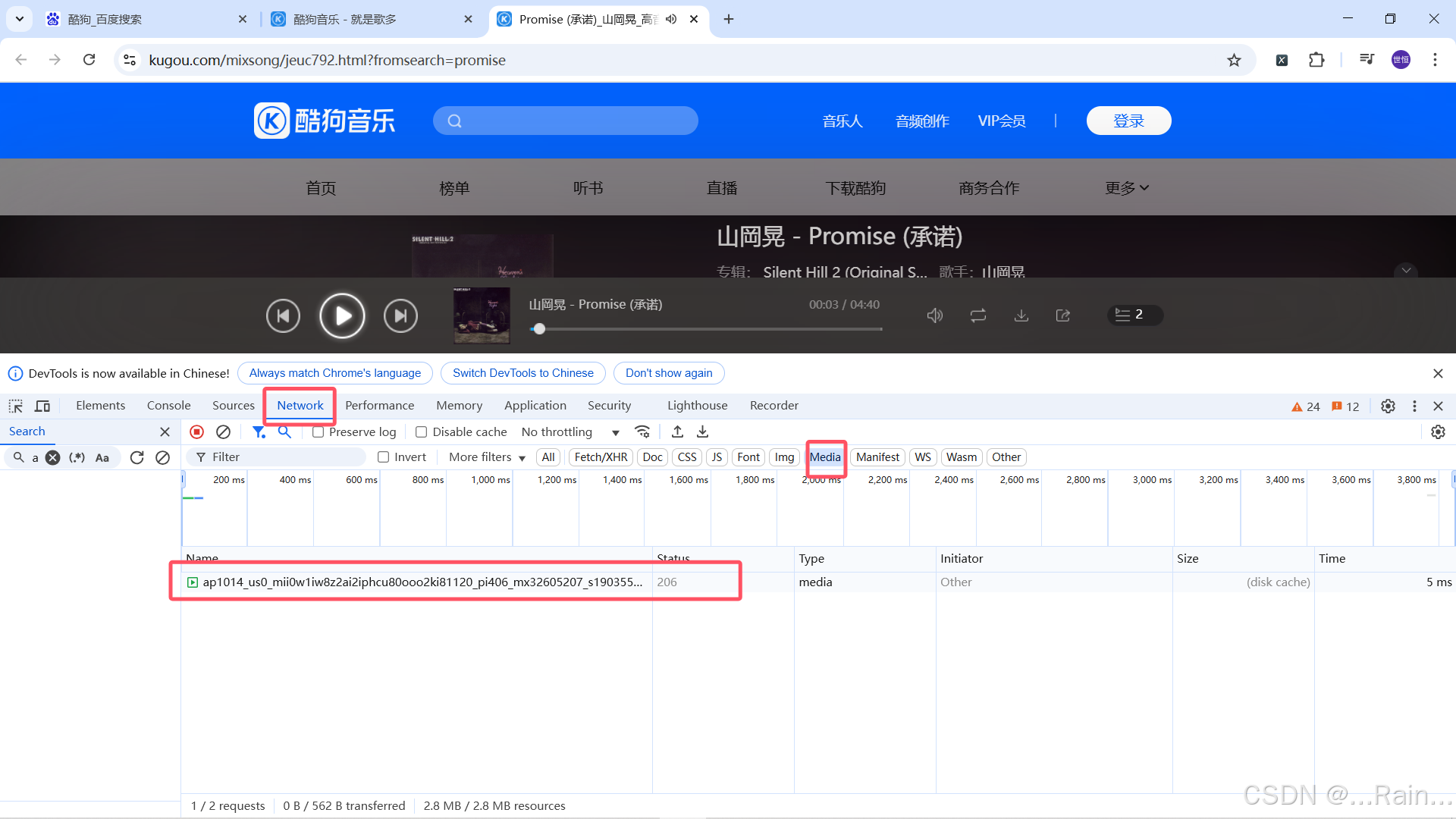
按f12打开开发者工具,在这个路径:Network→Media
下找到后缀为mp3的接口(没有这个的刷新网站,或者拖动进度条就会出现...........如果一直不出现可以直接按ctrl+f搜索mp3找到下面图片中箭头指向的接口)。
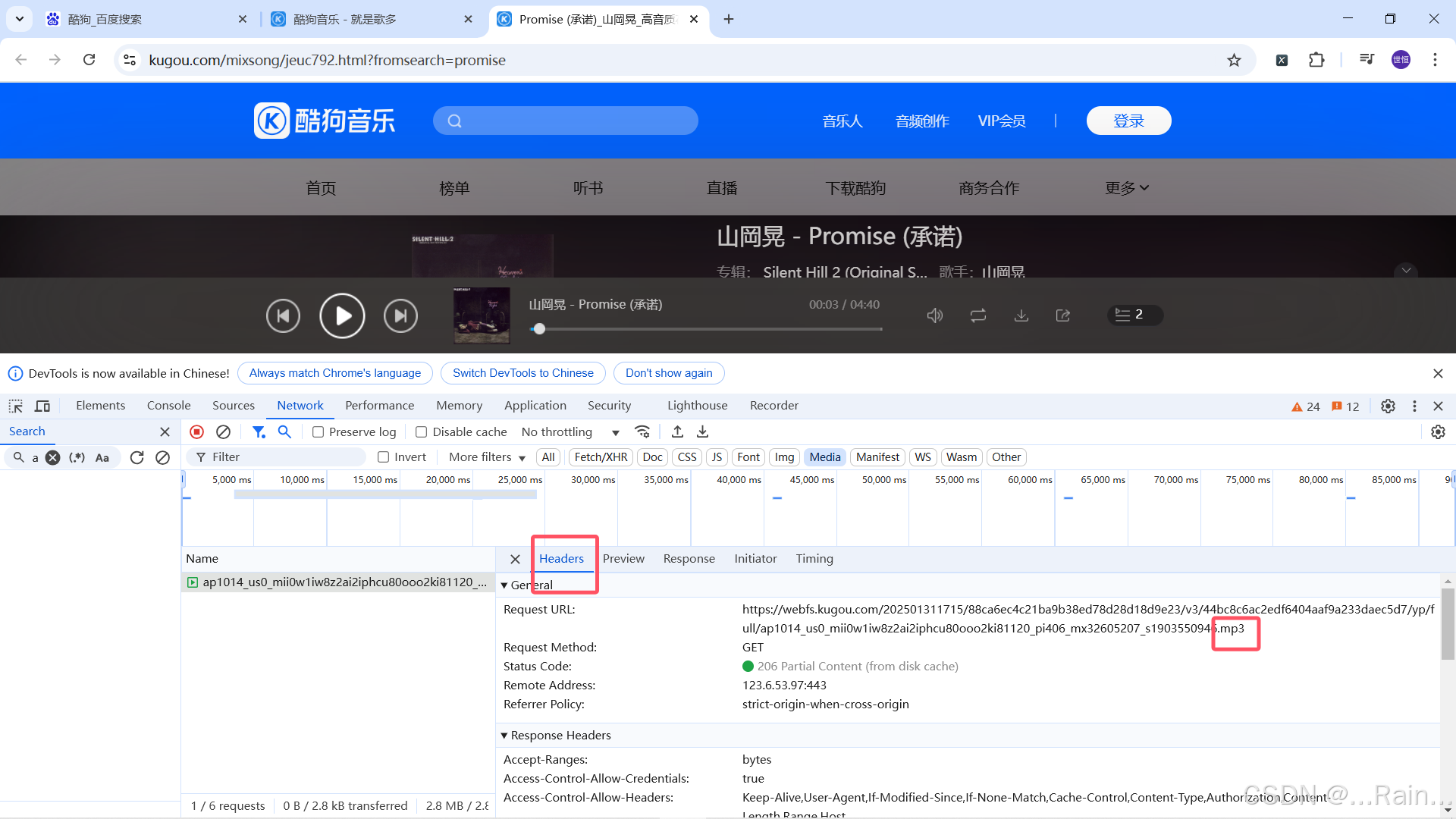
2.找到歌曲的url地址
复制画红线的这一块,按ctrl+f粘贴到搜索框中进行搜索
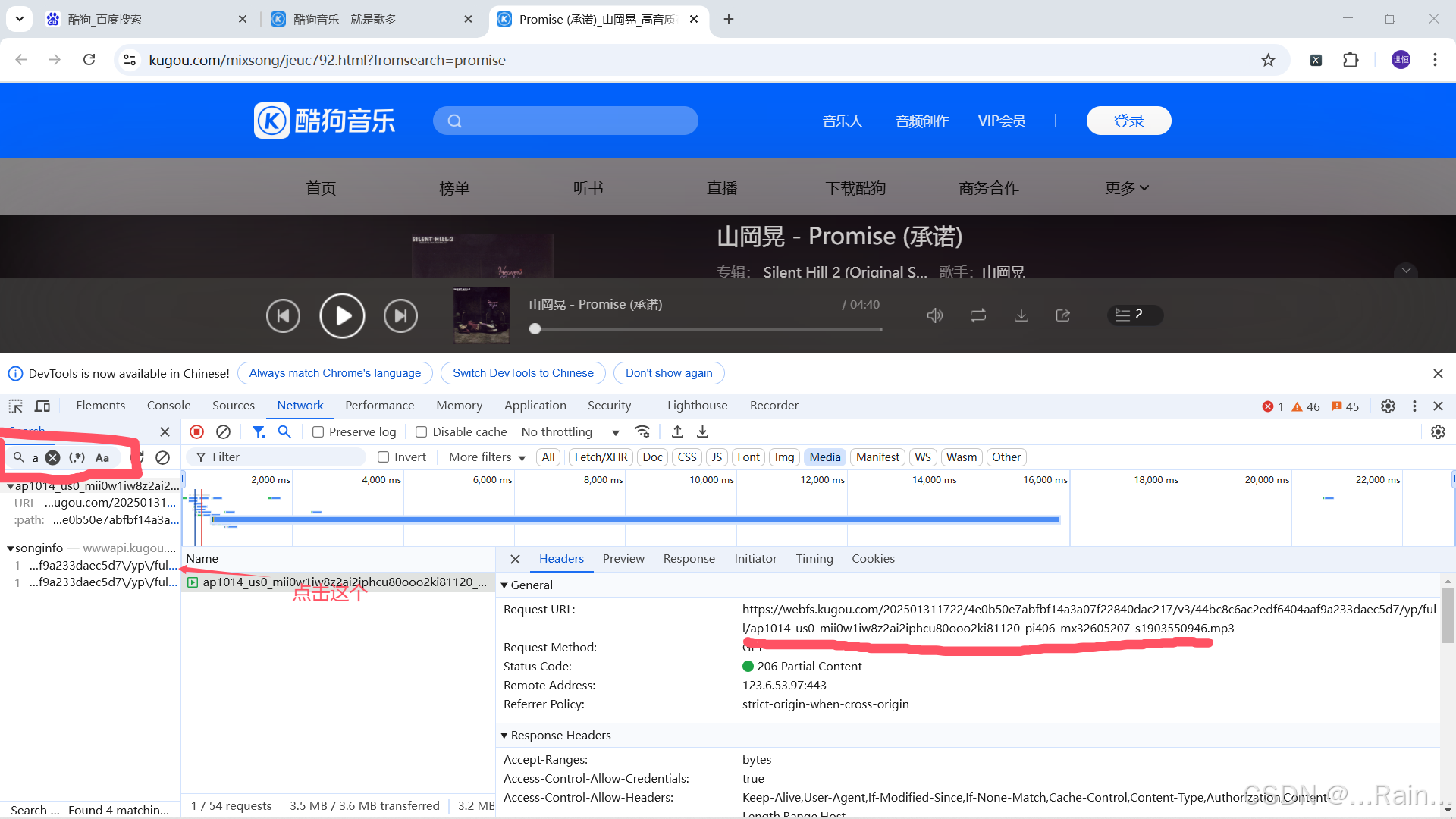 点击图片中箭头指向的
点击图片中箭头指向的
我们可以在preview中看到歌曲的信息
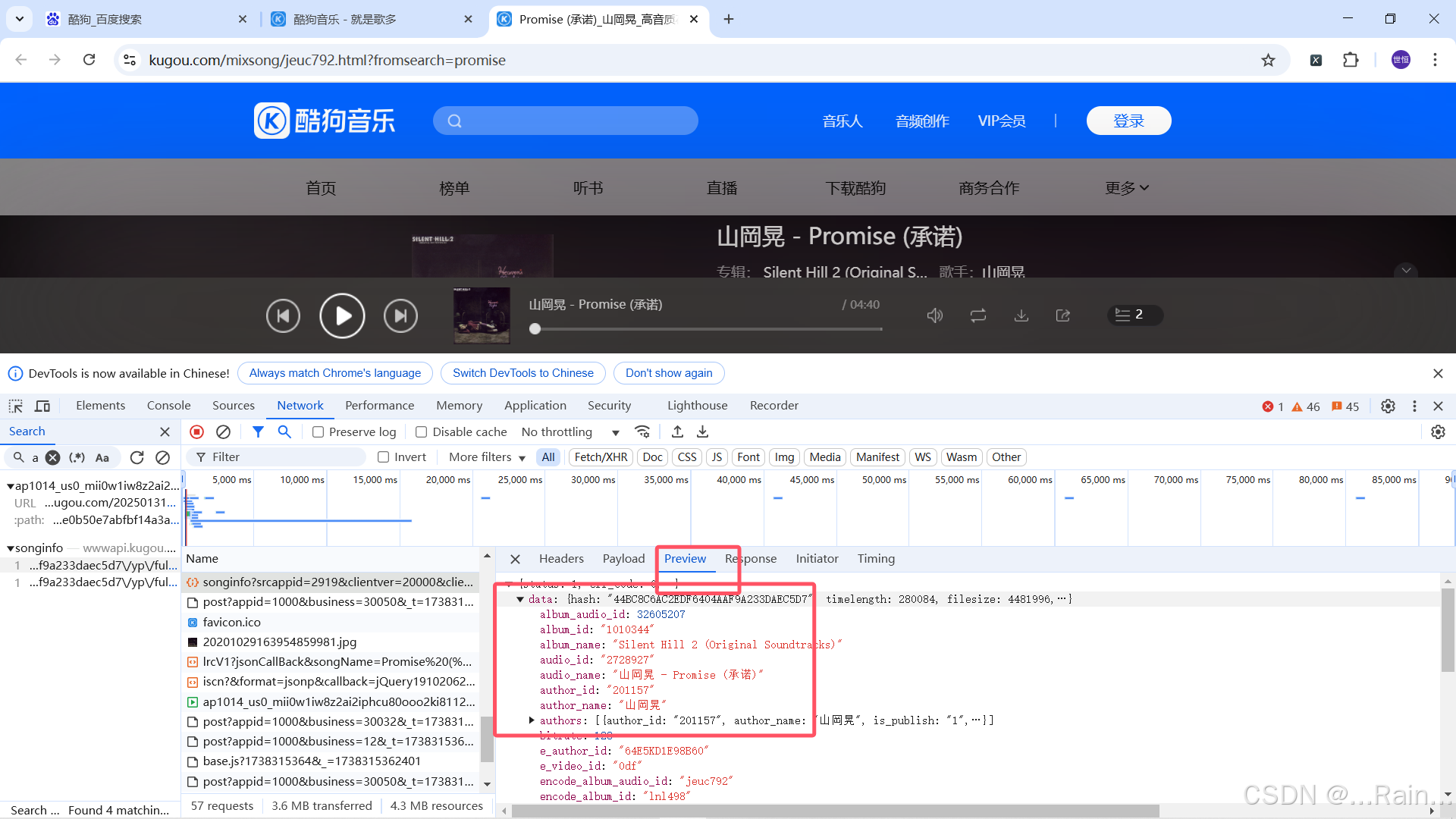
Header里的框中内容是音乐的url地址(后面的是参数,这里我们的url只需要这一小部分的就行)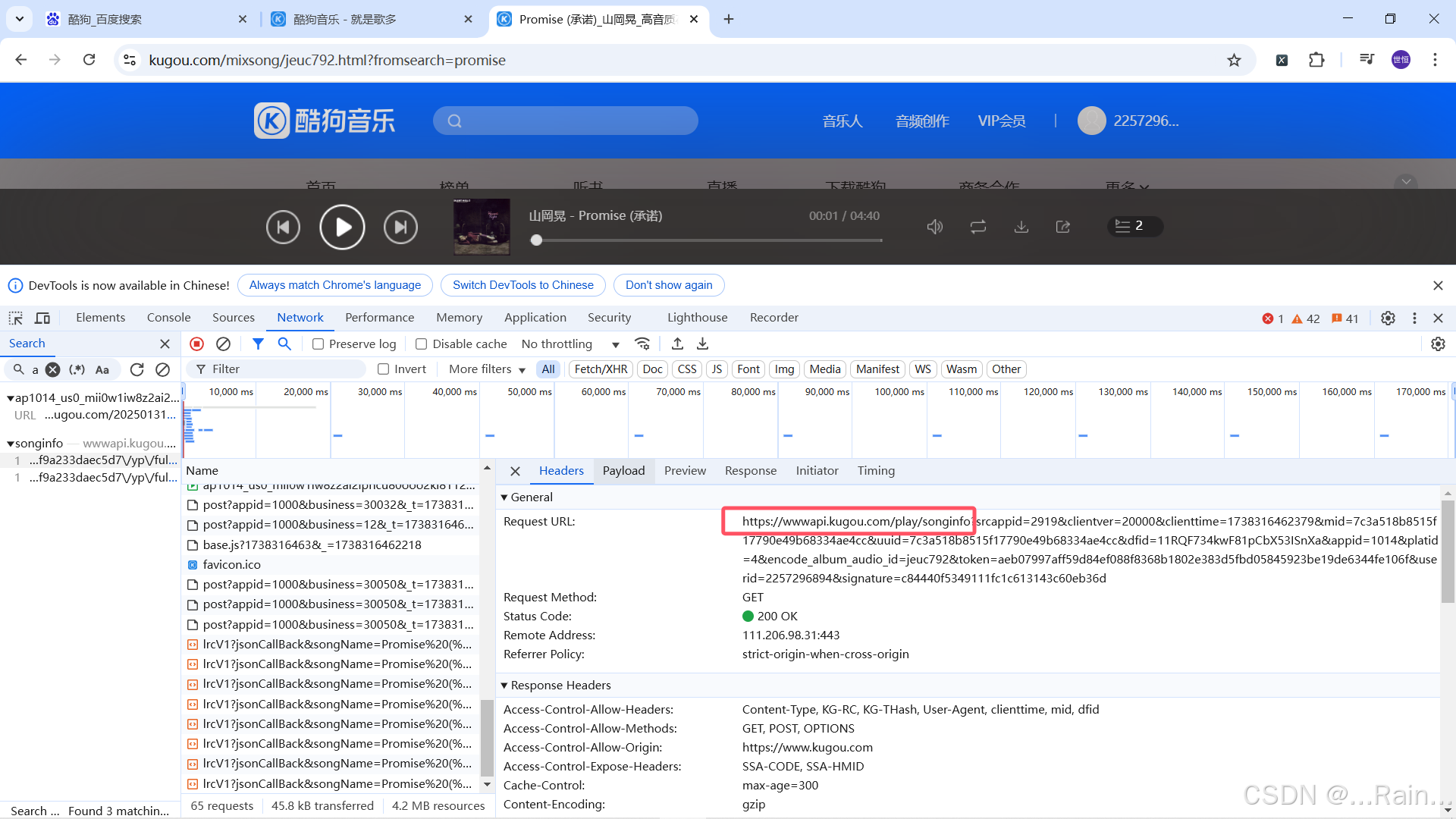
在payload中可以看到相关的参数
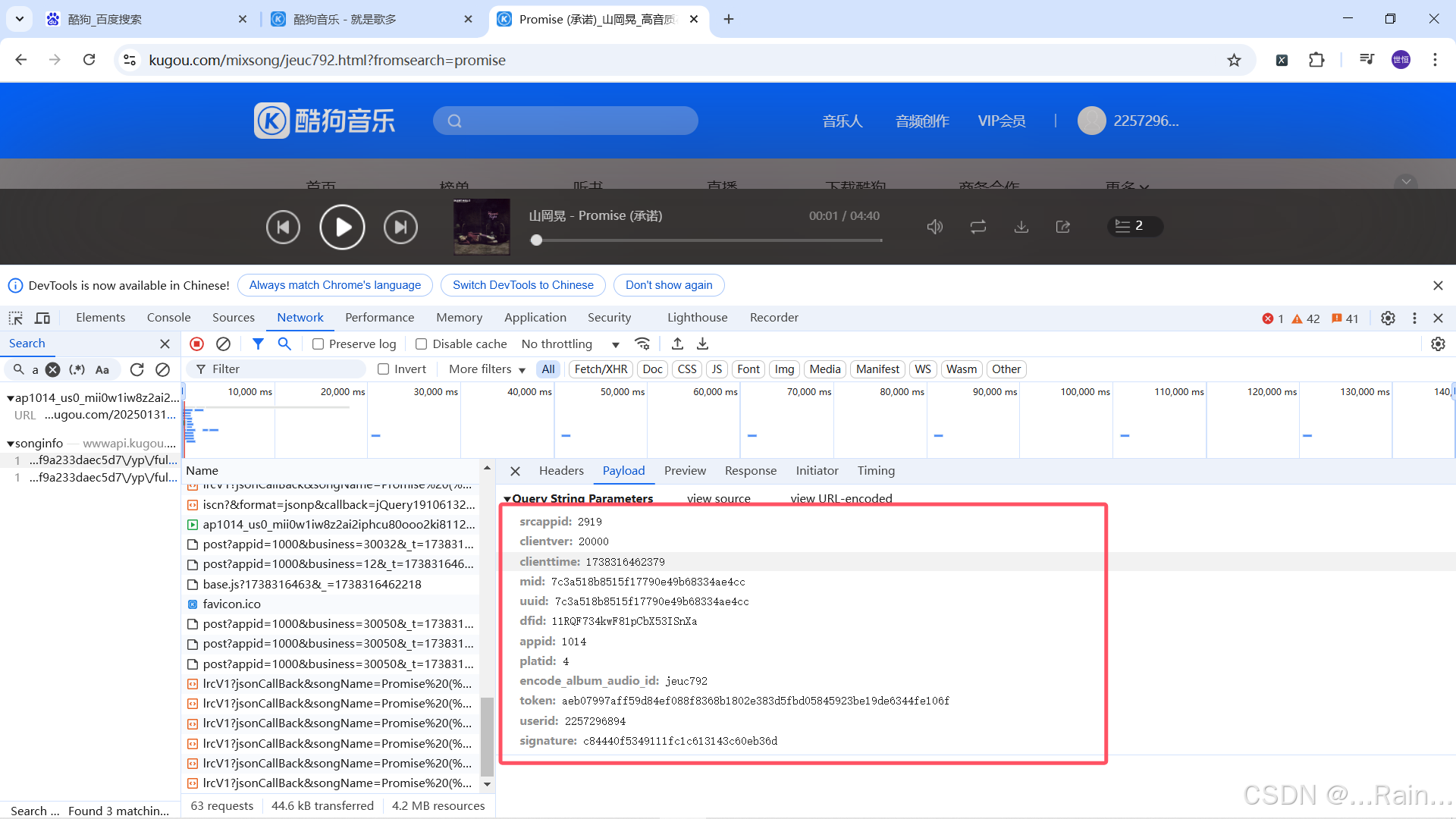
此时我们已经知道了我们需要爬取内容的基本信息可以写代码了。
1.进行伪装
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36'}
2.输入url
url='https://wwwapi.kugou.com/play/songinfo'
3.输入参数(payload里的参数复制过来,转换成字典的格式)这里提供一个方法
选中复制过来的参数
在pycharm中按Ctrl+R
源匹配为(.*?):(.*)
替换匹配为 "$1": "$2",
复制过来的参数可能在值前有空格可能会报错,需要删除掉
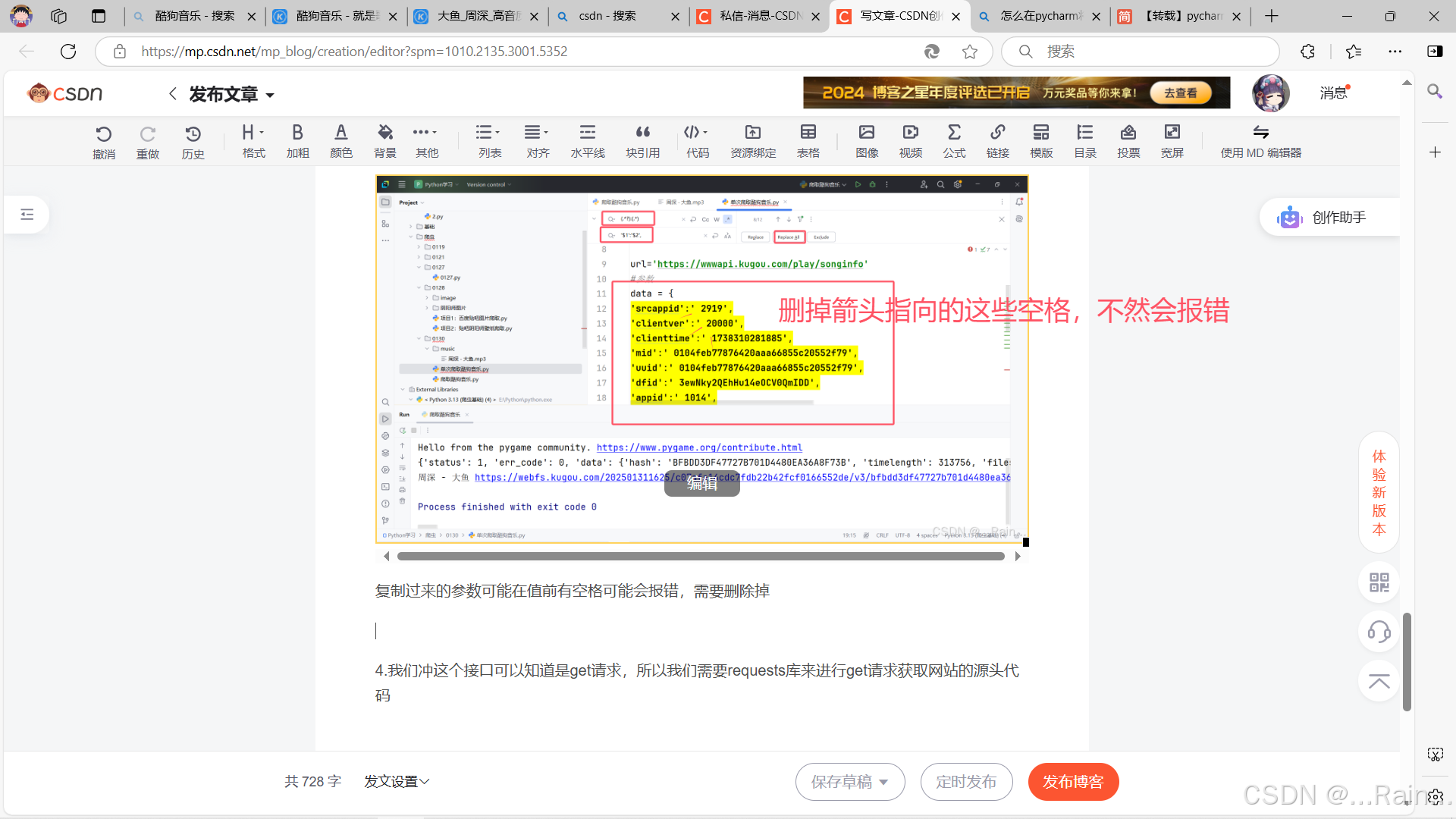
4.我们冲这个接口可以知道是get请求,所以我们需要requests库来进行get请求获取网站的源头代码
import requests
response = requests.get(url,params=data,headers=headers)
json_data = response.json()
print(json_data)###检测是否爬取到香港管内容,可以删除掉
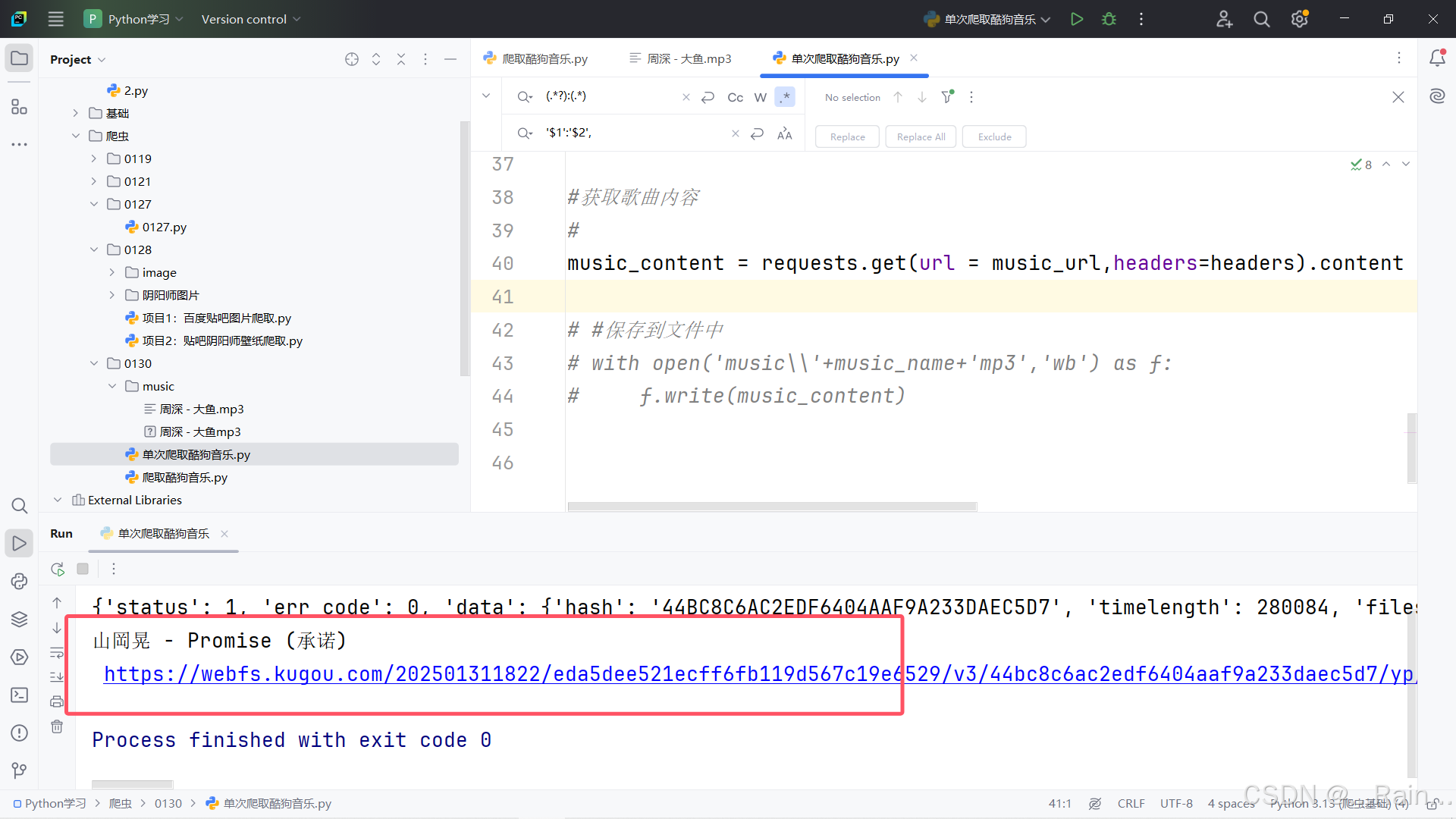
可以看到我们已经爬取到了相关内容
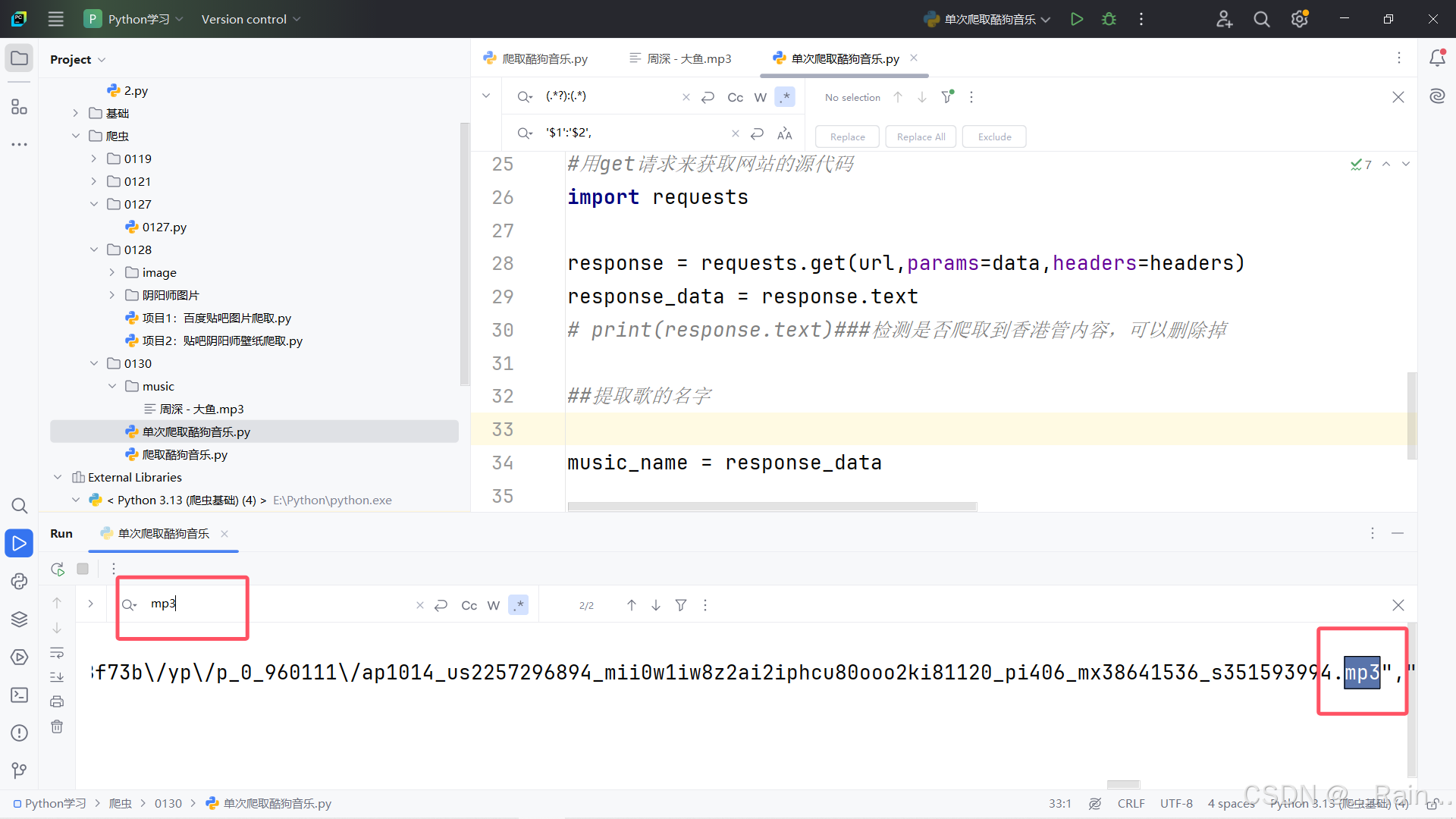
3.解析爬取到的源代码
#获取歌曲的名字
我们可以看到在preview下data下audio_name有其名字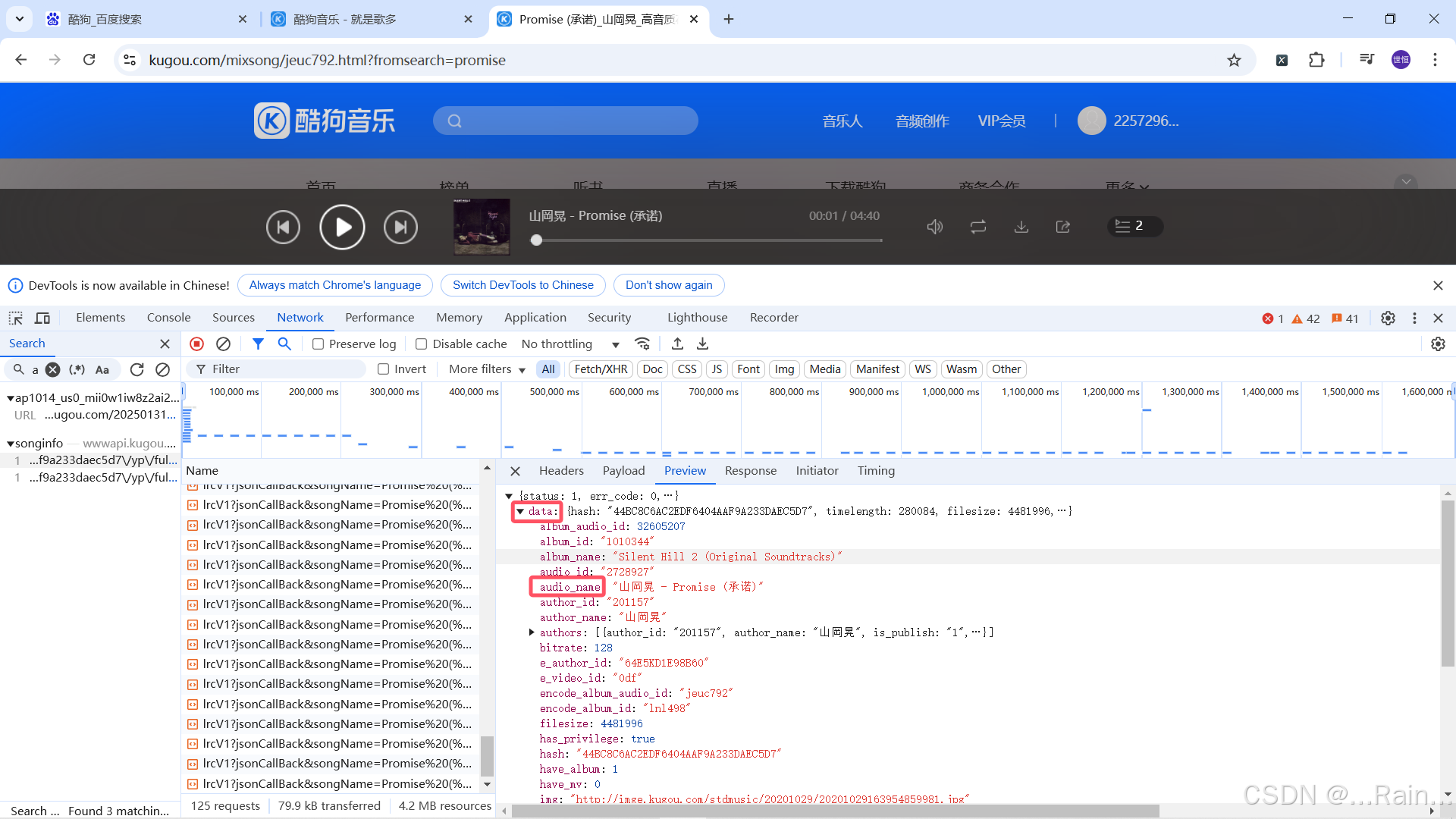
music_name =json_data['data']['audio_name']
music_url = json_data['data']['play_url']
print(music_name,'\n',music_url)
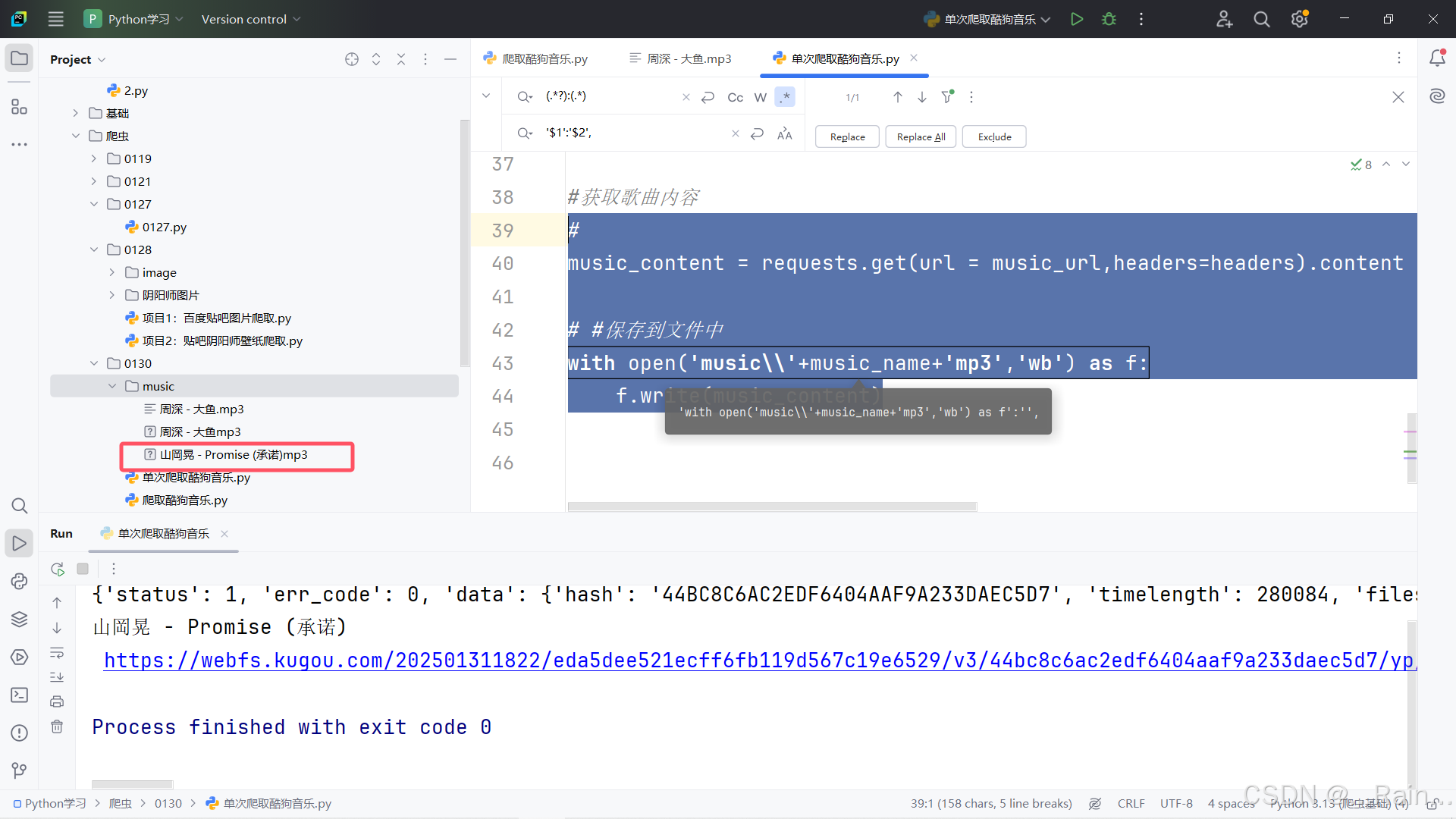
获取歌曲内容&&保存到文件
#
music_content = requests.get(url = music_url,headers=headers).content
# #保存到文件中
with open('music\\'+music_name+'mp3','wb') as f:
f.write(music_content)



















 7858
7858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











